📚 배열 개념
배열이란?
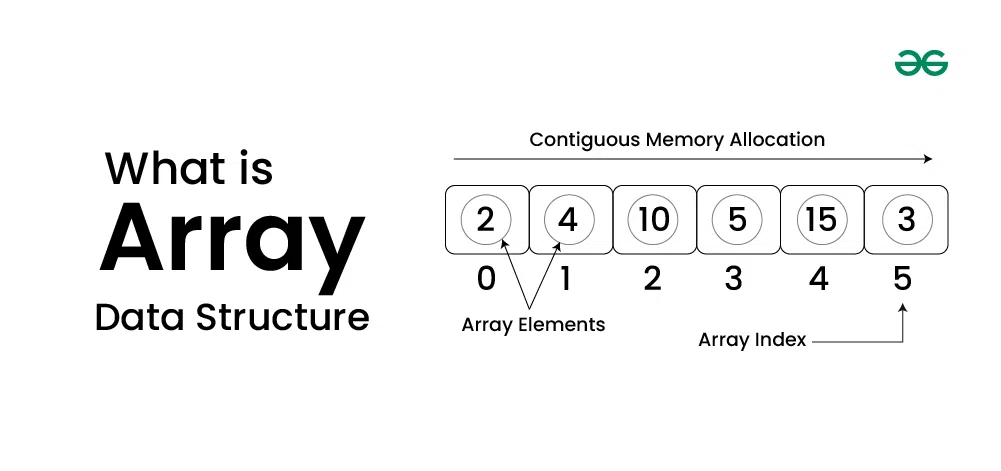
배열(Array)은 인덱스와 값을 일대일 대응해 관리하는 자료구조이다. 데이터를 저장할 수 있는 모든 공간은 인덱스와 일대일 대응하므로 어떤 위치에 있는 데이터든 한 번에 접근할 수 있다.
- 배열 요소(element): 배열을 구성하는 각각의 값
- 인덱스(index): 배열에서의 위치를 가르치는 숫자
배열 선언
배열을 선언하는 방법은 다음과 같다. 이름이 arr이고 길이가 6인 정수형 배열을 리스트를 활용해서 선언하는 3가지 방법을 예제로 알아보자.
1) 일반적인 방법
arr = [0, 0, 0, 0, 0, 0]
arr = [0] * 6
2) 리스트 생성자를 사용하는 방법
arr = list(range(6)) # [0, 1, 2, 3, 4, 5]
3) 리스트 컴프리헨션을 활용하는 방법
arr = [0 for _ in range(6)] # [0, 0, 0, 0, 0, 0]
이렇게 선언한 배열은 컴퓨터에 이런 모습으로 저장된다.
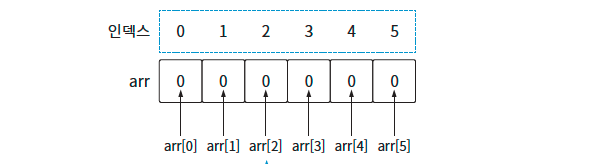
배열은 인덱스가 0부터 시작한다. 즉, 3번째 데이터에 접근하려면 arr[2]와 같이 접근하면 된다. 다만 파이썬의 경우 배열을 지원하는 문법은 없고 그 대신 리스트라는 문법을 지원한다.
엄밀히 말해 배열과 리스트는 다른 개념이지만 여기서는 파이썬 중심으로 내용을 풀어가므로 여기서는 코드와 함께 배열을 설명해야 할 때는 파이썬의 리스트를 사용하도록 하겠다.
파이썬의 리스트는 동적으로 크기를 조절할 수 있도록 구현되어 있다. 그래서 파이썬의 리스트는 다른 언어의 배열 기능을 그대로 사용할 수 있으면서 배열 크기도 가변적이므로 코딩 테스트에서 고려할 사항을 조금 더 줄여준다. 또 슬라이싱, 삽입, 삭제, 연결 등의 연산을 제공하므로 더 편리하다.
