
Exter Sort Merge
데이터가 메모리에 다 적재할 수 있는 경우에는 Quick Sort를 사용하여 정렬을 할 수 있다. 하지만 데이터 베이스 환경에서는 모든 데이터가 메모리에 올라갈 수 없기 때문에, 이런 경우에는 Externl sort-merge가 좋은 선택이 될 수 있다.
-
메모리 제한: 컴퓨터 메모리의 크기는 제한되어 있습니다. 만약 정렬해야 하는 데이터의 크기가 메모리보다 크다면, 모든 데이터를 메모리에 올리는 것은 불가능합니다. 이때 외부 정렬을 사용하면 파일에 저장된 데이터를 일부씩 읽어와서 정렬할 수 있습니다.
-
빠른 처리: 외부 정렬은 디스크의 파일에 저장된 데이터를 일부씩 읽어와 정렬하므로, 전체 데이터를 한번에 읽어와서 정렬하는 방식보다는 느리지만, 여러 번의 디스크 접근을 최소화하면서 빠르게 처리할 수 있습니다.
-
대용량 데이터 처리: 외부 정렬은 대용량의 데이터를 처리하는 데 효과적입니다. 외부 정렬을 사용하면 대용량의 데이터도 파일에 저장하고 필요한 부분만 읽어와서 정렬할 수 있으므로, 컴퓨터 메모리의 제한을 극복할 수 있습니다.
-
안정성: 외부 정렬은 정렬 과정에서 데이터의 안정성을 보장합니다. 메모리에 모든 데이터를 한번에 올리는 방식은 정렬 중에 메모리 오버플로우 등의 문제가 발생할 수 있습니다. 반면에 외부 정렬은 파일에 저장된 데이터를 일부씩 읽어와 정렬하기 때문에 이러한 문제를 예방할 수 있습니다.
Process
M을 메모리 사이즈로 표시한다(사용할 수 있는 페이지 수)
-
정렬된
run을 만든다. (initial-runs)
-> 디스크에서M개의 블록을 메모리에 적재한다.
-> 메모리에 있는 블록들을 정렬한다. (내부정렬)
-> 정렬된 데이터를 다시 디스크에 저장한다. (initail run생성)
-> relation 끝까지 반복
->N개의initial run들을 생성한다. -
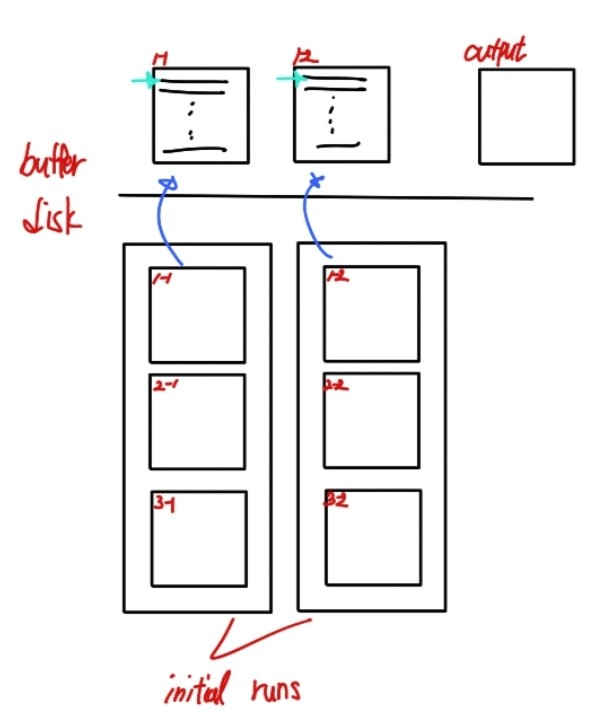
runs들을Merge한다.CASE 1. N < M
1. N개의 run들을 올리기 위해 N개의 페이지를 사용하고 1개는 Output을 저장하기 위한 페이지로 사용한다. 각 Run에서 첫 번째 블록을 읽어와 페이지에 저장한다.
2. 각 버퍼에서 첫번째 레코드를 선택한다. 정렬 우선순위에 따른 알맞은 레코드를 선택하고 Output 페이지에 저장한다. 해당 레코드는 해당 버퍼에서 삭제한다.
