
정의
인덱스(Index)는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다. (왜냐하면 보통 인덱스는 키-필드만 갖고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문이다.) 관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본이다.
인덱스 파일은 index Entries로 이루어져 있다.
- search-key : attribute to set of attributes used to look up records in a file.
- pointer : attrubte used to point to address of record

인덱싱 평가 지표
- Access types supported efficiently
- records with a specified value in the attribute -> 특정 attribute 값으로 조회
- records with an attribute value falling in a specified range of values
-> 범위 조회
Hash index는 1은 지원하지만 2는 지원하지 않는다.
B+ tree index는 1,2 모두 지원한다.
- Access time
- Insertion time
- Deletion time
- Space Overhead
인덱싱의 종류

Primary index ( Clustering Index)
- in a sequentially orderedd file , the index whose search key specifies the sequential order of the file -> search key와 record의 정렬 순서가 일치하는 경우
- search key가 보통 primary key이지만 꼭 그럴 필요는 없다.
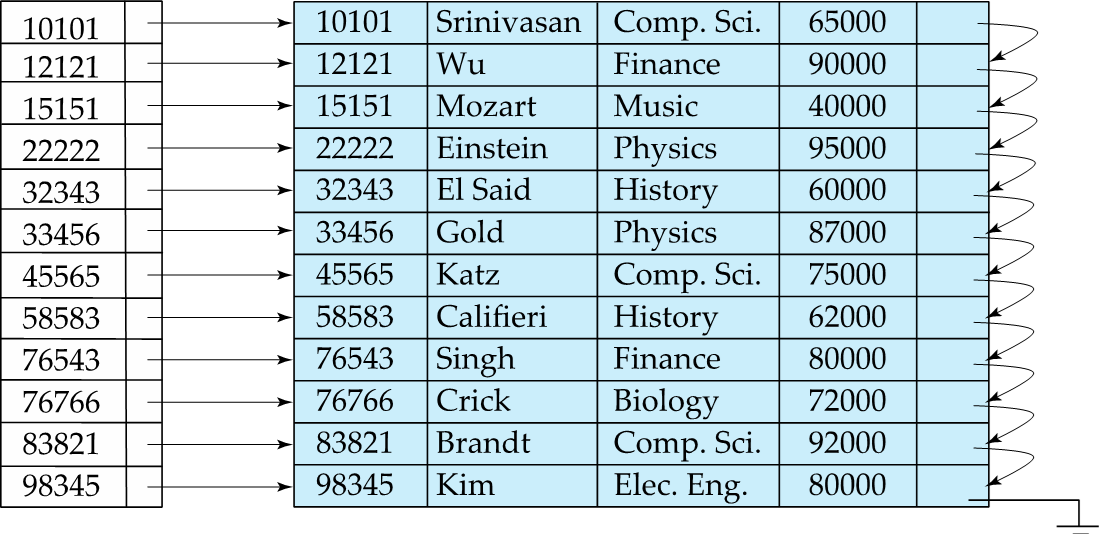
Dense Index
Index record appears for every search-key value in the file.
: 파일에 모든 search-key에 대해 Index record 존재.
- Dense Index에서는 데이터베이스에 저장된 모든 서치키마다 레코드가 생긴다. 이 점은 검색을 빠르게 해줄 수 있지만 인덱스 정보를 기록해야 하기 때문에 더 많은 저장 공간을 필요로 한다. 덴스 인덱싱에서는 두번 째열이 서치 키의 값과 디스크에 저장되 있는 실제 정보를 가리킨다.
- 한번의 디스크 검색만으로 서치 키를 사용해 어떠한 레코드던 찾을 수 있다. 키 값들이 정리되어 있기에 이진탐색을 할 수 있다. log2(n) 만큼 소요.
