[boostcampAI P stage] week 11-14
1.(1강) MRC Intro & Python Basics
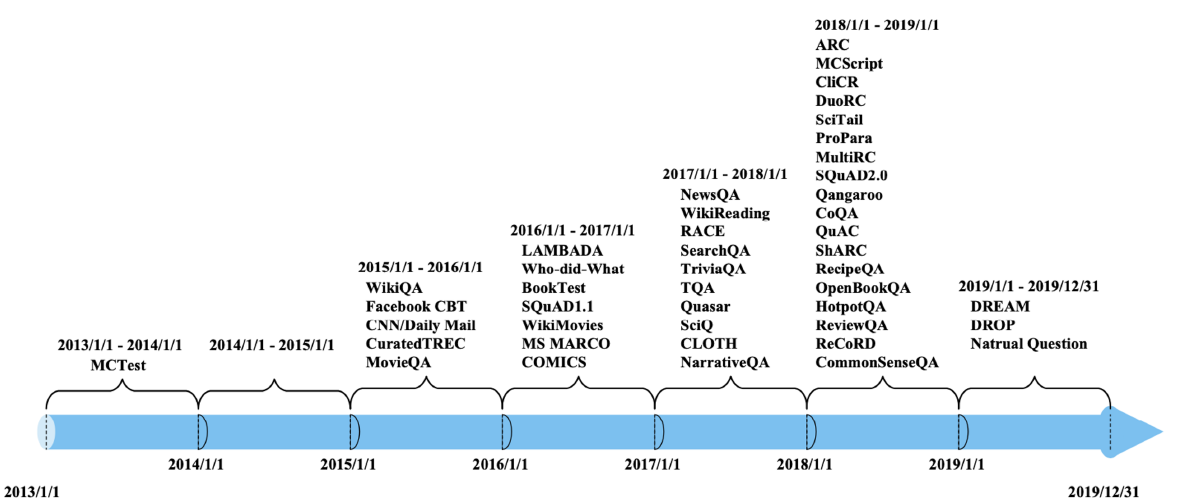
강의소개기계독해(MRC) 강의에 오신걸 환영합니다. 첫 강의에서는 기계독해에 대한 소개 기본적인 파이썬 지식들에 관한 강의입니다. 기계독해란 무엇인지, 어떠한 종류가 있는지, 평가는 어떻게 해야할 지에 대해 알아보고, 자연어 처리에 필요한 unicode / tokeni
2.(2강) Extraction-based MRC
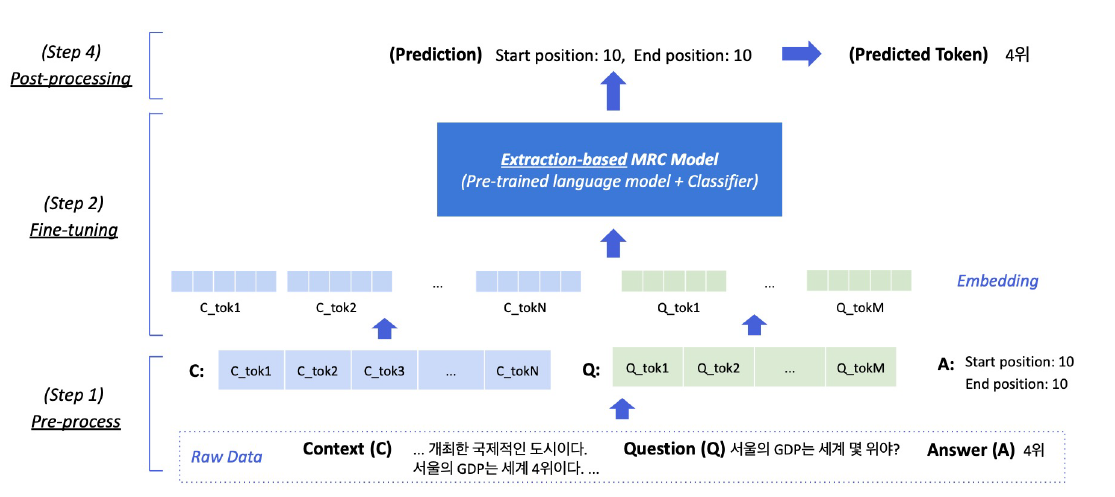
강의소개2강에서는 추출기반으로 기계독해를 푸는 방법에 대해 알아보겠습니다. 추출기반으로 기계독해 문제에 접근한다는 것의 의미를 이해하고, 실제 추출기반 기계독해를 어떻게 풀 수 있을지에 대해 배워볼 예정입니다. 학습 전 준비해야할 단계와 모델 학습 단계, 그리고 추출기
