[BoostCamp AI Tech / Day 12, PytTorch] (04강) AutoGrad & Optimizer
[boostcampAI U stage] week3
torch.nn.Module
딥러닝을 구성하는 Layer의 base class로, Input, Output, Forward, Backward(weights를 autograd) 정의하며, 여기서 이 과정들을 통해 학습이 되는 것을 parameter(tensor)로 지정한다.
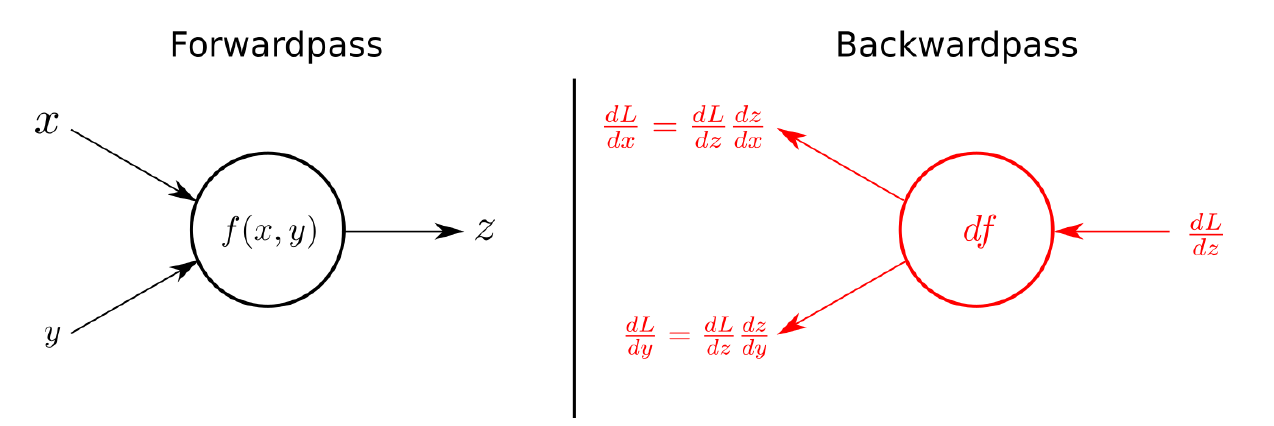
아래와 같이 nn.Module이 할 수 있는 것을 그림으로 보면,
결국 Input이 formula를 통해 Output이 출력되는 forward과정을 우측과 같이 결과를 미분하여 parameter로 정의된 값을 update한다.
nn.Parameter은 무엇일까?
Tensor 객체의 상속 객체로, nn.Module 내에attribute가 될 때 required_grad=True로 자동으로 설정되어 autroGrad의 대상이 되고, 따라서 backward 과정에서 학습 대상이 되는 Tensor이다.
결과적으로 직접 지정해줄 일은 잘 없고 대부분 layer에 weights 값들이 지정되어 있다.
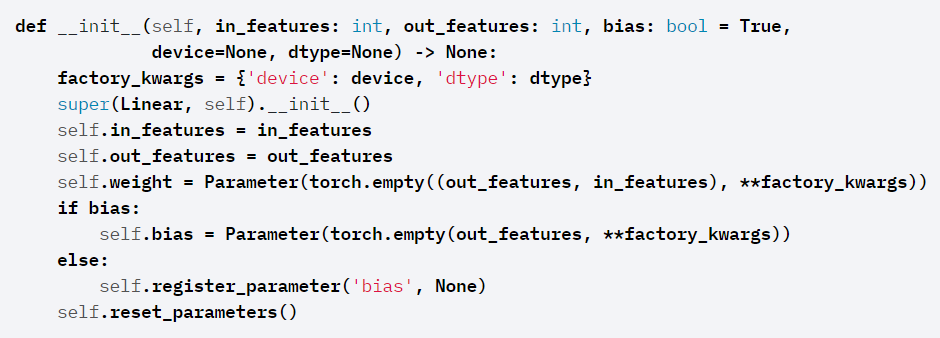
아래 코드는 가장 기본적인 선형 모델이다.
내부 코드를 보면, 결국 in_features와 out_features가 있는데, 여기서 parameter는 (in_features x out_features)로 지정이 되며, 예를 들어 in & out이 7,5이면 weights는 7x5 matrix가 된다. 결과적으로 paramter를 지정하지 않아도 생성이 된다.
그리고 input은 weight와 matrix multiplication을 해야하기 때문에 (n x 7) matrix를 입력으로 받는다.

만약 weights를 임의로 지정한 경우, torch.Tensor() 객체로 선언할 경우
Lieanr 객체를 생성하여 paramters()를 할 경우 아무런 결과도 출력되지 않는다.
반면 weights가 nn.Parameter()로 한 경우에는 weight가 출력이 된다.
왜 그럴까?
정답은, 클래스 인스턴스에 paramters()로 weight를 보는 건 학습 대상이 되는 weight만 볼 수 있다. 따라서 Tensor()로 weight를 지정한 경우에는 아무런 값이 출력되지 않는다.
tmp = MyLinear(7,5)
tmp.paramters() # self.weights가 nn.paramter() //// Tensor()
아래 코드는 pytorch에서 제공하는 nn.linear에 대한 api 문서로,
weight와 bias에 지정된 것을 보면 Parameter임을 알 수 있다. 따라서, 위에서 말한 것 처럼, 실제로 직접적으로 Parameter를 지정해줄 일은 거의 없다.
Backward
Layer에 있는 Parameter들의 미분을 수행하는데, Forward의 결과값(model의 output=예측치)과 실제값 간의 차이(loss)에 대해 미분을 수행하게 된다. 그리고 이 값들을 통해 parameters를 업데이트 한다.
backward 과정은 다음과 같이 정리할수 있다.
optimizer를 zero_grad()로 초기화를 해주고, 예측치와 실제값 간의 loss를 정이하고 이 값을 통해 loss.backward()를 하면 각 loss를 바탕으로 각 weight에 대한 gradient를 계산한다. 그리고 optmizer.step()을 통해 weight가 업데이트 된다.
여기서 zero_grad()를 하는 이유는, gradient 값은 학습이 진행될때마다 계산이 되므로, 현재 상태의 gradient만 구하기 위해 학습이 반복될 때마다 zero_grad()로 초기화를 시켜준다.

backward는 Module 단계에서 backward와 optimizer를 가져와서 오버라이딩 시키면 직접 지정이 가능한데, 다만 사용자가 직접 미분 수식을 기입해줘야 하는 부담이 있다.
