
Video Frame Interpolation via Adaptive Convolution 리뷰
- 관련연구는 제외
- 동일저자의 후속버전인 SepConv가 있으므로, 개념만 조금 다룬후 넘어갈 예정
📌목차
1. AdaConv 개요
2. AdaConv 내용📕 AdaConv 개요
비디오프레임 보간은 전형적으로 두 단계로 나뉨
- (1) 모션 추정
- (2) 픽셀 합성
간략설명
- 해당 논문에서는 (1)번과 (2)번 과정을 하나의 프로세스로 풀어낸 방식을 설명
- 각 픽셀의 공간적으로 적응하는 컨볼루션 커널을 추정하기위해 FCN을 사용했음
- DNN을 사용함으로써 얻은 이점
- Optical Flow와 같은 GT Data없이 프레임 보간가능
- 폐색(?), 흐림 및 급격한 밝기 변화와 같은 문제를 잘 처리하고 비디오 프레임 보간 잘 되더라!
📕 AdaConv 내용
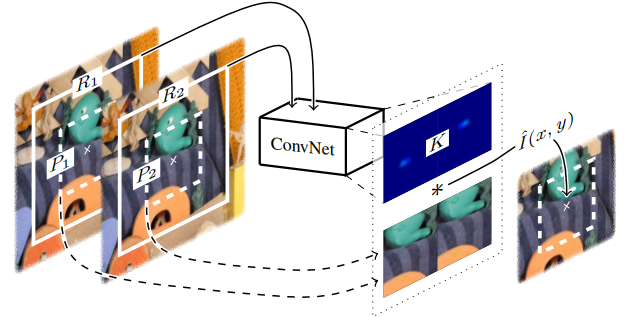
논문의 핵심방법은, 두 프레임에 Convolution 연산을 수행할 Kernel Filter를 찾는것
- 위치(x,y)를 기준으로 특정 넓이만큼 입력/출력 프레임의 영역을 패치(R1,R2)로 가정
- 두 패치 (R1,R2)를 ConvNet을 통과시켜 Kernel Filter (K)를 얻는다.
- 위치(x,y)를 기준으로 좀더 좁은 넓이만큼 입력/출력 프레임의 영역을 패치(P1,P2)로 가정
- 두 패치 (P1,P2)를 Kernel Filter(K)와 Convolution 연산을 수행
📖 모델 구조
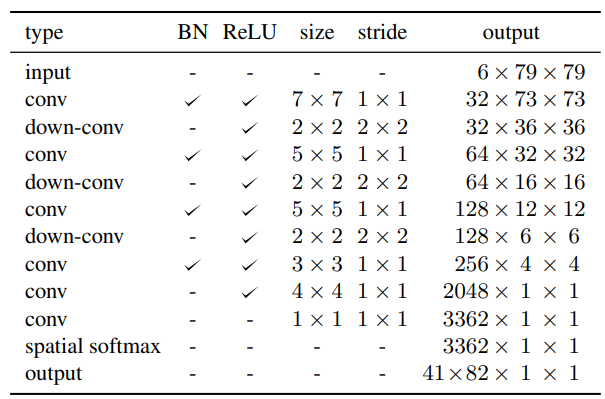
- 위 설명을 기준으로 보면 다음처럼 생각가능
- R1, R2 = 6 x 79 x 79
- P1, P2 = 6 x 41 x 41
- Kernel Filter = 41 x 82 (패치 두개를 동시에 컨볼루션 해서)
도대체 뭔 개소린지 모르겠는 부분
중요한 제약 조건은 출력 컨벌루션 커널의 계수가 음수가 아니어야 하고 합계가 1이어야 한다는 것입니다. 따라서 최종 컨볼루션 레이어를 공간 소프트맥스 레이어에 연결하여 이 중요한 제약 조건을 암시적으로 충족하는 컨볼루션 커널을 출력합니다.
📖 Loss Function
notations
- i : 학습 sample
- P : Patch (작은거)
- K : Kernel
- C(물결) : Color (GT)
- G(물결) : Gradient (GT)
저자가 제안한 Loss는 아래 Loss를 더한 값이다.
- 첫번째 Loss는 Color 를 이용한것이고 두번째는 Gradient를 이용한것
- 첫번째 Loss만 사용하면 블러가 낀 형태의 이미지가 도출되는 한계점을 지님
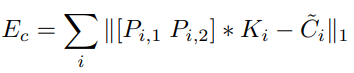
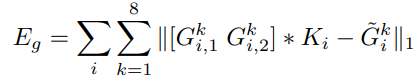
코드로 구현해봐야 정확히알거같은데 소스도없고 ..

인공지능 4년차 개발자입니다.