강의소개
강의소개
8강에서는 Open-domain QA 문제를 풀 때 발생할 수 있는 bias에 대해 배워보겠습니다. Bias는 무엇인지, 어떤 상황에서 발생할 수 있는지 전반적인 내용들에 대해 알아본 후 ODQA를 풀 때 생길 수 있는 여러 측면의 bias에 대해 알아보겠습니다. 마지막으로 각각의 bias를 해결하기 위한 노력들에는 어떤 것이 있는지 알아보는 시간을 가지겠습니다.
Further Reading
- Latent Retrieval for Weakly Supervised Open Domain Question Answering
- Dense Passage Retrieval for Open-Domain Question Answering
Definition of Bias
- type of Bias
- Bias in learing
- inductive bias
- 학습 시 과적합을 막거나 사전 지식을 주입하기 이위해 특정 형태의 함수를 선호하는 것
- 즉, 특정 입력-출력 형태가 있을 때 모델이 이 형태에 맞게 작동시키도록 유도하여 학습하는 것으로, 이 역시 bias지만 무조건 negative 요소는 아님
- inductive bias
- A Biased Word
- historical bias : 현실 세계 자체가 편향되어 있기에 모델이 원치 않는 속성으로 학습이 되는 것
- co-occurence bias : 성별과 직업 간 관계 등 표면적인 상관관계 때문에 원치 않는 속성이 학습되는 것
- Bias in Data Generation
- specification bias : 입력과 출력을 정의하는 방식에 의한 편향
- sampling bias : 데이터 샘플링 방식에 의한 편향
- e.g.) 모집단에서 A와 B의 비율이 50:50이지만, 표본집단을 생성 시 잘못된 샘플링으로 30:70으로 추출된 경우
- annotator bias : 어노테이터의 특성에 의한 편향
- Bias in learing
Bias in Open-domain Question Answering
-
Training bias in reader model
- SQuAD, klue-mrc 등과 같이 (Context,Query, Answer)이 모두 포함되어 항상 정답이 지문 내에 포함된 데이터쌍에 대해서 학습을 할 경우 Reader는 항상 정답이 문서 내에 포함된 데이터쌍(Positive)만을 학습하게 됨
- 단, inferece에서 데이터 내에 찾아볼 수 없었던 새로운 context가 주어질 경우 Reader는 해다 문서에 대한 독해 능력이 매우 떨어질 것이고, 결과적으로 정답을 출력하지 못함
-
How to mitigate training bias?
- 1) Train negative examples(5강 참고)
- 훈련 시 잘못된 예시 문서를 보여주면 retriever가 negative한 내용들을 먼 곳에 배치할 수 있음
- 단, 어떻게 negative sample을 지정하는지에 따라 다름
- 1) corpus 내에서 랜덤하게 추출
- 2) 조금 더 헷갈리는 Negative samples 추출
- BM25/TF-IDF를 통해 매칭 스코어는 가지지만 답을 포함하지 않은 샘플을 추출
- 같은 문서에서 나온 다른 passage나 question 선택
- 2) Add no answer bias
- 이 경우 마지막 레이어 weight에 훈려 가능한 bias를 추가하고, softmax로 answer prediction을 수행할 때 start와 end 확률이 bias 위치에 있는 경우 "대답 할 수 없음"으로 취급
- SQuAD의 경우 "No answer"를 추가하여 SQuAD2.0을 만듬(SQuAD 1.1에서 2.0으로 update 시 변경된 요소 중 하나임)
