Database System Concepts - Organization of Records in Files( 파일 구조 ), 버퍼 매니저
Database System Concepts
목록 보기
3/14

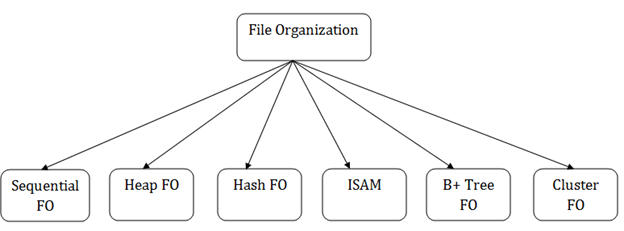
파일 구조
- 파일 구조는 데이터를 효율적으로 이용할 수 있도록 파일에 저장하는 방법
- 릴레이션을 구성하는 레코드는 일반적으로 하나의 파일로 존재하며 디스크 블록에 저장됨
- 블록은 디스크의 물리적인 속성으로 운영체제에 의해 결정되는 고정된 크기이지만, 레코드 크기는 가변적임
- 레코드는 고정 길이 또는 가변 길이의 필드로 구성, 즉 연관된 필드들이 모여서 고정 길이 또는 가변 길이 레코드가 됨
- 한 파일에 속하는 블록들이 반드시 물리적으로 인접해 있지는 않음
파일 구조의 종류
힙 파일 구조(Heap File Organization)
- 힙 조직은 가장 간단한 비 순서 파일 구조
- 레코드가 특정 순서나 구조없이 공간만 있으면 파일에 임의로 저장됩니다.
- 레코드를 빠르게 찾고 액세스하기 어렵습니다.
- 레코드를 효율적으로 정렬하거나 검색할 수 없으므로 데이터베이스 시스템의 성능을 제한할 수 있습니다.
- 힙 파일에서 질의는 모든 레코드를 참조하고 레코드를 접근하는 순서가 중요하지 않을 때 사용하는 것이 효율적
-> 결과적으로 힙 조직은 대규모 데이터베이스 시스템에서 일반적으로 사용되지 않습니다.
Free-Space Map
힙 파일 구조에서는 파일에 free space가 얼마나 남아있는지를 파악하는 것이 중요함. 따라서 free space map을 이용해 각 블록에 빈 공간이 얼마나 남아 있는지 저장해 놓음.
- free space mape은 한 블록당 한 entry를 가지고 있는 array이다.
- 각 entry는 few bits로 이루어져 있고 이는 빈 공간의 비율을 의미

-> 각 entry는 3 bits로 이루어져 있음. 예를 들어 5번째 entry인 7은 7/8 만큼이 비어있다는 것을 의미
- second-lebel free space map을 가질 수도 있음
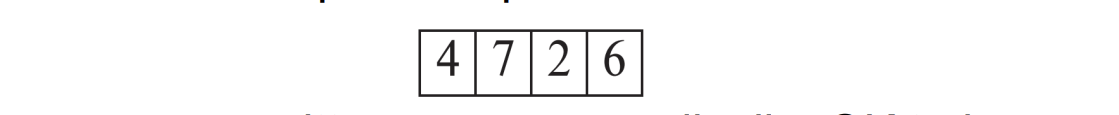
-> first level free space map을 최대 4개의 entry로 구분지어 최대값을 저장
예를 들어 MAX(4,2,1,4), MAX(7,3,6,5), MAX(1,2,0,1), MAX(1,0,5,6) 이런 식.
