순환 신경망
1) 순환 신경망: Recurrent Neural Network, RNN
RNN은 Sequence 모델. 즉, 입력과 출력을 시퀀스 단위로 처리. 번역기를 생각해보면, 입력은 단어나 문장이 주어지고, 이를 원하는 국가의 언어로 번역해 준다. 시퀀스 처리를 위해 고안된 모델이 시퀀스 모델.
용어는 비슷하지만, 순환 신경망과 재귀 신경망(Recursive)는 다른 개념임
1. 순환 신경망
배웠던 신경망들은 전부 입력에서 출력으로 한 방향으로만 향했다. RNN은 그렇지 않음. 은닉층 노드에서 활성화 함수 결과를 출력층으로 보내면서도, 다시 은닉층 노드의 입력으로 보내는 특징을 갖고 있음.
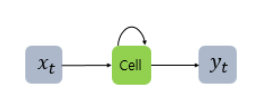 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀이라고 함. 이 셀은 이전 값을 기억하려는 메모리 역할을 수행하므로 메모리 셀 또는 RNN 셀이라고 함.
은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀이라고 함. 이 셀은 이전 값을 기억하려는 메모리 역할을 수행하므로 메모리 셀 또는 RNN 셀이라고 함.
각각의 시점(time-step) 바로 이전 시점에서 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 하고있음. 현재를 t라고 표현, t에서의 메모리 셀이 갖고있는 값은 과거 메모리 셀들의 영향을 받은 것을 의미.
메모리 셀이 출력층 방향 또는 다음 시점 t+1 자신에게 보내는 값을 은닉 상태(hidden state)라고 함. t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력으로 사용. -> 이전 시점의 메모리 셀에서 보낸 은닉 값을 현재 시점의 은닉 상태 계싼을 위한 인풋이 됨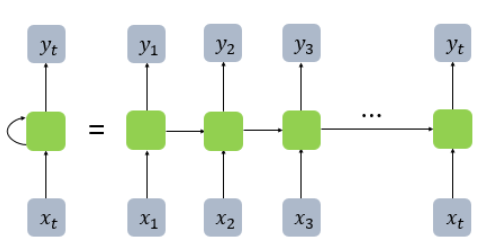 이 두개의 그림이 RNN을 표현하는 방식. 우측이 시점의 흐름에 따라 표현한 것이고, 좌측은 이를 그냥 함축한 것. 둘이 같은 것.
이 두개의 그림이 RNN을 표현하는 방식. 우측이 시점의 흐름에 따라 표현한 것이고, 좌측은 이를 그냥 함축한 것. 둘이 같은 것.
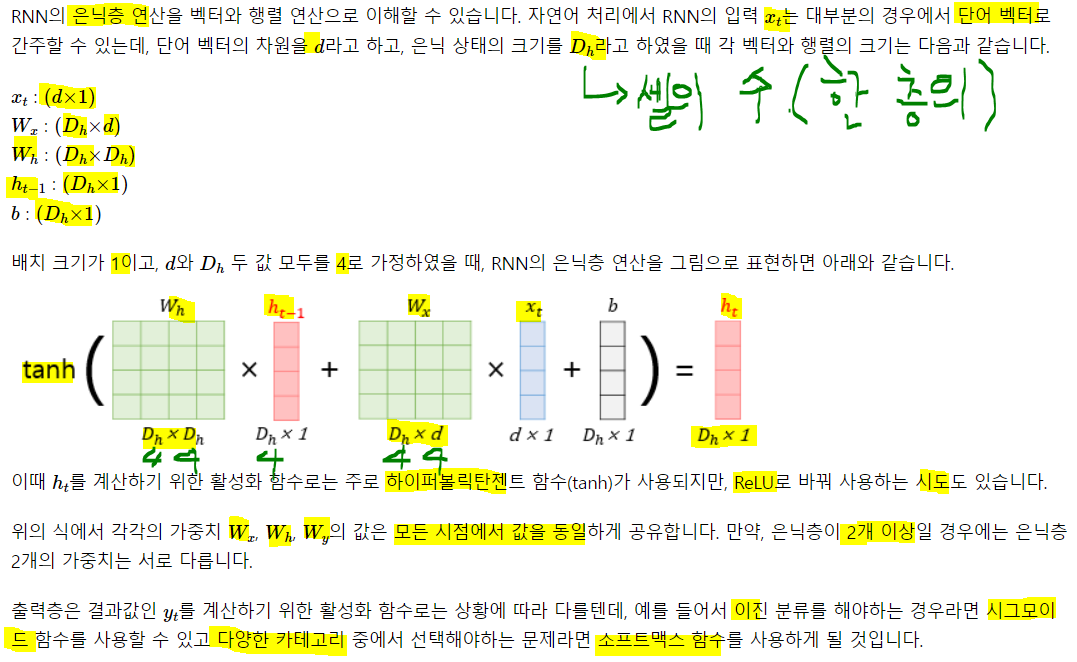
피드 포워드에선 뉴런이란 단위를 사용했지만, 순환신경망에선 뉴런이라는 단위보단, 입/출력층 에선 입력/출력 벡터, 은닉층에선 은닉 상태라는 말을 주로 씀. 따라서 위에서 회색, 연두색은 기본적으로 벡터 단위를 가정.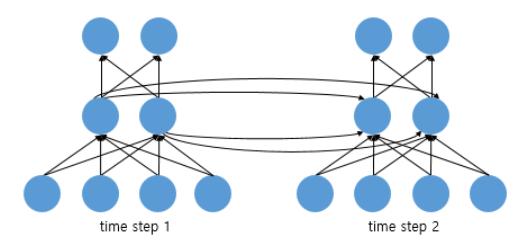
RNN을 뉴런 단위로 표현하면 위와 같다. t1에서 t2로 은닉 값을 넘겨주고 이를 받아 은닉 상태 계산의 입력 중 일부로 사용. 입력 벡터 차원이 4, 은닉 상태 크기가 2, 출력층 벡터 차원의 크기가 2인 RNN이 time-step이 2일 때 모습을 보여준다. 보통 time-step의 크기를 사용자가 지정해주는 듯.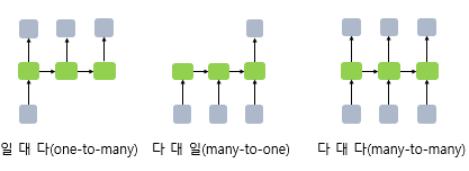
RNN은 입력과 출력의 길이를 다르게 설계 가능해 여러 용도로 사용. RNN 셀의 각 시점별 입, 출력의 단위는 정의 나름이지만, 가장 보편적 단위는 '단어 벡터'
입력은 하나였지만 여러개를 출력하는 일대다, 입력은 여러개지만 하나를 출력하는 다대일, 입력도 여러개 출력도 여러개인 다대다가 대표적인 구조
one-to-many의 경우 하나의 이미지 입력에 대해 사진의 제목을 출력하는 이미지 캡셔닝에 사용할 수 있다. 제목은 단어들의 나열이므로 시퀀스 출력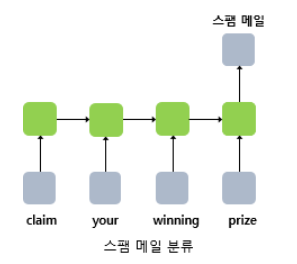 단어 시퀀스에 대해 하나의 출력을 하는 모델은 입력 문서가 감성 분류, 스팸 메일 분류등에 사용가능. RNN을 활용해 스팸 메일을 분류할 때의 아키텍처임.
단어 시퀀스에 대해 하나의 출력을 하는 모델은 입력 문서가 감성 분류, 스팸 메일 분류등에 사용가능. RNN을 활용해 스팸 메일을 분류할 때의 아키텍처임.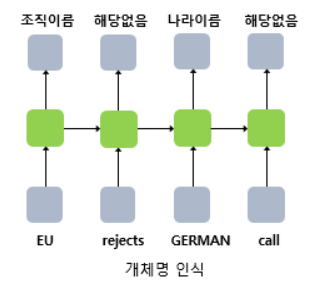
many-to-many의 경우 입력 문장으로 부터 대답 문장을 출력하는 챗봇과, 번역된 문장을 출력하는 번역기, 개체명 인식 혹은 품사 태깅에 속함.
2. 케라스로 RNN 구현
model.add(SimpleRNN(hidden_size)) # 가장 간단한 코드# 추가 인자를 사용할 때
model.add(SimpleRNN(hidden_size, input_shape = (timesteps, input_dim)))
# another expression
model.add(SimpleRNN(hidden_size, input_length = M, input_dim = N)) mat 한 장이라고 표현하겠음. input_length는 큰 시퀀스 -> 주로 영향을 서로 준다고 생각하는 단위 예를들면 일 단위의 시계열 자료라면 1주를 기준으로 주던 이런식. input_dim은 각 시퀀스의 차원 -> 몇 개의 원소로 구성되어있는 지.
mat 한 장이라고 표현하겠음. input_length는 큰 시퀀스 -> 주로 영향을 서로 준다고 생각하는 단위 예를들면 일 단위의 시계열 자료라면 1주를 기준으로 주던 이런식. input_dim은 각 시퀀스의 차원 -> 몇 개의 원소로 구성되어있는 지.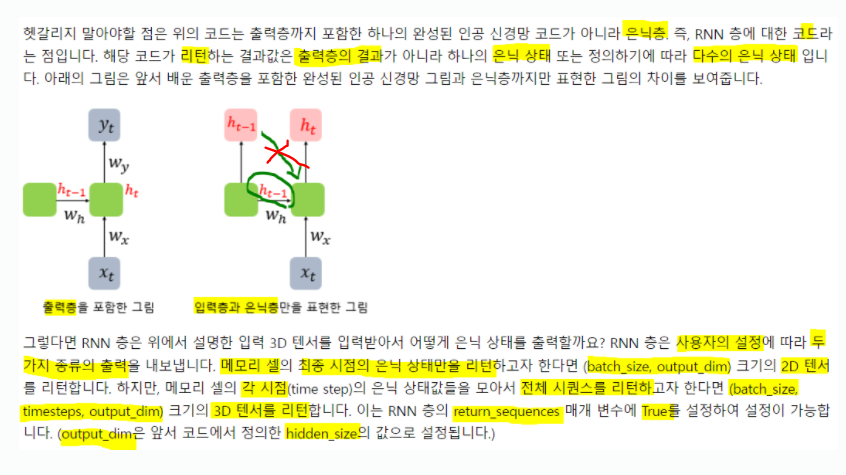
뒤에서 배우는 LSTM, GRU도 내부 매커니즘은 다르지만, model.add()를 통해 layer를 쌓아나가게 된다
from keras.models import Sequential
from keras.layers import SimpleRNN
model = Sequential()
## hidden_size = 3, input_length = 2, input_dim = 10
## hidden cell이 3개, time step이 2, 각 시퀀스당 원소 10개
model.add(SimpleRNN(3, input_shape = (2, 10)))
## model.add(SimpleRNN(3, input_lenght = 2, input_dim = 10))과 동일
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 3) 42
=================================================================
Total params: 42
Trainable params: 42
Non-trainable params: 0출력 값이 batch_size, output_dim(=hidden cell size) 이므로 2D 텐서임. batch size는 현 단계에선 알 수 없으므로 None.. 이제야 알았음....
model = Sequential()
model.add(SimpleRNN(3, batch_input_shape = (8, 2, 10)))
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_1 (SimpleRNN) (8, 3) 42
=================================================================
Total params: 42
Trainable params: 42
Non-trainable params: 0batch까지 표현된 것을 알 수 있음!!