3.(3강) Generation-based MRC
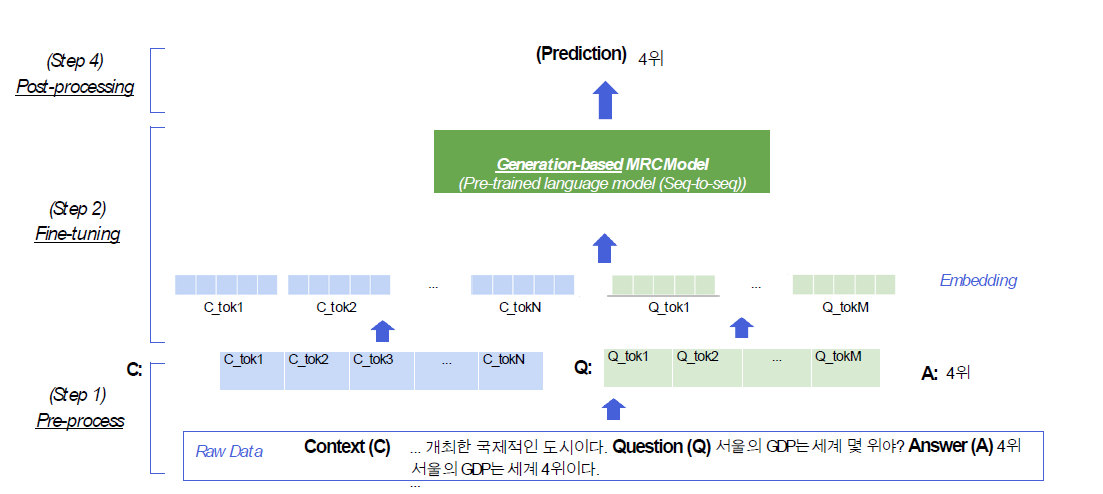
강의소개3강에서는 생성기반 기계독해에 대해 배워보겠습니다. 생성기반으로 기계독해를 푼다는 것의 의미를 이해하고, 어떻게 생성기반 기계독해를 풀 수 있을지 알아보겠습니다. 2강에서와 마찬가지로 모델 학습에 필요한 전처리 단계, 생성기반 모델 학습 단계, 그리고 최종적으로
4.(4강) Passage Retrieval - Sparse Embedding

강의소개4강에서는 단어기반 문서 검색에 대해 배워보겠습니다. 먼저 문서 검색 (Passage retrieval)이란 어떤 문제인지에 대해 알아본 후, 문서 검색을 하는 방법에 대해 알아보겠습니다. 문서 검색을 하기 위해서는 문서를 embedding의 형태로 변환해 줘야