순차 파일 구조(Sequential File Organization)
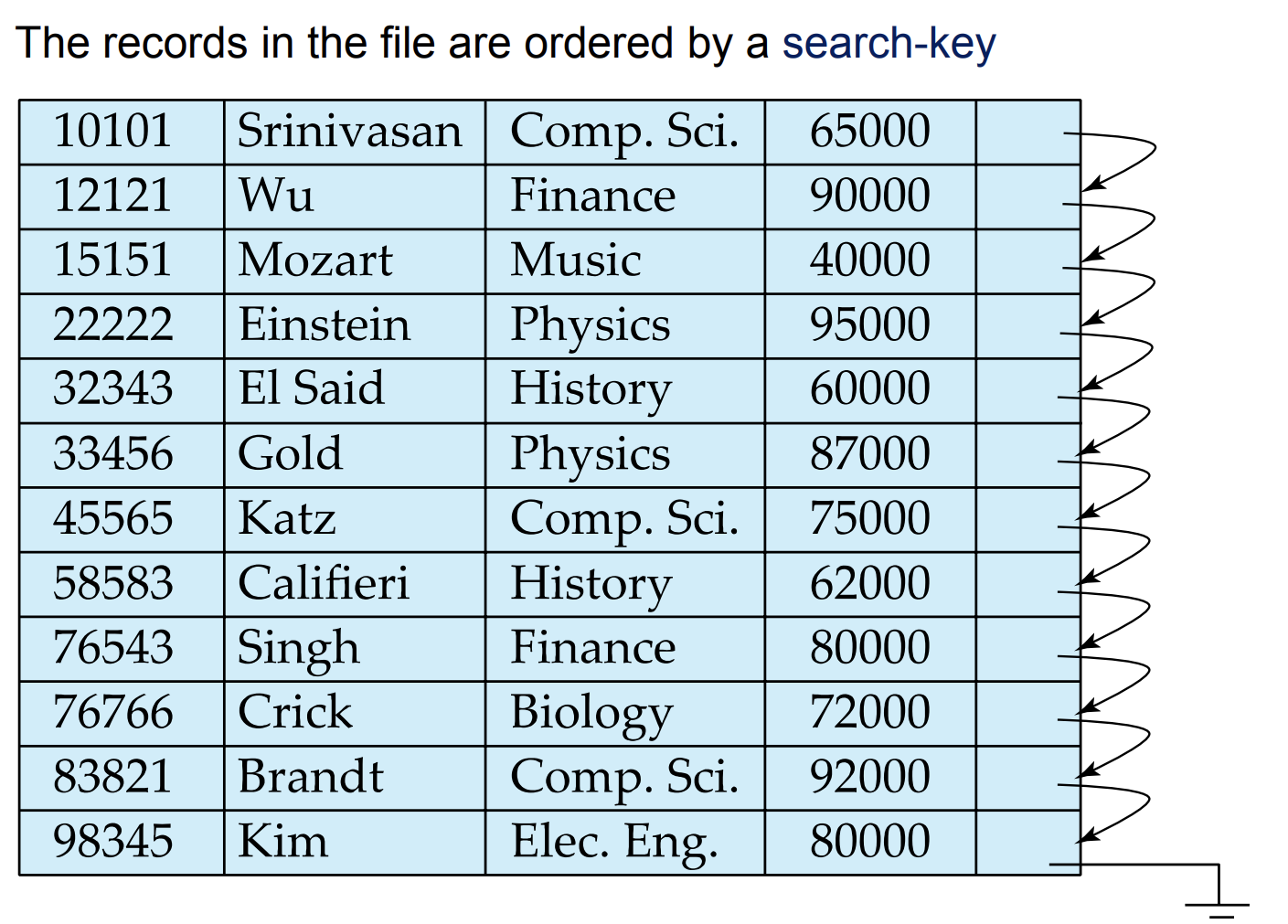
- 파일 내 레코드를 특정 순서(일반적으로 특정 필드나 필드 세트 기준)에 따라 저장하는 파일 구조
- 레코드들의 물리적 순서가 그 레코드들의 논리적 순서와 같게 저장함. -> IO를 줄일 수 있음
- 이 순서는 특정 기준과 일치하는 레코드를 찾거나 레코드를 정렬하는 데 용이함.
- 새로운 레코드를 파일에 삽입하는 것은 기존 레코드를 이동하여 새로운 레코드에 공간을 만들어야 하므로 시간이 걸릴 수 있음
- 레코드를 업데이트하는 것 또한 어려울 수 있음. 왜냐하면 올바른 순서를 유지하기 위해 파일을 재정렬해야하기 때문.
deletion
- use pointer chains
insertion
- 레코드가 있어야 하는 위치에 삽입한다
- 만약 그 위치에 free space가 존재한다면 삽입함.
- 없다면, overflow block에 삽입함.
- 그리고 pointer chain을 update 해주어야 함.
