[BoostCamp AI Tech / Day 12, PytTorch] (05강) Dataset & Dataloader
[boostcampAI U stage] week3
강의 소개
이번 강의에선 Pytorch Dataset, Dataloader를 사용하는 방법을 학습합니다. 데이터 입력 형태를 정의하는 Dataset 클래스를 학습하여 Image, Video, Text 등에 따른 Custom Data를 PyTorch에 사용할 수 있도록 학습하고, DataLoader를 통해 네트워크에 Batch 단위로 데이터를 로딩하는 방법을 배웁니다.
본 강의에서는 NotMNIST 데이터를 통해 직접 구현해보는 시간을 가집니다.
Further Question
DataLoader에서 사용할 수 있는 각 sampler들을 언제 사용하면 좋을지 같이 논의해보세요!
데이터의 크기가 너무 커서 메모리에 한번에 올릴 수가 없을 때 Dataset에서 어떻게 데이터를 불러오는게 좋을지 같이 논의해보세요!
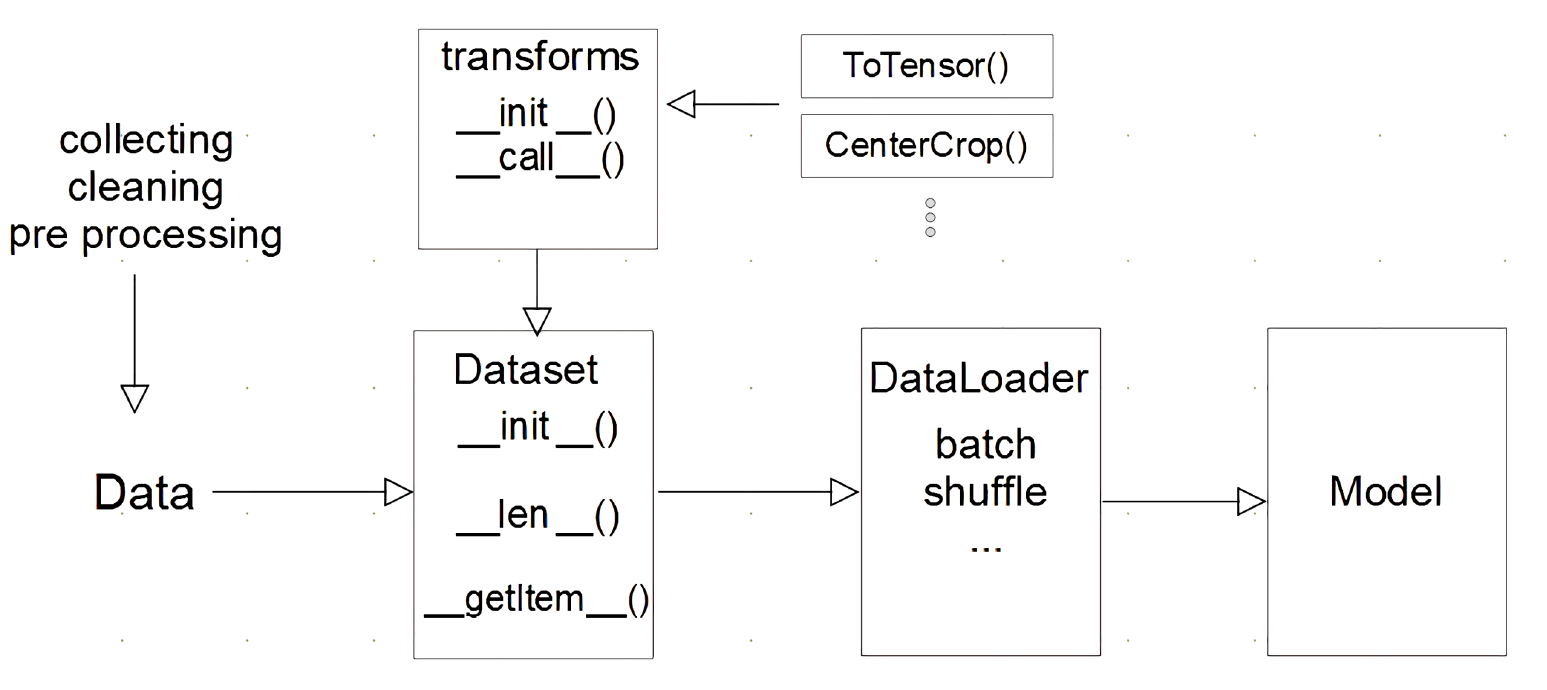
대용량 데이터를 다루기 위해 바닥부터 작성해볼 수 있지만, PyTorch는 대용량 데이터를 다루기 위해 DataSet API를 제공한다.
대용량 데이터를 먹이는(?) 방법
수집한 데이터를 가지고
Dataset 클래스를 가지고, 시작 시 init(데이터를 어떻게 불러올지), len (데이터 길이가 어느 정도 인지), getitem(하나의 데이터를 어떻게 불러와서 반환할 지)를 선언해준다.
transforms은 이미지 데이터를 전처리 하거나 data augmentation 할 때 데이터를 조금씩 변형해줄 때 해당 과정을 처리해주는데, 데이터를 Tensor로 변환(ToTensor())한다.
여기서 기억할 점은, 데이터 전처리 부분과 tensor로 변환해주는 부분은 구분이 되며, 전처리 단계가 아니라 보통 transforms 단계에서 수행해준다.
