강의 소개
네트워크를 성공적으로 학습시키기 위해서는 많은 양의 데이터가 필요합니다. 하지만 대부분의 상황에서 저희는 한정된 양의 데이터밖에 제공 받지 못합니다. 때문에 한정된 양의 데이터를 가지고 많은 양의 데이터로 학습시키는 효과를 내기 위해 data augmentation 기법을 사용합니다. Data augmentation이란 이미 가지고 있는 데이터를 가지고 새로운 데이터를 만들어 내는 여러 기법들을 통칭합니다.
이번 강의에서는 간단한 data augmentation 기법과 논문을 소개하고 그 중 rand augmentation이 현재 코드에 어떻게 적용되어 있는 지를 소개해드립니다.
마지막으로, AutoML 파트의 wrap-up으로 쉬운 toy problem(CIFAR-10)을 활용하는 가상의 시나리오를 통해 어떻게 AutoML이 원하는 모델을 찾아가는 지 실험을 통해 보여드릴 예정입니다. 실제 저희 업무환경의 대부분은 resource가 제한적이기 때문에, AutoML을 적용하는데 있어 어려움이 있습니다. 이를 개선하고자, scalable하게 적용할 수 있는 가장 간단한 방법을 적용해보고, 노하우와 직관을 통해 이러한 scalability 이슈를 개선할 가능성을 있다는 것을 가상 시나리오를 통해 보여드리고 싶었습니다.
대회에서는 여러분들 만의 engineering 노하우가 담긴 Search가 적용되었으면 합니다!
Further Reading
- Automl 리포트 예시
- [Paper] AutoAugment: Learning Augmentation Policies from Data
- [Paper] RandAugment: Practical automated data augmentation with a reduced search space
1. Overview: Image augmentation
1.1 Introduction
Data Augmentation
- 기존 훈련 데이터에 변화를 가하여 데이터를 추가로 확보하는 방법
- 데이터가 적거나 imbalance된 상황에서도 유용하게 활용 가능
- 직관적으로 모델에 데이터의 불변하는 성질을 전달하여 모델이 robust해짐
- ex) 강아지 이미지 : 회전,늘림,일부분 만 보임 등에서도 강아지 이미지
- 데이터 종류마다 Augmentation 종류 및 특성이 다름
- 음성, 정형데이터, 이미지 등등
경량화, AutoML 관점의 Augmentation?
- 경량화 관점에서 직접적으로 연결되지는 않지만, 성능 향상을 위해서는 필수적으로 적용되어야 하는 기법
- Augmentation 또한 일종의 파라미터로, AutoML의 search space에 포함이 가능한 영역
object detection에서의 대표적인 augmentation 기법들
- Mixup, CutMix, Mosaic(한 꼭지점 기준으로 네 면에 다른 이미지를 배치), Blur
image classification에서의 대표적인 augmentation 기법들

1.2 Image augmentation list-up
- augmentation 기법 별 code로 구현
- 블로그 상에선 따로 다루지 않을 예정
2. Image augmentation 논문 리뷰
2.1. Issue
- Task, Dataset 종류에 따라 적절한 Augmentation 종류, 조합, 정도(magnitude가 다를 것)
- ex1) Capacity가 작은 모델의 학습에 심한 augmentation을 적용 시 성능 저하 발생!
- ex2) 숫자 인식(MNIST) 데이터에 심한 rotation(180도) augmentation을 적용 시 성능 저하 발생!!(ex, 6을 뒤집으면 9로 인식할 경우도 있음)
2.2. 초간단 리뷰: AutoAugment
- AuoML로 Augmentation polcy를 찾고자 하는 배경에서 작성된 논문
- Data로부터 Data를 잘 반영하는 augmentation policy를 학습
- 총 5개의 sub policy, 각 subpolicy는 2개의 augmentation type, 각 probability와 magnitude를 가짐
- subpolicy : 2개의 augmentation 조합을 찾고, 두 augmentation을 몇 퍼센트의 확률로 적용할지와, magnitude를 가짐.
- 성능은 좋지만, 학습에 매우 큰 자원이 필요
- 속도를 개선하기 위해 다양한 시도가 있었음
- Fast autoaugment paper
- Adversarial autoaugment paper
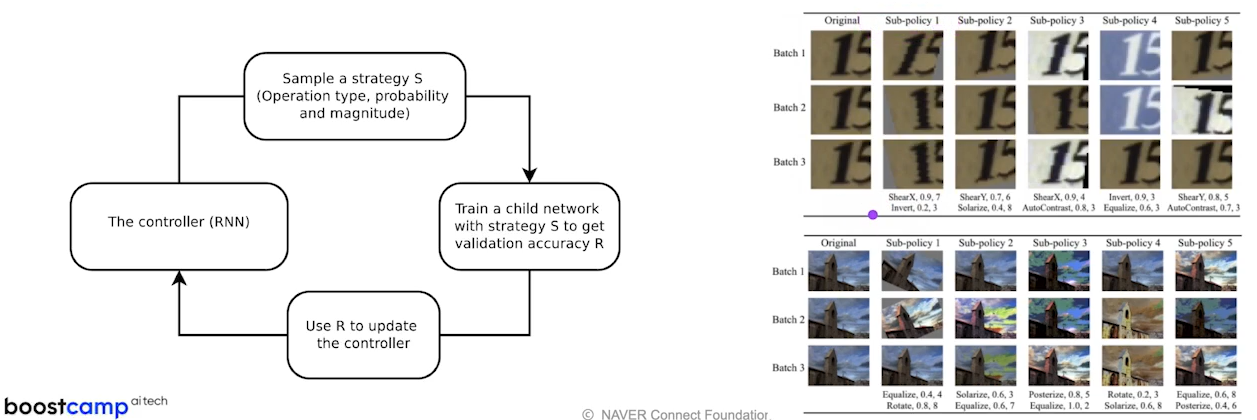
2.3. 초간단 리뷰: RandAugment
- 좋은 절충안!!
- 2개의 파라미터(N: 한 번에 몇 개 적용, M: 공통 magnitude)로 search space를 극단적으로 줄임
- RandAug : 약 10^2, AutoAug: 약 10^32
- 이 설정으로, policy를 찾는 여타 알고리즘과 거의 도등한 성능을 보임