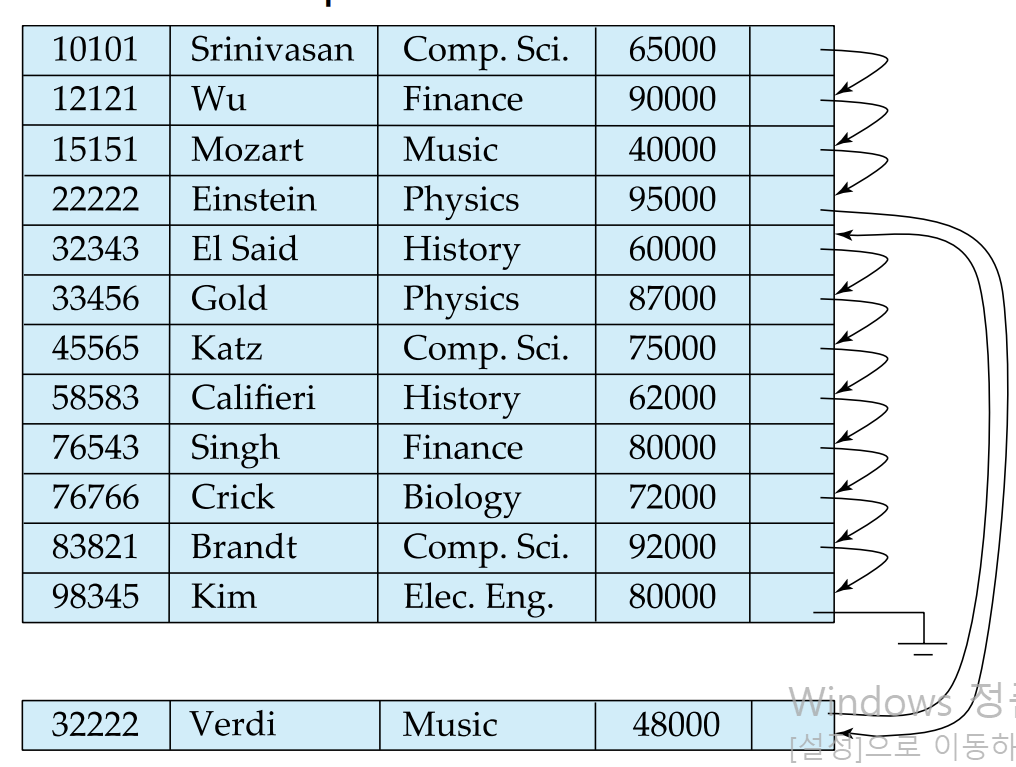
- 파일의 물리적 , 논리적 순서를 일치 시키기 위해 파일을 재구성 해줘야 함.
-> 위에 이미지처럼 Verdi 블록은 overflow block에 저장되어 물리적, 논리적 순서가 일치하지 않음. 따라서 IO를 최소화 하기 위해선 파일 재구성을 해줘야함
Multitable clustering 파일 구조
- 서로 다른 테이블의 관련 있는 레코드를 효율적으로 저장하고 검색하기 위한 파일 구조
-> motivation : store related records on the same block to minimize IO - 동일한 조건으로 테이블을 조인하는 빈도가 높을 때 사용됨.
