
📜 Automatic Diff
딥러닝 모델 최적화 방법은 파라미터에 대한 gradient 를 구하여 업데이트하는 방식을 사용한다.
파이토치에서 파라미터에 대한 gradient를 구하기위해서는 다음 과정을 거친다.
1. gradient를 구하고자 하는 파라미터에 requires_grad=True 부여
2. loss.backward() 실행
📕 간단한 신경망 보기
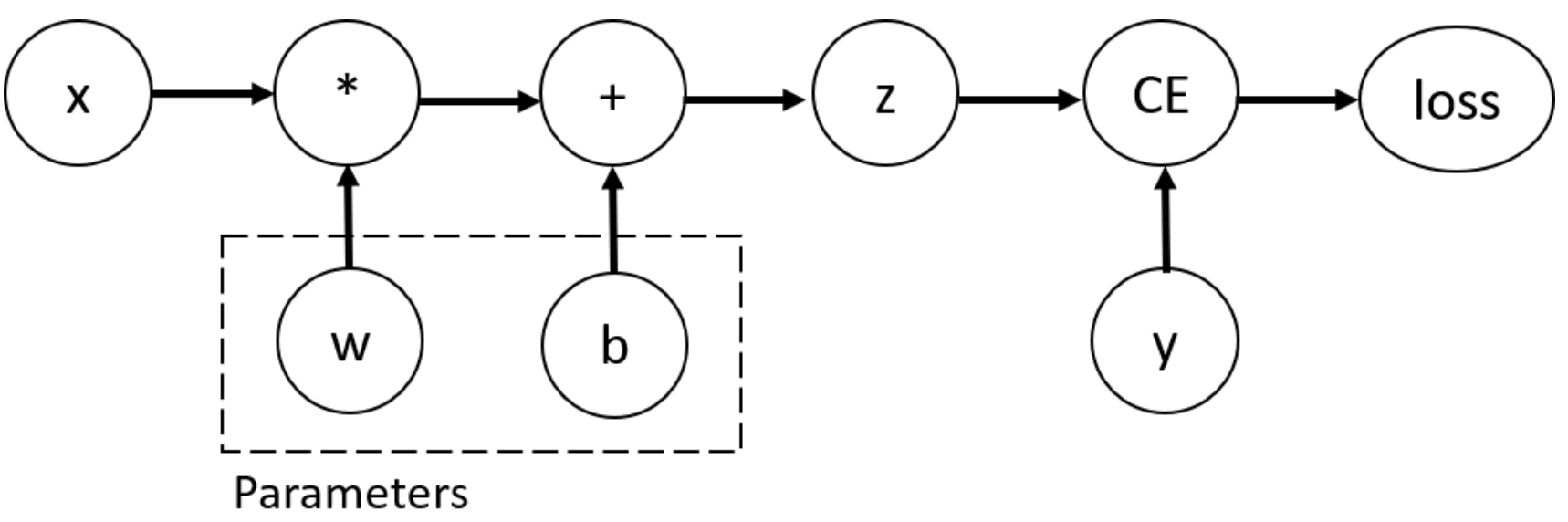
간단한 신경망 구현
# 예측값 y_hat = 입력(x) * 가중치(w) + 편향(b)
x = torch.rand(5)
w = torch.randn(5,3,requires_grad=True) # 미분가능설정 / 데이터정의시 또는 x.requires_grad_(True) 로 지정가능
b = torch.randn(3,requires_grad=True) # 미분가능설정 / 데이터정의시 또는 x.requires_grad_(True) 로 지정가능
y_hat = torch.matmul(x,w)+b
print(x)
print(w)
print(b)
print(y_hat)
> tensor([0.6995, 0.5062, 0.8033, 0.8676, 0.1050])
> tensor([[-0.7440, -0.8713, 0.3723],
[-0.1205, -0.1574, 0.7469],
[ 0.1624, -0.8205, -0.7742],
[ 2.0875, -0.0405, -2.1411],
[ 0.8769, -0.7643, 0.2188]], requires_grad=True)
> tensor([-1.9278, 0.4208, 0.2872], requires_grad=True)
> tensor([-0.4755, -1.0429, -1.5309], grad_fn=<AddBackward0>)실제값
# 실제값
y = torch.zeros(3)손실값
# Loss = 실제값과 예측값을 비교하여 손실값 구함
loss = f.binary_cross_entropy_with_logits(y_hat,y)
print(loss)
> tensor(0.3270, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>)Gradient 구함
# 역전파 수행
'''
1. dloss/dw
2. dloss/db
'''
loss.backward()
# grad 값 확인
print(w.grad)
print(b.grad)
> tensor([[0.0894, 0.0608, 0.0415],
[0.0647, 0.0440, 0.0300],
[0.1026, 0.0698, 0.0476],
[0.1109, 0.0754, 0.0514],
[0.0134, 0.0091, 0.0062]])
> tensor([0.1278, 0.0869, 0.0593])📕 미분가능여부 지정
# 1. 데이터 생성시 미분 가능 부여
data = torch.randn(5,3,requires_grad=True)
print(data.requires_grad)
# 2. 데이터 생성후 미분 가능 부여
data = torch.randn(5,3)
data.requires_grad_(True)
print(data.requires_grad)
# 3. 데이터 생성시 미분 불가 부여 (학습말고 테스트에서 사용)
with torch.no_grad():
y_hat = torch.matmul(x, w)+b
print(y_hat.requires_grad)
# 4. 데이터 생성후 미분 불가 부여 (학습말고 테스트에서 사용)
y_hat = torch.matmul(x, w)+b
y_hat = y_hat.detach()
print(y_hat.requires_grad)
> True
> True
> False
> False📚 참고
https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html

인공지능 4년차 개발자입니다.