5.(5강) Passage Retrieval - Dense Embedding
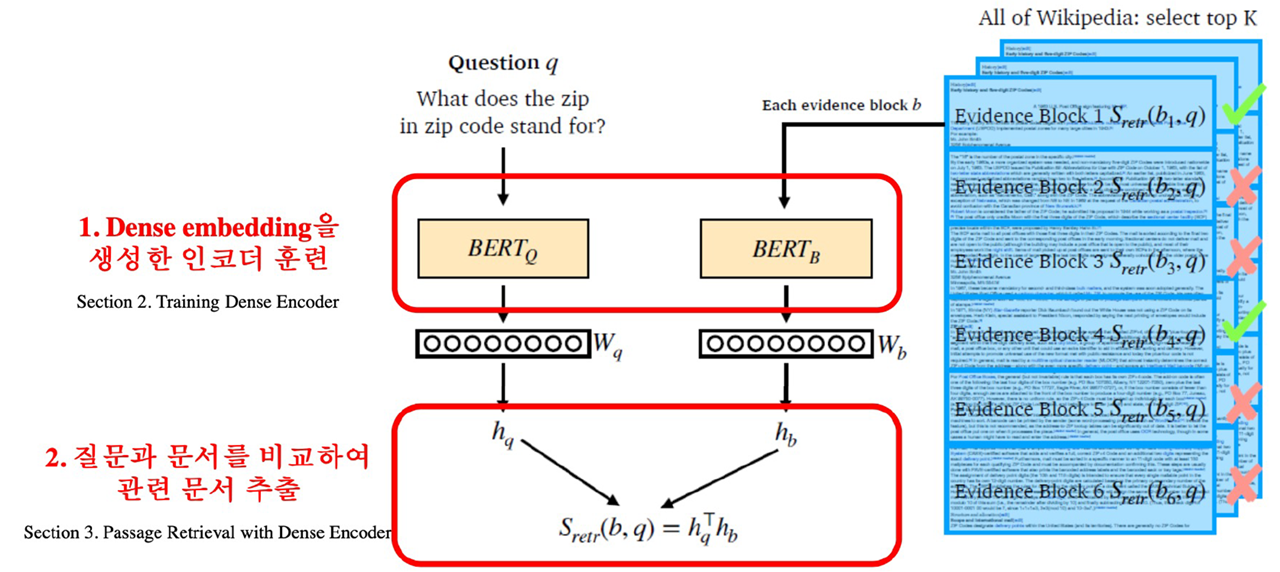
강의소개앞선 4강에서는 sparse embedding 기반 문서 검색에 대해 배워보았습니다. 이번 5강에서는 앞서 배운 sparse embedding이 가지는 한계점들에 대해 알아보고, 이를 해결할 수 있는 dense embedding에 대해 배워보겠습니다. Dense
6.(6강) Scaling up with FAISS(Scailing Up)
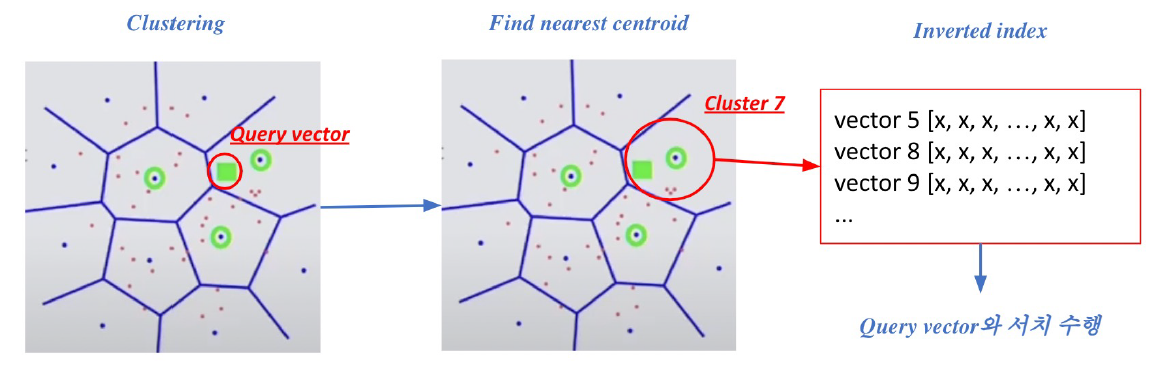
강의소개앞선 4, 5강에서 sparse / dense embedding을 활용해 문서 검색을 하는 방법에 대해 실습해보았습니다. 실습에서는 수만개 단위의 데이터였지만, 실제 문서 검색이 이루어지길 원하는 실제 상황에서는 그 문서의 수가 기하급수적으로 늘어나게 됩니다.
