기본적으로 다뤄야 할 데이터 타입
- CSV
- html(웹)
- xml
- json
CSV(Comma Separate Value)
- 쉼표(,)로 구분한 텍스트 파일
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식
- 탭(TSV), 빈칸(SSV)등으로 구분해서 만들기도 함
- 통칭해서 character-separated value(CSV) 라고 부름
파이썬으로 CSV 파일 읽기/쓰기
- Text파일 형태로 데이터 처리
- 일반적 Textfile을 처리하듯 파일을 읽어온 후, 한줄 한 줄씩 데이터를 처리
- CSV 객체로 CSV 처리 시
- Text 파일 형태로 데이터를 처리 시 문장 내에 들어가는 "," 등에 대해 전처리 필요
- 파이썬에서는 간단한 csv파일을 처리하기 위해 csv객체를 제공
- 한글로 되어 있는 경우 한글 처리 필요
line_counter = 0 #파일의 총 줄수를 count
data_header = [] #data 필드값을 저장
Kim_data_list = #data 개별 list를 저장하는 list
with open("data.csv") as data: #data.csv 파일을 data 객체에 저장
while True: #True or 1
line = data.readline() #데이터를 한 줄씩 읽어서 line변수에 할당
if not data: break #데이터가 없으면 loop종료
if line_counter == 0: #첫 번째 줄은 데이터 필드
data_header = data.split(",") #","로 데이터를 구분하여 data_header 리스트에 저장
else:
line_to_list = line.split(",")
if "KIM" in line_to_list: #성이 김 인 경우만 저장
Kim_data_list.append(line_to_list) #일반 데이터는 "," 기준으로 분리하여 list형태로 list에 저장
line_counter += 1
print("header :\t", data_header) #데이터 필드값 출력
for i in range(10): #샘플 10개만 데이터 출력
print("Data",i,":\t\t", Kim_data_list[i])
print(len(Kim_data_list)) #전체 데이터 크기 출력
with open("Kim_data_only.csv", "w") as Kim_data_only_csv:
for person in Kim_data_only_csv:
Kim_data_only_csv.write(",".join(person).strip("\n")+"\n")
# Kim_data_list 객체에 있는 데이터를 Kim_data_only.csv 파일에 쓰기
### csv 객체 활용 ###
import csv
reader = csv.reader(f
delimiter = ",", quotechar = '"',
quoting = csv.QUOTE_ALL)
# delimiter : 글자를 나누는 기준
# lineterminator : 줄 바꾼 기준(\r\n)
# quotechar : 문자열을 둘러싸는 신호 문자
# quoting : 데이터를 나누는 기준이 quotechar에 의해 둘러싸인 레벨
data = []
header = []
rownum = 0
import csv
with open("data.csv","r",encoding = "cp949") as file:
csv_data = csv.reader(file)
for row in data:
if rownum == 0:
header = row
else:
data.append(row)
rownum += 1
with open("data.csv","w",encoding = "utf8") as file:
writer = csv.writer(file, delimiter = "\t", quotechar = "'", quoting = csv.QUOTE_ALL)
writer. writerow(header) #제목 필드 파일 쓰기
for row in data:
writer.writerow(row)
웹(Web)
-
Word Wide Web(WWW), 줄여서 웹
-
데이터 송수신을 위한 HTTP 프로토콜 사용 + 데이터를 표시하기 위해 HTTML 형식을 사용
-
Web 동작 순서
- 요청 : 웹주소, form, header 등 서버에 요청
- 처리 : Database처리 등 요청 대응
- 응답 : HTML, XML 등으로 결과 반환(다운로드)
