- 시계열, 즉 sequence 데이터에 유용하게 사용됌
- 종속적인 데이터에 대해 어떻게 데이터를 설계하는지에 대해 학습
- 각 모델별 구조 파악
시퀀스 데이터
-
소리,문자,주가 등 데이터를 시퀀스(sequence) 데이터로 분류
-
시계열(time-seies) 데이터는 시간 순서에 따라 나열된 데이터로 시퀀스 데이터에 속함
-
시퀀스 데이터는 독립동일분포(i.i.d) 가정을 위배하기 때문에 데이터 순서 변환, 과거 정보 손실 등이 발생 시 데이터 확률분포도 변함
- 과거 정보 또는 앞뒤 맥락 없이 미래를 예측하거나 문장을 완성하는 건 불가능
-
이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부 확률을 이용
- .
-
일반적으로 모든 데이터가 분석에 영향을 주는 것이 아닌 만큼 일정 데이터를 중점적으로 분석을 진행
-
만약, 이전의 일부 고정된 길이만큼 시퀀스만 사용하는경우 AR(Autoregressive Model) 자귀회귀 모델 이라고 함
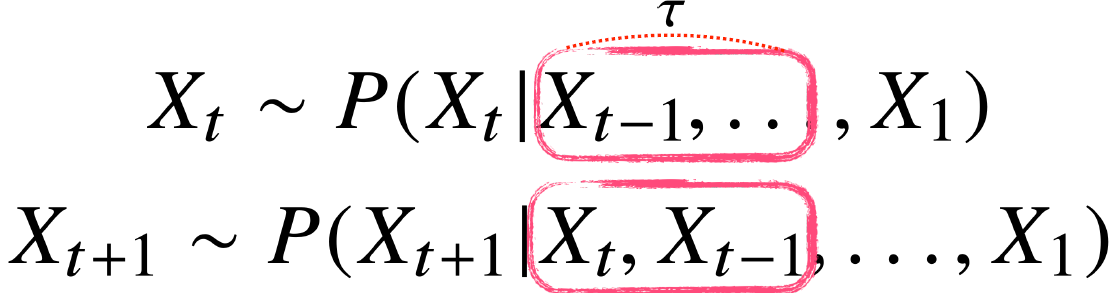
-
반대로, 먼 미래의 정보를 다 사용하는 경우 이전 정보를 제외한 나머지를 (잠재변수)로 인코딩하여 활용하는 모델을 잠재 AR모델 이라고 함
- 이 경우도 과거의 모든 데이터를 와 바로 이전 정보 로 하여 가변 길이의 정보를 고정 길이 문제 전환
