스택 개념
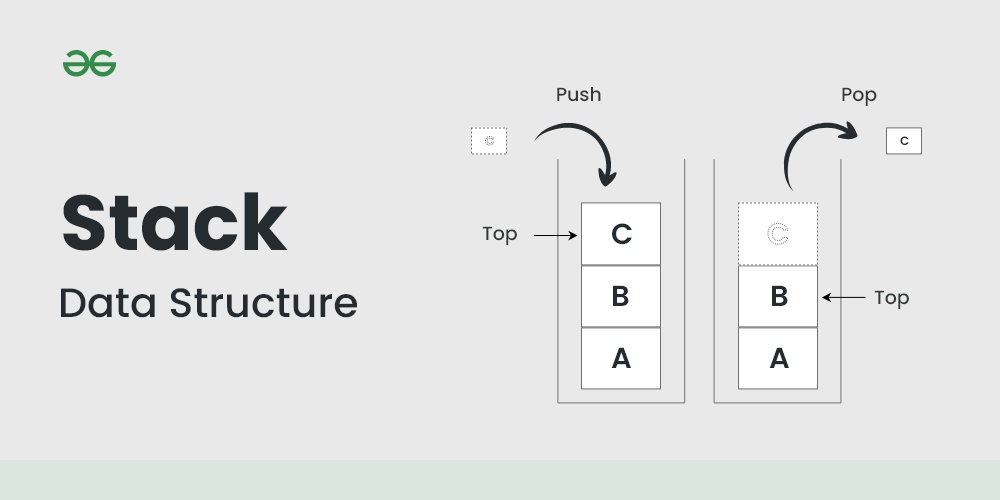
스택(Stack)이란?
스택stack의 어원은 ‘쌓는다’이다. 스택은 어원에서 짐작할 수 있듯이 먼저 입력한 데이터를 제일 나중에 꺼낼 수 있는 자료구조이다.
특성:
- 선입후출 (FILO, First In Last Out): 가장 먼저 입력된 데이터가 가장 마지막에 출력되는 구조이다.
- 예시: 티슈 사용 예시
- 티슈를 쌓을 때 가장 먼저 쌓은 것이 가장 아래에 위치하고, 나중에 쌓은 것이 그 위에 쌓이는 방식이다.
- 사용할 때는 맨 위에 있는 티슈부터 차례로 사용할 수 있다.
주요 연산:
- 푸시(
Push): 스택에 데이터를 삽입하는 연산 - 팝(
Pop): 스택에서 데이터를 꺼내는 연산
스택의 동작 원리 이해하기
다음 그림을 통해 스택에서 원소가 이동하는 과정을 이해해보자.
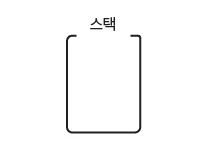
01단계 초기에는 빈 스택이 있다.
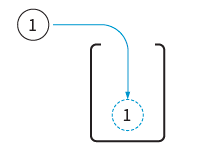
02단계 여기에 데이터 ‘1’을 푸시한다. 결과는 다음과 같다.
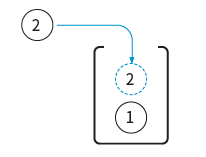
03단계 그럼 여기에 데이터 ‘2’를 또 푸시하면 어떻게 될까? ‘1’ 위로 ‘2’가 올라간다.
04단계 팝을 하면 어떻게 될까? 가장 위에 있는 데이터인 ‘2’가 빠져나온다.
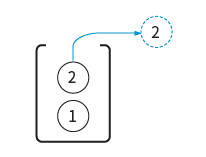
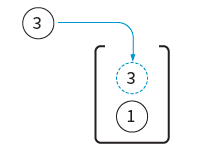
05단계 그리고 다시 데이터 ‘3’을 푸시를 하면? 다시 ‘1’위에 ‘3’이 위치하게 된다.
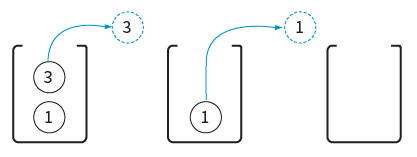
06단계 팝을 2번 연속으로 하면 ‘3’, ‘1’ 순서로 데이터가 빠져나온다.
스택의 정의
이제 스택의 ADT라는 것을 정의해보고 실제 스택이 동작하는 원리를 설명하도록 하겠다. ADT는 우리말로 추상 자료형abstract data type이다. 추상 자료형이란 인터페이스만 있고 실제로 구현은 되지 않은 자료형이다. 일종의 자료형의 설계도라고 생각하면 된다. 그렇다면 스택은 어떤 정의가 필요한 자료구조일까?