- 1) Train negative examples(5강 참고)
Annotation Bias from Datasets
- What is annotation bias
- 데이터셋을 제작 시 생기는 이슈로, ODQA model을 학습 시 기존 MRC 데이터셋을 활용하는데, ODQA에는 적합하지 않은 bias가 발생하 수 있음
- Dataset 종류
- 질문자가 답을 알고 있지 않는 경우 : Natural Question, WebQuesions, CuratedTrec 등
- 질문자가 답을 아는 경우 : TriviaQA, SQuAD, Korquad 등
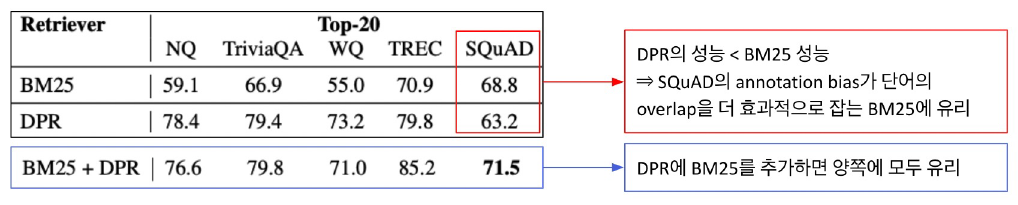
- 실제 질문 시 질문자는 답을 모르는 상태에서 질문을 하므로, 이 경우를 최대한 시뮬레이션을 해야 bias가 없는 dataset을 제작이 가능하지만, 실제 dataset을 만들 때 이것을 적용하기가 어려움 => 이런 데이터셋으로 학습 시 원치않는 편향 발생(답을 아는 경우의 데이터셋)
- 이 경우 질문이 지문에 dependence가 발생
- 특히 squad의 경우 사람들이 많이 보는 500개의 문서만 활용하는데, 실제 질문은 많이 보지 않는 지문에 대해서도 질문을 할 수 있으므로, 해당 dataset 분포 자체에 이미 bias가 존재함
- 또한 정답이 지문 내 어떤 문단의 어떤 위치에 있는지까지 알기에 bias가 더 발생
- Effect of annotation bias
- dataset별 성능 차이가, 모델이나 파라미터 조정 등 다른 factor에 의한게 아니라 dataset 자체의 bias 때문에 발생할 수 있음
- 단순히 dataset에 따라 retrieval 방식에 따른 성능 차이가 발생
- Dealing with annotation bias
- Annotation 단계에서 발생할 수 있은 bias를 인지하고, 이를 고려하여 데이터를 수집
- e.g.) Natural Question dataset의 경우, 실제 구글 검색엔진에서 user들이 사용했던 query를 모으고, annotator들이 tool을 활용해서 답을 찾는 방식으로 dataset을 구성하여 ODQA와 비슷했기에 bias를 줄일 수 있었음
- another bias in MRC dataset
- ODQA에 applicable하지 않은 질문들이 존재
- SQuAD가 그 예로, "대통령은 누구인가"와 같이 불분명한 질문이 있음. 질문은 성립하지만 어느 시점인지, 어느 국가인지 등에 대한 정보가 없기에 대통령이 누구인지에 대한 질문이 들어오면 특정 인물만 출력되는 것과 같이 bias가 생김
현재 MRC dataset을 다루면서 오늘 설명해주신 논문에 대해 팀원 중 한 분이 읽고 발표를 해주시기도 했고, 나 역시 훑는 정도로 읽어보면서 어느 정도 파악을 했었지만, 강의를 통해 논문에서 전하고자 했던 내용을 조금 더 알 수 있었다.또한, ODQA trak에서 bias가 미치는 영향에 대해 고민해본 적도 없었는데 이번 강의를 통하여 단순히 query에 적합한 answer를 출력해내는 것 뿐만 아니라 데이터셋에 따라 그 model이 가지는 bias에 대해 알 수 있었던 시간이었다.
이것을 보며 알게된 건, 우리가 가지고 있는 데이터셋은 SQuAD와 유사하므로 anntation bias가 단어의 overlap을 효과적으로 잡는 BM25가 성능이 왜 좋은지 부분이었으며, 아직 우리 팀이 시도해보지 못한 부분들에 대한 팁들도 얻었다.
이것을 바탕으로 더 성적을 높여보자

DL, NLP Engineer to be....