
📜 BeautifulSoup 대해서 알아보자.
📕 BeautifulSoup 사용하기
BeautifulSoup은 이전 request에서 얻은 HTML정보를 객체로 담는데 사용하는 라이브러리이다.
import requests
from bs4 import BeautifulSoup
utl = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'lxml')📖 BeautifulSoup 객체를 이용한 element 가져오기
- soup.태그명 : 첫번째로 특정 태그가 발견되는 element 리턴
- soup.태그명.attrs : 특정 태그가 있는 element의 속성값들을 딕셔너리 형태로 리턴
- soup.태그명.get_text() : 문장만 뽑아내기
- soup.find(태그명, 조건) : 조건에맞는 원하는 태그의 element 리턴
- soup.find_all(태그명, 조건) : 조건에 알맞는 원하는 태그의 element 전부 리스트로 가져옴
4, 5번을 자주사용하게 될 예정
- 조건형태(1) : attrs = {속성명 : 속성값}
- soup.find("a", attrs = {"class" : "Nbtn_upload"})- 조건형태(2) : text = "ㅇㅇㅇ"
- soup.find("a", text = "ㅇㅇㅇ")
📖 연습하기
네이버웹툰 홈페이지에서 웹툰 제목들 크롤링해오기
- 제목에 해당하는 html을 보면, a태그에 속성명 class 속성값 title을 가진다.
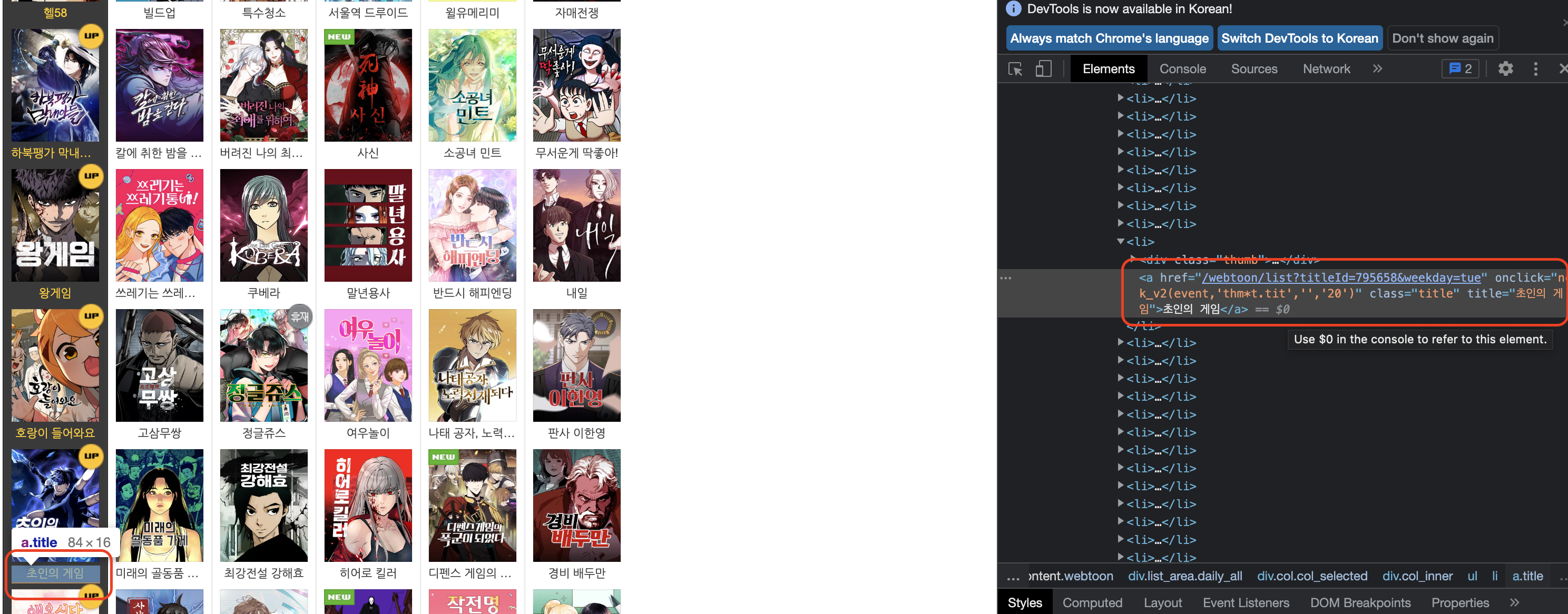
url = "https://comic.naver.com/webtoon/weekday"
headers = {"User-Agent":~~~"}
res = requests.get(url,headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
result = list(map(lambda x:x.get_text(),soup.find_all("a",attrs={"class":"title"})))
print(result)📖 부모, 형제, 자식 개념 배우기
부모 : 윗 태그
형제 : 같은 라인에 있는 태그
자식 : 아래 태그
알아둘점 : soup.find 결과는 다시 객체로 받을 수 있다.