언어에 따라 표준 라이브러리에서 스택 제공 여부는 다르다. 파이썬의 경우 스택을 제공하진 않지만 대안으로 리스트 메서드인
append()메서드,push()메서드로 스택을 대체할 수 있다.
덱(deque)은 한쪽으로만 데이터 삽입, 삭제할 수 있는 스택과 다르게 양쪽에서 데이터를 삽입하거나 삭제할 수 있는 자료구조이다. 이런 덱의 특징을 조금만 응용하면 스택처럼 사용할 수 있다. 이 방법은 기출 문제를 풀면서 충분히 다루도록 하겠다.
스택의 ADT
우선 스택에는 ➊ 푸시push, ➋ 팝pop, ➌ 가득 찼는지 확인isFull, ➍ 비었는지 확인isEmpty과 같은 연산을 정의해야 한다. 그리고 스택은 최근에 삽입한 데이터의 위치를 저장할 변수인 ➎ 탑top도 있어야 합니다. 표와 그림으로 정리하면 다음과 같다.
여기서는 스택의 내부 데이터를 배열로 관리하는 모습을 예로 들었다. 하지만 스택의 원소는 배열이 아니라 다른 자료구조로 관리할 수도 있다.

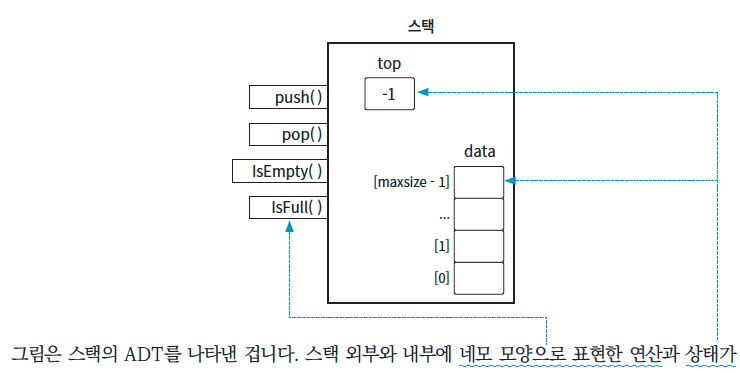
그림은 스택의 ADT를 나타내고 있다. 스택 외부와 내부에 네모 모양으로 표현한 연산과 상태가 보인다. 그림에서는 연산 시 해야 할 동작과 상태가 가지고 있어야 할 값을 정의하고 있기는 하지만 세부 구현 내용, 즉, 프로그래밍 언어는 무엇을 사용해야 하고 데이터는 이렇게 저장해야 한다는 등의 내용은 없다.
data 배열을 보면 최대 크기는 maxsize이므로 인덱스의 범위는 0부터 maxsize - 1이다. top은 가장 최근에 추가한 데이터의 위치를 참조한다. 지금 그림에서는 아무 데이터도 없으므로 top에 -1이 들어 있습니다. 만약 top이 0이면 데이터가 1개 있는 것이므로 초깃값을 0이 아니라 -1로 했음을 주목해야 한다.
그렇다면 우리는 스택을 공부를 할 때 ADT만 알면 되고 세부 구현은 몰라도 될까? 사실은 세부 구현을 알아두면 도움이 된다. 왜냐하면 어떤 문제도 ‘스택으로 푸세요’라고 대놓고 알려주지는 않기 때문이다. 만약 어떤 문제를 보고 ‘스택으로 푸는 게 좋겠다’라는 생각이 떠오르려면 스택의 세부 동작을 충분히 아는 것이 좋다.
스택 세부 동작에 대해 조금 더 자세히 알아보기
스택에 데이터를 추가하는 경우를 생각해보자. 이번에 설명할 내용은 이 푸시 연산을 수행할 때 스택 내부에서 일어나는 과정이다. 그림은 push(3) 연산을 수행하며 데이터 3이 추가되는 모습을 보여준다.
push() 연산
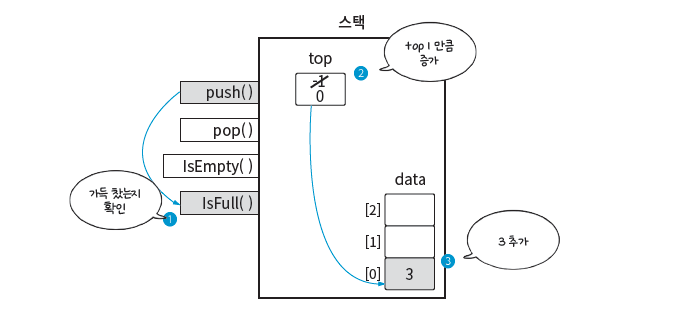
연산 과정은 push(3)을 호출하면 내부적으로 ➊ IsFull()을 수행해 우선 data 배열에 데이터가 가득 찼는지 확인하고, ➋ 그렇지 않다면 top을 1만큼 증가시킨 후 top이 가리키는 위치 ➌ data[0]에 3을 추가합니다.
pop() 연산
반대로 pop() 연산을 수행한다면 어떨까?
