강의 소개
Generalization 성능 향상을 위한 앙상블의 개념에 대해서 알아보고 지금까지 학습된 모델 Weight를 가지고 앙상블 블을 한번 시도해 봅시다.
또한, 경진대회에서 자주 언급되는 K-fold cross validation과 Test Time Augmentation(TTA)에 대해 알아봅니다.
마지막으로, Hyperparameter optimization에 대해서 간략하게 다루겠습니다.
제가 Hyperparameter optimization 관련해서 '시간도 오래걸리고 해봤자 성능 변화도 잘 없고' 라는 말을 시작으로 언급드렸는데요. 오해의 소지가 있을 것 같아서 추가적으로 부연 설명을 드리려 합니다.
Hyperparameter Opt는 적절한 파라미터를 찾기 위해 경우에 따라서는 성능 향상에 비해 돈과 시간과 리소스가 많이 필요한 것은 사실입니다. 하지만 "내 모델의 성능을 최대한 올릴 수 있는 Hyperparameter를 자동으로 찾는다."는 관점에서는 상당히 큰 메리트가 있습니다. 그런 의미에서 최근 급부상하고 있는 AutoML분야에서 이 Hyperparameter Opt는 상당히 중요한 요소중 하나입니다. 아래 Further Reading에서 관련 내용을 한번 읽어보시는걸 추천드려요!
Ensemble
이전까지 과정에서 만들어진 다양한 모델들 중 최고의 성능을 제외하고 다 버리는게 아니라, 모델별 특정 class를 잘 분류하는 모델들이 있다. 따라서 이 모델들을 적절히 합쳐서 더 나은 결과를 만드는 것이 앙상블이다.
앙상블 과정에서 살펴볼 요소는 바로 bias와 variance다. 일반적으로 딥러닝 시 충분한 데이터를 확보한 상태에서 모델을 학습시키므로 overfitting이 잦게 발생하는데, 이 부분은 앙상블을 통해서 어느 정도 해결이 가능하다.
앙상블은 대표적으로 bagging, boosting, stacking이 있다.
여기서, high bias인 경우에는 boosting(lgbm,xgb ...)을 통해 조금씩 성능을 향상시키고,
반대로, high variance인 경우에는 bagging(randomForest)을 통해 정답률을 높일 수 있다.
따라서, 딥러닝에선 각 모델이 가지고 있는 특징을 바탕으로 voting을 통해 개선하는 bagging 방식이 적합하다.
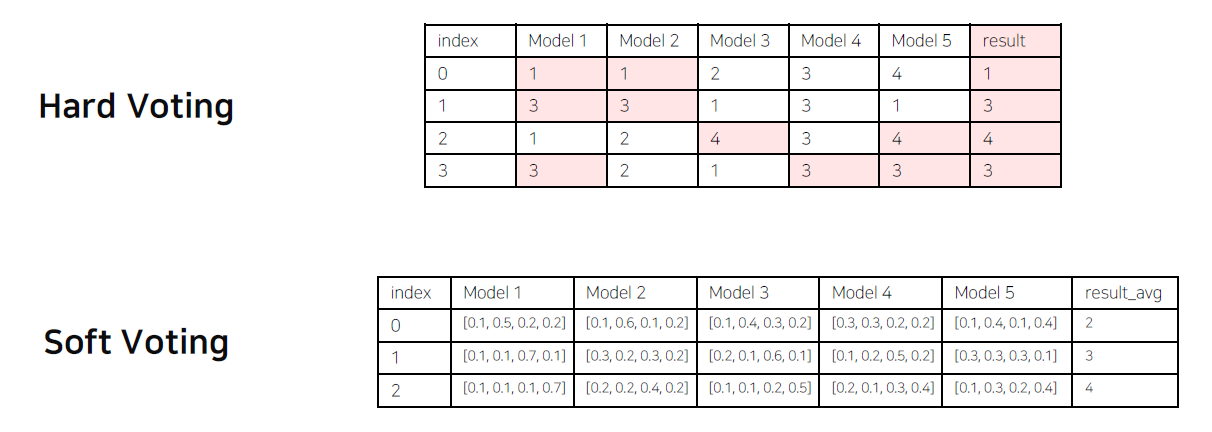
voting 방식은 hard voting vs soft voting이 있다.