Dense Index on ID , with instructor file sorted on ID
Dense Index on dept_name , with instructor file sorted on dept_name
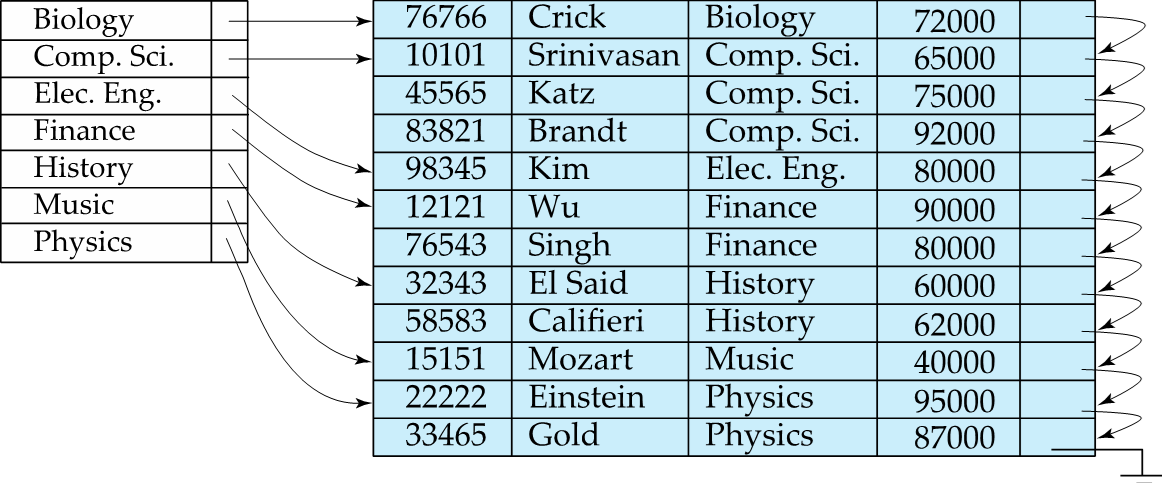
Sparse Index
- Index record appears or only some search-key values.
- Applicable when records are sequentially ordered on search-key
: 몇몇 searck-key에 대해서만 Index record 존재. 그리고 records가 search-key로 정렬되어 있을 때만 적용 가능.
-
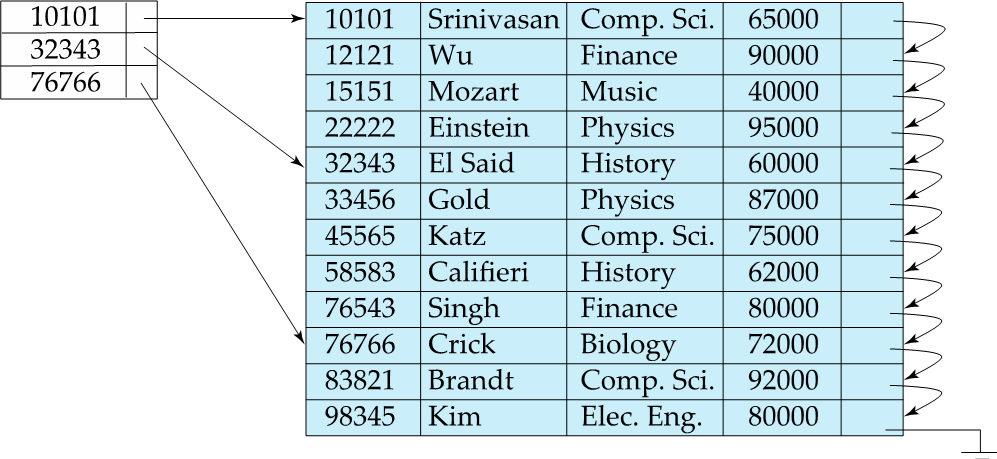
Sparse Index는 파일 안의 몇 개의 값을 위해 저장해 놓는 인덱스 기록 방법이다. 덴스 인덱싱의 저장공간 필요를 해결하는데 도움을 주는 이 방법은, 첫번째 인덱스 열이 같은 데이터 블럭 주소를 저장하기에 데이터가 필요할 때는 그 블럭의 주소를 불러온다.
-
하지만 몇 개의 서치 키 값을 위한 인덱스 기록만 저장하기 때문에 저장 공간이 덜 필요하고 overhead (주소를 가리키는 머리)를 추가하거나 제거할 때 신경쓸 부분이 줄어들지만 원하는 레코드를 찾아올 때는 블럭만을 가져오기에 덴스 인덱싱 보다 레코드를 찾아오는 부분에서는 속도가 느리다.
-
search-key value K로 조회하고 싶을 때
-> find index record with largest search key value < K
-> 예를 들어 K가 45565라면 , 45565보다 작으면서 가장 큰 search-key는 32343.