DataLoader는 Dataset에서 데이터를 어떻게 처리할 지 정의한 다음, 이것들을 묶어서 model에 feeding을 시켜주는데, 보통 batch를 만들거나, batch를 만들 때 데이터를 shuffle해주는 역할을 수행하고
이 과정이 끝나면 model에 데이터들이 들어간다.
DataSet class
- 데이터입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식을 표준화
- Image, Text, Audio 등에 따른 다른 입력 정의
init에서 초기 데이터 생성 방법을 지정하여, 이미지가 있으면, data의 dir를 정의하는 등 labels와 text가 어디서 생성되는지를정의한다.
len은 데이터 전체 길이를 저장한다.
getitem은 idx값을 지정했을 때 거기에 맞는 데이터를 반환해주는데, 일반적으로 classification 문제에선 아래와 같이 dict type으로 반환해준다.

Data class 생성 시 유의할 점
- 데이터 형태에 따라 각 함수를 다르게 정의해야 한다.(image, text, 등등..)
- 모든 것을 데이터 생성 시점에 처리할 필요는 없다.
- image의 Tensor 변화는 학습에 필요한 시점에 변환
- ex) image는 cpu에서 tensor로 변환하고 gpu넘겨서 학습하는 과정으로, 병렬적 처리, 학습 시점에 transforms로 정의
- 데이터 셋에 대한 표준화된 처리 방법 제공 필요
- 후속 연구자나 동료가 편하게 해당 데이터셋 처리가 가능
- 최근에는 HuggingFace, FastAI 등의 도구를 통해 표준화된 라이브러리 사용
DataLoader Class
- Data의 Batch를 생성해주는 클래스
- Dataset은 데이터를 어떻게 불러올지에 대한 정의라면, DataLoader는 어떻게 데이터를 묶어서 model에 넘겨줄지에 대한 정의
- 학습 직전(GPU feed전) 데이터 변환을 책임
- Tensor로 변환 + Batchh 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
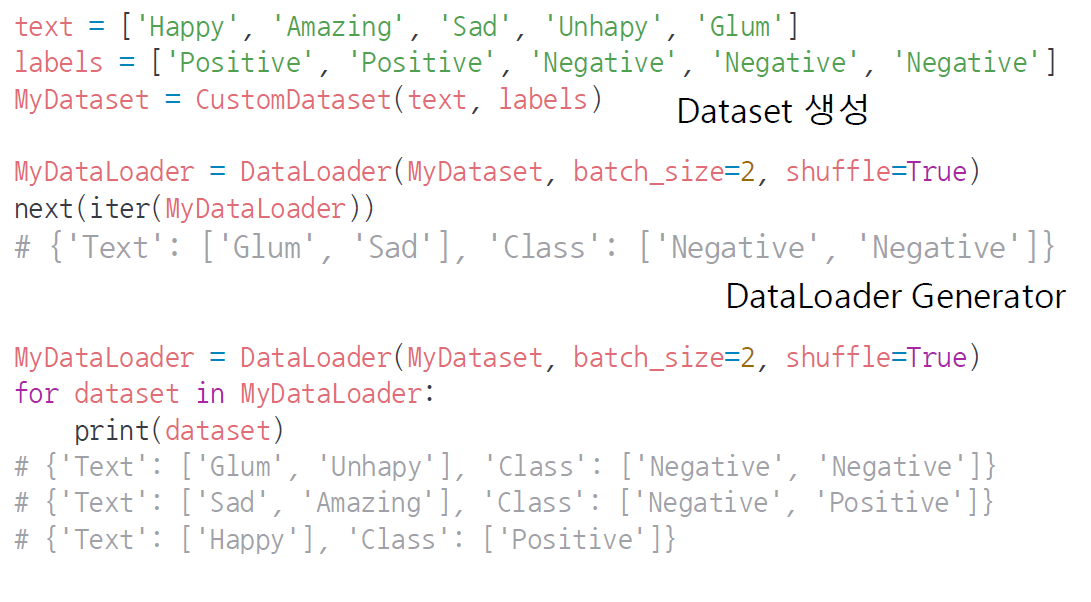
위에서 생성한 Dataset을 Dataloader에 넣어주고, batch_size 및 shuffle augment값 지정
여기서 next(iter(MyDataLoader)) or for dataset in MyDataLoader로 하면, 데이터를 batch_size에 맞게 묶어서 값을 생성해내고, 이 값을 가지고 GPU에 넘겨서 데이터를 학습해준다.
마지막 data는 batch_size만큼 없지만 그대로 데이터를 출력하여
결과적으로 이 예제에선 batch마다 2,2,1 개의 데이터를 호출한다.
Dataloader의 attribute를 보면
- sampler와 batch_sampler는 데이터를 어떻게 추출할지 인덱스를 정해주는 기법으로 (S-stage 및 안수빈님의 github blog 참고, 링크)
- cllate_fn은 데이터 출력 방법을 지정
- variable length의 가변인자 처리시 유용
- batch_size로 부르기에 text 데이터의 경우 글자수가 다를 수 있는데, 이때 padding을 하는 방법들을 적용해주는 등 sequence type data 처리시 유용하게 사용됨

Transforms
아래와 같이 데이터를 Tensor로 변환해주는데, 그 과정에서 데이터를 전처리 후 Tensor로 변환한다.
과정을 보면, image 데이터가 있을 때 224x224 size로 image를 변환하고, numpy image를 tensor image로 변경할 땐 axis 변경이 필요하여 flip을 시켜준 다음, Tensor로 변환하는데,
여기서 Tensor값은 0~1의 값을 가지는데, 이 값을 RGB 각각의 mean, std로 normalize해준다.

