한국어 언어 모델 학습 및 다중 과제 튜닝 - (3강) BERT 언어모델 소개 & (4강) 한국어 BERT 언어 모델 학습
[boostcampAI P stage] week 9-10
강의 소개
BERT는 Bidirectional Encoder Representations from Transformers의 약자로 구글이 공개한 인공지능 언어 모델입니다.🤩
BERT는 주어진 Mask에 대하여 양방향으로 가장 적합한 단어를 예측하는 사전 언어 모델입니다.
이번 강의에는 BERT의 내부 구조에 대해 간략하게 알아보고, BERT를 활용하여 해결할 수 있는 다양한 자연어 처리 Task에 대하여 알아봅니다.🤩
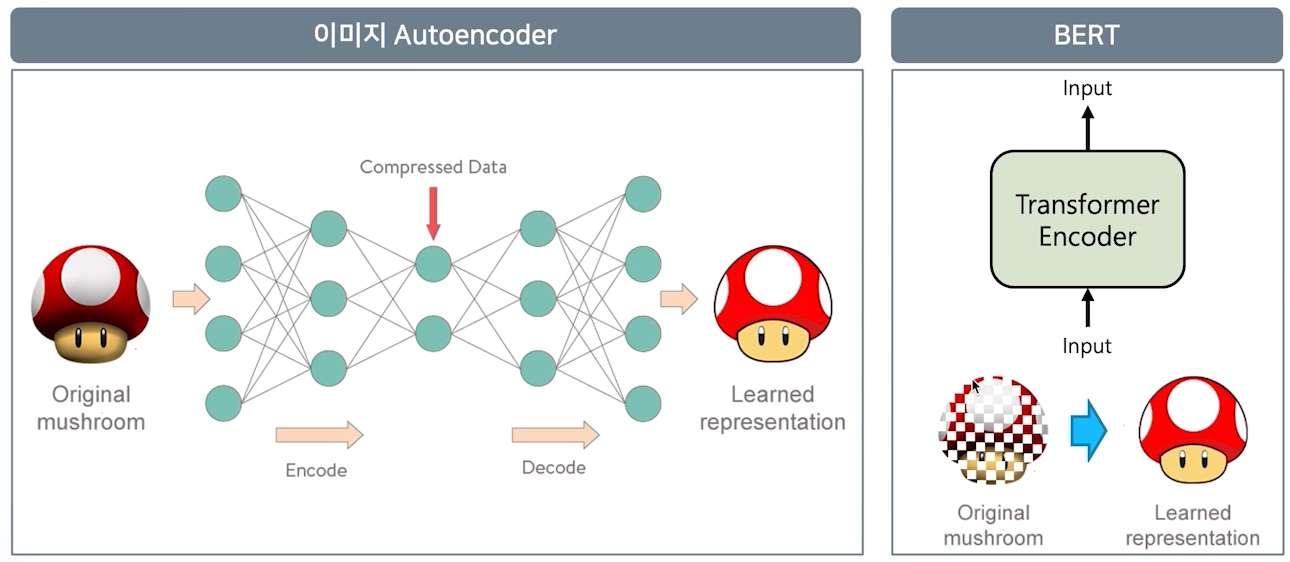
이미지 분야에서는 Audoencoder라는 모델이 있고, encoder와 decoder로 구성되어 있다.
이 구조에서 encoder는 이미지를 압축된 형태로 표현하는게 목적이고, decoder는 원복을 그대로 복원하는게 목적이다.
BERT는 self-attention(transforemr encoder)로, 입력된 정보를 다시 입력된 정보로 representation되게 학습이 진행된다. 단 masking 기법을 적용하여 원본을 복원하는 과정의 난이도를 부여하여 더 확실히 학습하게 만든 모델이다.
