
Video Frame Interpolation via Adaptive Separable Convolution 리뷰
- 관련연구는 제외
- 전체적인 개념은 이전 논문과 동일함. 그래서 자세한 설명 생략
📌목차
1. SepConv 개요
2. SepConv 내용📕 개요
동일한 저자의 이전 연구 AdaConv는 41 x 41 2D Kernel의 경우 1080p 영상 기준 약 26GB의 GPU메모리가 필요하다. 즉 메모리를 많이 사용하기 때문에, 문제가 되었다.
이 문제를 해결하고자, SepConv라는 논문을 다시 제시하였고
SepConv는 2D 커널이 아닌 1D Kernel 2개 (수직, 수평)를 사용하는 방법을 통해 필요 메모리를 줄였다
SepConv 특징
- 2D Kernel이 아닌 1D Kernel 2개를 사용하였다.
- UNet구조를 사용하였다.
📕 내용
예측값은 아래 수식과 같음
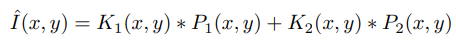
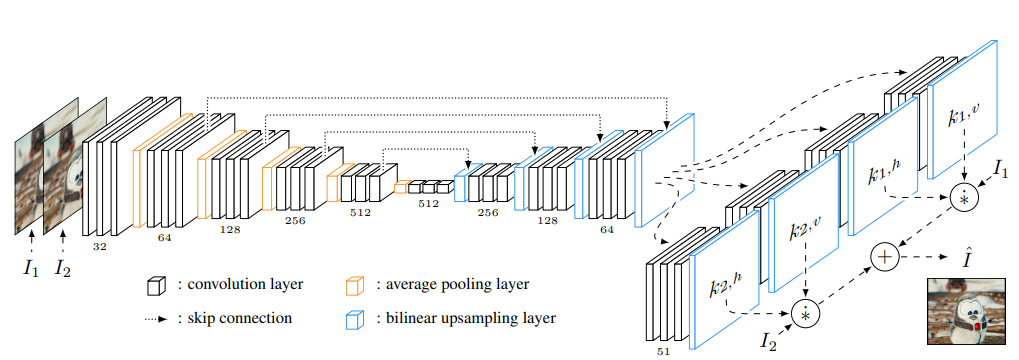
📖 구조
- UNet 구조를 사용하였음 (Skip Connection 이용)
- Upsampling은 Bilinear upsampling 방식
- github 코드를 보니까, 그림과 다르게 채널 변경될때마다 Convolution을 한번씩만 시행하는거 같음
📖 Loss Function
1) Frame 간의 차이 - L1 Loss 사용
2) Frame을 CNN Model 통과한 중간 결과값의 차이 - L2 Loss 사용
- 저자들은 VGG19의 Relu4_4 Layer 통과한 결과값을 L2 Loss 쓴게 성능이 제일 좋다고 하였음

인공지능 4년차 개발자입니다.