배열과 차원
배열은 2차원 배열, 3차원 배열과 같이 다차원 배열을 사용할 때도 많다. 하지만 컴퓨터 메모리의 구조는 1차원이므로 2차원, 3차원 배열도 실제로는 1차원 공간에 저장한다. 다시 말해 배열은 차원과는 무관하게 메모리에 연속 할당된다.
1차원 배열
1차원 배열은 가장 간단한 배열 형태를 가진다. “간단하다.”라고 말한 이유는 1차원 배열의 모습이 메모리에 할당된 실제 배열의 모습과 같다는 것이다.
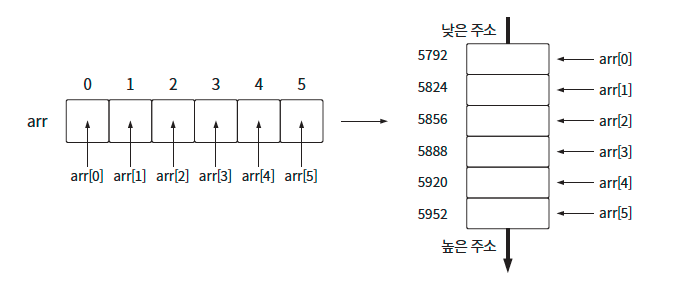
왼쪽 그림이 1차원 배열의 모습이고, 오른쪽 모습이 실제 메모리에 배열이 할당된 모습이다. 배열의 각 데이터는 메모리의 낮은 주소에서 높은 주소 방향으로 연이어 할당된다.
2차원 배열
2차원 배열은 1차원 배열을 확장한 것이다. 2차원 배열은 파이썬에서 리스트를 사용해 다음과 같이 선언할 수 있다.
# 2차원 배열을 리스트로 표현
arr = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
# arr[2][3]에 저장된 값을 출력
print(arr[2][3]) # 12
# arr[2][3]에 저장된 값을 15로 변경
arr[2][3] = 15
# 변경된 값을 출력
print(arr[2][3]) # 15
리스트 컴프리헨션을 활용하면 다음과 같이 선언할 수도 있다.
# 크기가 3 * 4인 리스트를 선언하는 예
arr = [[i]*4 for i in range(3)] # [[0, 0, 0, 0], [1, 1, 1, 1], [2, 2, 2, 2]]
2차원 배열 데이터에 접근하는 방법은 1차원 배열과 비슷하다. 행과 열을 명시해 [ ] 연산자를 2개 연이어 사용한다는 점만 다르다.
arr = [[1, 2, 3], [4, 5, 6]] # ➊ 2행 3열 2차원 배열을 표현하는 리스트 선언
이를 그림으로 나타내면 다음과 같다.
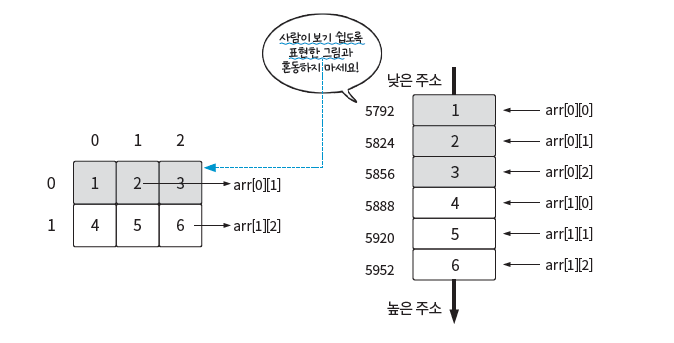
왼쪽은 2차원 배열을 사람이 이해하기 쉽도록 2차원으로 표현한 것이고, 오른쪽은 실제 메모리에 2차원 배열이 저장된 상태를 표현한 것이다. 실제로는 오른쪽처럼 0행, 1행 순서로 데이터를 할당해 1차원 공간에 저장한다.
⏱️배열의 효율성
이제 배열 연산의 시간 복잡도를 공부하면서 배열의 효율성을 알아보자.
배열 연산의 시간 복잡도
- 접근:
O(1)- 인덱스를 이용해 직접 접근하기 때문에 빠르다.- 삽입/삭제:
O(n)- 배열의 중간에 요소를 삽입하거나 삭제할 경우, 해당 위치 이후의 모든 요소를 이동시켜야 한다.