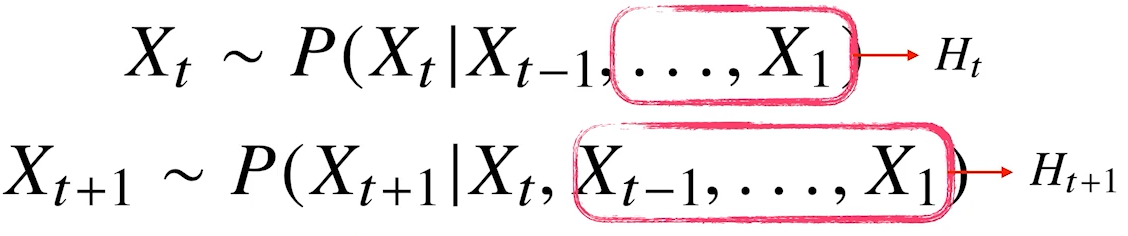
RNN
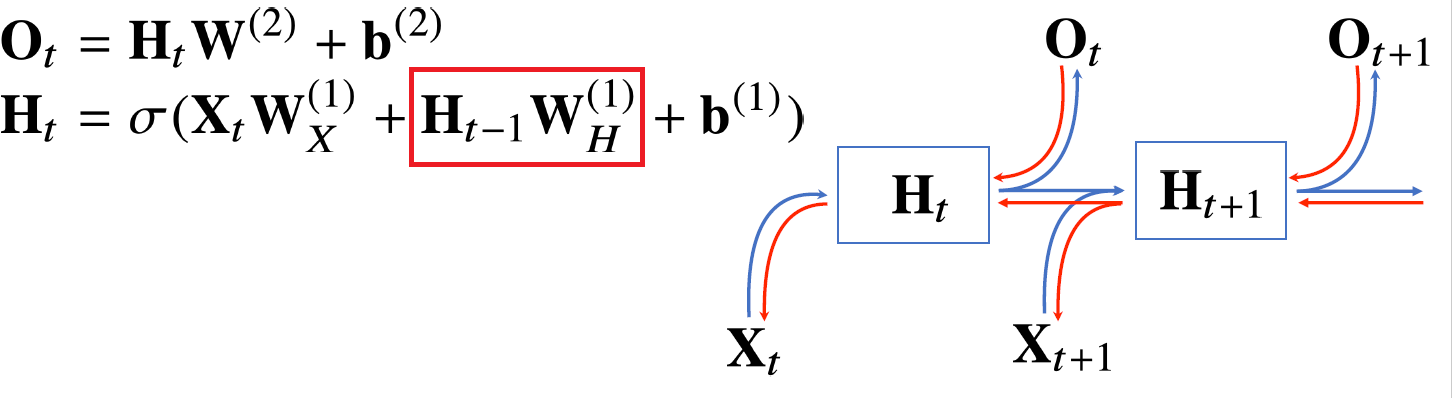
- RNN은 기본적으로 MLP와 유사하지만 항을 추가하여 이전 정보를 추가로 고려하여 이후 데이터를 예측하는데 영향을 주도록 설계
- 과정 중간에 들어가는 는 시점에 따라 변하지 않는 불변인 가중치 행렬
- RNN의 역전파는 BPTT(BackPropagation Through Time)이라고 부르는데, 마지막 시점의 gradient부터 첫번째 시점까지 순차적으로 연산을 진행
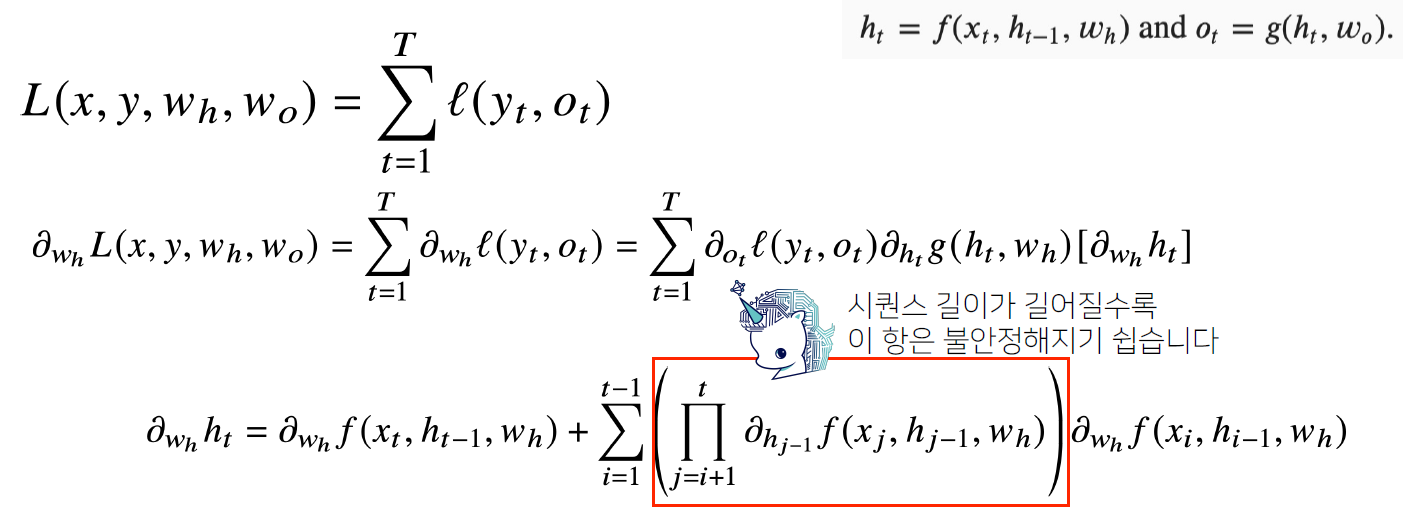
- BPTT를 통해 가중치 행렬에 대한 미분을 계산 시 저렇게 곱해지는 하나의 항이 나오는데, 1보다 커지면 발산하기 쉽고 1보다 작으면 0이 될 수 있으며 음수면 진동할 수 있음
- 매우 불안정한 항이므로 일정 길이를 끊어서 사용하는 방법을 truncated BPTT라고 하며, 이 방법을 통해 gradient vanishing 문제를 일부 해결할 수 있음
- 따라서 이를 극복하기 위해 GRU나 LSTM과 같이 메모리 게이트를 추가한 새로운 모델이 등장
!! 1주차 끝!

DL, NLP Engineer to be....