[boostcampAI P stage] week 9-10
1.한국어 언어 모델 학습 및 다중 과제 튜닝 - (1강)인공지능과 자연어 처리
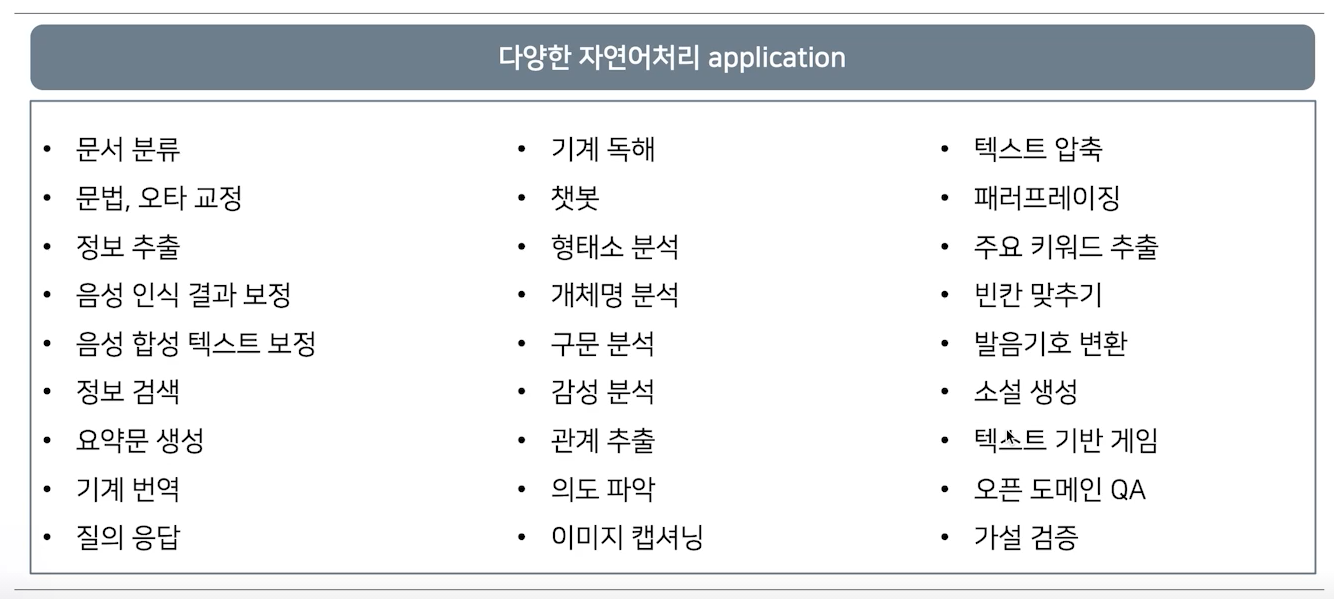
강의 소개이제 본격적으로 자연어처리 공부를 시작해보겠습니다! 🥰 인공지능이 발전함에 따라 자연어와 관련된 여러 Task들을 해결할 수 있게 되었습니다.이번 강의에는 인공지능의 발전이 어떻게 자연어 처리 분야에 영향을 주고 발전하게 되었는지 알아봅니다.또한 앞으로의 과
2.한국어 언어 모델 학습 및 다중 과제 튜닝 - (2강) 자연어의 전처리

강의 소개인공지능에서 가장 중요한 데이터!! “Garbage in, garbage out” 이라는 말이 있습니다.일반적으로 좋은 데이터를 학습해야 좋은 성능의 모델을 기대할 수 있습니다.또한 데이터 전처리는 단순히 '정제' 의 개념이 아니라, 어떤 문제를 해결하겠다는
3.한국어 언어 모델 학습 및 다중 과제 튜닝 - (3강) BERT 언어모델 소개 & (4강) 한국어 BERT 언어 모델 학습
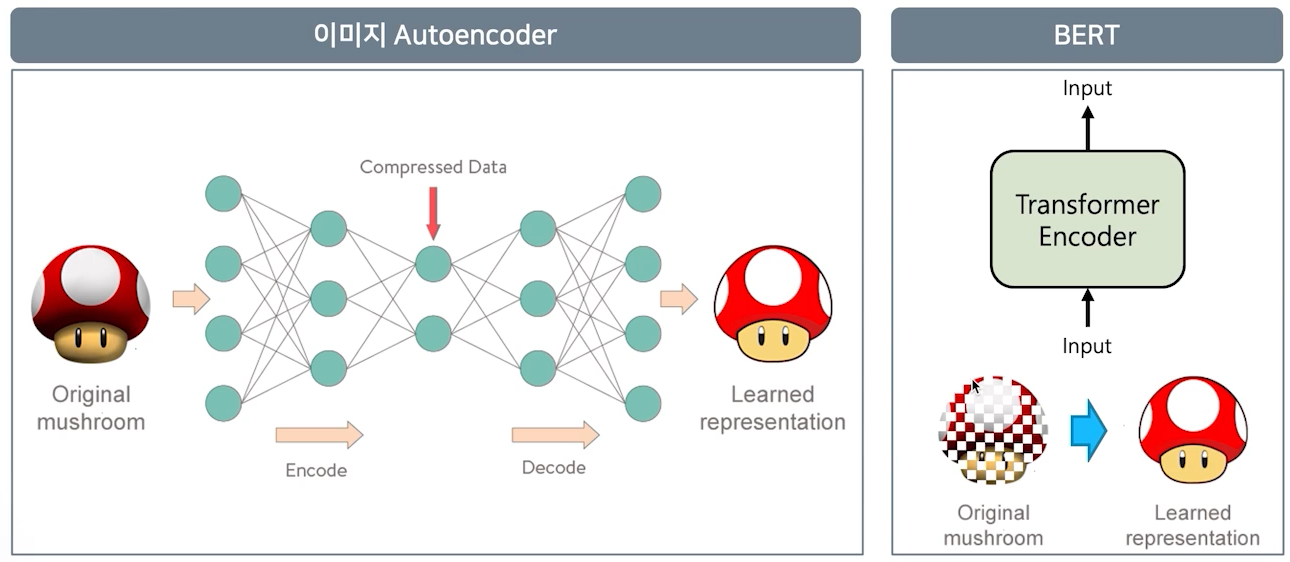
강의 소개BERT는 Bidirectional Encoder Representations from Transformers의 약자로 구글이 공개한 인공지능 언어 모델입니다.🤩BERT는 주어진 Mask에 대하여 양방향으로 가장 적합한 단어를 예측하는 사전 언어 모델입니다.
