규칙 기반 NLP
정의 및 특징
-
Rule에 맞게 처리하는 시스템
-
Rule 생성을 위해 task에 대한 전문 지식 필요
-
데이터를 전문가가 만들어야 했음
통계 기반 NLP
정의 및 특징
-
대량의 텍스트 데이터로 통계를 내어 단어 표현
-
모두가 무의식적으로 생산한 대량의 데이터를 활용
-
다음 단어를 확률적으로 예측
-
Sparsity Problem으로 인한 한계 도달
- 충분한 양의 데이터를 사용하지 못해 언어를 정확하게 modeling하지 못함
Statistical Machine Translation
-
여러 component 조합으로 시스템 구성
- Translation Model + Language Model + Re-ordering Model
-
처음에는 단어 단위로 번역 수행
-
구 단위의 번역 방식 제안
-
구 내에 변수 개념을 도입한 Hierarchical Phrase-Based SMT 제안
- eat an apple에서 eat X로 치환, X에는 apple banana 등 다양한 단어 수용
-
Syntax Base SMT 제안
-
eat X를 eat NP(명사구)로 변경
-
X에 올 수 있는 단어를 한정 지어 불필요한 후보를 제거
-
ML 및 DL 기반 NLP
정의 및 특징
- 전문가 + 모두(일반인) 공존의 시대
데이터의 용도
-
지도학습을 위한 데이터
-
정답을 필요로하는 데이터
-
시간 및 금전 비용 발생
-
대량 구축 어려움
-
-
비지도학습을 위한 데이터
-
정답이 필요하지 않은 데이터
-
손쉽게 대량 구축 가능
-
지도학습을 보완하여 성능을 더욱 향상시키는 방법으로 사용
-
Language Model
- 컴퓨터가 이해할 수 있는 지식표현 체계로 변환
Pre-train & Fine-tuning 기반 NLP
정의 및 특징
-
대중이 만든 데이터 (Pre-train) + 전문가가 만든 데이터 (Fine-tune)
-
대량의 말뭉치로 언어 능력을 pre-training 후 task specific fine-tuning
벤치마크 등장
-
Task-specific benchmark dataset 대량 등장
-
훈련, 검증, 평가 데이터로 구성
Neural Symbloic NLP
정의 및 특징
-
전문가의 데이터를 전면 활용
- 상식정보, 추론 능력 등 딥러닝 모델 한계 보완
예시
- Knowledge base에서 정보를 바탕으로 질문에 대답하는 knowledge base question answering
Large Language Models (LLM)
정의
- 대규모 언어 모델
Foundation Models
- adaptation을 통해 task에 맞게 model 학습
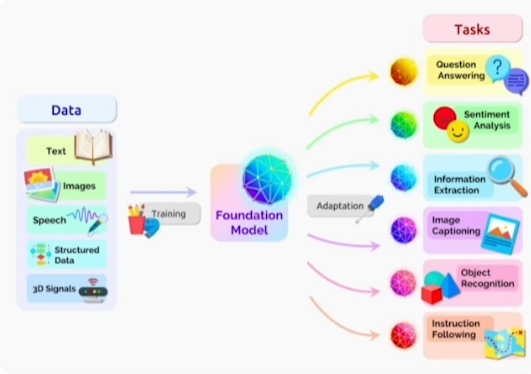
In-Context Few-Shot Learning & Prompt Learning
-
몇 개의 예시를 입력으로 같이 줌
-
예시의 문맥을 통해 학습
예시
- OpenAI GPT-3, Meta의 LLaMA, Google PALM, Naver HyperCLOVA, …
Human FeedBack Data 기반 NLP
ChatGPT
-
무의식적 데이터 생성이 아닌, 모델에게 피드백을 주기 위한 데이터 생성
-
피드백을 반영하는 Reinforcement Learning
- 의식적 데이터 생성 = 피드백

검색의 새로운 패러다임
-
검색의 주도권이 사용자에게 있음
-
사람이 model의 결과를 수정하도록 만듦
Prompt Engineering
-
다양한 능력을 가진 ChatGPT의 능력을 발굴
- 이 때 적절한 Prompt가 필요
Summary
규칙 기반 NLP 부터 Human Feedback NLP까지
전문가가 만든 데이터에만 의존하던 시대에서, 모두의 의식적 데이터 생성까지
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