7.(7강) Linking MRC and Retrieval
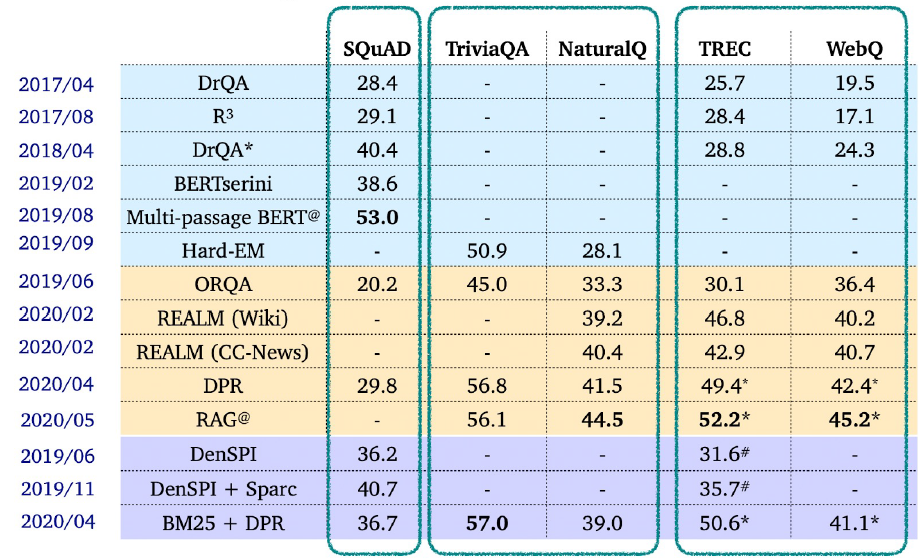
강의소개6강에서는 기계독해와 문서 검색을 연결해 Open-domain question answering (ODQA)를 푸는 방법에 대해 배워보겠습니다. 먼저 이번 기계독해 강의의 대회에서도 풀어야 할 ODQA가 무엇인지에 대해 알아보겠습니다. ODQA를 풀기 위한 접근
8.(8강) Reducing Training Bias
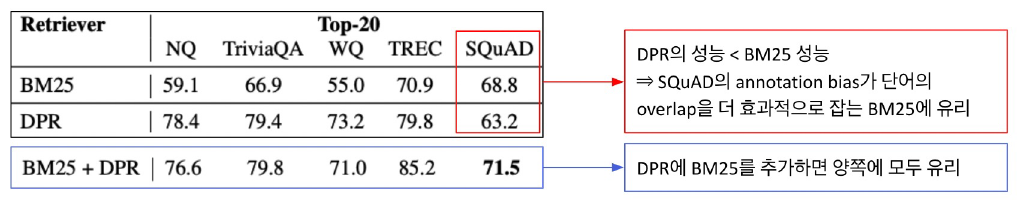
강의소개강의소개8강에서는 Open-domain QA 문제를 풀 때 발생할 수 있는 bias에 대해 배워보겠습니다. Bias는 무엇인지, 어떤 상황에서 발생할 수 있는지 전반적인 내용들에 대해 알아본 후 ODQA를 풀 때 생길 수 있는 여러 측면의 bias에 대해 알아보
9.(9강) Closed-book QA with T5
강의소개9강과 10강에서는 retriever-reader 방법론 외의 ODQA를 푸는 다양한 방법들에 대해 알아보겠습니다. 9강에서는 최근 등장한 T5 모델을 활용한 closed-book QA에 대해 배워보겠습니다. T5의 핵심은 text-to-text format을
10.(10강) QA with Phrase Retrieval

강의소개10강에서는 phrase retrieval을 활용한 real-time oepn-domain question answering에 대해 배워보겠습니다. Phrase 단위로 retrieval한다는 것이 무엇인지 알아보고, phrase retrieval을 수행하는 방법