강의 소개
모델 경량화 기법에는 다양한 방법론들이 있습니다. 주요 경량화 기법으로는 Pruning, Knowledge Distillation,Weight Factorization, Quantization이 있습니다.
이번 시간에는 본 강의에서는 다루지 않는 Pruning 과 Knowledge Distillation 의 기본 컨셉과 논문들을 다루면서 조금이나마 Pruning과 Knowledge Distillation 을 맛볼 수 있게 준비했습니다!
각 기법 안에서도 여러 갈래로 연구가 진행되고 있는데요, 그 중 중요하다고 생각되는 논문들을 다루고 있으니 연구들의 큰 흐름과 좋은 insight 를 얻어가셨으면 좋겠습니다!
강의 목표 : 어떤 경량화를 적용해야 할까?
현업에서 경량화는 deploy하는 시점에 대부분 적용이 된다고 한다. 이때 경량화는 주어진 환경에 따라 적용할 수 있는 방향이 다르다.
환경은 아래와 같이 다양하게 존재한다.
- Deploy 환경(CPU/GPU, Quantization 적용 시 가속 가능한 device 존재 여부)
- 주된 문제 상황(Latency 축소, Edge device이므로 모델 사이즈 축소 등)
- 경량화 요구 정도( 성능 Drop을 감수한 경량화 / 성능 drop 절대 불가 등)
- HW 리소스(From scratch로 재학습이 가능한가, E.g) Tranformer, 매우 큰 dataset)
논문은 각자의 novelty를 위해 현실과는 조금 다른 결과이며, 다른 기법들과의 조합은 잘 언급하지 않는 경향이 있다. 따라서 각 기법의 효과를 이해하고, 상황의 요구 상황에 맞게 어떤 경량화 기법들을 조합해야 할 지는 엔지니어의 몫이다.
따라서 이 강의에서는 각 기법들의 주된 특징과 주요 흐름을 파악하는 것이 목표다.
모델 경량화 recap
- 주요 경량화 기법
- 효율적인 architecture(MobileNet, EfficentNet 등 + NAS) -> 다른 강의 참고
- Pruning(STructured, Unstructured) :주로 다룰 내용
- Knowledge Distillation(Response based, Feature based) : 주로 다룰 내용
- Weight Factorization(Tucker decomposition,...) -> 6~9강
- Quantization -> 6~9강
+ Transformer 의 각 기법 적용은 NLP 경량화 기법에서 다룰 예정
Paper Review
Pruning
- Pruning : 중요도가 낮은 파라미터를 제거하는 것
- Pruning 단위 : Stuctured(group, block) / Unstructured(fine grained)
- Pruning 기준 : 중요도 정하기
- Magnitude(L2,L1), BN scaling factor, Energy-based, Feature map 등
- 기준 적용 방법 : Network 전체로 줄세워서(global), Layer마다 동일한 비율로 기준(local)
- gobal로 할 경우 layer마다 pruning 되는 정도가 다름
- local로 할 경우 layer마다 동일 비율로 pruning 적용
- 어떤 phase : 학습된 모델에(pretrained model) / initialize 시점에(pruning at initialization)
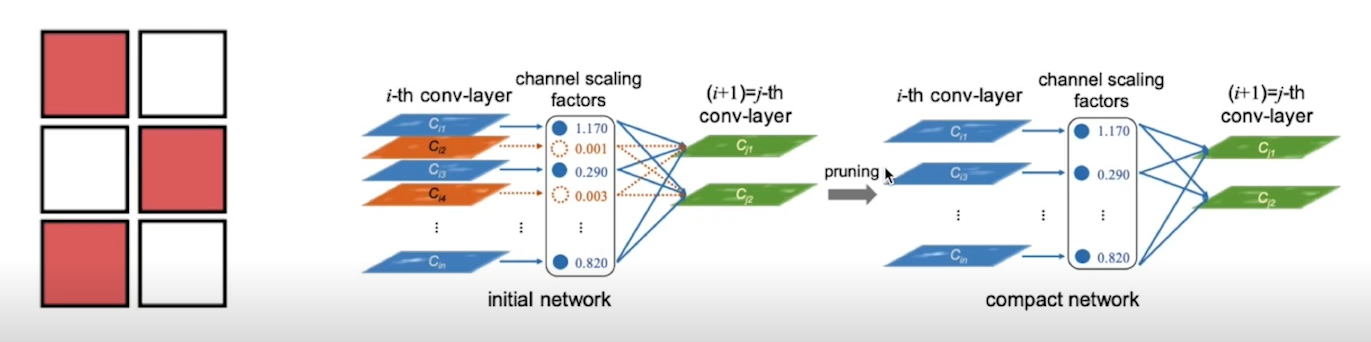
structured Pruning
- 파라미터를 그룹 단위로 pruning(그룹 단위 : channel,filter, layer level 등 가능)
- Masked(0으로 pruning 된) filter 제거 시 실질적 연산 횟수 감소로 직접적인 속도 향상
conv-layer의 output인 channel scaling factors를 봤을 때, 실질적으로 중요하지 않은(값이 매우 작은) factors들을 지울 경우 layer 수가 감소하여 속도가 빨라지게 된다.