- hard voting : softmax로 출력된 class를 count하여 max count인 class로 선택
- 이 방식의 단점은, idx 2번의 답이 2라고 할떄, Model2는 높은 확률로 class 2를 예측했지만, 나머지는 애매한 확률로 다른 것을 예측했는데, 그 경우 이 logits 자체를 고려하지 않으므로 의견이 묵살된다. 따라서 이러한 부분들이 고려되는 것이 아래 soft voting 방식이다.
- soft voting : softmax 전 logits을 가지고 평균을 계산하여 max-avg인 class 선택
Cross Validation
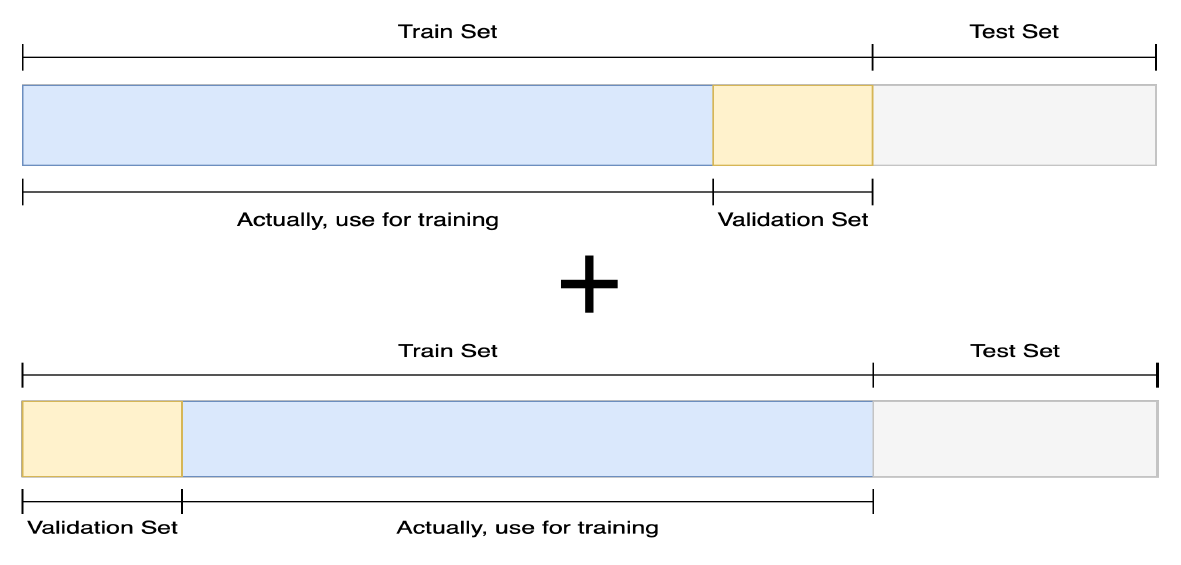
데이터를 검증하기 위해 validation을 나눴는데, 그 데이터 조차 학습에 사용하지 못하는게 아쉬운 상황일 경우가 있다. 이럴 때 사용하는 것이 cross validation이다.
특정 validation set이 있을 때 나머지 데이터로 학습 후 validation set으로 검증한 다음, 다시 validation set을 나누고 학습 및 검증을 반복한다. 이 장점은 학습 데이터와 검증 데이터가 다르므로 보다 일반화 성능을 개선할 수 있다.
