Markov Reward Process
구성요소 <S, P, R, γ>
- S : states
- P : Probabilities
- R : reward function
- γ : discount factor
Return
Reward of multiple transition
Rt : immediate reward
그 이후 시점에는 discount factor가 적용된 reward의 모든 합이다.
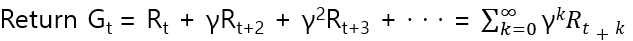
discount factor
미래 시점의 불확실성에 대한 discount, future reward에 대한 현재 value 치환을 위해 사용한다.
γ = 0 : immediate reward만 고려하겠다.
γ = 1 : Future reward를 immediate reward만큼 beneficial한 것으로 고려하겠다.
Value function
expected return starting from state s
value function v(s)
= E[Gt | St = s]
= E[Rt+1 + γRt+2 + ··· | St = s]
= E[Rt+1 + γGt+1 | St = s]
= E[Rt+1 + γV(st+1) | St = s]
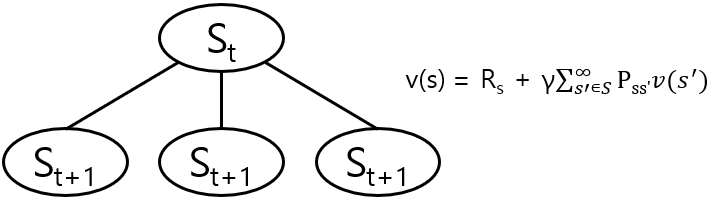
t시점에 s state일 때 가능한 모든 t+1 시점의 s'의 value function과 Pss'의 곱을 다 더하여 s state의 v(s)를 구할 수 있다.

AI-Kid