- 렌더링 : HTML, XML 표시
HTML(Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현하기 위한 언어
- 제목, 단락,링크 등 요소 표시를 위한 Tag를 사용
- 모든 요소들은 꺽쇠 괄호 안에 둘러 쌓여 있음
- Hello, World #제목 요소, 값은 Hello, World
- 모든 HTML은 트리 모양의 포함 관계를 가짐
- 일반적으로 웹 페이즈의 HTML 소스파일은 컴퓨터가 다운로드 받은 후 웹 브라우저가 해석/표시
- 웹에 대한 이해의 필요성
- 많은 정보가 웹을 통해 공유가 되며
- 공유된 정보를 바탕으로 다양한 분석을 위해 데이터 추출 방법을 알아야 함
- HTML 구조
# HTML 구조 : <html> - <head> - <title> - <body> - <p>
# Element, Attribute Value 이루어짐
# <tag attribute1 = "att_value1" attribute2 = "att_value2"> 보이는 내용(value) </tag>
<!doctype html>
<html>
<head>
<title>Hello HTML</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>
HTML parsing for 정규표현식
- (정규표현식은 어느 정도 아는 내용이기에 설명은 생략)
import re
import urllib.request
url = url_link #url 값 입력
html = urllib.request.urlopen(url) #url 열기
html_contents = str(html.read().decode("utf8)) #html 파일을 읽고, 문자열로 반환
result = re.findall(찾을 부분에 대한 정규표현식, html_contents) #출력된 데이터는 Tuple 형태XML(eXtensible Markup Language)
- 데이터의 구조와 의미를 설명하는 TAG(Markup)를 사용하여 표시하는 언어
- TAG와 TAG 사이에 값이 표시되고, 구조적인 정보를 표현할 수 있음
- HTML과 문법이 비슷, 대표적인 데이터 저장 방식
- 최근엔 json 형태로 많은 데이터가 공유되지만, 2000년대 초기만 해도 xml 형태를 사용했음
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(메타정보)가 표현되며, 용도에 따라 다양한 형태로 변경 가능
- XML은 컴퓨터(PC<->스마트폰 등) 간에 정보를 주고받기 매우 유용한 저장방식으로 쓰이고 있음
- #XML 구조(트리구조)
<?xml version = "1.0"> <고양이> <우리집 고양이> <이름>나비</이름> <품종>샴</품종> <나이>6</나이> </우리집 고양이> <친구네 고양이> <이름>바다</이름> <품종>페르시안</품종> <나이>5</나이> </친구네 고양이> </고양이> 고양이 /\ / \ / \ / \ 우리집 고양이 친구네 고양이 / | \ / | \ 이름 품종 나이 이름 품종 나이 | | | | | | 나비 샴 6 바다 페르시안 5
xml parcing
- XML도 HTML과 같이 구조적 markup 언어
- beatifulsoup, lxml, html5lib등 여러가지 parcer로 파싱이 가능
- lxml을 이용 시 css 문법으로 특정 요소를 쉽게 가져올 수 있으며
Beautifulsoup보다 성능이 뛰어남
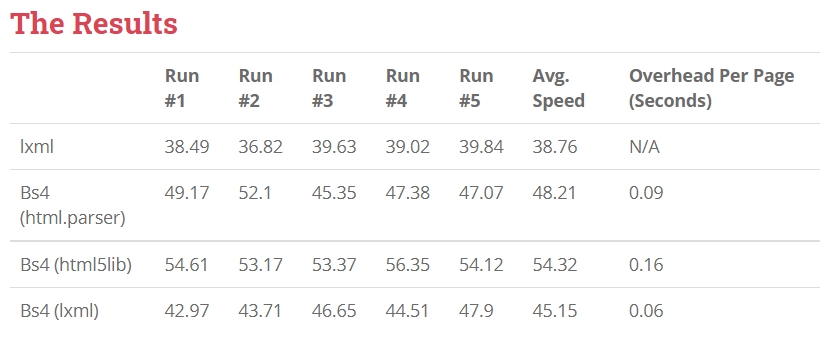
출처 : https://edmundmartin.com/beautiful-soup-vs-lxml-speed/
- 코드 실습은 colab으로 진행
Json
- JavaScript Ojbect Notation
- 원래 웹 언어인 Java Script의 데이터 객체 표현 방식
- 간결성으로 기계/인간이 모두 이해하기 편함
- 데이터 용량이 적고, Code로 전환이 쉬움
- 이로 인해 XML의 대체제 많이 활용되고 있음
- Python의 Dict Type과 유사(Key & value 쌍)
- json 모듈을 사용하여 파싱 및 저장
- read : load, write : dump (with문 과 함께)
- 데이터 저장 및 읽기는 dict type과 상호 호환 가능
- 웹에서 제공하는 API 대부분 정보 교환 시 Json 활용
- 페이스북, 트워터, Github 등 거의 모든 사이트가 json 활용
- 실습 코드는 생략

DL, NLP Engineer to be....