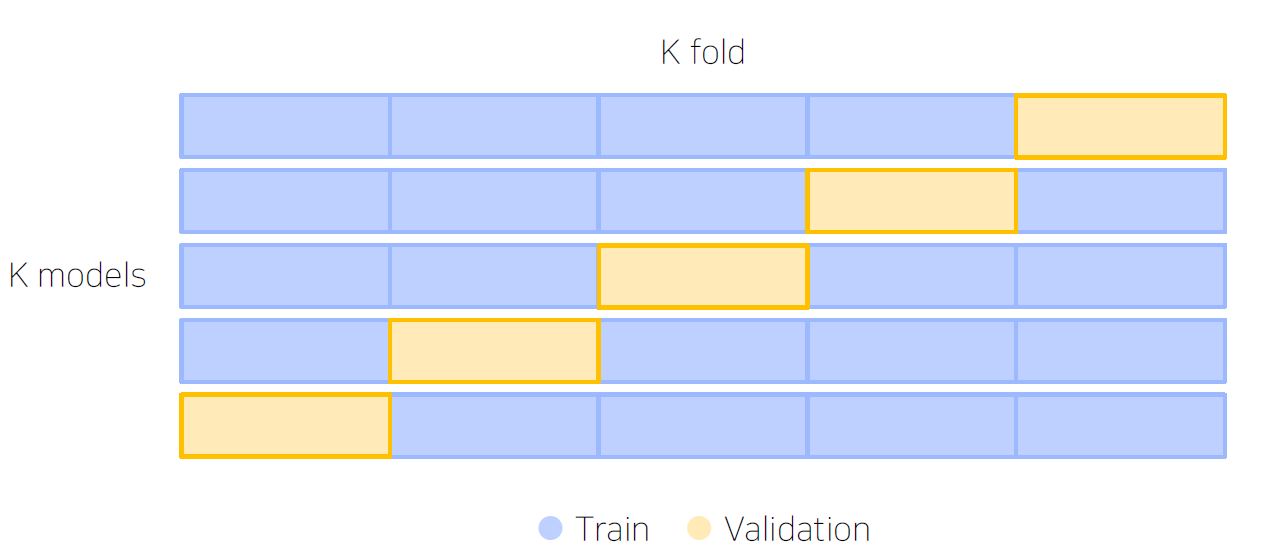
나누는 방법에 대해서도 여러가지가 있는데 아래는 class 분포까지 고려하여 K개로 나눈 방법론이며, Stratified K-Fold Cross Validation이다. 여기서 일반적으로 K는 5 정도부터 시작하여 조금씩 높여 성능을 확인한다.
TTA(Test Time Augmentation)
반대로 테스트 이미지를 Augmentation 후 모델 추론, 출력된 여러가지 결과를 앙상블을 하며, 이것을 TTA라고 부른다. 이 방법이 쓰이는 이유는 간단하다. 테스트 환경 역시 동일하지 않고 특정 noise가 발생할 것이라는 가정에서 시작하였으며, 현재 우리가 학습시킨 모델이 이러한 노이즈가 섞인 데이터도 잘 구별할 지에 대해 확인하는 과정이다.
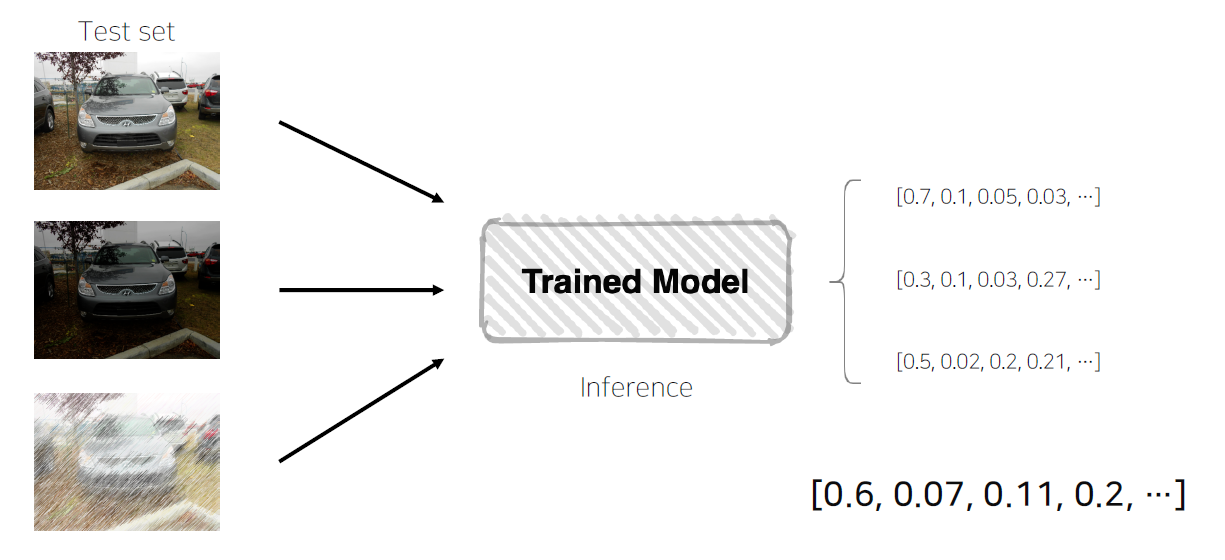
하지만, 단순히 noise가 낀 이미지를 넣고 그것으로 판단하는 것이 아니라, 여러 augmentation을 적용한 동일한 이미지에 대한 logits을 평균을 취하고 이 값을 토대로 softmax롤 통해 최종 class를 반환한다. 이것으로 볼 때 현재 model이 noise 환경에서도 잘 동작한다는 것을 확인할 수 있다.