4.한국어 언어 모델 학습 및 다중 과제 튜닝 - (5강) BERT 기반 단일 문장 분류 모델 학습
강의 소개3강에서 배운 BERT를 가지고 자연어 처리 Task를 해결해 봅니다. 🧐단일 문장 분류 모델은 주어진 문장에 대하여 특정 라벨을 예측하는 것입니다.활용 분야로는 리뷰의 긍정/부정 등의 감성 분석, 뉴스의 카테고리 분류, 비속어 판단 모델 등이 있습니다.Re
5.한국어 언어 모델 학습 및 다중 과제 튜닝 - (6강) BERT 기반 두 문장 관계 분류 모델 학습
강의 소개3강에서 배운 BERT를 가지고 자연어 처리 Task를 해결해 봅니다. 🥴두 문장 관례 분류 모델 학습은 주어진 두 문장에 대하여 두 문장에 대한 라벨을 예측하는 것입니다.5강의 단일 문장 분류 모델과의 가장 큰 차이점은 Input 문장의 개수입니다.두 문장
6.한국어 언어 모델 학습 및 다중 과제 튜닝 - (7강) BERT 언어모델 기반의 문장 토큰 분류
강의 소개이번 강의에서 소개하는 문장 토큰 분류 모델은 전체 문장에 대한 하나의 라벨이 아닌, 각 토큰에 대한 라벨을 예측합니다. 😀활용 분야로는 POS-tagging, NER 등이 있습니다. 😁문장 토큰 관계 분류 task주어진 문장의 각 token이 어떤 범주에