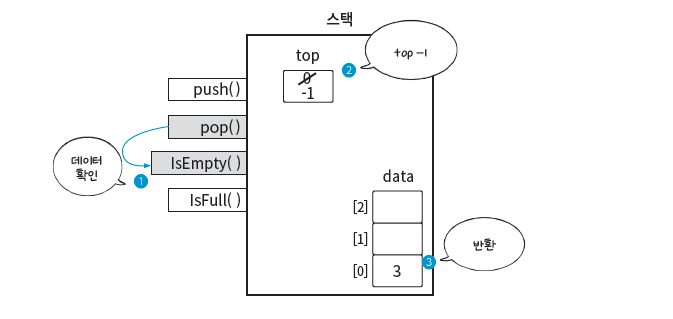
그림에서 보듯 pop() 함수를 수행하면 내부적으로 ➊ IsEmpty() 함수를 우선 수행해 data 배열에 데이터가 없는 건 아닌지 확인하고, 데이터가 있다면 ➋ top을 1만큼 감소시키고 ➌ 데이터 3을 반환한다. 여기서 ‘3이 남아 있는데?’라고 생각할 수도 있습니다. 앞서 정의한 스택의 ADT에서 top은 최근에 삽입한 데이터의 위치라고 했다. 즉, top이 가리키는 위치는 -1이므로 실제 data 배열에 데이터가 남아 있더라도 스택은 비어 있다고 보아도 된다.
스택 구현하기
코딩 테스트에서는 문제에 적용할 자료구조 or 알고리즘을 파악하는 능력이 중요하다. 문제에서 의도한 데이터 흐름이 스택에 맞는지 알아차려야 한다.
예를 들어 데이터를 그냥 저장하고 순서와 상관 없이 임의 접근하기만 해도 되면 배열을, 최근에 삽입한 데이터를 대상으로 연산해야 한다면 스택을 떠올리는 것이 좋다.
본격적으로 문제를 풀기 전에 앞서 정의한 스택 ADT를 구현하면 다음과 같다.
stack = [ ] # 스택 리스트 초기화
max_size = 10 # 스택의 최대 크기
def isFull(stack):
# 스택이 가득 찼는지 확인하는 함수
return len(stack) == max_size
def isEmpty(stack):
# 스택이 비어 있는지 확인하는 함수
return len(stack) == 0
def push(stack, item):
# 스택에 데이터를 추가하는 함수
if isFull(stack):
print("스택이 가득 찼습니다.")
else:
stack.append(item)
print("데이터가 추가되었습니다.")
def pop(stack):
# 스택에서 데이터를 꺼내는 함수
if isEmpty(stack):
print("스택이 비어 있습니다.")
return None
else:
return stack.pop( )
그러나 파이썬의 리스트는 크기를 동적으로 관리하므로 max_size나 isFull() 함수, isEmpty() 함수는 실제 문제를 풀 때 구현하지 않는다.
실제로 다음 코드를 보면 max_size, isFull() 함수는 사용하지 않고 isEmpty() 함수는 len(stack) == 0으로 검사한다.
stack = [ ] # 스택 리스트 초기화
def push(stack, item):
# 스택에 데이터를 추가하는 함수
stack.append(item)
print("데이터가 추가되었습니다.")
def pop(stack):
# 스택에서 아이템을 꺼내는 함수
if len(stack) == 0:
print("스택이 비어 있습니다.")
return None
else:
return stack.pop( )
그런데 push() 함수, pop() 함수를 구현한 부분을 보면 실제 이 함수들이 하는 일은 리스트의 append() 메서드, pop() 메서드를 호출하는 것이 전부이다. 그러므로 push() 함수와 pop() 함수는 다음과 같이 굳이 구현하지 않아도 된다.
stack = [ ]
# 스택에 데이터 추가
stack.append(1)
stack.append(2)
stack.append(3)
# 스택에서 데이터 꺼냄
top_element = stack.pop( )
next_element = stack.pop( )
# 스택의 크기를 구함
stack_size = len(stack)
# top_element : 3
# next_element : 2
마치며
스택은 개념 자체는 크게 어렵지 않으므로 비교적 쉽게 이해할 수 있다. 그러나 실전에 들어가 문제를 풀다 보면 ‘이 문제는 스택을 활용해야 풀 수 있다’라는 생각 자체를 못해서 풀지 못하는 경우가 많다. 따라서 스택 관련 문제를 많이 풀어보며 ‘이 문제는 스택을 사용하는 게 좋겠다’라는 감을 익히기를 권한다.