성능과 효율의 Trade-off
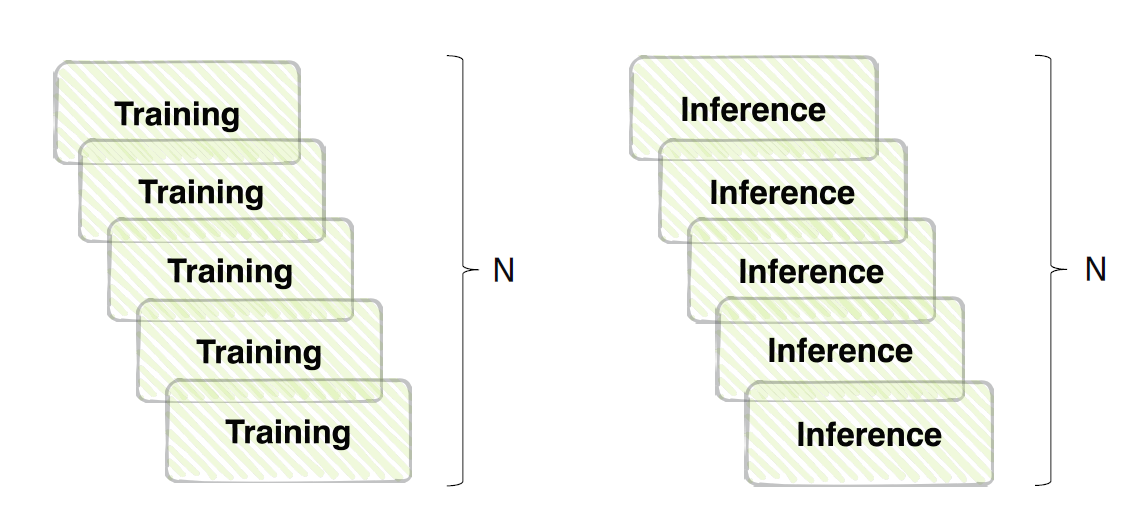
하지만 앙상블 효과는 확실하지만, 그 만큼 학습과 추론 시간이 배로 소모된다. 일반적인 현업에선 성능보단 효율을 중요시하여 앙상블을 잘 사용하지 않지만, 반대로 대회같은 경우 효율보단 성능이므로 최대한 끌어올리기 위해 사용한다. 이처럼 환경에 따라 적절한 사용을 고려해야 한다.
Hyperparameter Optimization
하이퍼파라미터는 시스템의 매커니즘에 영향을 주는 주요한 파라미터이다.
- learning rate, batch size, loss, optimizer, k-fold, dropout, hidden layer 개수 등...
하이퍼 파라미터가 변경될 떄마다 시스템이 조금씩 달라지므로 그에 따른 성능 차이도 발생한다. 따라서 적절한 파라미터를 선정하는 것이 중요하지만, 단 시간이 매우 많이 필요하다. 따라서 서빙 단계에서는 한 번 조정한 하이퍼파라미터는 환경이 변할 때마다 튜닝을 해줘야 하고, 효율을 따져야 하므로 튜닝을 크게 고려하지 않는다.
search 방법은 grid search, random search, bayesian optimization 등이있다.