3. 만약 페이자가 비어 있다면, 해당 run에서 다음 블록을 읽어온다.
4. 모든 페이지가 빌 때까지 반복
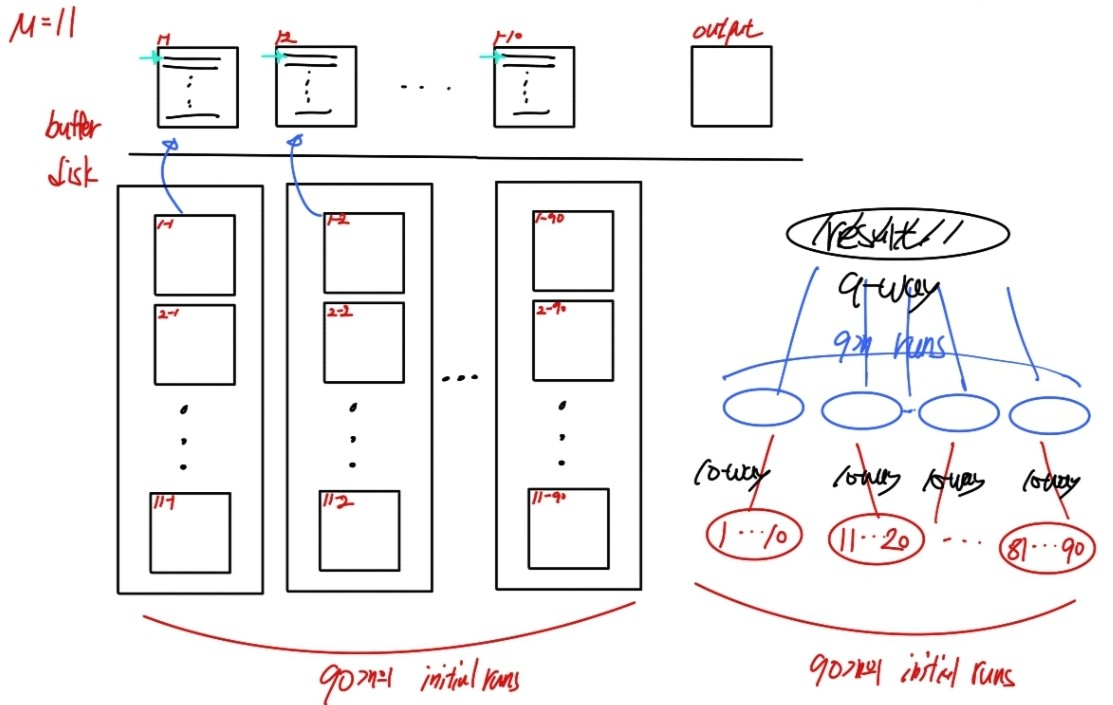
Case2. N >= M
보통은 사용할 수 있는 페이지의 수보다 RUN의 개수가 많은 상황이 일반적이다. 몇번의 merge pass가 필요함.1. 각 pass 마다
M-1개의runs을 머지한다.r2. 각 pass가 지날 때마다
1/(M-1)만큼runs이 수가 작아진다.
ex) M=11, 이고initial runs이 90개라면, pass가 한번 지나면 다음 번에는 9개의 run으로 줄어든다.3. 모든 run이 1개로 머지될 때까지 반복한다.
Cost Analysis
- br : 블록 수
- M : 버퍼 페이지 수
- 2br * ( # of passes ) + 2br
(초기 run 만들 때)- br(최종결과 output으로 쓰는 것 제외)