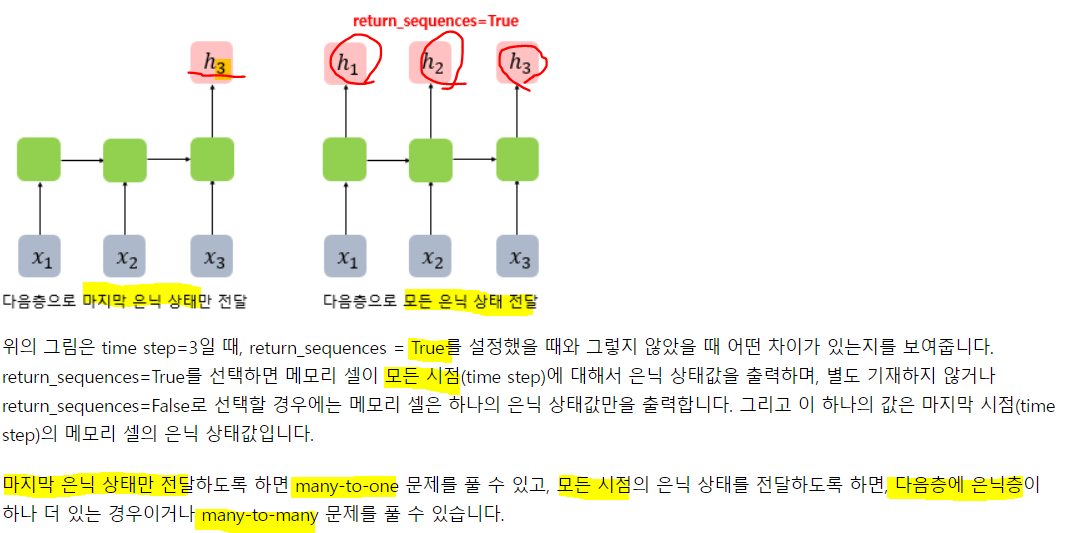
return_sequences를 True로 주어 3개의 히든 값을 출력하도록 함!
model = Sequential()
model.add(SimpleRNN(3, batch_input_shape = (8, 2, 10), return_sequences = True))
model.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_2 (SimpleRNN) (8, 2, 3) 42
=================================================================
Total params: 42
Trainable params: 42
Non-trainable params: 0output shape이 3차원 텐서로 늘어났음!
3. 파이썬으로 RNN 구현하기
numpy로 RNN을 구현해보자
로 은닉상태를 계산했었음
# 아래의 코드는 의사 코드(pseudocode)로 실제 동작하는 코드가 아님.
hidden_state_t = 0 # 초기 은닉 상태를 0(벡터)로 초기화
for input_t in input_length: # 각 시점마다 입력을 받는다.
output_t = tanh(input_t, hidden_state_t) # 각 시점에 대해서 입력과 은닉 상태를 가지고 연산
hidden_state_t = output_t # 계산 결과는 현재 시점의 은닉 상태가 된다.각 셀은 t 시점의 은닉상태를 계산하기 위해 인풋과 t-1 시점의 은닉상태 값을 인풋으로 활성화 함수의 출력 값으로 계산!
import numpy as np
timesteps = 10 # 시점의 수 NLP에선 보통 문장의 길이
input_dim = 4 # 입력의 차원. NLP에선 보통 단어 벡터의 차원
hidden_size = 8 # 은닉 상태의 크기. 메모리 셀의 용량
# 이해를 돕기위해 (timesteps, input_dim)으로 인풋을 설정했지만
# 케라스에선 (batch_size, timesteps, input_dim)을 인풋으로 받는다.
inputs = np.random.random((timesteps, input_dim)) # 입력에 해당되는 2차원 텐서
hidden_state_t = np.zeros((hidden_size,))
# 초기 은닉 상태는 0
# 은닉 상태의 크기로 은닉 상태를 만듦
print(hidden_state_t)[0. 0. 0. 0. 0. 0. 0. 0.]# 가중치와 편향 설정
# 8, 4 크기의 2D 텐서. 입력을 위한 가중치
Wx = np.random.random((hidden_size, input_dim))
# 8, 8 크기의 2D 텐서. 은닉 상태의 가중치
Wh = np.random.random((hidden_size, hidden_size))
# 8, 크기의 1D 텐서. 편향
b = np.random.random((hidden_size,))
print(np.shape(Wx))
print(np.shape(Wh))
print(np.shape(b))(8, 4)
(8, 8)
(8,)모든 가중치의 값들은 랜덤하게 할당된 것!
total_hidden_state = []
# 메모리 셀 동작
for input_t in inputs:
output_t = np.tanh(np.dot(Wx, input_t) + np.dot(Wh, hidden_state_t) + b) # tanh(Wx * Xt + Wh * Ht-1 + b)
total_hidden_state.append(list(output_t)) # 각 시점의 은닉 상태의 값을 계속해서 축적
print(np.shape(total_hidden_state)) # 각 시점 t별 메모리 셀의 출력 크기는 (timestep, output_dim)
hidden_state_t = output_t # t시점의 hidden은 output!!(입력과 이전은닉의 가중합 + b의 활성함수 출력 값!!)
# 출력시 값을 깔끔하게 보여줌
total_hidden_state = np.stack(total_hidden_state, axis = 0)
print(total_hidden_state) # (timesteps, output_dim), 10, 8의 tensor를 보여줌(1, 8)
(2, 8)
(3, 8)
(4, 8)
(5, 8)
(6, 8)
(7, 8)
(8, 8)
(9, 8)
(10, 8)
[[0.99982132 0.99997723 0.99989196 0.99991973 0.99994923 0.99999833
0.99999939 0.99998869]
[0.99974263 0.9999187 0.99969568 0.99981932 0.99977407 0.99999367
0.99999653 0.99993311]
[0.99980556 0.99997787 0.99990589 0.99988172 0.99989049 0.99999725
0.99999787 0.99996039]
[0.99977577 0.99998239 0.99994567 0.99984129 0.99997001 0.99999637
0.99999932 0.99997892]
[0.99988121 0.99996804 0.99990061 0.99993933 0.99995235 0.99999901
0.9999995 0.99999377]
[0.99974639 0.99994325 0.99979589 0.99982641 0.99987908 0.99999449
0.99999805 0.99995615]
[0.99987718 0.9999827 0.99993631 0.9999353 0.99993767 0.99999898
0.99999907 0.99998793]
[0.99988728 0.99999025 0.99996197 0.99994742 0.99996876 0.99999931
0.99999953 0.99999336]
[0.99985682 0.99997774 0.99991428 0.99992387 0.99992802 0.99999861
0.99999897 0.99998512]
[0.99982638 0.99998074 0.99993813 0.99988009 0.99993701 0.99999756
0.99999865 0.99997312]]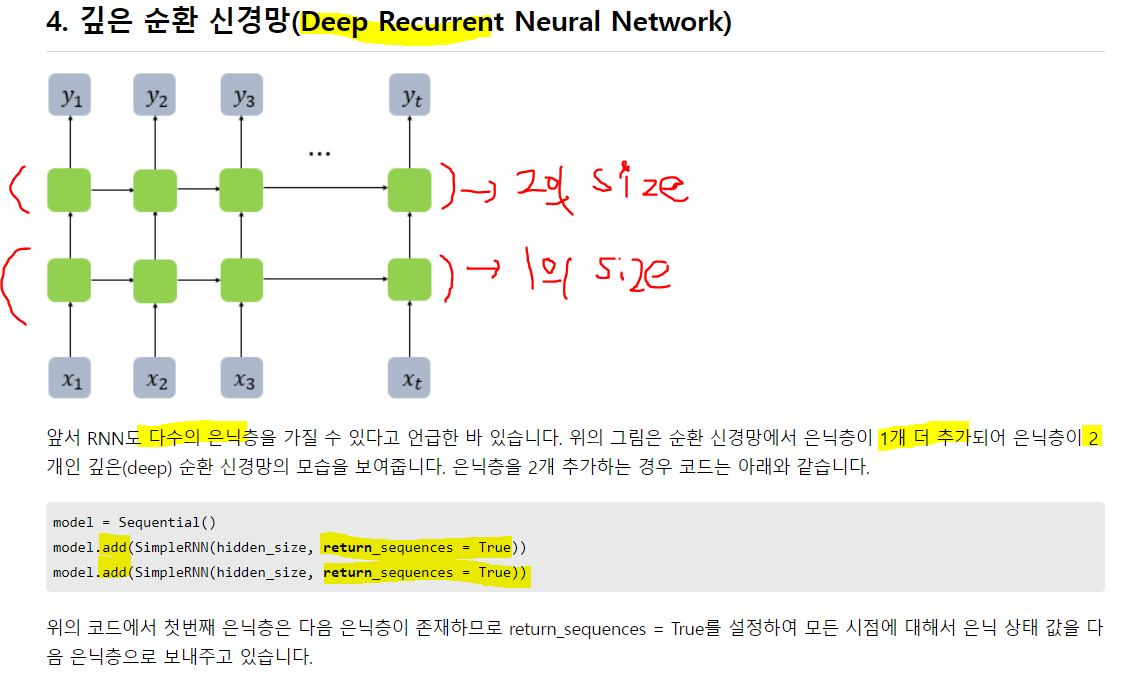

 1번 은닉층만 input_shape을 지정해줬음!
1번 은닉층만 input_shape을 지정해줬음!
6. 점검 퀴즈
RNN을 제대로 이해했는지 퀴즈를 통해서 확인해보세요! 모델에 대한 설명이 다음과 같을 때, 총 파라미터 개수를 구해보세요.
- Embedding을 사용하며, 단어 집합(Vocabulary)의 크기가 5,000이고 임베딩 벡터의 차원은 100입니다.
- 은닉층에서는 Simple RNN을 사용하며, 은닉 상태의 크기는 128입니다.
- 훈련에 사용하는 모든 샘플의 길이는 30으로 가정합니다.
- 이진 분류를 수행하는 모델로, 출력층의 뉴런은 1개로 시그모이드 함수를 사용합니다.
- 은닉층은 1개입니다.