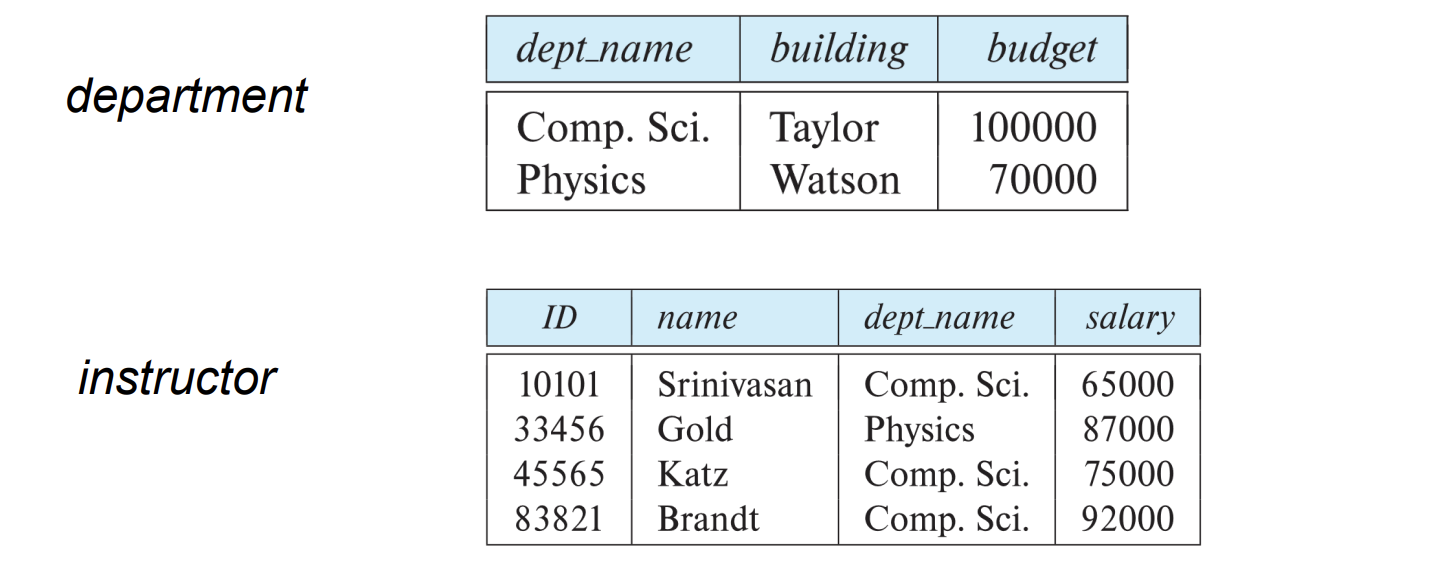
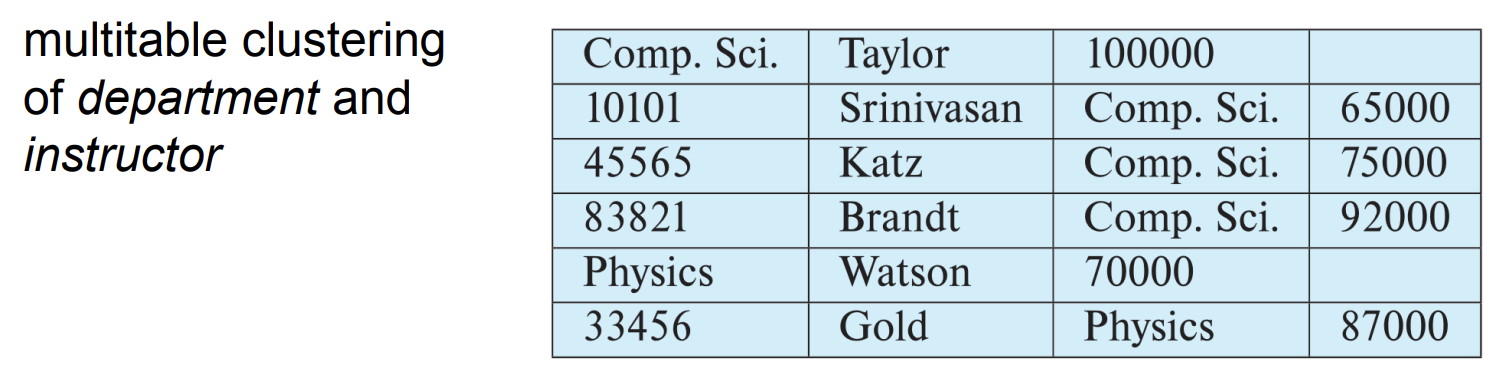
- department만 조회하는 쿼리는 비효율적임
-> can add pointer chains to link records of a particular relation.
첫 번째 레코드와 여섯 번째 레코드는 department와 관련된 레코드이기 때문에 이 둘을 chains하는 포인터를 추가할 수 있음.
B+-Tree 파일 구조
- 이진 검색 트리의 확장된 버전
- 루트 노드로부터 모든 단말 노드에 이르는 경로의 길이가 같은 높이 균형트리
- 순서 인덱스는 파일이 커질수록 데이터 탐색에 있어서 접근 비용이 커지는 문제점을 해결하기 위해 제안
- 상용 DBMS에서도 널리 사용되는 대표적인 순서 인덱스이다.
