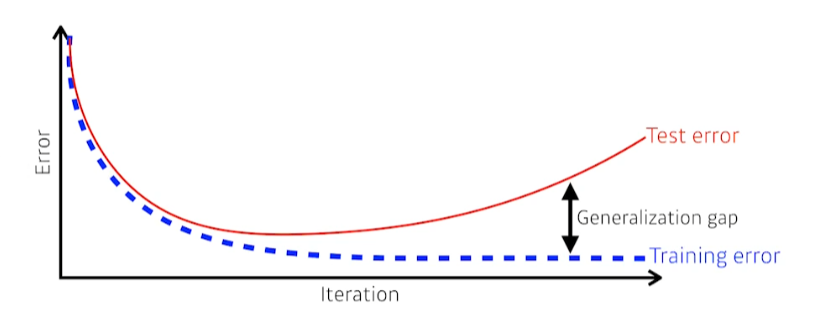
Generalization (일반화)
Cross-Validation
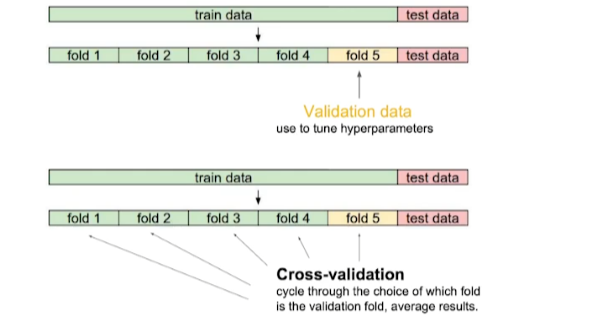
- 학습 데이터를 K개로 나눠 K-1개로 학습을 시키고 나머지로 validation을 test
- 최적의 hyperparameter set을 찾을 때 사용
Bias and Variance
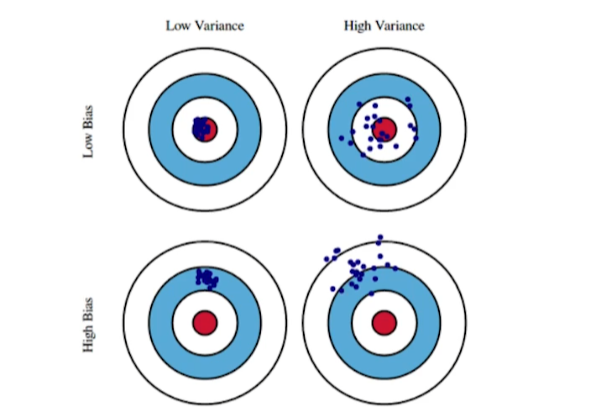
-
Variance가 높으면 Overfitting의 위험이 있음
-
Bias and Variance Tradeoff
- bias와 variance를 둘 다 줄이기는 힘들다.
- bias와 variance를 둘 다 줄이기는 힘들다.
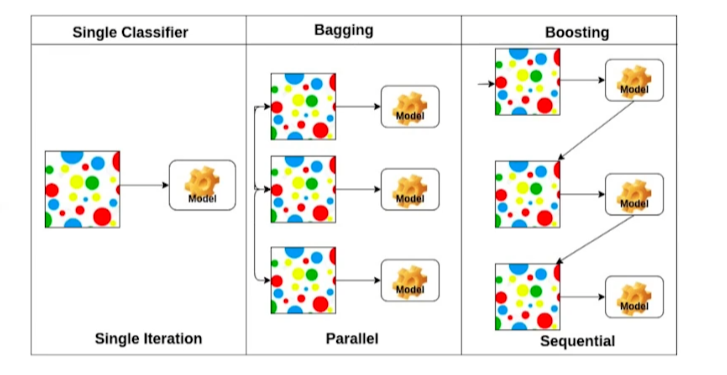
Bootstrapping
- 학습 데이터를 sampling해 여러 개를 만들어 여러 model 또는 metric을 만드는 기법
- Bagging (Bootstrapping aggregating)
- 여러 모델들을 가지고 output을 voting, averaging 기법으로 도출 (Ensemble)
- Boosting
- weak learner를 sequential하게 combine해 하나의 strong learner를 만듦
Gradient Descent Methods
batch-size를 크게 하면 sharp-minimizer로 수렴하고 작게하면 flat-minimizer로 수렴한다.
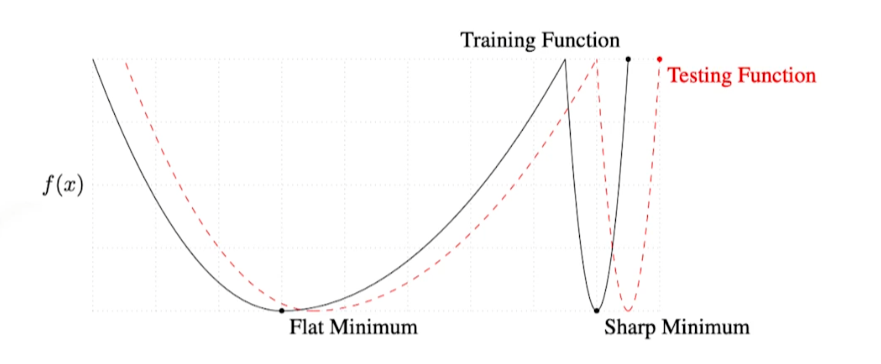
Sharp-minimum에서 약간만 멀어져도 testing function에서는 매우 높은 값이 나옴
- training에 활용되지 않은 test-data에서 잘 작동하지 않을 수 있다.