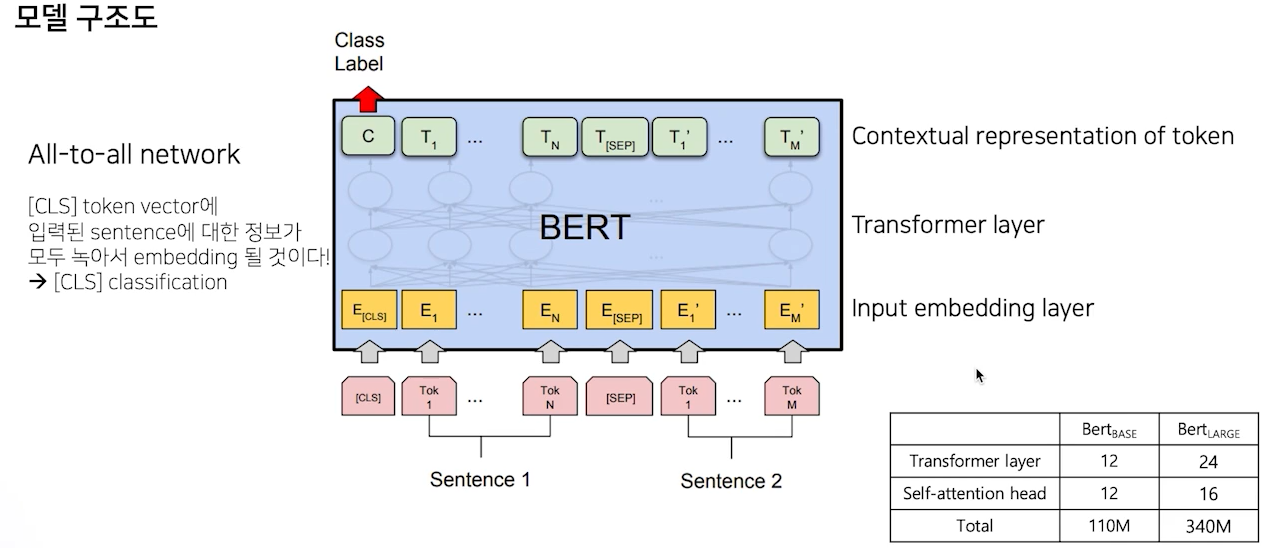
bert의 input layer는 cls + sentence1 + sep + tokens of sentence2로 이루어져 있으며, 12개의 layer로 구성(base model)로 구성되어 있으며, CLS는 sent1과 sent2가 next sentence 관계인지 학습을 진행한다.
- 학습 코퍼스 데이터는 BookCorpus, English Wikipedia를 사용했다.
- Tokenizer는 workpiece tokenizer를 사용하고, token sequence로 학습이 진행된다.
- 이후 마스킹 과정(전체의 15%)을 통해 특정 token을 [mask]로 바꿔주준다.
- 이것을 기준으로 전체 학습이 진행되고, 두 문장의 관계에 대해선 CLS token 이후 Dense layer가 추가되어 해당 문장의 관계에 대해 학습한다.
BERT는 GLUE benchmark를 활용하여 성능을 측정하고 구성은 다음과 같다.
- MNLI, QQP, QNLI, SST-2, CoLA, STS-B, MRPC, RTE, WNLI
- 추가로 SQiAD, CoNLL, SWAG
다양한 task가 있지만, 아래 4개의 모델로 전부 커버가 가능하다.