해시 파일 구조
- 해시 함수를 이용하는 방법으로, 해시 함수는 레코드의 탐색키를 입력받아 레코드가 저장될 블록의 주소를 반환하고, 해당 주소에 레코드를 저장하는 방식
- 특정 레코드를 검색해야 하는 경우 대부분의 경우 한번의 블록 접근으로 원하는 레코드를 찾을 수 있어
- 힙 파일, 순차 파일 구조 보다 블록 접근 측면에서 보면 검색 속도가 빠르다고 볼 수도 있겠으나, 문제는 해시 함수가 어떤 구조를 갖느냐에 따라 빠를 수도 있고, 느릴 수도 있다.
- 공간적인 측면에서 다른 파일 구조들과 비교 해본다면 블록 주소들을 저장해야하는 공간이 필요하므로 다른 파일 구조들에 비해 공간의 낭비가 있을 수 가 있음.
버퍼(Buffer)와 버퍼 매니저(Buffer Manager)
Buffer : portion of main memory available to store copies of disk blocks
Buffer Manager : subsystem responsible for allocating buffer space in main memory
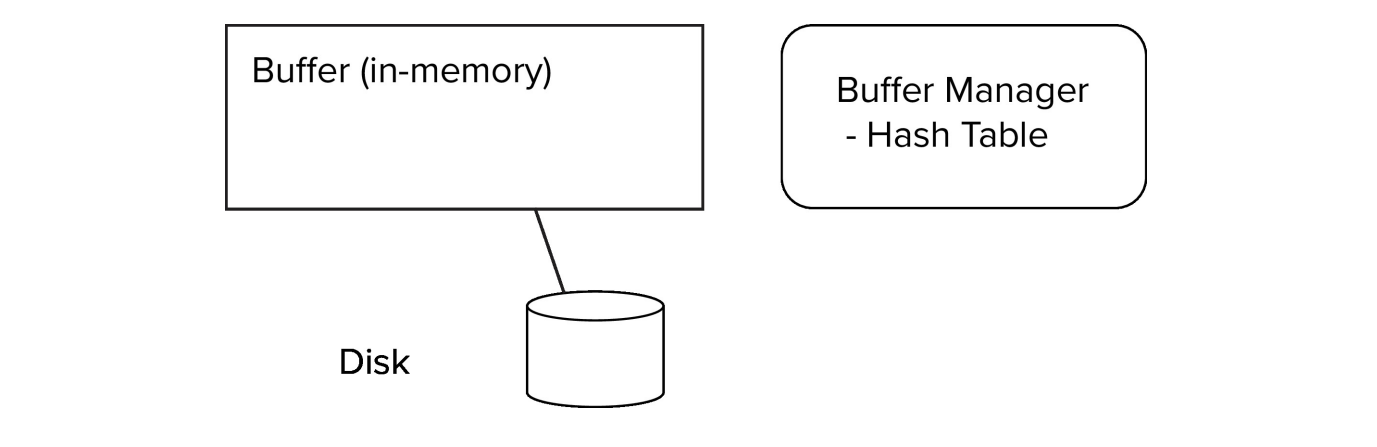
- 프로그램은 디스크에 있는 블록이 필요할 때 buffer manager를 호출한다.
- 만약 블록이 버퍼에 있다면, 버퍼 매니저는 메인 메모리에 있는 해당 블록의 주소를 반환함.
- 만약 블록이 버퍼에 있지 않다면, 버퍼 매니저는 해당 블록에 메모리를 할당함.
- 교체할 다른 블록을 선택해야함 -> victim을 선택
- 교체될 블록이 modified되어 있을 때만 디스크에 다시 저장함
버퍼 교환 정책(Buffer - Replacemnet Policies)
LRU (Least Recently Used)
- 많은 OS에서 사용하고 있는 정책
- 사용된지 가장 오래된 블록을 교체하자
- 하지만 몇몇 쿼리에서는 비효율적일 수 있음
Toss-immediate
- 블록의 마지막 레코드가 처리되면 바로 메모리를 해제해 버리는 것
MLR (Most Recently Used)
- 가장 최근에 접근되었고 unpin된 블록을 교체하자.
출처
javatpoint
