
📌목차
1. MLP-Mixer 개요
2. MLP-Mixer 구조 및 이해
3. 실험 결과✔️ 기억할용어
- Token Mixing MLP Block
- Channel Mixing MLP Block
📕 MLP-Mixer 개요
논문명 : 2021 - MLP-Mixer: An all-MLP Architecture for Vision
ViT와 동일하게 Google Research에서 발표한 논문으로, ViT가 Self Attention만으로 성능을 높일 수 있었다면 MLP만으로도 성능을 높일 수 있지 않을까? 라는 생각으로 시작한 방법론
📕 MLP-Mixer 구조 및 이해
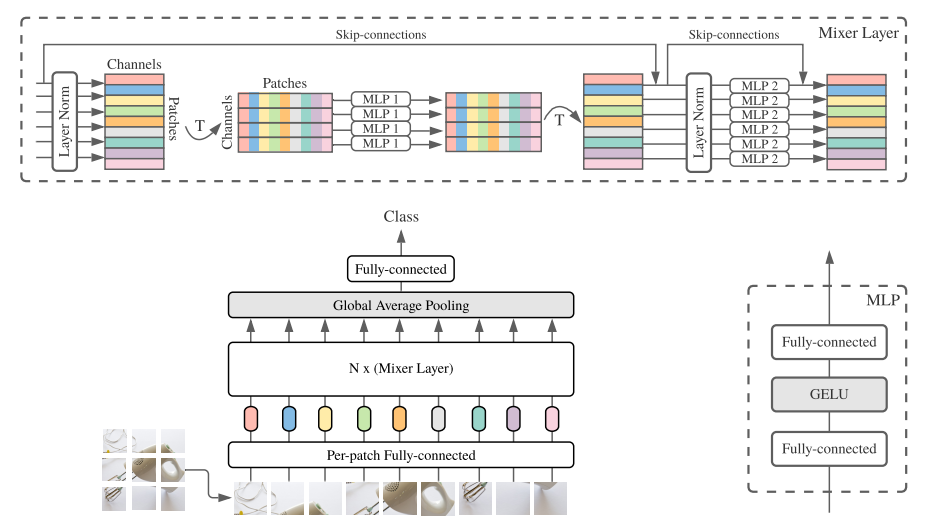
구조는 위 그림과 같으며, 매우 직관적으로 표현되어 있음
구조는 크게 세가지로 구성됨
1. Patch Embedding
- ViT와 동일하게 이미지를 패치로 분할하고 임베딩하였음
- ViT와 차이점은 Position Embedding 을 추가하지 않았음
2. MLP Block
- (1) MLP1 : Token Mixing MLP Block
- Token을 섞어서 하나의 토큰이 되게 하였음. (뒤집은것) - (2) MLP2 : Channel Mixing MLP Block
- Channel을 섞어서 하나의 토큰이 되게 하였음 (원상태로 되돌린것)
3. GAP (Global Average Pooling)
- GAP로 통합시켜 최종적으로 FC-Layer를 통과하게 됨
📕 실험 결과
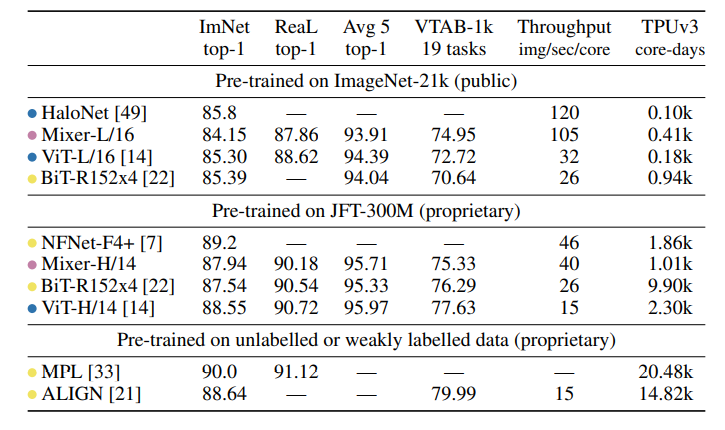
- SOTA는 달성 못하였지만, 경쟁력있는 성능을 보여주었음
📚 Reference

인공지능 4년차 개발자입니다.