
빙터뷰 프로젝트에서 사용한 기본적인 데이터는 뷰인터에서 크롤링을 이용해 수집했다.
크롤링 여부를 확인해본 결과 Allow : / 이여서 마음 놓고 크롤링을 진행했다.

크롤링을 진행한 데이터는 다음과 같이 대분류, 중분류, 소분류 태그와 각 태그에 딸려 있는 질문들이다.
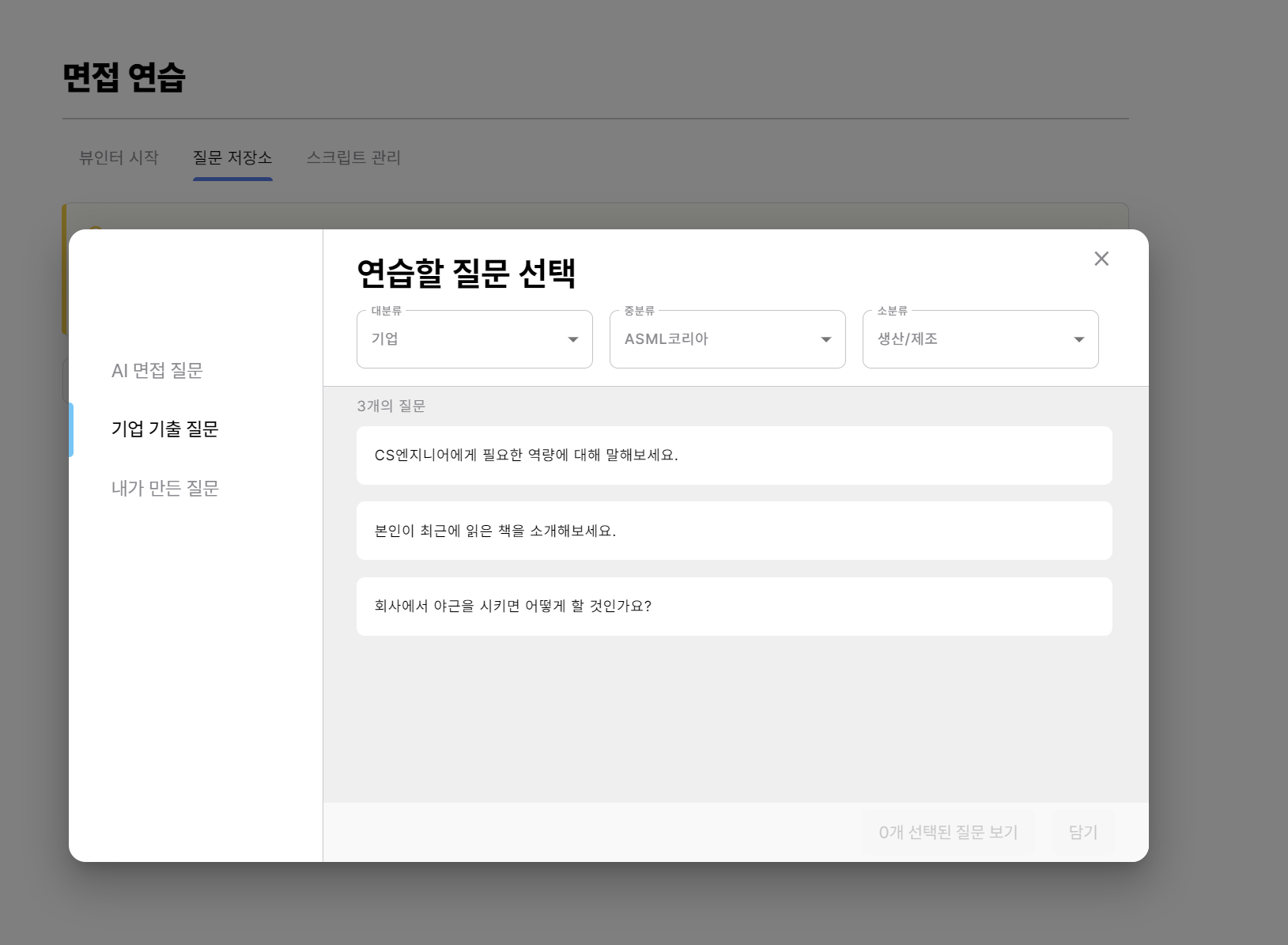
중분류 태그에 존재하는 기업 정보와 소분류 태그에 존재하는 직무 정보는 개수가 몇개 안돼서 직접 python HTMLParser를 이용하여 html 파일을 파싱하여 데이터를 수집하였다.