- 단일 문장 분류
- 한개의 문장이 어떤 class에 속하는지
- 두 문장의 관계 분류
- next sentence, 한 문장이 다른 문장의 가설이 되는지, 두 문장의 유사도 등
- 문장 토큰 분류
- NER
- 기계 독해 정답 분류
- 질문에 답변의 구간을 찾아내는 task
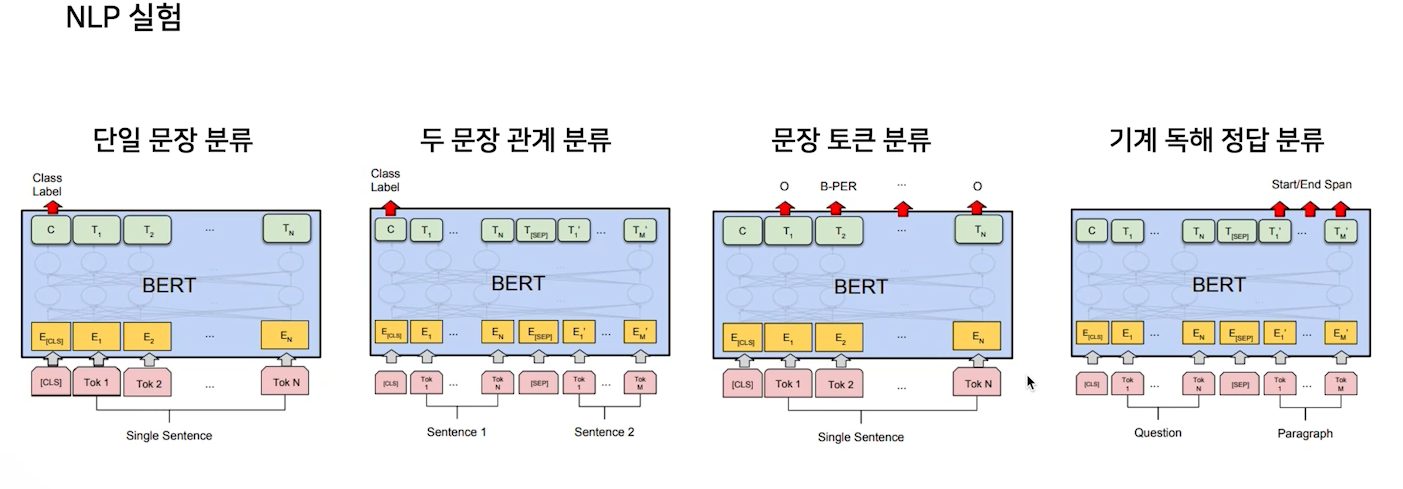
- 질문에 답변의 구간을 찾아내는 task
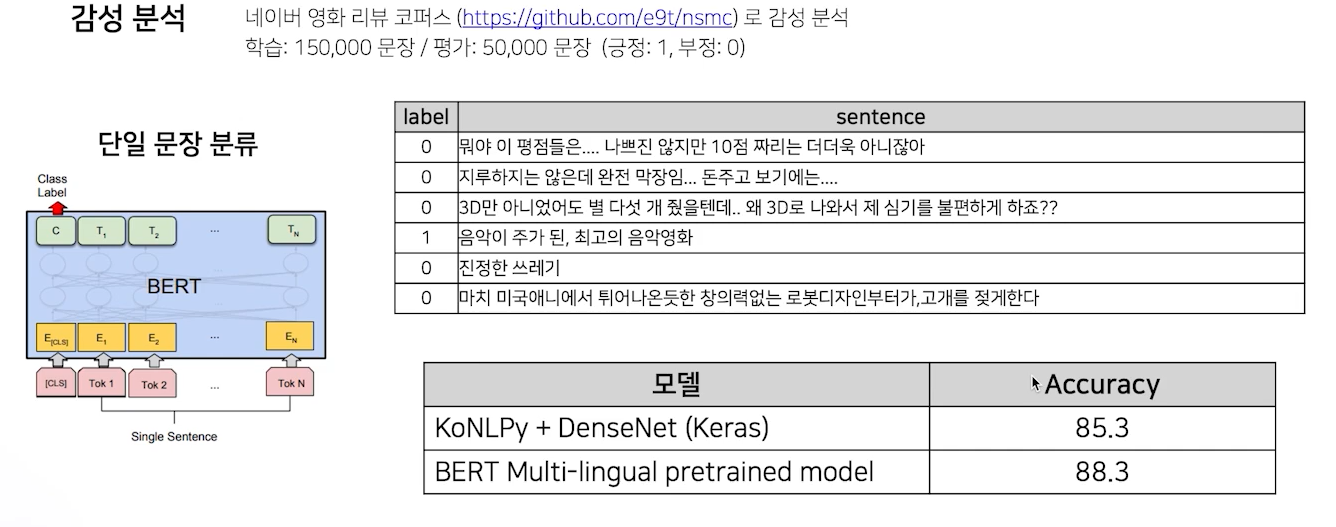
우선 단일 분류 모델로 수행하는 것중 감성 분석 task이다.