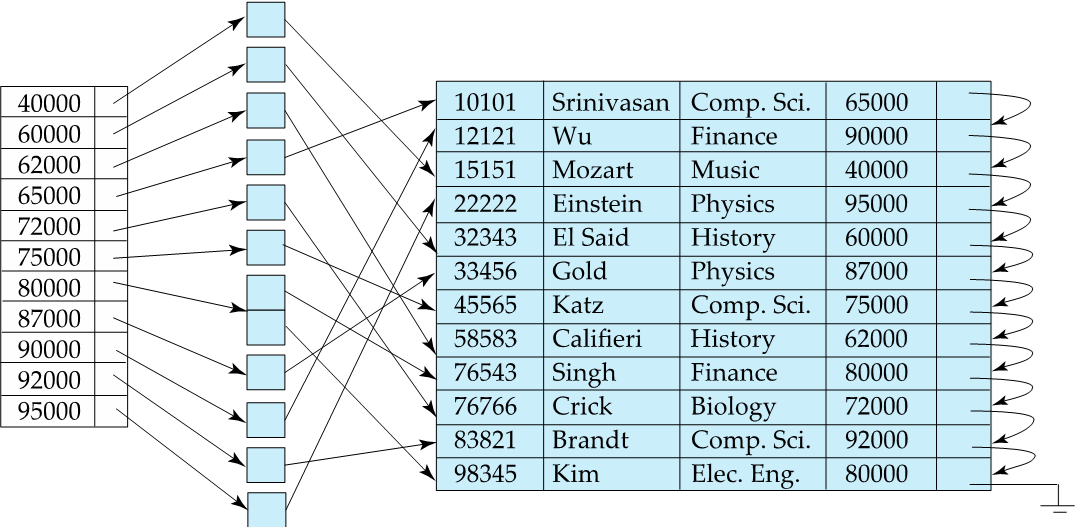
Secondary index( Non Clustering Index)
- an index whose search key specifies an order different from the sequential order of the file. -> search key와 record의 정렬 순서가 다른 경우
Secondary Index on salary field of instructor
Index record의 pointer는 bucket을 가리킨다. 그리고 bucket은 search-key value에 따른 실제 데이터를 가리킨다.
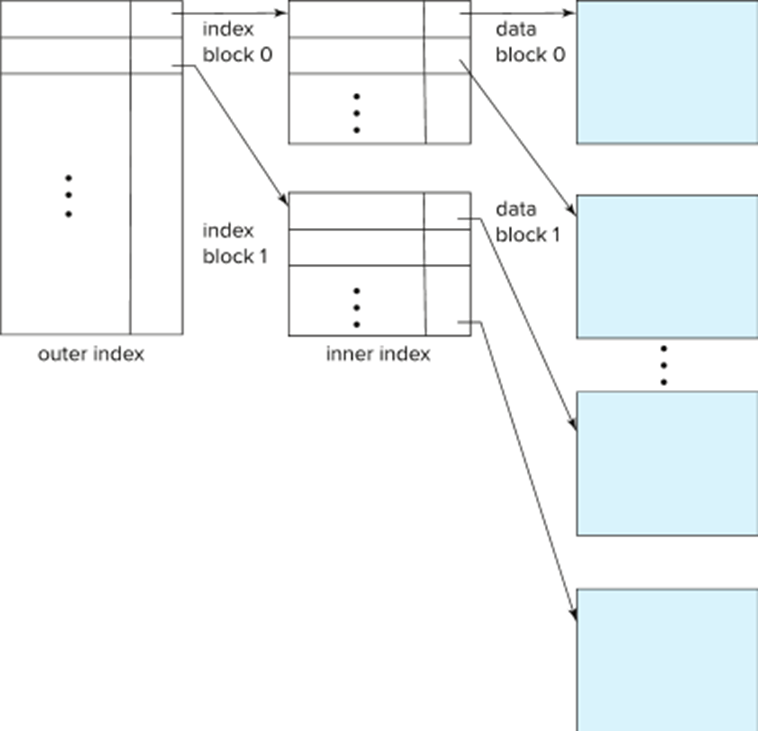
Multilevel Index
If index does not fit in memory, access becomes expensive.
: index file이 너무 커져서 memory에 맞지 않으면 IO가 증가해서 access 비용 증가
Solution: treat index kept on disk as a sequential file and construct a sparse index on it.
- outer index – a sparse index of the basic index
- inner index – the basic index file
Non-unique keys

create index salary_index on instructor(salary) 이런 식으로 salary에 대해서 index를 만드는 sql을 날렸으면, salary는 unique하게 레코드를 식별할 수 없기 때문에 내부적으로 salary와 recordId와 합성한 키를 searck-key로 해서 index를 만들게 된다.
그래서 select * from instructor where salary = 80000 이런 식으로 salary가 80000인 레코드를 조회한다면, 다음과 같은 range 질의로 바뀌어서 sql 실행됨.
where (salray,recordId) >= ( 80000, -∞) and (saray,recordId) <= ( 80000, +∞)
인덱싱의 장점과 단점
장점
- Indices offer substantial benefits when searching for records.
단점
- indices imposes overhead on database modification
when a record is inserted or deleted, every index on the relation must be updated
When a record is updated, any index on an updated attribute must be updated - Sequential scan using clustering index is efficient, but a sequential scan using a secondary (nonclustering) index is expensive on magnetic disk
Each record access may fetch a new block from disk
Each block fetch on magnetic disk requires about 5 to 10 milliseconds