배열은 임의 접근이라는 방법으로 배열의 모든 위치에 있는 데이터에 단 한 번에 접근할 수 있다. 따라서 데이터에 접근하기 위한 시간 복잡도는 O(1)이다. 그러나 배열에 데이터를 추가하는 경우는 어떨까? 배열은 데이터를 어디에 저장하느냐에 따라 추가 연산에 대한 시간 복잡도가 달라집니다.
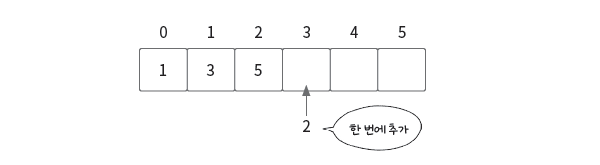
맨 뒤에 삽입할 경우
다음과 같은 배열이 있을 때 2를 추가한다고 생각해보자. 맨 뒤에 삽입할 때는 arr[3]에 임의 접근을 바로 할 수 있으며 데이터를 삽입해도 다른 데이터 위치에 영향을 주지 않는다. 따라서 시간 복잡도는 O(1)이다.
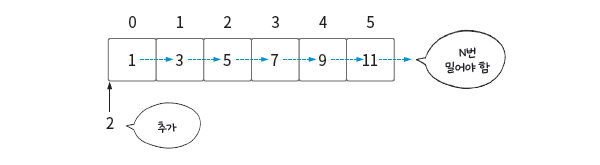
맨 앞에 삽입할 경우
데이터를 맨 앞에 삽입한다면 어떨까? 이 경우 기존 데이터들을 뒤로 한 칸씩 밀어야 한다. 즉, 미는 연산이 필요하다. 데이터 개수를 N개로 일반화하면 시간 복잡도는 O(N)이 된다.
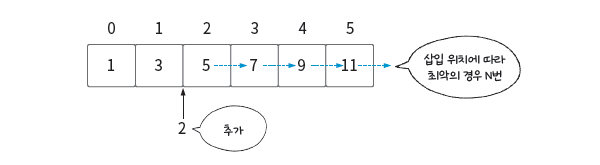
중간에 삽입할 경우
중간에 삽입할 경우도 보자. 5 앞에 데이터를 삽입한다면 5 이후의 데이터를 뒤로 한 칸씩 밀어야 한다. 다시 말해 현재 삽입한 데이터 뒤에 있는 데이터 개수만큼 미는 연산을 해야 한다. 밀어야 하는 데이터 개수가 N개라면 시간 복잡도는 O(N)이 된다.
물론이죠! 배열을 선택할 때 고려해야 할 사항들을 마크다운 형식으로 정리해드리겠습니다.
배열 선택 시 고려사항
배열은 데이터에 빠르게 접근할 수 있는 장점이 있지만, 메모리 사용량과 데이터 삽입 시 성능 문제가 있을 수 있다. 코딩 테스트에서는 다음 사항을 고려하여 배열을 선택해야 한다.
1) 메모리 크기 확인
- 문제점: 배열은 고정된 크기를 가져야 하므로, 할당할 수 있는 메모리 크기를 확인하는 것이 중요하다.
- 권장사항: 배열로 표현하려는 데이터가 너무 많으면 런타임에서 할당에 실패할 수 있다.
- 정수형 1차원 배열: 약 1000만 개
- 2차원 배열: 3000x3000 크기까지 고려
2) 데이터 삽입 빈도 확인
- 문제점: 배열은 중간이나 처음에 데이터를 삽입할 때 시간 복잡도가 O(n)이므로 성능 저하가 발생할 수 있다.
- 권장사항: 데이터 삽입이 빈번한 경우, 배열보다는 리스트나 다른 자료구조를 사용하는 것이 좋다.
우리는 배열을 리스트로 표현하기로 했으므로 구현 시에는 배열 크기에 대한 고민은 하지 않는다. 공부하는 정도로만 읽고 기억해두자.