input_dim = (100, 5000)
hidden_size = 128
batch_size= 30
model = Sequential()
model.add(SimpleRNN(128, input_shape = (100, 5000)))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "sequential_21"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_28 (SimpleRNN) (None, 128) 656512
_________________________________________________________________
dense_13 (Dense) (None, 1) 129
=================================================================
Total params: 656,641
Trainable params: 656,641
Non-trainable params: 0정답은
Embedding = 5000(input) 100(embedding) = 500,000
Wx = 100(embedding) 128(hidden) = 12,800
Wh = 128(hidden) * 128(hidden) = 16,384
bias(hidden) = 128
Wy = 128(hidden_size)
bias(output) = 1
2) 장단기 메모리(Long Short-term Memory, LSTM)
위에서 배운 RNN을 바닐라 RNN. 그 한계를 극복하기 위해 여러 모델들이 등장
1. 바닐라의 한계
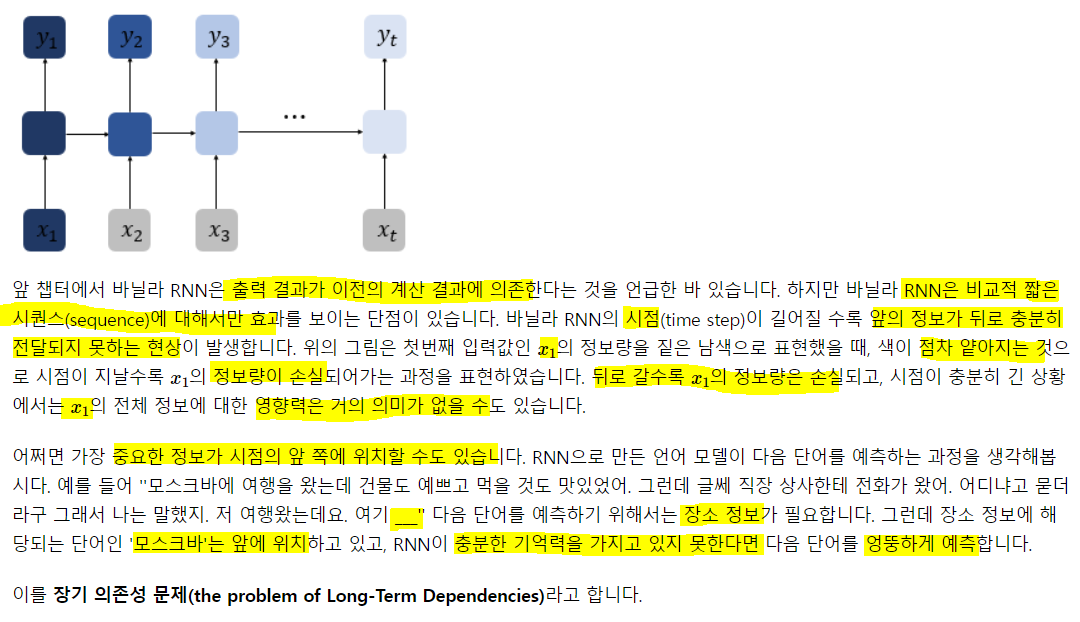
왜 의미가 줄어들까? 계속되는 가중치 곱과 활성화 함수에 의해 원래의 값이 자꾸 변형되기 때문!! 아마 줄어들 것임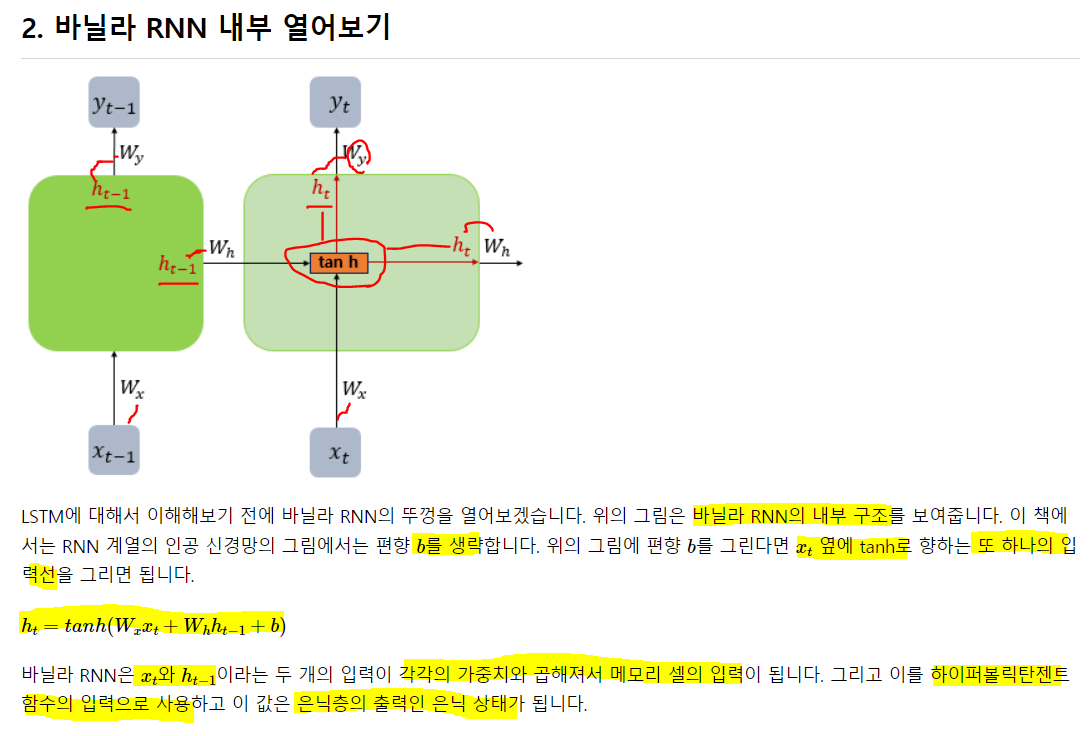
3. LSTM
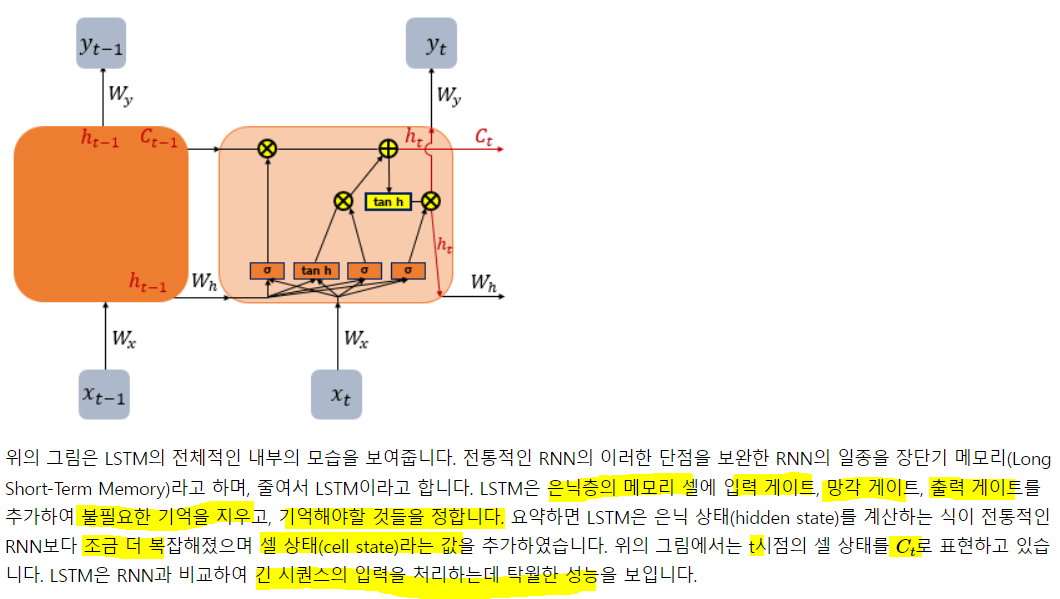
은닉층 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트가 생겨 불필요한 기억을 지우고, 기억해야할 것들을 정함. 복잡해 보이지만, 입/출/망 게이트가 은닉 셀에 있고 기억할 건 기억하고, 버릴 건 버린다는 것만 알아두자 일단.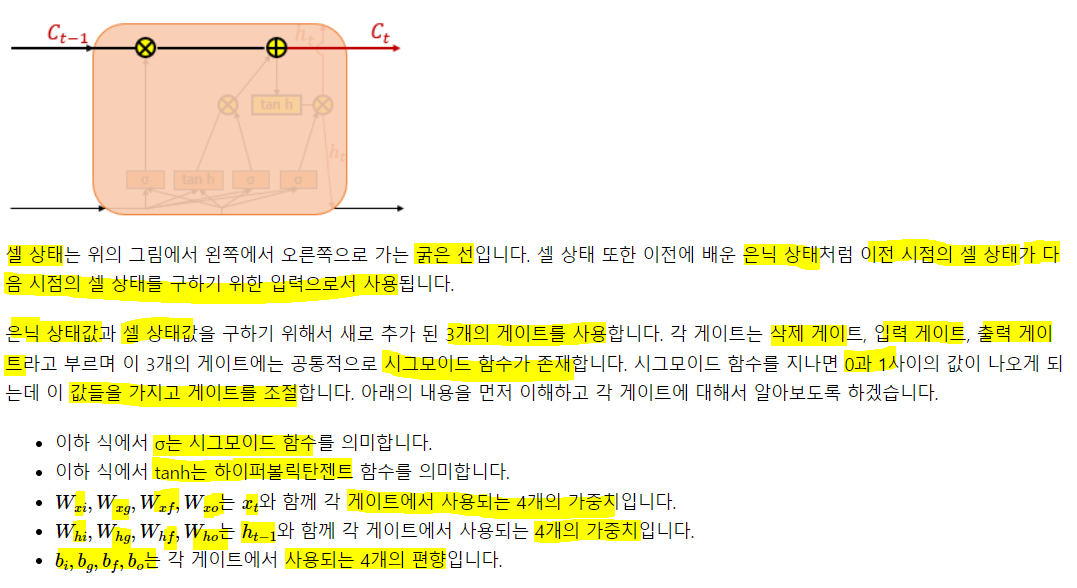
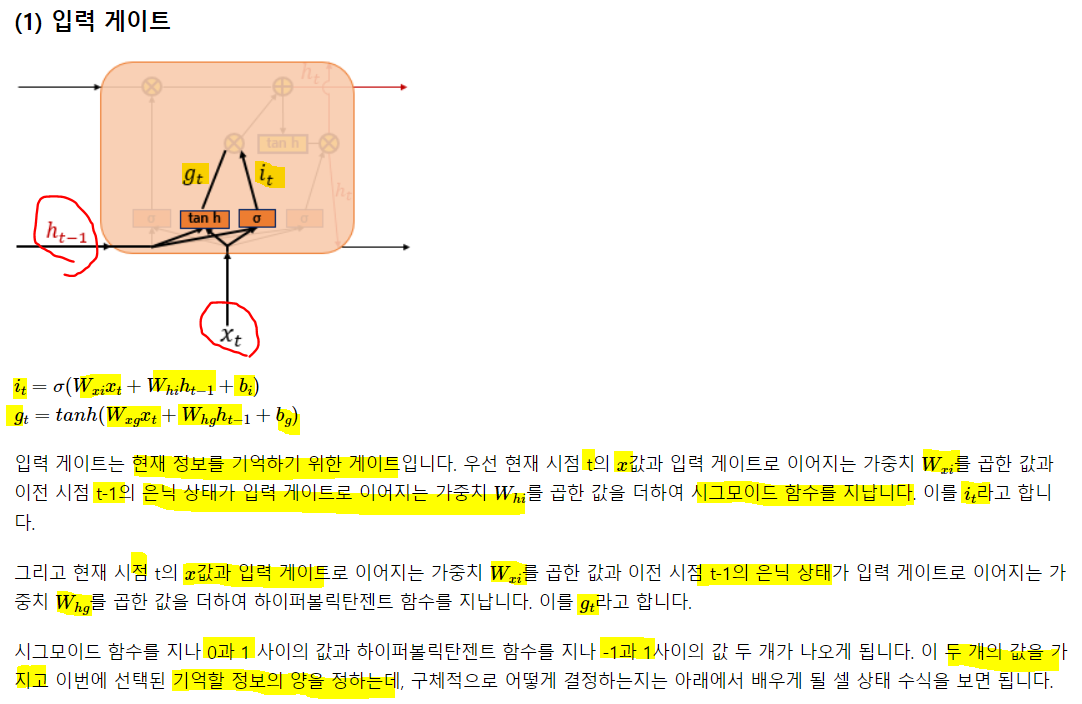 t시점의 x와 t-1시점의 은닉값과 i(시그모이드)와 g(하이퍼탄)가중치와의 가중합을 구해 i는 시그모이드, g는 하이퍼탄젠트에 넣어 출력된 값을 gt, it라 함. 이 것을 이용해 기억할 정보의 양을 정함
t시점의 x와 t-1시점의 은닉값과 i(시그모이드)와 g(하이퍼탄)가중치와의 가중합을 구해 i는 시그모이드, g는 하이퍼탄젠트에 넣어 출력된 값을 gt, it라 함. 이 것을 이용해 기억할 정보의 양을 정함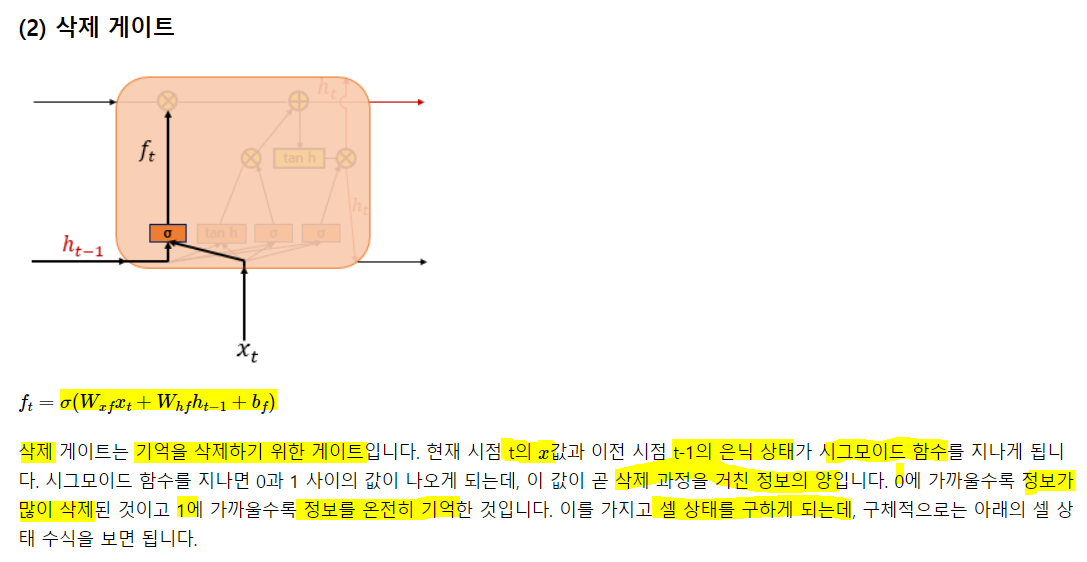
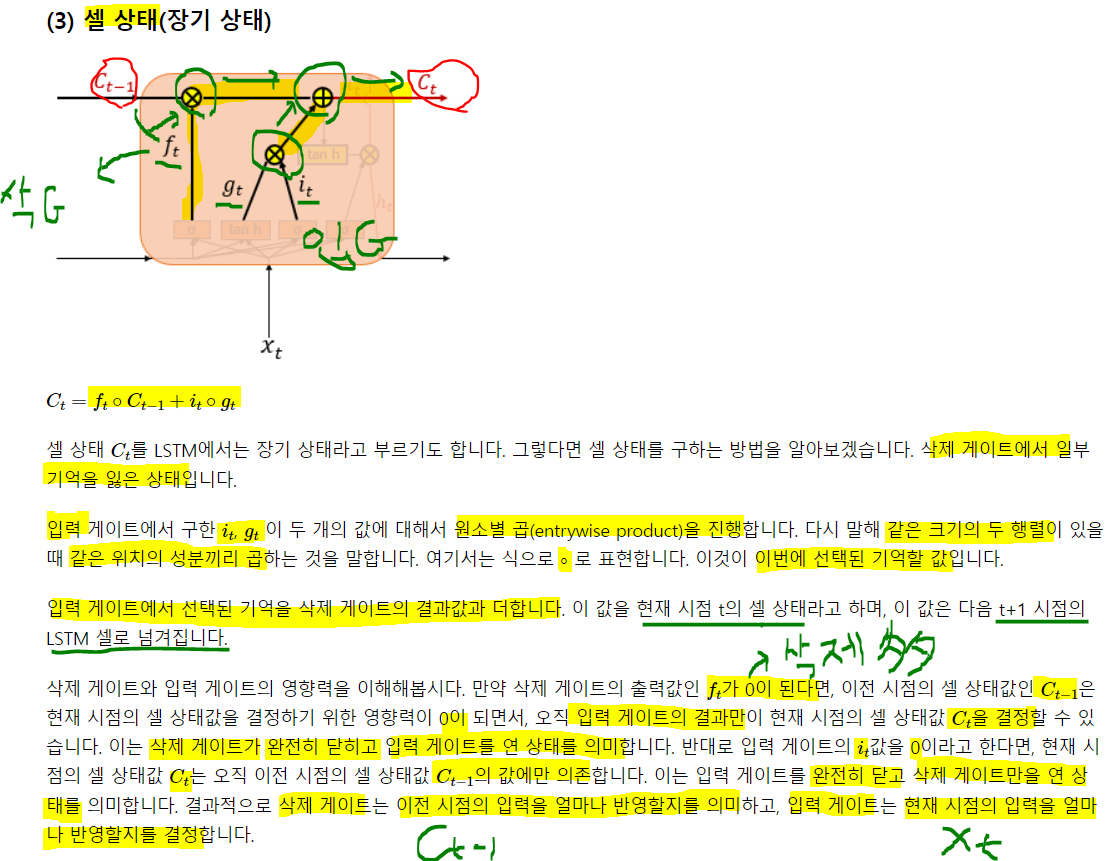
