PyTorch
Learning Rate & Scheduler
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=1)-
learning rate를 어떻게 사용할지에 대해 scheduler 정의
-
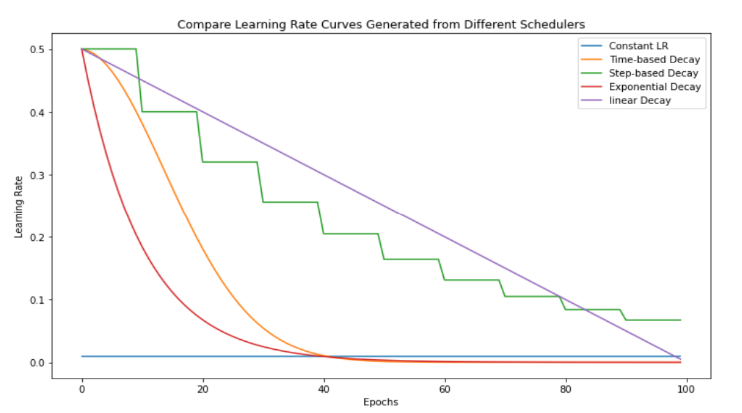
Constant LR의 경우 LR의 변동이 없고, 나머지 Scheduler은 LR을 계속해서 조정
-
해당 실습 코드에선 Step-based Decay 사용
Pytorch만 썼을 때의 문제점
- 모델을 학습하고 평가하는 반복 학습을 할때마다 dataloader를 매번 호출해야하며
모델과 데이터, 옵티마이저를 일일히 불러와서 코드가 중복이 되는 불편함이 있다.
- 모델, 데이터, 학습 및 평가가 구조적으로 정리되지 않아 가독성이 떨어진다.
PyTorchLightning 실습
!pip install pytorch-lightning PL 설치
Data Preparation
def prepare_data(self):
# download
MNIST(os.getcwd(), train=True, download=True)
MNIST(os.getcwd(), train=False, download=True)
def setup(self, stage = None):
# Assign train/val datasets for use in dataloaders
if stage == "fit" or stage is None:
mnist_full = MNIST(os.getcwd(), train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Assign test dataset for use in dataloader(s)
if stage == "test" or stage is None:
self.mnist_test = MNIST(os.getcwd(), train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)-
setup()에서 stage 파라미터를 이용해 train, test 구분-
fit(train)일 땐 train, valid data를 나눔
-
test 단계에선
train=False
-
-
train_dataloader, val_dataloader, test_dataloader
Model Implementation
PyTorch와 다르게 모델 구현에서 forward 함수와 더불어
optimizer, train/valid/test step을 모두 메서드로 구현
class PLNet(pl.LightningModule):
# Model Implementation -------------------------------------------------------
def __init__(self):
super(PLNet, self).__init__()
self.layer_1 = nn.Linear(28 * 28, 128)
self.layer_2 = nn.Linear(128, 256)
self.layer_3 = nn.Linear(256, 10)
self.validation_step_outputs = []
self.test_step_outputs = []-
validation step outputs, test step outputs list도 함께 선언
- 한 epoch의 결과를 list에 저장하기 위해 사용
# Updater Implimentation -----------------------------------------------------
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=1)
return [optimizer], [scheduler]configure_optimizers예약 함수에 optimizer와 scheduler 정의 및 return
# training Step --------------------------------------------------------------
def training_step(self, batch, batch_idx):
data, target = batch
output = self(data)
## loss calculation
loss = F.nll_loss(output, target)
return loss-
training_step,validation_step,test_step-
train → valid → test 순으로 자동 실행
-
한 step에서 한 batch를 계산
-
-
output = self(data)- forward 함수 호출
# Validation Step to Epoch ---------------------------------------------------
def validation_step(self, batch, batch_idx):
data, target = batch
output = self(data)
## loss calculation
loss = F.nll_loss(output, target)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.eq(target.view_as(pred)).sum().item()
preds = {"val_loss" : loss, "correct" : correct}
self.validation_step_outputs.append(preds)
return preds
def on_validation_epoch_end(self):
avg_loss = torch.stack([x['val_loss'] for x in self.validation_step_outputs]).mean()
self.log('val_loss', avg_loss)
self.log('avg_val_loss', avg_loss)
self.validation_step_outputs.clear()
# Test Step to Epoch ---------------------------------------------------------
def test_step(self, batch, batch_idx):
data, target = batch
output = self(data)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.eq(target.view_as(pred)).sum().item()/ len(target)
preds = {"correct": correct}
self.test_step_outputs.append(preds)
return preds
def on_test_epoch_end(self):
outputs = self.test_step_outputs
all_correct = sum([output["correct"] for output in outputs])
accuracy = all_correct / len(outputs)
self.log("accuracy", accuracy)
self.test_step_outputs.clear()-
self.log(이름, 값)을 이용해 logger로 사용 가능 -
on_validation_epoch_end,on_test_epoch_end- 한 번의 epoch이 끝나면 해당 함수로 넘어옴
Iterative Learning
# Data Preparation
dm = MNSTDataModule()
pl_net = PLNet()
# Train & Validation
trainer = pl.Trainer(max_epochs = 3)
trainer.fit(pl_net, datamodule=dm)- 최대 실행 횟수 설정 및 학습 모드로 실행
Pytorch Lightning 을 사용할 때의 장점
PyTorch Lightning 구조는 기존의 PyTorch 학습을 간단한 한줄에 묶을 수 있고,
중복되는 Deep Learning Block을 Module들로 묶어서 모듈의 가독성과 재활용성을 높일 수 있다.
Test
trainer.test(datamodule=dm)
-
평가 모드 실행
-
dropout rate 0.0 세팅,
no_grad()적용
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
