
📌목차
1. Swin Transformer 개요
2. Swin Transformer 구조
3. Relative Position Bias
4. 실험 결과✔️ 기억할용어
- Patch Partition
- W-MSA
- SW-MSA
📕 Swin Transformer 개요
논문명 : 2021 ICLR - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Swin = Shifted Windows
Swin Transformer는 Vision Transformer의 방법론을 사용한 모델
- 이미지 패치를 결합하면서 계층적으로 feature map을 구성
- 각 Local Window에 대해서 Self-Attention을 수행하기 때문에 연산량이 입력이미지 사이즈에 비례하게 됨.
- 이미지 분류/인식 등 다양한 Task에서 Backbone으로 사용될 수 있음
📖 Swin Transformer vs ViT
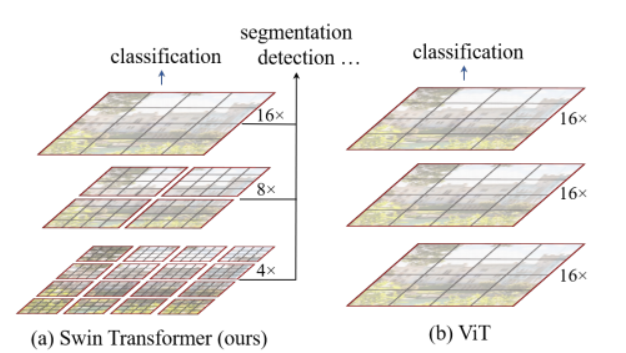
Swin Transformer
- 패치를 잘게 쪼갠뒤, 빨간색 테두리 내에 존재하는 Patch를 끼리만 Selt-Attention을 수행
- 연산량이 이미지 사이즈에 비례
ViT(Vision Transformer)
- 패치를 쪼갠뒤, 빨간색 테두리(기본 이미지) 에 존재하는 Patch를 끼리 Self-Attention 수행
- 연산량이 이미지 사이즈에 제곱해서 비례
📕 Swin Transformer 구조
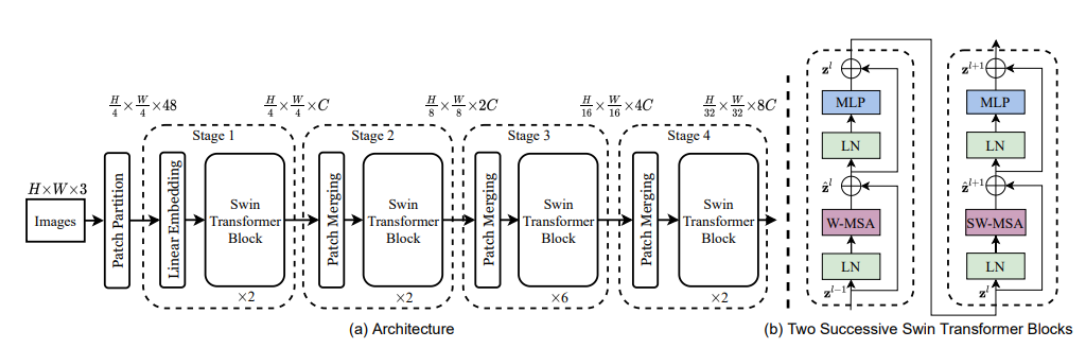
위 그림은 Swin Transformer 전체적인 구조로
Module 구성은 다음 4가지
- Patch Partition
- Linear Embedding
- Swin Transformer
- Patch Merging
📖 Patch Partition
Patch 를 구분짓는 행위
- 입력 이미지 사이즈 : H x W x 3
- 출력 이미지 사이즈 : H/4 x W/4 x 48
- 예) ( 224,224,3 ) --> ( 56,56,48 )
- 즉, 16x16x3 Pixel이 한 Patch가 되며, 채널로 넘어감.
📖 Linear Embedding
활성화함수를 거치지않는 선형 임베딩이다.