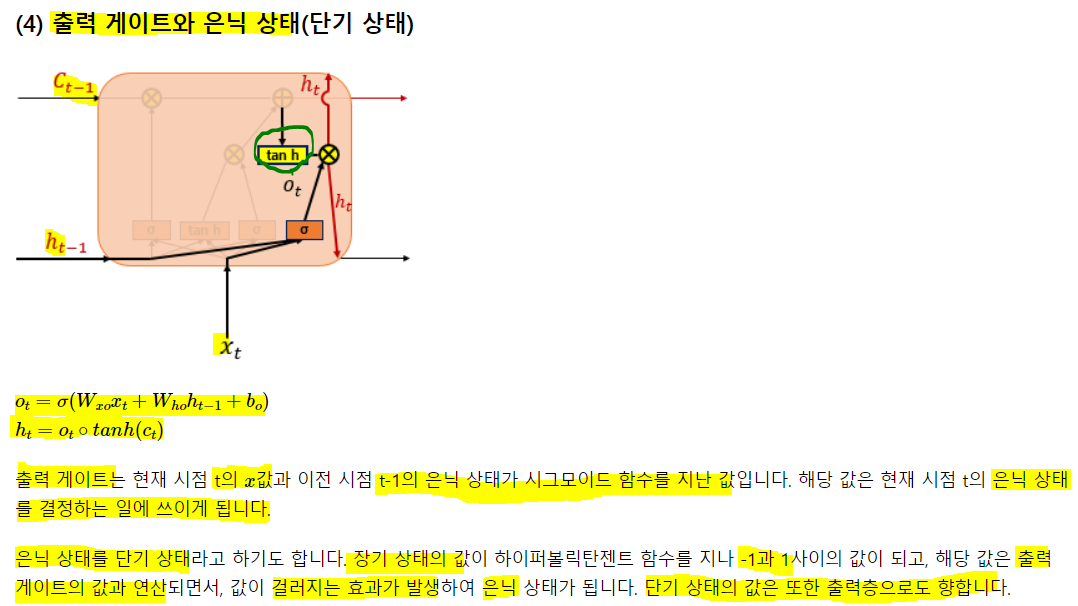
3) 게이트 순환 유닛(Gated Recurrent Unit, GRU)
GRU는 LSTM의 장기 의존성 문제에 대한 해결책을 유지하며, 은닉 상태를 업데이트 하는 계산을 줄였음. GRU는 성능은 LSTM과 유사하며, 복잡했던 LSTM 구조를 간단화 시킴.
1. GRU
LSTM에선 입력, 삭제, 출력 3개의 게이트가 존재. GRU는 업데이트, 리셋 두가지만 존재. 학습 속도는 GRU가 빠르다고 알려졌고, 성능 측면에서도 비슷하다 알려짐.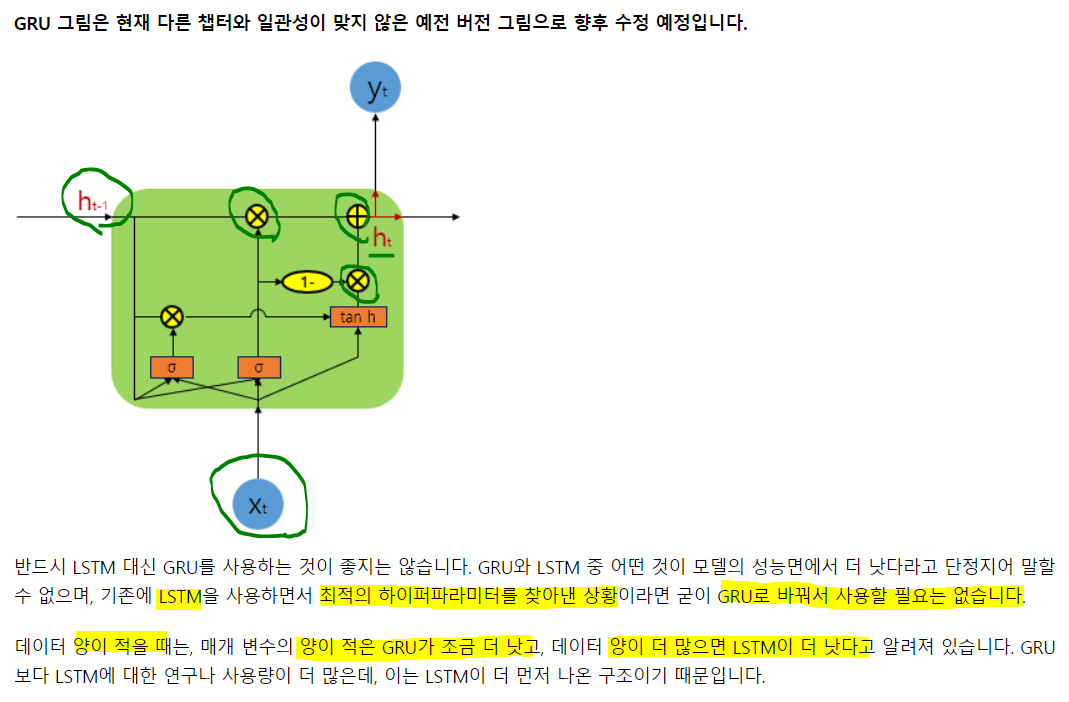 계산되는 과정에 대한 설명이 없으므로 자세하게 이해는 못하겠으나, RNN의 특성처럼 이전시점의 은닉 값과 현재 시점의 입력으로 현재 은닉을 계산하고 이걸 출력 or t+1 시점의 은닉 계산의 입력으로 사용.
계산되는 과정에 대한 설명이 없으므로 자세하게 이해는 못하겠으나, RNN의 특성처럼 이전시점의 은닉 값과 현재 시점의 입력으로 현재 은닉을 계산하고 이걸 출력 or t+1 시점의 은닉 계산의 입력으로 사용.
계산되는 과정에서 Xt는 시그모이드 두개, 하이퍼 탄젠트 하나를 지나고 첫번째 시그모이드의 출력은 xt와 함께 탄젠트의 입력이 됨 두번째 시그모이드는 올라가다 1)1-이란 연산을 해서 tanh의 결과와 연산되어 위로 올라가고, 2)두번 째 시그모이드값이 그냥 올라갔던 것이 ht-1과 연산되어 1)과 2)를 이용해 ht를 계산함.
2. 케라스에서 GRU
model.add(GRU(hidden_size, input_shape = (timesteps, input_dim)))GRU가 LSTM에 비해 더 간결. 우선 게이트 자체도 3개에서 두 개로 줄었기 때문. 빠른 결과를 원하면 GRU가 나은 것 같고.. 무조건 GRU > LSTM은 아님.
어떤 데이터를 넣냐에 따라 모델이 보이는 성능은 다르다고 생각한다. 따라서 딥러닝 모델도 교차검증을 해야하지 않을까?라고 생각한다.
4) 케라스의 SimpleRNN과 LSTM 이해하기
1. 임의의 입력 생성하기
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import SimpleRNN, LSTM, BidirectionalRNN과 LSTM을 테스트하기 위한 임의의 값을 만든다
train_X = [[0.1, 4.2, 1.5, 1.1, 2.8], [1.0, 3.1, 2.5, 0.7, 1.1], [0.3, 2.1, 1.5, 2.1, 0.1], [2.2, 1.4, 0.5, 0.9, 1.1]]
print(np.shape(train_X))(4, 5)단어 벡터의 차원은 5, 문장의 길이는4.
다시말해, 4번의 timesteps가 존재하고, 각 시점마다 5차원의 단어 벡터가 입력으로 사용됨. RNN은 2D가 아닌 3D텐서를 입력으로 받기때문에 3D로 바꿔줌. 배치1로..
train_X = np.array(train_X).reshape(1,4,5).astype(np.float32)
print(train_X.shape)(1, 4, 5)배치 사이즈가 1이고, timesteps가 4, 단어 벡터의 크기가 5인 data set을 구성!!
