8강의 소개
GPT는 Generation Pre-trained Transformer의 약자로 OpenAI에서 공개한 모델입니다. 😄
BERT와 가장 큰 차이점은 GPT는 단일 방향으로 주어진 단어 다음에 가장 올 확률이 높은 단어를 예측하는 모델입니다.🤣
Generation 분야에 강점을 가지고 있는 모델입니다.
Reference
- GPT : Language Understanding
- GPT-2 : Language Models are Unsupervised Multitask Learners
- GPT-3 : Language Models are Few-Shot Learners
- 언어 모델의 학습법 : Week 19 - 언어 모델을 가지고 트럼프 봇 만들기?!
9강의 소개
이번 강의에는 8강에서 배운 GPT를 활용하여 이전 강의에서 실습한 BERT로 만든 챗봇과는 다른 방법으로 챗봇을 실습합니다. 이번 강의를 통해 두 개의 방법이 어떻게 다르고, 어떻게 활용하는지 생각해봅시다!😝😛
+)
채팅 데이터가 정말로 많다면 훨씬 자연스러운 챗봇이 나올 수 있겠죠?
그래서 보통 가장 경쟁력 높은 챗봇을 개발한 기업/연구진을 보면, 엄청나게 많은 채팅 데이터를 보유하고 있습니다 🤤
+)
자신만의 채팅 데이터를 추가해서 챗봇을 만들어보세요!
학습 데이터에 따라 persona가 다양한 챗봇도 개발할 수 있을 것입니다 🤗
1:1로 대화한 카톡 데이터를 활용해볼 수도 있겠죠?
Reference
-
chitchat
-
GPT-2 Classification
-
Generate dataset from language model
BERT vs GPT
- BERT : 자연어 임베딩 모델
- GPT : 자연어 생성 모델
GPT Model
- Transformer의 decoder를 사용한 모델
- 이전 timestep에서 예측한 단어를 현재 timestep의 input으로 사용하여 단어를 예측
- RNN과 마찬가지로, input sequence의 context vector를 출력하고, linear layer를 통과시켜 분류 테스크에 적용하기 위해 만들어진 모델
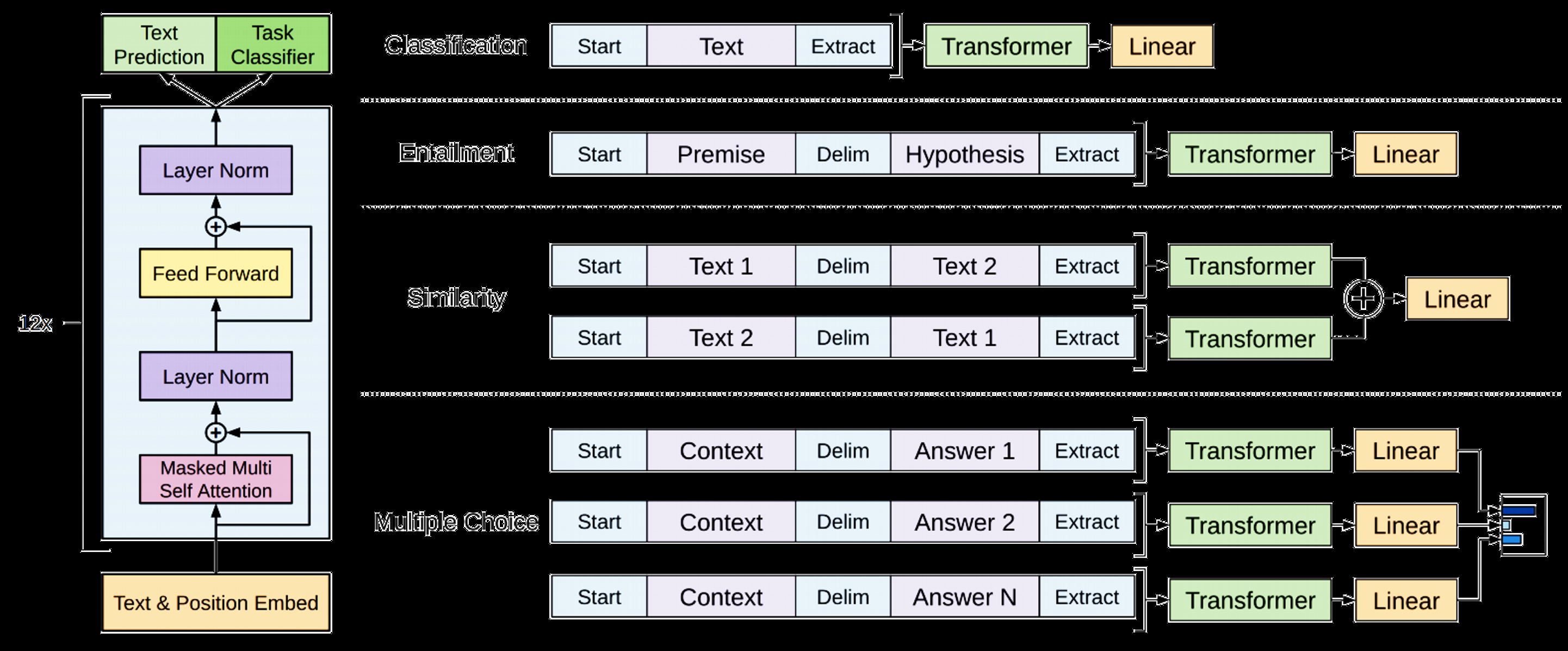
- "자연어 문장-> 분류" 성능이 아주 좋은 디코더인 GPT
- Pre-train - fine-tune을 통해 적은 데이터로도 높은 분류의 성능을 나타냄(BERT의 밑거름)
- 그 결과 다양한 task에서 SOTA 달성
- 하지만 여전히 supervised-learning이며, fune-tuning된 모델은 다른 task에 사용 불가
하지만, GPT를 개발한 연구진들은 다음과 같은 생각을 했다.