사용법
1. 부모
- 객체.parent
- 형제 (다음형제)
- 객체.next_sibling.next_sibling : 개행때문에 두번해준다.
- 객체.find_next_sibling(태그) : 개행상관X방법
- 형제 (이전형제)
- 객체.previous_sibling.previous_sibling : 개행때문에 두번해준다.
- 객체.find_previous_sibling(태그) : 개행상관X방법
- 형제들 불러오기
- 객체.find_next_siblings(태그) : 개행상관X
- 자식
- 객체.태그
📖 한가지 웹툰에 대해 정보(제목,회차별 평점,링크) 가져오기
- 기본세팅
url = "https://comic.naver.com/webtoon/list?titleId=795658&weekday=tue"
headers = {"User-Agent":~~~}
res = requests.get(url,headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")- 제목 불러오기
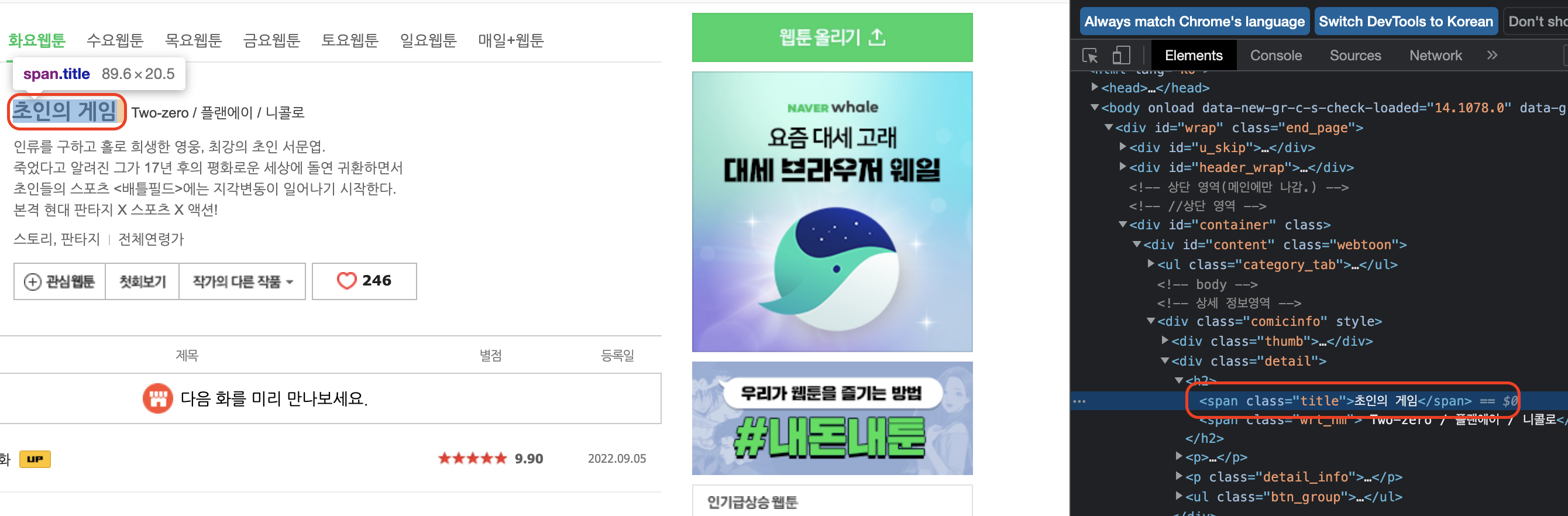
name = soup.find("span",attrs={"class":"title"}).get_text()- 회차/평점/링크 가져오기
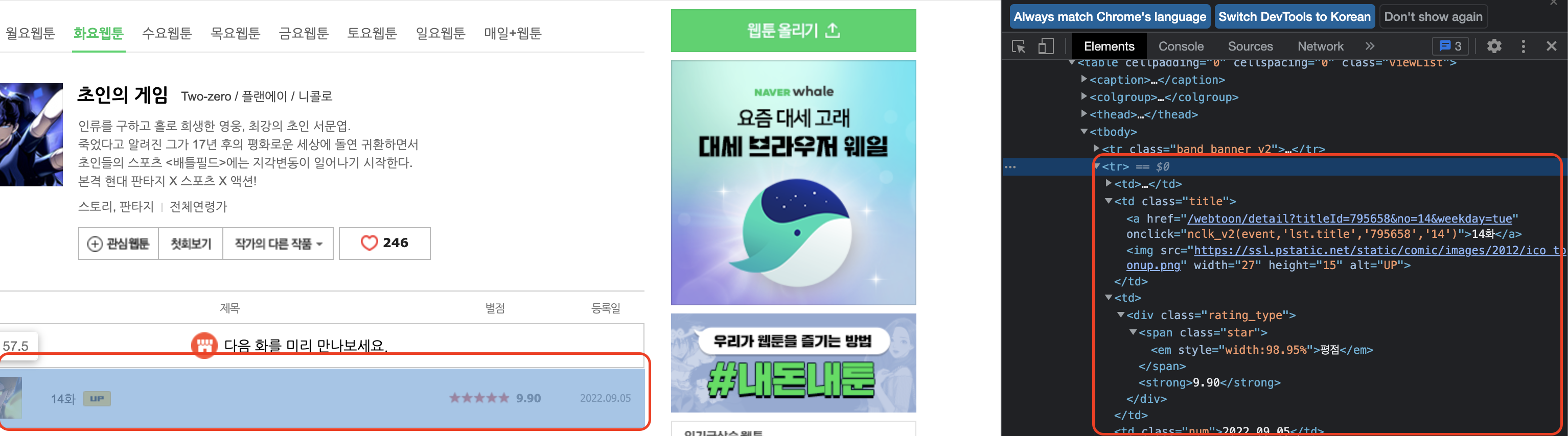
회차별로 tr태그에 감싸져있음.
"다음화를 미리 만나보세요." 부분을 가져와 형제태그를 불러오는식으로 해보자.