2. Simple RNN 이해하기
위에서 생성한 데이터를 입력으로 출력값을 이해해보자
return_sequences(모든 은닉을 출력할지), return_state 모두 False가 디폴트
rnn = SimpleRNN(3) # 출력3
hidden_state = rnn(train_X)
print('hidden state: {}, shape: {}'.format(hidden_state, hidden_state.shape))hidden state: [[-0.9453287 -0.95964974 -0.9335618 ]], shape: (1, 3)(1, 3) 크기의 텐서가 출력. 마지막 시점의 은닉상태임. why? sequences를 False 했으므로!! True로 지정해서 결과를 보자
rnn = SimpleRNN(3, return_sequences = True) # 출력3
hidden_state = rnn(train_X)
print('hidden state: {}, shape: {}'.format(hidden_state, hidden_state.shape))hidden state: [[[ 0.9979033 -0.8292727 0.99746215]
[ 0.92280936 -0.96193004 0.9762535 ]
[-0.2010851 -0.14825453 0.989886 ]
[ 0.8348752 -0.97942525 0.97860205]]], shape: (1, 4, 3)입력은 (1, 4, 5) 크기를 가지는 텐서였고 4가 시점에 대한 값. 모든 시점에 대해 은닉 값을 출력하므로 1(batch), 4(시점), 3(메모리 셀 크기) 크기의 텐서를 출력
return_state가 True면 return_sequences의 T/F 여부와 관계 없이 마지막 시점의 은닉상태를 출력. 시퀀스와 스테이트 모두 True라면 SImpleRNN은 두 개의 출력을 리턴!
rnn = SimpleRNN(3, return_sequences = True, return_state = True)
hidden_states, last_state = rnn(train_X)
print('hidden_state: {}, shape: {}'.format(hidden_states, hidden_states.shape))
print('last_state: {}, shape: {}'.format(last_state, last_state.shape))hidden_state: [[[-0.97335804 -0.99725085 -0.08901022]
[-0.99774575 -0.98328656 0.9043592 ]
[-0.9986511 -0.9714776 0.96777153]
[ 0.48120782 -0.6730154 0.99432313]]], shape: (1, 4, 3)
last_state: [[ 0.48120782 -0.6730154 0.99432313]], shape: (1, 3)sequences는 모든 은닉에 대한 값을 리턴하므로 (1,4,3), state는 마지막 은닉에 대해서만 출력하므로 (1, 3). hidden_state의 마지막 state와 last_state가 일치하는 것을 알 수 있음
# 시퀀스는 False, state는 True라면?
rnn = SimpleRNN(3, return_sequences = False, return_state = True)
hidden_states, last_state = rnn(train_X)
print('hidden_state: {}, shape: {}'.format(hidden_states, hidden_states.shape))
print('last_hidden_state: {}, shape: {}'.format(last_state, last_state.shape))hidden_state: [[ 0.76048744 -0.97010994 0.9228985 ]], shape: (1, 3)
last_hidden_state: [[ 0.76048744 -0.97010994 0.9228985 ]], shape: (1, 3)둘 다 마지막 은닉 상태를 출력하게 된다....
state는 그냥 마지막 은닉 상태를 출력할지 말지에 대한 인자인듯
3. LSTM 이해하기
SimpleRNN은 거의 쓰질 않고, LSTM이나 GRU를 주로 사용. 임의의 입력에 대한 LSTM을 보고, 시퀀스는 F, 스테이트는 T를 보자
from tensorflow.keras.layers import LSTM
lstm = LSTM(3, return_sequences = False, return_state = True)
hidden_state, last_state, last_cell_state = lstm(train_X)
print('hidden state: {}, shape: {}'.format(hidden_state, hidden_state.shape))
print('last hidden state: {}, shape: {}'.format(last_state, last_state.shape))
print('last_cell_state: {}, shape: {}'.format(last_cell_state, last_cell_state.shape))hidden state: [[ 0.33627674 -0.10527286 -0.1177433 ]], shape: (1, 3)
last hidden state: [[ 0.33627674 -0.10527286 -0.1177433 ]], shape: (1, 3)
last_cell_state: [[ 0.7871392 -0.21441908 -0.8608165 ]], shape: (1, 3)simpleRNN과 달리 세 개의 결과를 반환한다. 시퀀스 False이므로 첫번째 결과는 마지막 은닉 상태. LSTM이 SimpleRNN과 다른 점은 state를 True로 두면 마지막 은닉 상태 뿐만 아니라 셀 상태까지 반환. LSTM은 셀도 존재했기 때문!!
state는 셀과 은닉 둘다 의미하는 듯
이번엔 시퀀스도 True로 바꿔 모든 은닉 상태를 표현해보자!
from tensorflow.keras.layers import LSTM
lstm = LSTM(3, return_sequences = True, return_state = True)
hidden_state, last_state, last_cell_state = lstm(train_X)
print('hidden state: {}, shape: {}'.format(hidden_state, hidden_state.shape))
print('last hidden state: {}, shape: {}'.format(last_state, last_state.shape))
print('last_cell_state: {}, shape: {}'.format(last_cell_state, last_cell_state.shape))hidden state: [[[ 0.01949248 -0.16192679 0.4955156 ]
[ 0.09818548 -0.25397515 0.6430741 ]
[ 0.13511217 -0.25302598 0.50047046]
[ 0.12425174 -0.26801497 0.24326652]]], shape: (1, 4, 3)
last hidden state: [[ 0.12425174 -0.26801497 0.24326652]], shape: (1, 3)
last_cell_state: [[ 0.30659544 -0.45376328 0.46202454]], shape: (1, 3)SimpleRNN에선 state를 True로 두는 게 무슨의미가 있나 싶었지만, LSTM은 시퀀스에선 셀 스테이트 정보를 알 수 없기 때문에 스테이트 True가 의미가 있는듯?
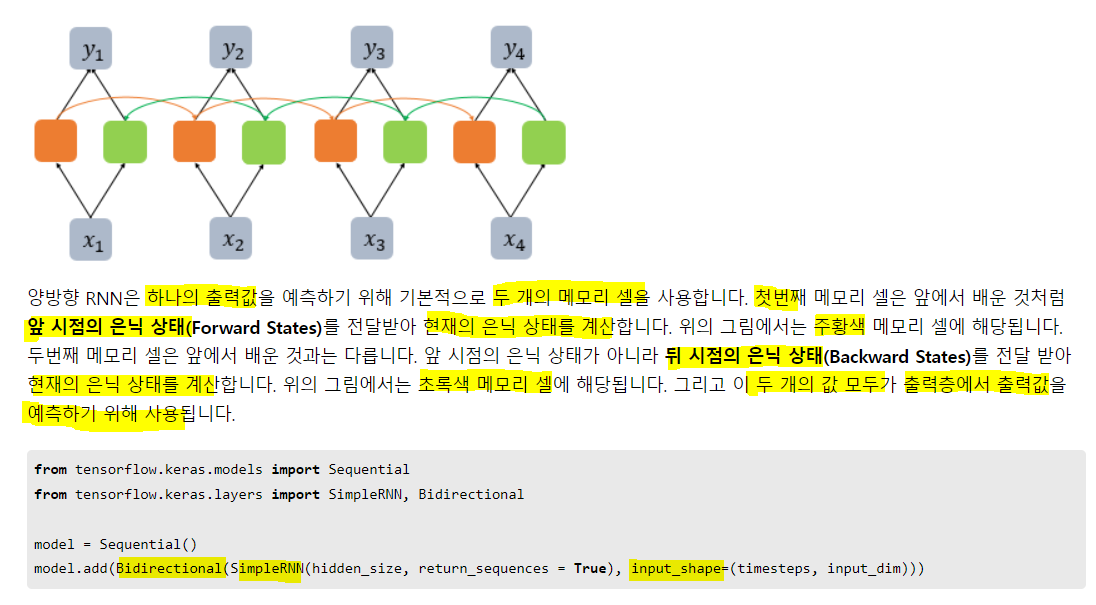
3. Bidirectional(LSTM)
양방향 LSTM의 출력을 보자. 시퀀스 T/F에 대해 은닉 값이 어떻게 바뀌는지 비교하기 위해 출력되는 은닉 상태의 갑을 고정해보자
import tensorflow as tf
## 커널 초기화 하기위한 값
k_init = tf.keras.initializers.Constant(value=0.1)
b_init = tf.keras.initializers.Constant(value=0)
r_init = tf.keras.initializers.Constant(value=0.1)
# sequences False, state True
bilstm = Bidirectional(LSTM(3, return_sequences = False, return_state = True,
kernel_initializer = k_init, bias_initializer = b_init,
recurrent_initializer = r_init))
hidden_state, forward_h, forward_c, backward_h, backward_c = bilstm(train_X)
print('hidden_state: {}, shape: {}'.format(hidden_state, hidden_state.shape))
print('forward_state: {}, shape: {}'.format(forward_h, forward_h.shape))
print('backward_state: {}, shape: {}'.format(backward_h, backward_h.shape))hidden_state: [[0.63031393 0.63031393 0.63031393 0.7038734 0.7038734 0.7038734 ]], shape: (1, 6)
forward_state: [[0.63031393 0.63031393 0.63031393]], shape: (1, 3)
backward_state: [[0.7038734 0.7038734 0.7038734]], shape: (1, 3)양방향은 t+1 은닉과 t-1의 은닉을 동시에 받음. 그래서 forward, backward 존재.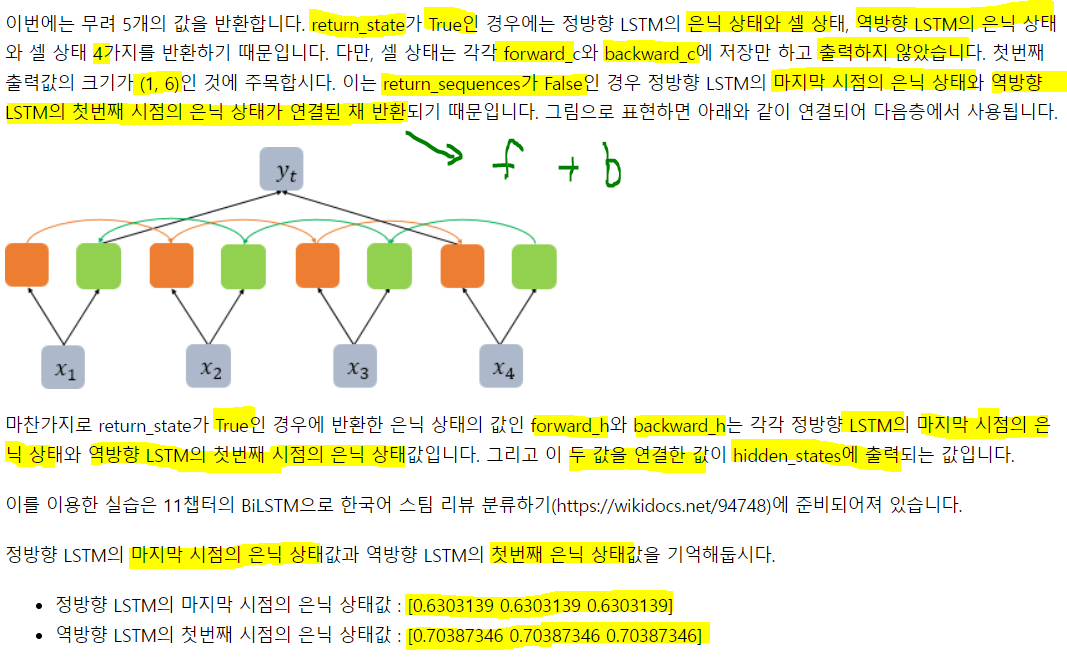
마지막 출력엔 역방향, 정방향의 합이므로 shape이 (1,6)이고 가만보면 두개가 그냥 이어붙어져 있음.