- 입력 이미지 사이즈 : H/4 x W/4 x 48
- 출력 이미지 사이즈 : H/4 x W/4 x 96
📖 Swin Transformer
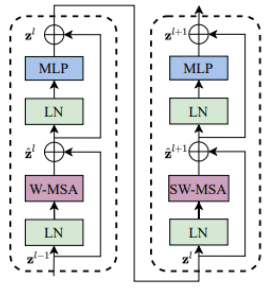
위 연속적인 구조 하나가 Swin Transformer Block 한개이다.
W-MSA (Windows-Self Attention)
- 현재 윈도우에 있는 패치들끼리만 Self-Attention 수행
- 이미지는 주변 픽셀들간의 관계성이 가장 높기 때문에, 이 방식을 사용하면 성능도 잡고 연산량도 줄일 수 있음
- 논문에서 말하기를, 이 방법을 쓰면 이미지 사이즈(hw)에 제곱으로 비례하던 연산량이 선형적으로 변할 수 있다고 함
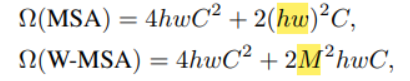
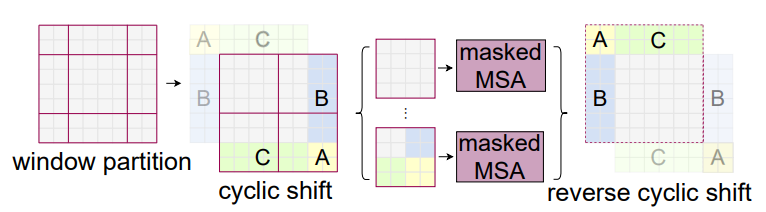
SW-MSA (Shifted Windows-Self Attention)
- 위 W-MSA를 사용하면, 윈도우 위치가 고정되어 있기때문에, 고정된 위치에서만 계속 Self-Attention을 수행하여 전체적인 공간정보를 학습하지못하는 단점이 있다. 그래서 저자들은 윈도우를 shift하여 Self-Attention을 추가적으로 진행하는 SW-MSA 방법을 제시하였음
- window shift : window size // 2
- A,B,C 구역은 mask를 씌워서 self-attention 수행안함
📕 Relative Position Bias
기존 Transformer는 Position Embedding 을 통하여 위치정보를 부여해주었다. (cos, sin 사용)
하지만 Swin Transformer 저자들은 상대적 좌표차이를 더해주는것이 더 좋다고 설명한다. (아래에서 B가 상대적 좌표차이이다.)

📕 실험 결과
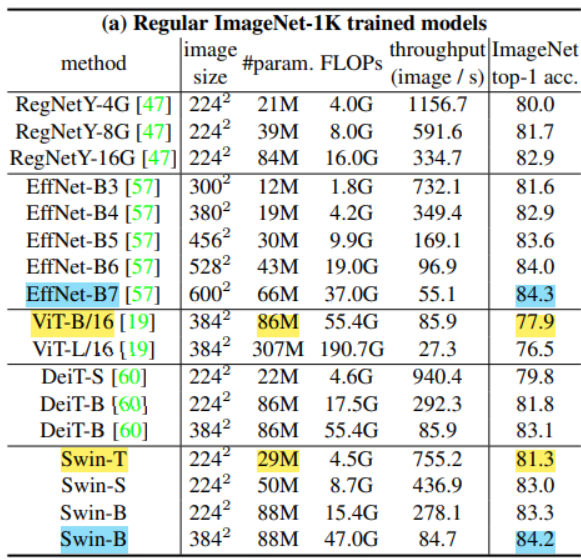
- 기존 ViT보다 학습파라미터도 적으면서 성능이 높게나옴
- CNN SOTA Model이었던 EfficientNet-B7과 비슷한 성능을 보임
- 다른 Task(객체탐지, 분할 등)의 Backbone으로 사용했을때의 성능도 거의 SOTA 성능을 보임
- W-MSA와 SW-MSA를 같이 사용하는게 성능이 좋았음
- Relative Position Embedding 만을 사용하는게 성능이 좋았음
솔직히말해서 내용이 어려워 자세한 이해가 힘들다.
코드를 사용할 순간이오면 그때 더 자세히 보자 ㅎㅎ
📚 Reference
https://paperswithcode.com/method/swin-transformer
https://visionhong.tistory.com/31

인공지능 4년차 개발자입니다.