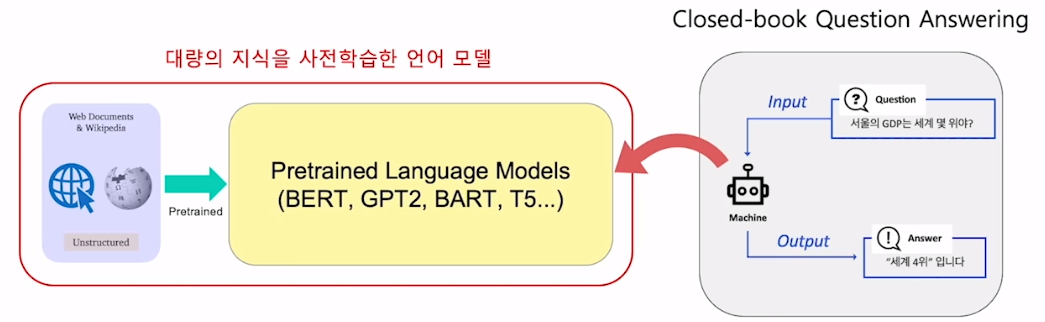
Closed-book Question Answering
Closed-book QA
Open-domain QA 안에 Open-book, Closed-book으로 나뉨
사전 학습으로 대량 지식을 학습했으면, 이미 하나의 knowledge storage 라고 판단
Open-book QA vs. Closed-book QA
| Open-book QA | Closed-book QA | |
|---|---|---|
| 지식을 찾는 방식 | 대량의 지식 소스를 특정 문서 단위로 나눠 query와 관련된 문서 search | 대량의 지식 소스를 기반으로 학습 된 언어 모델이 그 지식을 기억하고 있다고 가정 / Search 과정 필요 없음 |
| 문제점 | 지식 소스 저장 어려움 / 검색 시간 소요 | 사전 학습된 모델이 얼마나 지식을 잘 기억하고 있는지 중요 |
Text-to-Text format
Closed-book QA as Text-to-Text format
-
Closed-book QA는 generation based MRC와 유사함
- 입력 지문 없이 질문만 들어가는 것이 차이점
-
입력 값(질문)과 출력 값(답변)에 대한 설명을 추가함
Text-to-Text format
-
Input으로 text를 받고, output으로 새로운 text를 생성하는 문제
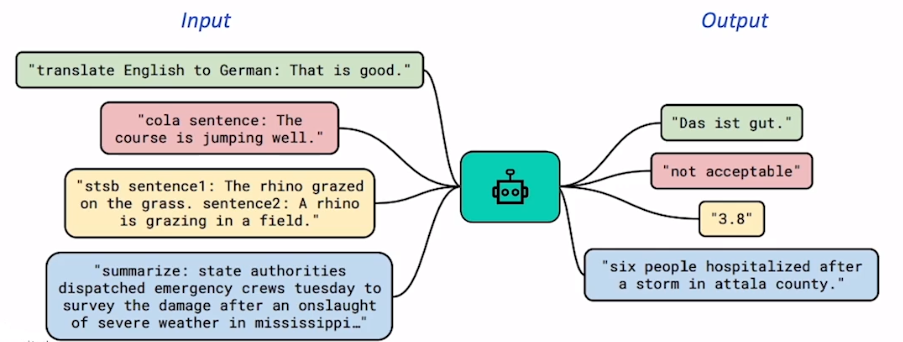
-
어떤 task를 수행해야 하는지 질문 앞에 명시
-
모델은 그에 맞는 task를 수행
-
-
이전에는 각 task에 맞는 모델을 각각 만들었다면, 앞에 task를 붙여주면 하나의 모델이 해결
T5
- Text-to-Text format 형태로 데이터 입출력을 만들어 거의 모든 자연어 처리 문제 해결하도록 학습된 Seq2Seq transformer 모델
Fine-tuning T5
- Input: Task-specific prefix 추가
e.g., “trivia question: 질문” , ”answer: 정답 형태”
Experiment Results & Analysis
Experiment Setting
-
Dataset
- Open-domain QA 또는 MRC 데이터셋에서 지문을 제거하고 질문과 답변만 남긴 데이터셋
-
Salient Span Masking
- 고유 명사, 날짜 등 의미를 갖는 단위에 속하는 토큰 범위를 마스킹 한 뒤 학습
-
Fine-tuning
- Pre-trained T5 체크포인트를 Open-domain QA 학습 데이터셋으로 추가 학습
Quantitive Examples
-
대부분 Open-book 스타일 모델보다 뛰어난 성능
-
모델 크기 커질수록 성능 증가
-
Salient Span Masking이 성능을 크게 향상시킴
Limitations
-
모델 크기가 커서 계산량이 많고 속도가 느림
-
모델이 어떤 데이터로 답을 내는지 알 수 없음
-
참조하는 지식을 추가하거나 제거가 어려움
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid