CV 경량화와 NLP 경량화의 차이점
- Original task -> Target task로의 fine tuning하는 방식이 주된 흐름
- 기본적으로 transformer 구조(CV 대비 구조의 작은 변화)
- Pros
- Large model -> small model 방식의 KD와 좋은 궁합
- 모델 구조가 거의 유사해서, 논문의 재현 가능성이 높고, 코드 재사용성이 높음
- Cons:
- Resource 제한(오랜 학습으로 인한 검증 시간 부족, from scatch 학습에 큰 부담)
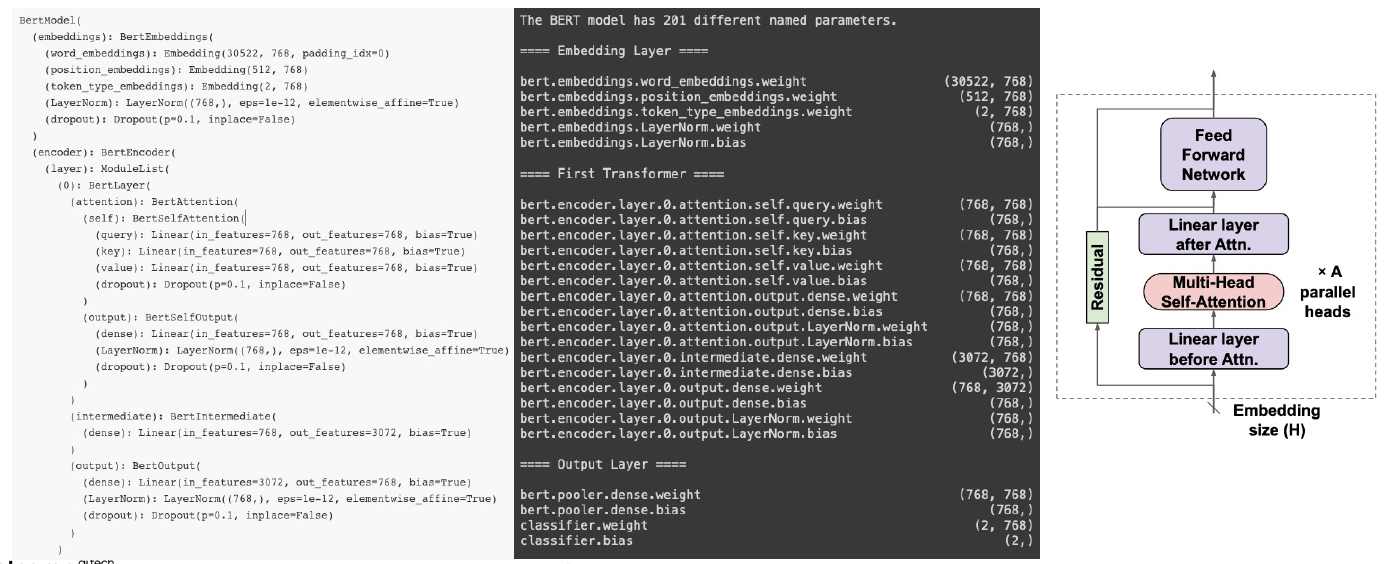
Bert Profiling
- Embedding Dimension = Hidden dimension = 768 차원
- 12개의 Encoder layer
- embedding vector -> Linear layer => Q,K,V vector 출력
- linear layer output -> Multi-Head Self-Attention
- MHA output -> Linear layer
- embedding vector + MHA -> LayerNorm
- LayerNorm output -> Feed Forward Network
- embedding vector + Feed Forward Network -> Encoder output!
- Model size ans computations
- Embedding layer : look up table이므로 FLOPs X
- Linear before Attn : k,q,v mat 연산으로 after 대비 3배
- MHA : matmul, softmax 등의 연산으로 별도의 파라미터는 없음
- FFN : 가장 많은 파라미터 및 연산횟수

DL, NLP Engineer to be....