언어의 특성 상, 지도학습의 목적함수와 비지도학습의 목적함수는 같으므로 굳이 fine tuning을 할 필요는 없다!!
fine-tuning에서 사용되는 label 자체도 언어이므로, 대용량의 데이터를 학습하면 그 안에서 다양한 task에 대해 학습하는 것과 동일하다고 판단하였다. 따라서, 이 가정을 바탕으로 다음 모델들을 개발을 하였다.
연구진들은 다음과 같은 과정이 불필요하다고 판단하였다.
사람의 경우 특정 task를 학습하기 위해 많은 양의 데이터를 필요로 하지 않다. 예를 들어, 특정 문장에 대해 감정을 분류할 경우 이 문장이 기쁨/슬픔/놀람 등을 태깅하면서 학습하지 않는다.
또 다른 문제점으로, 대용량의 데이터를 학습하여 pre-trained model을 만들었는데, "fine-tuning을 통해 하나의 task만을 수행하는 모델을 만드는 건 비효율적이다"라는 의견을 냈다.
그래서 zero-shot, one-shot, few-shot 같은 방법을 제안하였다.
기존 학습의 경우 특정 downstream task에 적용하기 위해 fine-tuning 과정에서 gradient를 update하여 최적화를 시켰다.
하지만 @-shot에선, 단순하게 해당 task에 대한 description과 몇 가지 예시를 입력함으로써 모델에게 어떤 task임을 알리고 prompt를 입력하여 결과를 출력한다. 여기서 zero-shot은 예시가 없고, one-shot은 한 개의 예시가, 그리고 few-shot은 여러 개의 예시가 사용된다.

이러한 방법과 함께, 11GB의 데이터로 학습하고, 모델 파라미터 개수를 10배이상 늘린 GPT-2 모델을 만들어냈으며, GPT-2 모델은 기계독해, 요약, 변역 등의 자연어 task에서 일반 신경망 수준까지 성능을 끌어올렸다.
여기서 멈추지 않고, GPT2의 파라미터를 100배 이상, 그리고 학습 데이터를 기존 40GB에서 570GB까지 늘려서 학습을 시켜 GPT-3 Model을 만들어냈다. GPT2와 유사하게 transformer의 decoder 구조를 사용했지만 조금은 변형시켜 사용하였다.(이 부분은 따로 논문을 읽고 작성할 예정이다.)
그리고 다양한 TASK에서 매우 높은 성능을 보였음을 찾아볼 수 있다.
하지만 GPT-3가 만능일까?
GPT 계열 모델은 특정 task에 대해 학습을 하지 않으며, 기존 train 시 사용된 corpus를 기준으로 task를 수행한다. 그렇다면 다음과 같이 문제점을 들 수 있다. 첫 번째로, weight update가 없으므로 새로운 지식 학습이 없다. 두 번째로, 시기에 따라 달라지는 문제에 대응이 불가하다.
지금까지는 모델 구조를 개선하고, 모델과 학습 데이터 크기를 늘리므로써 성능을 개선했지만, 이 점이 최선일까 하는 의문도 든다. 또한, 정보는 단순히 글로만 배우는 게 아니므로 Multi modal에 대한 정보도 필요로 한다.
이후는 실습이므로 내용은 여기까지만 다룬다.
단, 실습에서 배운 것 중 한가지 알고가야 할 부분이 있다.
일반적으로 pre-training model을 가져와서 사용할 떄, tokenizer도 가져오지만, 만약 special token을 추가할 경우? add_special_token method를 이용하면 된다. 단, tokenizer를 저장할 때 save와 save_model이 있는데 두 가지는 조금 차이가 있다.
- save : tokenizer 자체를 저장하여 tokenizer 정보에 대한 소실이 없다.
- save_model : tokenizer dictionary 자체를 저장하므로 어떤게 새롭게 추가된 speecial token인지 등을 알 수 없다. 따라서 불러올 경우 다시 add_special_token을 거쳐야 한다.
이번 강의를 들으며, 아무리 최신 모델이고, 성능이 좋다 하더라도 한계가 있음을 또 한 번 알게 되었다. 하지만 반대로 이 점을 강점으로도 판단할 수 있다고, 개인적으로 생각한다. 어느 정도 시간이 지나면 과거 정보에 대해 일부는 소실되는 문제가 있다. 하지만 GPT-3 모델은 특정 시점의 정보만을 학습했기에 해당 정보가 소실되는 문제는 없다. 나처럼 과거를 좋아하고 기억하고 싶어하는 사람에게는 한 가지 추억이 될수도...? 라고 그냥 재미 삼아 생각해보았다.
여튼, 앞으로 자연어 엔지니어로써 현재 수준 이상의 모델을 만들기 위해 다양한 노력과 시도가 필요할 것으로 보이며, 나도 꼭 한 손 거들고 싶다.