1. Momentum
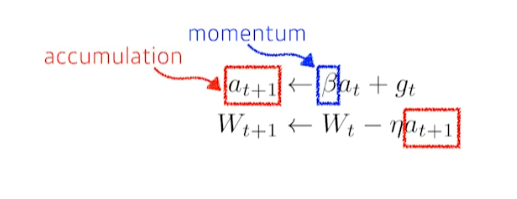
- β : gradient 방향의 hyperparameter
- t+1번째의 gradient는 버리고 momentum과 t시점의 gradient를 합친 accumulation으로 update
- 한 번 흘러가기 시작한 gradient의 방향을 어느정도 유지시켜 gradient가 왔다갔다해도 잘 학습하는 효과
2. Nesterov Accelerate Gradient (NAG)
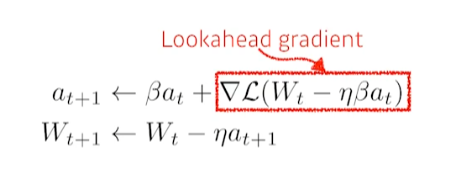
- momentum보다 더 빨리 local minimum에 converge
3. Adagrad
- 뉴럴 네트워크에서 많이 변한 parameter는 적게 변화시키고 적게 변한 parameter는 많이 변화
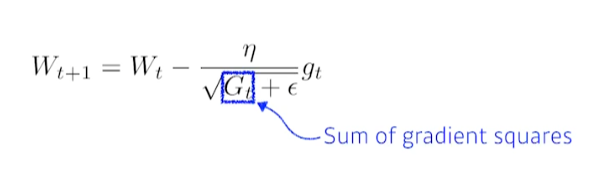
- Gt : 지금까지 gradient가 얼마나 변했는지를 제곱하여 더함
- G는 계속해서 커지며, 무한대로 가면 0으로 수렴해 W가 update되지 않음
4. Adadelta
- Adagrad에서 G가 계속해서 커지는 현상을 막음
- window-size만큼의 gradient 변화만 보려함
- Learning rate가 없음
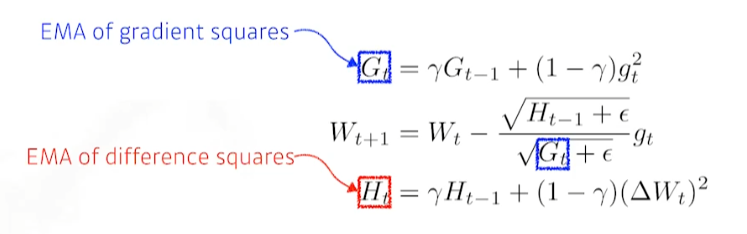
5. RMSprop
- Adadelta에 learning rate를 적용
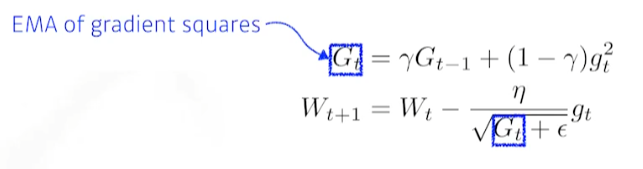
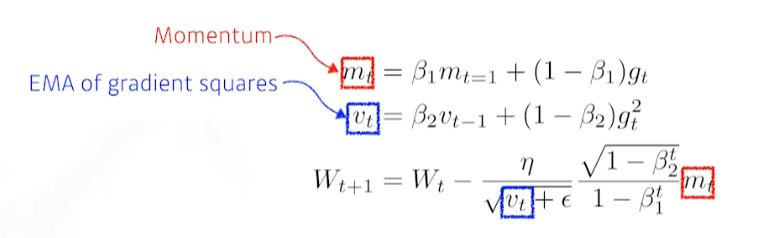
6. Adam (Adaptive Moment Estimation)
- momentum과 EMA of gradient squares를 combine
Regularization
학습을 방해해 학습 데이터 외 데이터에도 성능이 잘 나오도록 하는 것이 목표
Early Stopping
- validation error가 training error보다 커지면 학습 중단
Parameter Norm Penalty
- Network의 Weight를 작게 만듦
Data Augmentation
- label이 변경되지 않는 한에서 data 증강
Noise Robustness
- 입력과 weight에 noise를 넣음
Label Smoothing
- train 단계에서 데이터 두 개를 뽑아 mix up 시킴
- mix up, cutmix
Dropout
- 일부 뉴런을 0으로 set
Batch Normalization
- 적용하고자 하는 layer의 statistics를 정규화
실습
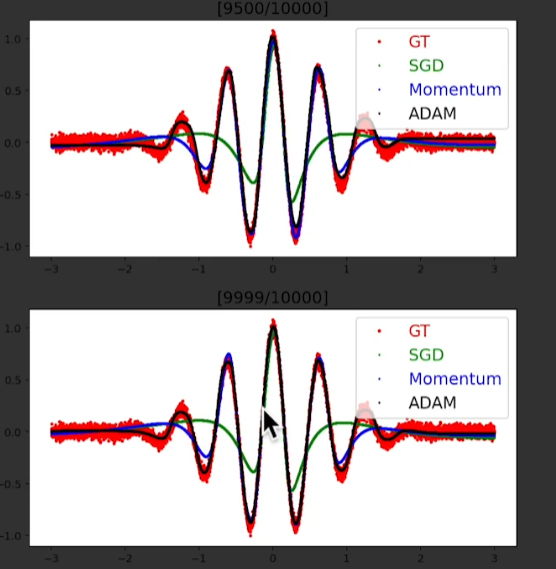
10000번의 iteration을 돌았음에도 SGD는 잘 예측하지 못하지만,
adam은 거의 정확하게 예측하는 것을 확인 가능
→ 웬만하면 adam optimizer로 모델을 설계하자
※ 모든 이미지의 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid
이런 유용한 정보를 나눠주셔서 감사합니다.