참고로 특정태그의 속성값 가져올시 딕셔너리 키의 value 가져오는 형태와 동일
예) a["href"] : a태그의 href속성의 속성값을 가져옴
tr = soup.find("tr",attrs={"class":"band_banner v2"}) # 다음화를 미리만나보세요
trs = tr.find_next_siblings() # 5화~14화 담은 태그
link_lst = [] # 링크 모음
num_lst = [] # 회차 모음
star_lst = [] # 평점 모음
for i in trs:
td = i.find("td",attrs={"class":"title"}) # 회차/링크 정보가 있는 태그
link = "https://comic.naver.com" + td.a["href"]
link_lst.append(link)
num = td.a.get_text()
num_lst.append(num)
star_td = td.next_sibling.next_sibling # 평점 정보가 있는 태그 (위 태그의 형제 태그임)
star = star_td.div.strong.get_text()
star_lst.append(star)
print(f"웹툰 제목 : {name}")
df = pd.DataFrame({"회차":num_lst,"평점":star_lst,"링크":link_lst})
print(df)📚 Reference
내용들은 전부 코딩 유튜브를 운영하고 계신 나도코딩 님의 영상을 공부하여 정리한 글입니다. 정말 설명잘하십니다. 한번 꼭 보세요!

인공지능 4년차 개발자입니다.