Unstuctured Pruning
- 파라미터 각각을 독립적으로 Pruning
- Pruning을 수행할수록 네트워크 내부의 행렬이 점점 희소(Sparse)해짐
- Structured Pruning과 달리 Sparse Computation에 최적화된 소프트웨어 또는 하드웨어에 적합한 기법
- 아래와 같이 Sparse representation에 대해서 연산 가속이 가능하다던지 등이 적용되지 않는 한 속도 향상은 없음
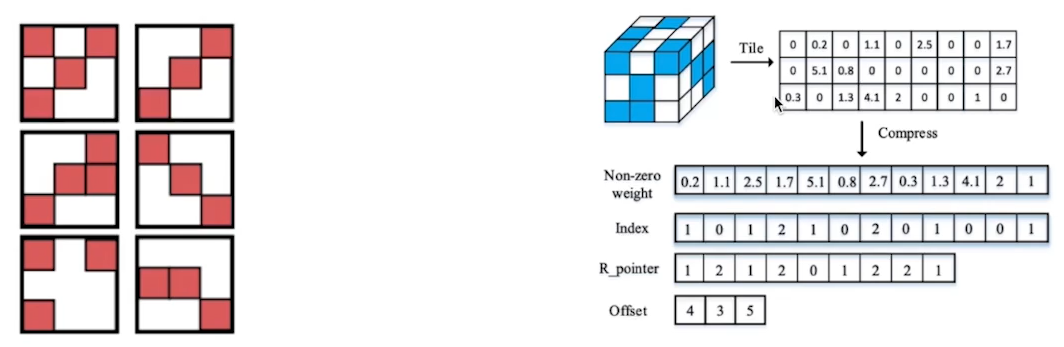
- 아래와 같이 Sparse representation에 대해서 연산 가속이 가능하다던지 등이 적용되지 않는 한 속도 향상은 없음
Knowledge Distillation
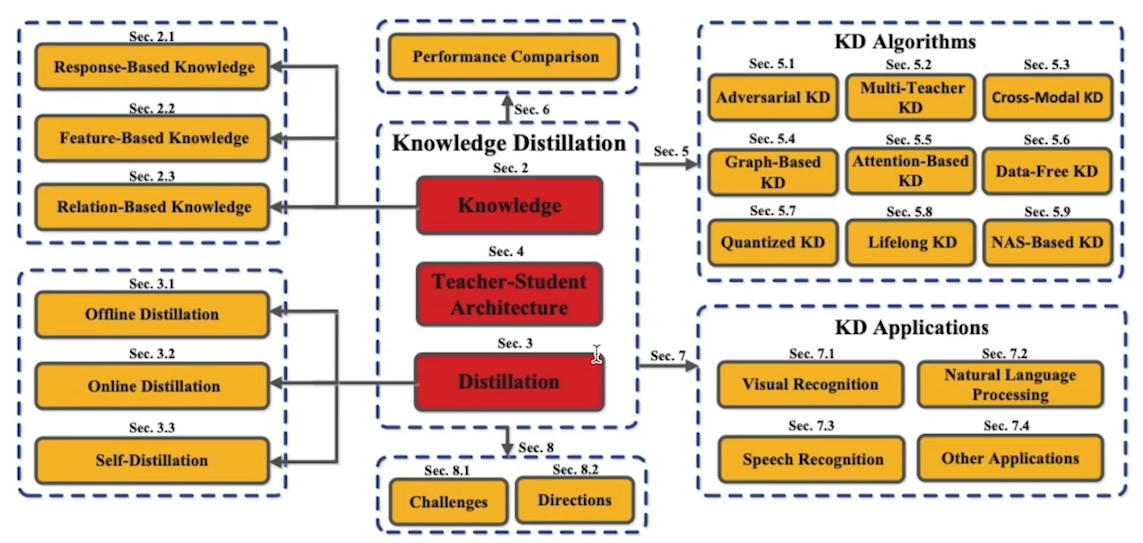
- teacher의 정보를 어떻게 빼낼까? => 다음 과 같이 세 가지 경우로 구분이 가능
- Response-Based Knowledge - 최종만 빼내는 경우
- Feature-Based Knowledge - 중간중간 layer의 결과를 빼내어 student에게 넘겨주는 경우
- Relation-Based Knowledge - 데이터 간의 정보(input layer), 여러 feature들간의 정보(hint layers), 출력 결과 간의 정보(output layer)처럼 특정 데이터 혹은 feature 간의 정보를 활용한 경우