이번엔 그러면 sequences True의 결과
## 커널 초기화 하기위한 값
# sequences False, state True
bilstm = Bidirectional(LSTM(3, return_sequences = True, return_state = True,
kernel_initializer = k_init, bias_initializer = b_init,
recurrent_initializer = r_init))
hidden_state, forward_h, forward_c, backward_h, backward_c = bilstm(train_X)
print('hidden_state: {}, shape: {}'.format(hidden_state, hidden_state.shape))
print('forward_state: {}, shape: {}'.format(forward_h, forward_h.shape))
print('backward_state: {}, shape: {}'.format(backward_h, backward_h.shape))hidden_state: [[[0.35906473 0.35906473 0.35906473 0.7038734 0.7038734 0.7038734 ]
[0.5511133 0.5511133 0.5511133 0.58863586 0.58863586 0.58863586]
[0.59115744 0.59115744 0.59115744 0.3951699 0.3951699 0.3951699 ]
[0.63031393 0.63031393 0.63031393 0.21942244 0.21942244 0.21942244]]], shape: (1, 4, 6)
forward_state: [[0.63031393 0.63031393 0.63031393]], shape: (1, 3)
backward_state: [[0.7038734 0.7038734 0.7038734]], shape: (1, 3)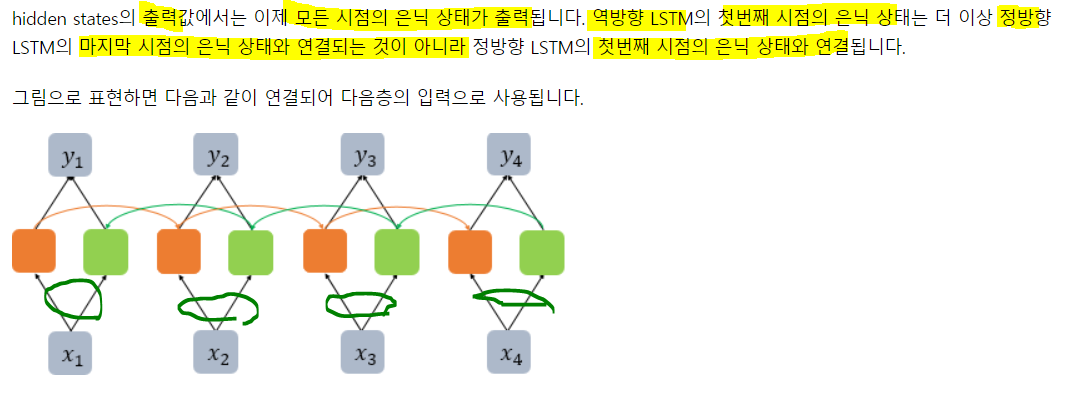 왜 둘이 차이가 있었을지를 생각해보자. return_sequences를 False로 주면 마지막 은닉만 나오게 된다. 정방향은 뒤로가서 4번째가 마지막이고, 역방향은 앞으로 가서 1번째가 마지막이다. 따라서 이 둘이 결합되어 마지막 은닉을 형성한 것!
왜 둘이 차이가 있었을지를 생각해보자. return_sequences를 False로 주면 마지막 은닉만 나오게 된다. 정방향은 뒤로가서 4번째가 마지막이고, 역방향은 앞으로 가서 1번째가 마지막이다. 따라서 이 둘이 결합되어 마지막 은닉을 형성한 것!
seqeuences를 True로 주면 각 은닉이 모두 생성된다. 이는 곧 맨 마지막 백워드와 첫번째 포워드가 결합해 첫번째 은닉, 두번째 포워드와 세 번째 백워드가 결합해 두번째 은닉.... 이런식으로 맨 마지막 y4는 마지막 포워드와 첫번째 백워드가 결합해 은닉!!
5) RNN 언어 모델
1. RNN 언어 모델(Recurrent Neural Network Language Model, RNNLM)
n-gram과 NNLM(피드포워드 언어모델)은 고정된 개수의 단어만을 입력으로 받아야 한다는 단점 존재. 시점이랑 개념이 도입된 RNN은 입력 길이를 고정하지 않아도 된다!
RNNLM의 학습 과정을 보자
예문: 'what will the fat cat sit on'
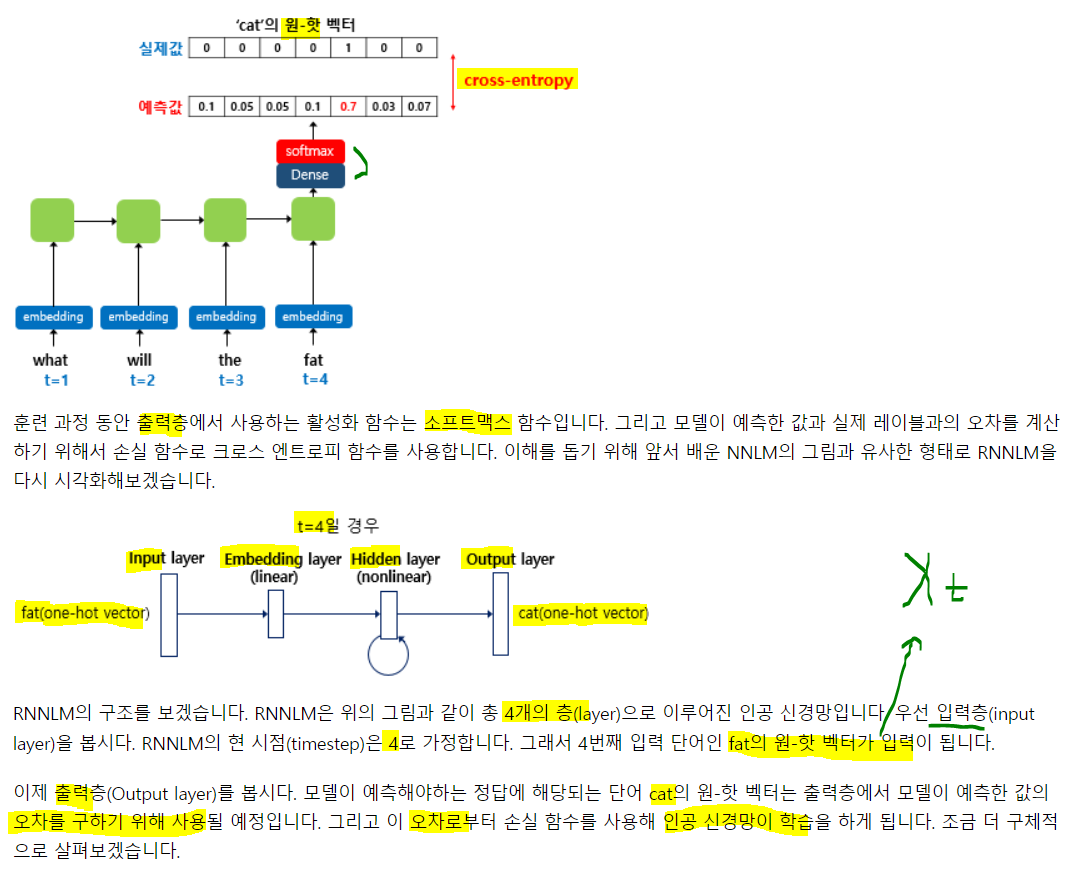
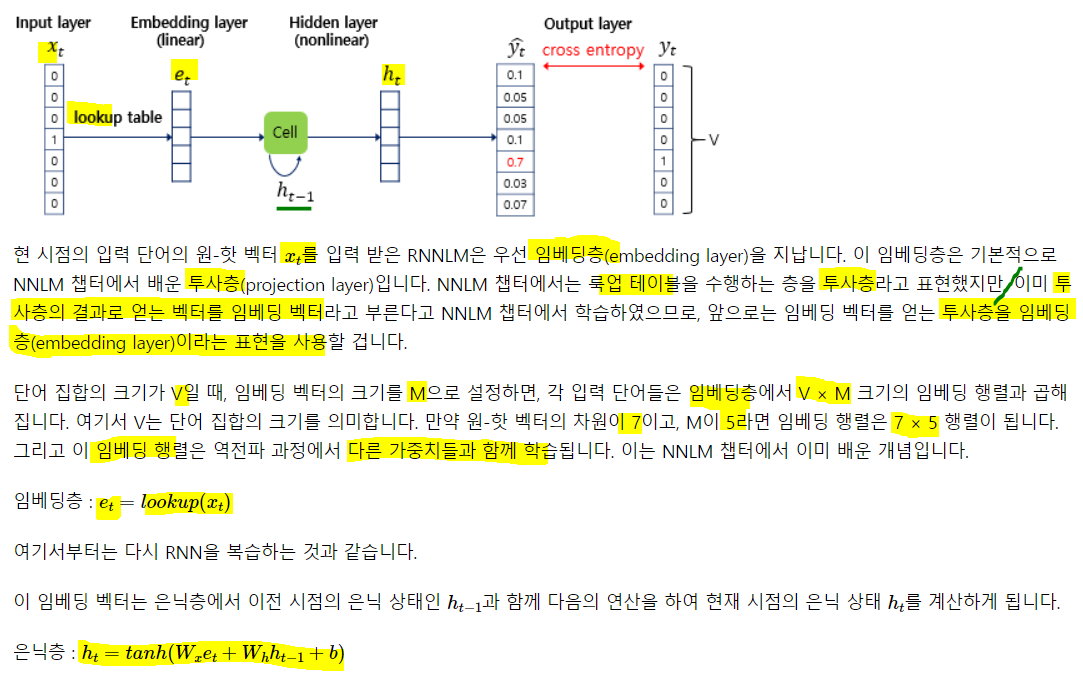 원핫은 모든 토큰에 대해 생성되는 것이기 때문에 사전의 크기와 같음.
원핫은 모든 토큰에 대해 생성되는 것이기 때문에 사전의 크기와 같음. 각 층의 가중치들이 역전파 과정을 통해 학습하는 것임
각 층의 가중치들이 역전파 과정을 통해 학습하는 것임
6) RNN을 이용한 텍스트 생성
many-to-one을 이용해 문맥을 반영해 텍스트를 생성해보자
1. RNN을 이용해 텍스트 생성
이런 데이터를 이용해서 한 번 만들어 보자

1) 데이터에 대한 이해와 전처리
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
from tensorflow.keras.utils import to_categorical
## 위 예제 문장의 저장
text="""경마장에 있는 말이 뛰고 있다\n
그의 말이 법이다\n
가는 말이 고와야 오는 말이 곱다\n"""
## 단어 집합 생성 후 크기 확인
t = Tokenizer()
t.fit_on_texts([text])
vocab_size = len(t.word_index) + 1
# 토크나이저 정수 인코딩은 인덱스 1부터 시작하지만
# 원핫 배열의 인덱스는 0부터 시작하므로
# 배열의 크기를 실제 단어의 집합 크기보다 +1로 생성해야 하므로 미리 설정
print('단어 집합의 크기: {}'.format(vocab_size))단어 집합의 크기: 12토큰화를 통해 11개의 토큰이 생긴 것을 알 수 있음
각 단어와, 부여된 정수 인덱스 출력
print(t.word_index){'말이': 1, '경마장에': 2, '있는': 3, '뛰고': 4, '있다': 5, '그의': 6, '법이다': 7, '가는': 8, '고와야': 9, '오는': 10, '곱다': 11}sequences = []
for line in text.split('\n'): #엔터를 기준으로 자름
encoded = t.texts_to_sequences([line])[0] # 단어의 sequences로 만들어 줌.
for i in range(1, len(encoded)):
# 인코디드의 길이-1 만큼 반복하고 0~2, 0~3, ... 0~마지막토큰 까지 생성
sequence = encoded[:i+1]
sequences.append(sequence) # 위에서 생성한 sequence를 다 담아줌
print('학습에 사용할 샘플의 수: {}'.format(len(sequences)))
print(sequences)학습에 사용할 샘플의 수: 11
[[2, 3], [2, 3, 1], [2, 3, 1, 4], [2, 3, 1, 4, 5], [6, 1], [6, 1, 7], [8, 1], [8, 1, 9], [8, 1, 9, 10], [8, 1, 9, 10, 1], [8, 1, 9, 10, 1, 11]]아직 label을 자르지 않았다. 각 시퀀스에서 -1번째 값이 label이 됨
우선 전체 데이터에 대해 길이를 일치 시켜 주자. 가장 긴 샘플의 길이로 패딩을 진행
max_len = max(len(i) for i in sequences)
print('샘플 최대 길이: {}'.format(max_len))
sequences = pad_sequences(sequences, maxlen = max_len, padding = 'pre')
print(sequences)샘플 최대 길이: 6
[[ 0 0 0 0 2 3]
[ 0 0 0 2 3 1]
[ 0 0 2 3 1 4]
[ 0 2 3 1 4 5]
[ 0 0 0 0 6 1]
[ 0 0 0 6 1 7]
[ 0 0 0 0 8 1]
[ 0 0 0 8 1 9]
[ 0 0 8 1 9 10]
[ 0 8 1 9 10 1]
[ 8 1 9 10 1 11]]최대길이 6에 맞게 제로패딩을 해줬다. 'pre' 줬기 때문에 앞에서부터 0이 채워진다.
