MDP
- MRP에 action(decision)이 추가된 형태
- <S, A, P, R, γ> 형태
Ai : finite set of actions
Pss'a : s → s' 이면서 t 시점일 때 a 액션을 하는 확률
P[st+1=s' | st , At = a]
Rsa : E[Rt+1=s' | st , At = a] = E[Rt+1=s' | st]
Reward는 보통 action은 고려하지 않고 state에만 dependent

Agent가 action을 취하면 Environment에서 reward와 다음 state 정보를 제공
MDP는 Agent 개념이 도입되면서 passive 하지 않고 active
Policy
- mapping from states to actions π : S → A
- π(a | s) = P(At | st = s)
- MDP policy는 현재 state에 dependent
MDP에서 policy가 주어지면 MRP 문제와 동일해진다.
State value function & Action value function
state value function vπ(s) : policy π를 따를 때 s state의 expected return
action value function qπ(s) : policy π를 따르고 action a를 취할 때 s state의 expected return
Action value function
qπ(s, a) = Eπ[Gt | St+1 = s, At = a]
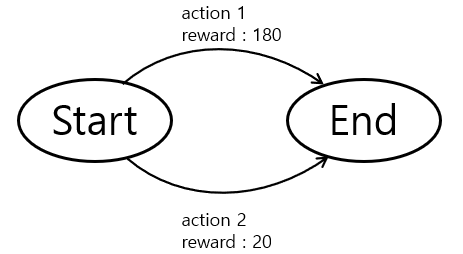
qπ(Start, action1) = 180
qπ(Start, action2) = 20
State value function
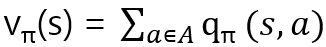
그림으로 두 함수를 설명한다면,
State value function

Action value function

AI-Kid