3. Rand Augmentation 적용하기
- 코드 상에서 진행
4. AutoML 실습 및 결과 분석
4.1 가상의 시나리오
- AutoML 구동 전 다음과 같은 내용을 파악해야 함
- 가용가능한 자원(CPU,GPU) 수 파악
- 일반 모델을 학습하는데 걸리는 시간
- 등등..
- 특정 task에 모델 제작 요청이 들어왔을 때, objective, task를 한 번 수행하는데 걸리는 시간, 해당 리소스에서 구동시킬 수 있는 최대 세션 수 등을 파악해야 함.
- 시간을 줄여야 할 경우? 데규모의 셋을 소규모 샘플링하여 모델에 학습 및 모델 성능에 가장 큰 영향을 주는 인자만 Search space에 포함
- 이후 AutoML로 모델 성능 파악 및 그래프화
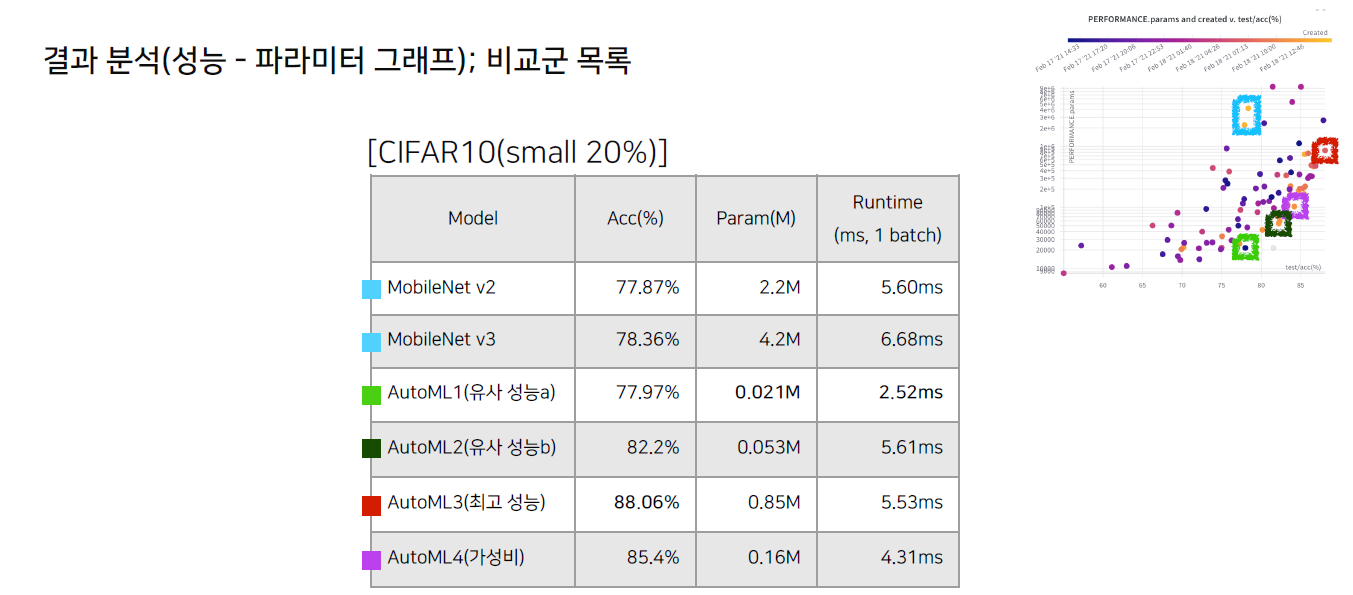
4.2 결과 분석 및 논의
- 우측에 샘플을 토대로 구한 모델 성능을 기반으로 n개의 모델 선정
- baseline : MobileNet v2 & v3
- 유사 성능 대비 모델 사이즈가 작은 경우
- 유사 사이즈에서 성능이 가장 좋은 경우
- 등...
- 이후 몇 가지 모델의 configuration을 가지고 전체 데이터로 학습을 진행
- 모델 제작 요청자 의도에 맞게 모델을 전달
약간의 discussion & open questions
- AutoML로 데이터셋, task에 특화된 모델을 찾는 것이 가능
- 다만, 현실적인 문제(시간, 리소스 등)들을 해소하기 위해 엔지니어링은 아직 사람의 노하우가 필요
- 데이터셋이 계속 추가되고 변화하는 현실 상황에서 이전 결과를 지속적으로 활용하려면 시스템을 어떻게 구성해야 할 지에 대한 방법을 생각해야 함.

DL, NLP Engineer to be....