레이블 분리엔 넘파이를 사용
sequences = np.array(sequences)
X = sequences[:, :-1]
y = sequences[:, -1]
print(X)
print('')
print(y)[[ 0 0 0 0 2]
[ 0 0 0 2 3]
[ 0 0 2 3 1]
[ 0 2 3 1 4]
[ 0 0 0 0 6]
[ 0 0 0 6 1]
[ 0 0 0 0 8]
[ 0 0 0 8 1]
[ 0 0 8 1 9]
[ 0 8 1 9 10]
[ 8 1 9 10 1]]
[ 3 1 4 5 1 7 1 9 10 1 11]학습을 위한 원핫 잇코딩
y = to_categorical(y, num_classes = vocab_size)2) 모델 설계하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, SimpleRNN
model = Sequential()
## 레이블을 분리했으므로 -1
model.add(Embedding(input_dim = vocab_size, output_dim = 10, input_length = max_len-1))
model.add(SimpleRNN(32)) # 메모리 셀 사이즈 32
## 출력층
model.add(Dense(vocab_size, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(X, y, epochs = 200, verbose = 2)임베딩 벡터는 10차원을 가지고, 32의 은닉 상태 크기를 가지는 바닐라RNN
Epoch 1/200
1/1 - 1s - loss: 2.4980 - accuracy: 0.0000e+00
Epoch 2/200
1/1 - 0s - loss: 2.4850 - accuracy: 0.0000e+00
------- 중략 -------
Epoch 199/200
1/1 - 0s - loss: 0.1160 - accuracy: 1.0000
Epoch 200/200
1/1 - 0s - loss: 0.1139 - accuracy: 1.0000
<keras.callbacks.History at 0x7f0098d9de50>모델이 정확한 예측을 하는지 확인하기 위해 문장 생성하는 함수를 만들어 출력
def sentence_generation(model, t, current_word, n): #모델, 토크나이저, 현재 단어, 반복 수
init_word = current_word # 처음 단어도 마지막에 출력하기 위함
sentence = ''
for _ in range(n):
# 현재 단어에 대한 정수 인코딩
encoded = t.texts_to_sequences([current_word])[0]
encoded = pad_sequences([encoded], maxlen = 5, padding = 'pre') # 패딩을 통해 shape 맞춰줌
result = np.argmax(model.predict(encoded, verbose = 0)) # class를 저장
# 입력한(현재단어)에 대해 Y를 예측하고, 예측한 단어를 저장
for word, index in t.word_index.items():
if index == result: # 예측 단어의 인덱스와 동일한 단어가 있다면
break # 해당 단어가 예측 단어이므로 break
# break 되었다면 예측한 단어이고, 이 단어를 추가해주는 것!!
current_word = current_word + ' ' + word
sentence = sentence + ' ' + word # 예측 단어를 문장에 저장
print(sentence)
# for문이므로 이 행동을 다시 반복
sentence = init_word + sentence
return sentenceprint(sentence_generation(model, t, '경마장에', 4))
# 경마장에 라는 단어 뒤에는 총 네개의 단어가 있으므로 4번 예측있는
있는 말이
있는 말이 뛰고
있는 말이 뛰고 있다
경마장에 있는 말이 뛰고 있다print(sentence_generation(model, t, '그의', 2))말이
말이 법이다
그의 말이 법이다입력한 단어로 다음 단어를 예측해 정답과 비교해 문장을 형성하고, 이 문장으로 다음 단어를 예측하고... 이런 과정을 거쳐 최종 문장을 만든 것
print(sentence_generation(model, t, '가는', 5)) # 5번 예측말이
말이 고와야
말이 고와야 오는
말이 고와야 오는 말이
말이 고와야 오는 말이 곱다
가는 말이 고와야 오는 말이 곱다앞의 문맥을 기준으로 '말이'다음 나올 단어를 훈련 데이터와 일치하게 예측.
이 모델은 충분한 훈련 데이터가 없어서 문장의 길이에 맞게 예측하기 위해 횟수를 4, 2, 5를 지정. 이 이상의 숫자를 주면 기계는 그 뒤에 나오 단어가 무엇인지 배운 적이 없어 임의 예측을 한다!
주어진 데이터를 학습해서 예측을 하는 것이란 걸 잊진 말기.
2. LSTM을 이용해 텍스트 생성
LSTM을 이용해 많은 데이터로 텍스트 생성해보자.
1) 데이터에 대한 이해와 전처리
import pandas as pd
from string import punctuation
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
from tensorflow.keras.utils import to_categorical
df = pd.read_csv('/content/drive/MyDrive/산학협력프로젝트/딥러닝을 이용한 자연어 처리 입문/ArticlesApril2018.csv')
df.head()
print('열의 개수:', len(df.columns))
print(df.columns)열의 개수: 15
Index(['articleID', 'articleWordCount', 'byline', 'documentType', 'headline',
'keywords', 'multimedia', 'newDesk', 'printPage', 'pubDate',
'sectionName', 'snippet', 'source', 'typeOfMaterial', 'webURL'],
dtype='object')헤드라인 열에서 모든 신문 기사의 제목을 뽑아 하나의 리스트로 만들자
headline = []
headline.extend(list(df.headline.values))
headline[:5]['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell',
'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.',
'The New Noma, Explained',
'Unknown',
'Unknown']Unknown 이라는 값이 있음. 결측치는 아니지만 지금 하고자 하는 실습에 관계 없으므로 노이즈라 판단해서 제거해주자
print('총 샘플의 수: {}'.format(len(headline)))
headline = [n for n in headline if n != 'Unknown']
print('노이즈 제거 후: {}'.format(len(headline)))
headline[:5]총 샘플의 수: 1324
노이즈 제거 후: 1214
['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell',
'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.',
'The New Noma, Explained',
'How a Bag of Texas Dirt Became a Times Tradition',
'Is School a Place for Self-Expression?']데이터 전처리는 구두점 제거와 단어의 소문자화.
def repreprocessing(s):
s = s.encode('utf8').decode('ascii', 'ignore')
return ''.join(c for c in s if c not in punctuation).lower()
text = [repreprocessing(x) for x in headline]
text[:5]['former nfl cheerleaders settlement offer 1 and a meeting with goodell',
'epa to unveil a new rule its effect less science in policymaking',
'the new noma explained',
'how a bag of texas dirt became a times tradition',
'is school a place for selfexpression']구두점 제거와 소문자로 변경해줌
단어 집합을 만들고 크기를 확인해보자
t = Tokenizer()
t.fit_on_texts(text)
## one-hot은 인덱스 0부터 시작이므로
vocab_size = len(t.word_index) + 1
print('단어 집합의 크기: {}'.format(vocab_size))단어 집합의 크기: 3494정수 인코딩과 동시에 하나의 문장을 여러 줄로 분해해 훈련 데이터를 구성하자
sequences = []
for line in text: # 1214개 샘플에 대해 하나씪 가져옴
encoded = t.texts_to_sequences([line])[0] # 각 샘플에 대한 정수 인코딩
for i in range(1, len(encoded)):
sequence = encoded[:i+1]
sequences.append(sequence)
sequences[:11][[99, 269],
[99, 269, 371],
[99, 269, 371, 1115],
[99, 269, 371, 1115, 582],
[99, 269, 371, 1115, 582, 52],
[99, 269, 371, 1115, 582, 52, 7],
[99, 269, 371, 1115, 582, 52, 7, 2],
[99, 269, 371, 1115, 582, 52, 7, 2, 372],
[99, 269, 371, 1115, 582, 52, 7, 2, 372, 10],
[99, 269, 371, 1115, 582, 52, 7, 2, 372, 10, 1116],
[100, 3]]위 sequences는 모든 문장을 각 단 어가 시점마다 하나씩 추가적으로 등장하는 형태로 만들었지만, 레이블 분리는 안했음.
왜 이런식으로 sequences를 구성하냐면 '나는 집에 간다'라고 하면 '나는'뒤엔 '집에'가 오게, '나는 집에'뒤엔 '오게'가 오게 sequences를 생성해서 나는 다음엔 집에가 온다는 걸, 나는 집에 뒤엔 간다가 온다는걸 기계에게 학습시키기 위함임!!
index_to_word = {}
for key, value in t.word_index.items():
index_to_word[value] = key
print('빈도수 상위 582번 단어: {}'.format(index_to_word[582]))빈도수 상위 582번 단어: offermax_len으로 패딩을 진행
max_len = max(len(l) for l in sequences)
print('최대 길이: {}'.format(max_len))
sequences = pad_sequences(sequences, maxlen = max_len, padding = 'pre')
print(sequences[:3])최대 길이: 24
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 99 269]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 99 269 371]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 99 269 371 1115]]X, y 분리
sequences = np.array(sequences)
X = sequences[:, :-1]
y = sequences[:, -1]
y = to_categorical(y, num_classes = vocab_size)모델 설계 및 학습
from tensorflow.keras.layers import Embedding, Dense, LSTM
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length = max_len - 1))
model.add(LSTM(128))
model.add(Dense(vocab_size, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam', metrics = ['accuracy'])
model.fit(X, y, epochs = 100, verbose = 1)각 단어의 임베딩 벡터는 10차원, 128의 은닉 상태 크기를 가지는 LSTM을 사용
문장 생성하는 함수를 이용해서 문장을 생성해보자.
def sentence_generation(model, t, current_word, n): #모델, 토크나이저, 현재 단어, 반복 수
init_word = current_word # 처음 단어도 마지막에 출력하기 위함
sentence = ''
for _ in range(n):
# 현재 단어에 대한 정수 인코딩
encoded = t.texts_to_sequences([current_word])[0]
encoded = pad_sequences([encoded], maxlen = 23, padding = 'pre') # 패딩을 통해 shape 맞춰줌
result = np.argmax(model.predict(encoded, verbose = 0)) # class를 저장
# 입력한(현재단어)에 대해 Y를 예측하고, 예측한 단어를 저장
for word, index in t.word_index.items():
if index == result: # 예측 단어의 인덱스와 동일한 단어가 있다면
break # 해당 단어가 예측 단어이므로 break
# break 되었다면 예측한 단어이고, 이 단어를 추가해주는 것!!
current_word = current_word + ' ' + word
sentence = sentence + ' ' + word # 예측 단어를 문장에 저장
print(sentence)
# for문이므로 이 행동을 다시 반복
sentence = init_word + sentence
return sentenceprint(sentence_generation(model, t, 'i', 10))
# 임의의 단어 'i'에 대해서 10개의 단어를 추가 생성 disapprove
disapprove of
disapprove of school
disapprove of school vouchers
disapprove of school vouchers can
disapprove of school vouchers can i
disapprove of school vouchers can i still
disapprove of school vouchers can i still apply
disapprove of school vouchers can i still apply for
disapprove of school vouchers can i still apply for them
i disapprove of school vouchers can i still apply for themprint(sentence_generation(model, t, 'how', 10))
# 임의의 단어 'how'에 대해서 10개의 단어를 추가 생성 to
to prevent
to prevent a
to prevent a racist
to prevent a racist hoodie
to prevent a racist hoodie is
to prevent a racist hoodie is mexicos
to prevent a racist hoodie is mexicos drug
to prevent a racist hoodie is mexicos drug war
to prevent a racist hoodie is mexicos drug war a
how to prevent a racist hoodie is mexicos drug war a7) 글자 단위 RNN(Char RNN)
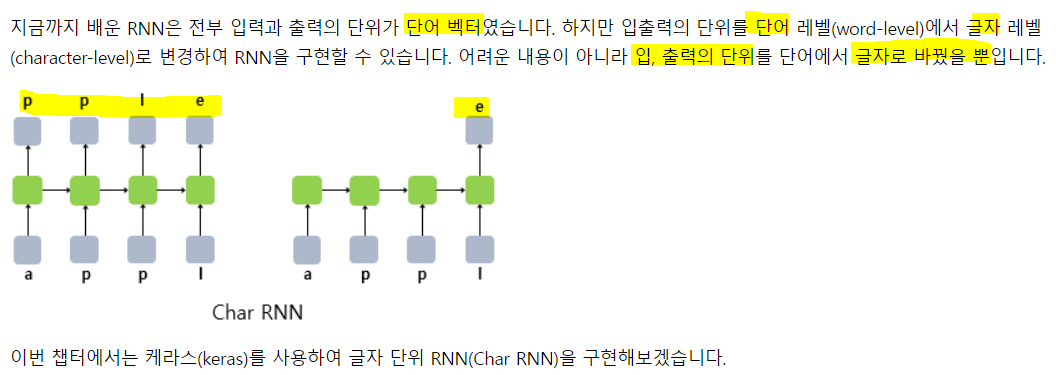
1. 글자 단위 RNN 언어 모델
앞서 배운 단어 단위 모델과 다르 점은 글자 단위를 입, 출력으로 사용하므로 임베딩 층을 사용하지 않음.