주어진 sentence에 대해 긍정/부정을 판단하는 테스크이다.
또 다른 예로는 관계 추출이다. 주어진 문장 내에서 지식 정보를 추출하는 것인데, subject entity와 object entity의 관계를 예측하는 task이다.
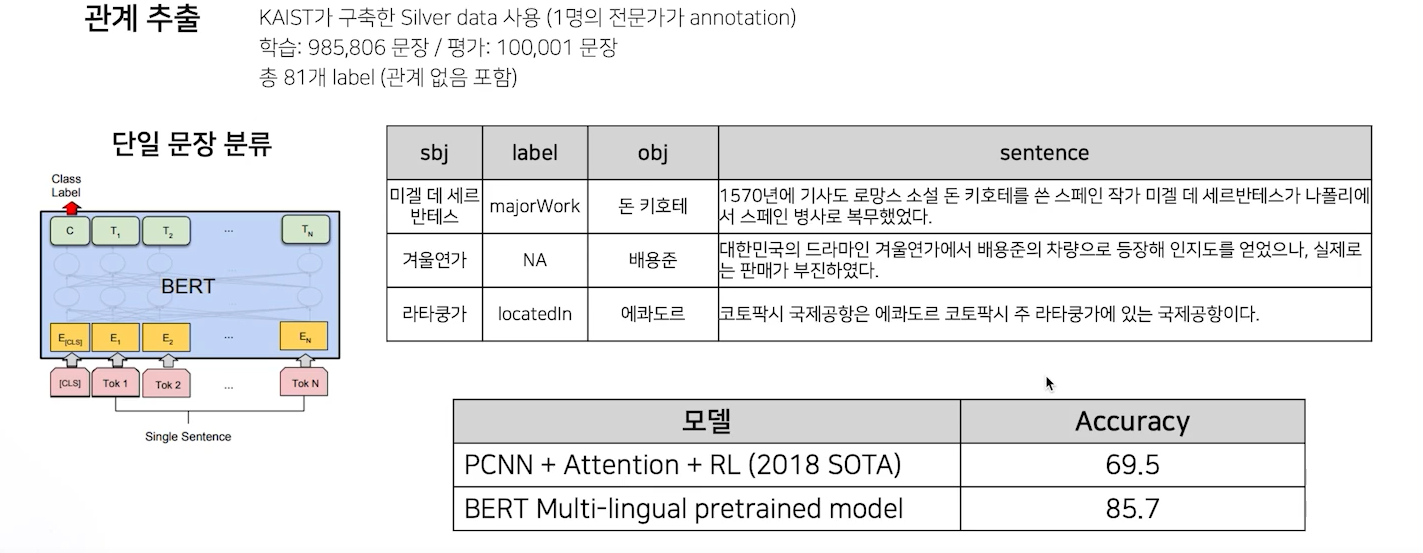
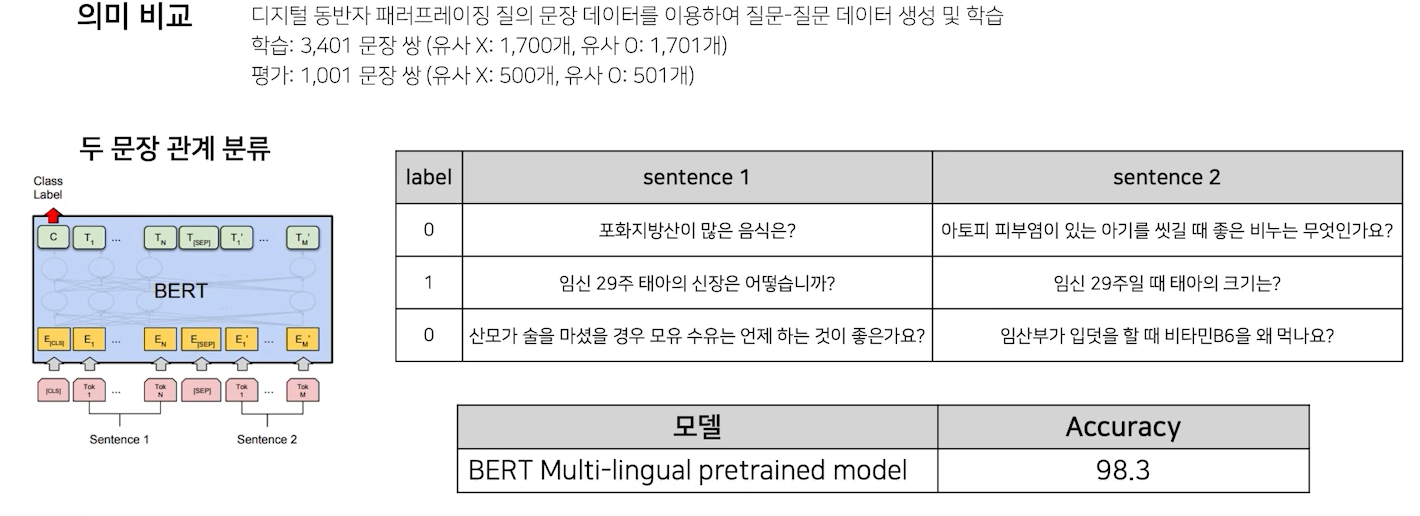
다음은 의미 비교 task이다.
단 이 task에서 문제는, 예시를 보면, 너무 상관없는 질문이 input으로 들어왔음을 알 수 있다. 이는 전처리 문제로, 실제 우리가 분류할 문제는 굉장히 의미가 유사한 문장 관계를 분류하는 것이다. 따라서 데이터 설계를 잘해서 학습을 진행하다.
이후 다양한 버트 모델의 응용이 있다.
이 이후 과정은 실습으로 따로 해당 글에선 다루지 않을 예정이다.
강의 소개
이번에는 3강에서 소개한 BERT를 직접 학습하는 강의입니다.
다양한 언어 모델들을 활용하고 공유할 수 있는 Huggingface Hub에 대해 소개하고, 직접 본인의 모델을 공유하는 실습을 진행합니다.🤓
reference
- LM training from scratch
- 나만의 BERT Wordpiece Vocab 만들기
- Extracting training data from large language model
- BERT 추가 설명
Bert 학습단계!!
- Tokenizer 만들기 - 데이터셋 확보하기-> 학습(NSP,Masking)
이미 있는 거 쓰지, 왜 새로 학습해야 해요?
도메인 특화 task의 경우 도메인 특화된 학습 데이터만 사용하는 것이 성능이 더 좋다고 합니다.
우선 학습을 위한 데이터를 만들자
- 학습을 위한 데이터를 데이터 셋 형태로 만들어야 한다.
- 모델을 학습할 때는 두 가지 기준이 있는데 바로 dataset과 dataloader이다.
- dataset은 모델의 input 형태로 만들어 주는 것이고
- dataloader는 input을 어떻게 넣어주는지에 대한 것이다.
- BERT 기준으로 input 형태는 input_ids, token_type_ids, position_ids이다.
나머지는 실습을 통해서 할 예정이고 따로 작성은 안한다!