from html.parser import HTMLParser
ret = []
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Encountered a start tag:", tag)
def handle_endtag(self, tag):
print("Encountered an end tag :", tag)
def handle_data(self, data):
print("Encountered some data :", data)
ret.append(data)
file = open('html.txt', 'r',encoding='utf-8')
txt = file.read()
parser = MyHTMLParser()
parser.feed(txt)
file2 = open('소분류.txt','a',encoding='utf-8')
file2.write(','.join(ret)+'\n')
file.close()
file2.close()문제는 이제 직무별로 질문들을 수집해야 했는데, 기업들이 약 100개 정도 되고 한 기업에 적어도 4개 이상의 직무가 존재했기 때문에 500개가 넘는 직무를 일일히 들어가서 HTMLParser를 이용해서 데이터를 수집할 수 없었다. 그래서 이를 자동화 하기 위해 셀레니움을 이용해 데이터 수집을 진행했다.
# selenium의 webdriver를 사용하기 위한 import
from selenium import webdriver
# selenium으로 키를 조작하기 위한 import
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# 페이지 로딩을 기다리는데에 사용할 time 모듈 import
import time
import json
# 크롬드라이버 실행
# 경로 예: '/Users/Name/Downloads/chromedriver'(Mac OS)
driver = webdriver.Chrome('chromedriver.exe')
#크롬 드라이버에 url 주소 넣고 실행
driver.get('https://front.viewinter.ai/index.html#/login/')
# 페이지가 완전히 로딩되도록 5초동안 기다림
time.sleep(3)
id_input = driver.find_element(By.XPATH,'//*[@id="root"]/section/section/section/div[2]/section/form/input[1]')
secret_input = driver.find_element(By.XPATH,'//*[@id="root"]/section/section/section/div[2]/section/form/input[2]')
id_input.send_keys("ID")
secret_input.send_keys("PASSWORD")
time.sleep(3)
loginbutton = driver.find_element(By.XPATH,'//*[@id="root"]/section/section/section/div[2]/section/form/div[3]/div[1]')
loginbutton.click()
time.sleep(3)
quizRepoButton = driver.find_element(By.XPATH,'//*[@id="root"]/section/section/section/div[2]/section/div[1]/div/div[2]/button/span[1]')
quizRepoButton.click()
time.sleep(3)
quizAddButton = driver.find_element(By.XPATH,'//*[@id="root"]/section/section/section/div[2]/section/div[2]/div[2]/div/div[2]/div/button[1]')
quizAddButton.click()
time.sleep(3)
기출질문버튼 = driver.find_element(By.XPATH,'/html/body/div[6]/div[3]/div/div/div[1]/div/div[2]/button')
기출질문버튼.click()
time.sleep(3)
ret = dict()
for i in range(1,203):
midLevel = driver.find_element(By.XPATH,'/html/body/div[6]/div[3]/div/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div')
midLevel.click()
time.sleep(3)
XPATH = '//*[@id="menu-selected"]/div[3]/ul/li[' + str(i) + ']'
기업 = driver.find_element(By.XPATH,XPATH)
기업이름 = 기업.get_attribute("textContent")
ret[기업이름] = dict()
print(기업이름)
기업.click()
time.sleep(3)
소분류 = driver.find_element(By.XPATH, '/html/body/div[6]/div[3]/div/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/div')
소분류.click()
time.sleep(3)
lis = driver.find_elements(By.TAG_NAME, 'li')
for li in range(1,len(lis)+1):
LIXPATH = '//*[@id="menu-selected"]/div[3]/ul/li['+ str(li) +']'
liButton = driver.find_element(By.XPATH,LIXPATH)
직무이름 = liButton.get_attribute("textContent")
ret[기업이름][직무이름] = []
print(직무이름)
liButton.click()
time.sleep(3)
questions = driver.find_elements(By.CLASS_NAME,'questionBar')
for question in questions:
p = question.find_element(By.TAG_NAME,'p')
질문 = p.get_attribute("textContent")
ret[기업이름][직무이름].append(질문)
print(질문)
if li == len(lis):
continue
소분류 = driver.find_element(By.XPATH,'/html/body/div[6]/div[3]/div/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/div')
소분류.click()
time.sleep(3)
print(ret)
# JSON 파일에 데이터 저장
with open("질문.txt", "w",encoding='utf-8') as file:
json.dump(ret, file,ensure_ascii=False)
수집한 데이터를 파싱까지 하면 다음과 같이 정리된 데이터를 얻을 수 있었다.