7.한국어 언어 모델 학습 및 다중 과제 튜닝 - (8~9강) GPT 언어 모델
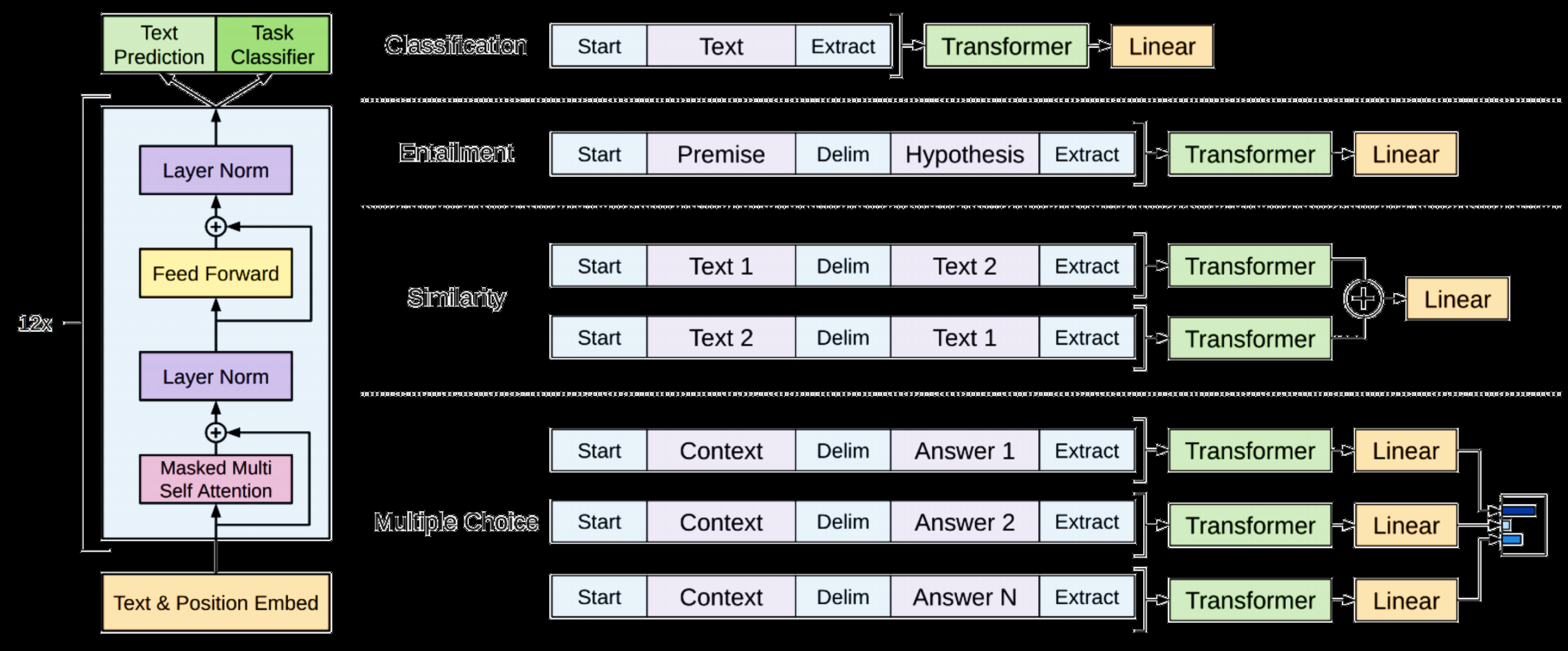
강의 소개GPT는 Generation Pre-trained Transformer의 약자로 OpenAI에서 공개한 모델입니다. 😄BERT와 가장 큰 차이점은 GPT는 단일 방향으로 주어진 단어 다음에 가장 올 확률이 높은 단어를 예측하는 모델입니다.🤣Generatio
8.한국어 언어 모델 학습 및 다중 과제 튜닝 - (10강) 최신 자연어처리 연구
강의 소개드디어 KLUE 강의의 마지막 강의입니다.지금 이 순간에도 더 좋은 성능을 갖는 모델을 만들기 위해 많은 연구자들이 RoBERTa, XLNet, BART, T5 등등, 다양한 실험과 새로운 알고리즘을 개발하고 있습니다. 🤗최신 언어모델 관련 연구 트랜드를 살
9.Pstage-2 KLUE Relation Extraction

AUPRC : 82.295점, 19개 팀 중 4등micro F1 score : 73.069점, 19개 팀 중 7등대회 개요Task : Relation extraction - subject와 object entity간 관계 예측기간 : 21.09.27 10:00 ~ 2