1) 데이터 이해와 전처리
import numpy as np
import urllib.request
from tensorflow.keras.utils import to_categorical
## 데이터 수집
urllib.request.urlretrieve('http://www.gutenberg.org/files/11/11-0.txt', filename = '11-0.txt')
f = open('11-0.txt', 'rb') # 읽고 쓰기 모드
lines = []
for line in f:
line = line.strip() # \r, \n 제거
line = line.lower()
line = line.decode('ascii', 'ignore') # \xe2\x80\x99 같은 바이트 열 제거
if len(line) > 0:
lines.append(line)
f.close # 다 수행했으므로 파일 닫음
lines[:5]['the project gutenberg ebook of alices adventures in wonderland, by lewis carroll',
'this ebook is for the use of anyone anywhere in the united states and',
'most other parts of the world at no cost and with almost no restrictions',
'whatsoever. you may copy it, give it away or re-use it under the terms',
'of the project gutenberg license included with this ebook or online at']각 원소는 문자열로 구성되어 있고, 특별히 의미있게 문장 토큰화가 된 상태는 아님. 하나의 문자열로 합치자
text = ' '.join(lines)
print('문자열 길이 또는 총 글자의 개수:', len(text))문자열 길이 또는 총 글자의 개수: 159484문자열은 어떤 글자로 구성되어 있을까? 문자열로부터 글자 집합을 만들자. 중복을 제거한 단어들의 모음인 단어 집합을 만들었지만, 이번엔 글자 집합을 만든다.
char_vocab = sorted(list(set(text)))
vocab_size = len(char_vocab)
print('글자 집합의 크기: {}'.format(vocab_size))글자 집합의 크기: 56코퍼스 내에 수십만 단어가 존재해도 영어는 26개 알파벳 뿐이기 때문에 최대 52개임(대문자+소문자)
방대한 텍스트라도 집합 크기를 적게 가져갈 수 있단 것은 구현과 테스트를 쉽게 할 수 있으므로 RNN 동작 매커니즘을 이해하기 위해 많이 사용
char_to_index = dict((c, i) for i, c in enumerate(char_vocab)) # 고유한 정수 인덱스 부여
print(char_to_index){' ': 0, '!': 1, '"': 2, '#': 3, '$': 4, '%': 5, "'": 6, '(': 7, ')': 8, '*': 9, ',': 10, '-': 11, '.': 12, '/': 13, '0': 14, '1': 15, '2': 16, '3': 17, '4': 18, '5': 19, '6': 20, '7': 21, '8': 22, '9': 23, ':': 24, ';': 25, '?': 26, '[': 27, ']': 28, '_': 29, 'a': 30, 'b': 31, 'c': 32, 'd': 33, 'e': 34, 'f': 35, 'g': 36, 'h': 37, 'i': 38, 'j': 39, 'k': 40, 'l': 41, 'm': 42, 'n': 43, 'o': 44, 'p': 45, 'q': 46, 'r': 47, 's': 48, 't': 49, 'u': 50, 'v': 51, 'w': 52, 'x': 53, 'y': 54, 'z': 55}구두점, 공백, 특수문자 다양함
index_to_char = {}
for key, value in char_to_index.items():
index_to_char[value] = key자꾸 이런식으로 귀찮게 인덱싱 하는 이유는 tokenize가 단어 단위로 이뤄졌기 때문
# Example) 샘플의 길이가 4라면 4개의 입력 글자 시퀀스로 부터 4개의 출력 글자 시퀀스를 예측. 즉, RNN의 time step은 4번
appl -> pple
# appl은 train_X(입력 시퀀스), pple는 train_y(예측해야하는 시퀀스)에 저장한다.다수의 문장 샘플을 분리. 분리 방법은 샘플 길이를 정하고, 해당 길이만큼 문자열 전체를 둥분
seq_length = 60
n_samples = int(np.floor((len(text) - 1) / seq_length))
print('문장 샘플의 수:', n_samples)문장 샘플의 수: 2658train_X = []
train_y = []
for i in range(n_samples): #2658번 반복
X_sample = text[i * seq_length: (i+1) * seq_length]
X_encoded = [char_to_index[c] for c in X_sample] # 정수 인코딩
train_X.append(X_encoded)
y_sample = text[i * seq_length + 1: (i+1) * seq_length + 1] #오른 쪽으로 한 칸 shifting
y_encoded = [char_to_index[c] for c in y_sample]
train_y.append(y_encoded)샘플 수 60으로 배치 사이즈를 60으로 정해준 것이고
하나의 문자로 다음 문자를 예측하는 것이므로 y를 한 칸씩 shift 해준 것
인코딩도 수동으로 했기 때문에... 계속 이런 식으로
글자 단위 RNN에선 입력에 대해 임베딩을 하지 않는다. 임베딩 층을 사용하지 않을 것이므로 원-핫 인코딩을 함. 단어 단위 RNN에선 임베딩을 했음. 왜냐면 원핫으로 표현하기엔 너무 많고, 유사도 이슈도 있고 여러 이유들이 있었음. 후에 더 학습하자
train_X = to_categorical(train_X)
train_y = to_categorical(train_y)
print('train_X의 크기:', train_X.shape)
print('train_y의 크기:', train_y.shape)train_X의 크기: (2658, 60, 56)
train_y의 크기: (2658, 60, 56)배치 사이즈가 60이었기 때문에 배치 횟수는 2658번.
한 시퀀스를 60개로 구성했기 때문에 timesteps가 60.
사전의 길이가 56이었으므로 원핫을 수행했을 때 컬럼의 수는 56
2) 모델 설계하기
from tensorflow.keras.layers import TimeDistributed
model = Sequential()
model.add(LSTM(256, input_shape = (None, train_X.shape[2]), return_sequences = True))
model.add(LSTM(256, return_sequences = True))
model.add(TimeDistributed(Dense(vocab_size, activation = 'softmax')))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(train_X, train_y, epochs = 100, verbose = 1)이전 단어 RNN은 임베딩을 레이어를 쌓아놨기 때문에 따로 input 주지 않았음.
input_shape의 첫번째 인자 input_length는 대부분의 경우에 선택적으로 주는 인자 값이랍니다. 그래서 None으로 줘도 잘 동작함. 다시 말해 None으로 줘도 상관 없고, X_train.shape[1]로 줘도 상관 없는듯
def sentence_generation(model, length):
ix = [np.random.randint(vocab_size)] # 글자에 대한 랜덤 인덱스 생성
y_char = [index_to_char[ix[-1]]] # 랜덤 익덱스로부터 글자 생성
print(ix[-1],'번 글자',y_char[-1],'로 예측을 시작!')
X = np.zeros((1, length, vocab_size)) # (1, length, 55) 크기의 X 생성. 즉, LSTM의 입력 시퀀스 생성
for i in range(length):
X[0][i][ix[-1]] = 1 # X[0][i][예측한 글자의 인덱스] = 1, 즉, 예측 글자를 다음 입력 시퀀스에 추가
print(index_to_char[ix[-1]], end="")
ix = np.argmax(model.predict(X[:, :i+1, :])[0], 1)
y_char.append(index_to_char[ix[-1]])
return ('').join(y_char)
sentence_generation(model, 100)48 번 글자 s 로 예측을 시작!
s and finhered, said the king. and helldone, impor a little birds and as of poptrait with the terms s and finhered, said the king. and helldone, impor a little birds and as of poptrait with the terms o개판임
2. 글자 단위 RNN으로 텍스트 생성하기
text='''
I get on with life as a programmer,
I like to contemplate beer.
But when I start to daydream,
My mind turns straight to wine.
Do I love wine more than beer?
I like to use words about beer.
But when I stop my talking,
My mind turns straight to wine.
I hate bugs and errors.
But I just think back to wine,
And I'm happy once again.
I like to hang out with programming and deep learning.
But when left alone,
My mind turns straight to wine.
'''을 이용해 분석 해보자
tokens = text.split() # \n 제거
text = ' '.join(token)
print(text)I get on with life as a programmer, I like to contemplate beer. But when I start to daydream, My mind turns straight to wine. Do I love wine more than beer? I like to use words about beer. But when I stop my talking, My mind turns straight to wine. I hate bugs and errors. But I just think back to wine, And I'm happy once again. I like to hang out with programming and deep learning. But when left alone, My mind turns straight to wine.글자 집합 생성
char_vocab = sorted(list(set(text)))
print(char_vocab)
vocab_size = len(char_vocab)
print('글자 집합의 크기', vocab_size)[' ', "'", ',', '.', '?', 'A', 'B', 'D', 'I', 'M', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'v', 'w', 'y']
글자 집합의 크기 33정수 인코딩
char_to_index = dict((c, i) for i, c in enumerate(char_vocab))예를 들어 훈련 데이터에 student라는 단어가 있고,
입력 시퀀스의 길이를 5라고 한다면 입력 시퀀스와
예측해야하는 글자는 다음과 같이 구성됩니다.
# Example) 5개의 입력 글자 시퀀스로부터 다음 글자 시퀀스를 예측. 즉, RNN의 time step은 5번
stude -> n
tuden -> tlength = 11
sequences = []
for i in range(length, len(text)):
seq = text[i-length: i]# 11의 문자열을 만듦
sequences.append(seq)
print('총 훈련 샘플의 수', len(sequences))
sequences[:10]총 훈련 샘플의 수 426
['I get on wi',
' get on wit',
'get on with',
'et on with ',
't on with l',
' on with li',
'on with lif',
'n with life',
' with life ',
'with life a']첫 문장이던 I get on with life as a programmer가 10개의 샘플로 분리 됨. 길이 10인
X = []
for line in sequences:
temp = [char_to_index[char] for char in line]
X.append(temp)
sequences = np.array(X)
X = sequences[:, :-1]
y = sequences[:, -1]
for line in X[:5]:
print(line)[ 8 0 16 14 28 0 24 23 0 31]
[ 0 16 14 28 0 24 23 0 31 18]
[16 14 28 0 24 23 0 31 18 28]
[14 28 0 24 23 0 31 18 28 17]
[28 0 24 23 0 31 18 28 17 0]토큰 내에 공백도 있고 문자만 있는 게 아님. 따라서 문자 뒤에 공백이 왔던 것도 학습을 한 것이라 띄어쓰기도 되는 것임. 문자 단위로 학습을 시킨 것!! 문장 생성엔 좀 부적잘 하지 않은가 싶다.
## x에 대해 원핫인코딩 해서 매트릭스화
sequences = [to_categorical(x, num_classes = vocab_size) for x in X]
X = np.array(sequences)
y = to_categorical(y, num_classes = vocab_size)
print(X.shape)
시퀀스를 10으로 지정했으므로 timesteps 10, 중복 제외한 문자의 수는 33개였음. 샘플을 만든게 426개 였음(한 문장에 대해 10의 길이로 문자열 기준으로 문장 생성했던 것)!
2) 모델 설계
model = Sequential()
model.add(LSTM(80, input_shape = (X.shape[1], X.shape[2])))
model.add(Dense(vocab_size, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(X, y, epochs = 100, verbose = 1)def sentence_generation(model, char_to_index, seq_length, seed_text, n):
# 모델, 인덱스 정보, 문장 길이, 초기 시퀀스, 반복 횟수
init_text = seed_text # 문장 생성에 사용할 초기 시퀀스
sentence = ''
for _ in range(n): # n번 반복
encoded = [char_to_index[char] for char in seed_text] # 현재 시퀀스에 대한 정수 인코딩
encoded = pad_sequences([encoded], maxlen=seq_length, padding='pre') # 데이터에 대한 패딩
encoded = to_categorical(encoded, num_classes=len(char_to_index))
result = np.argmax(model.predict(encoded, verbose=0))
# 입력한 X(현재 시퀀스)에 대해서 y를 예측하고 y(예측한 글자)를 result에 저장.
for char, index in char_to_index.items(): # 만약 예측한 글자와 인덱스와 동일한 글자가 있다면
if index == result: # 해당 글자가 예측 글자이므로 break
break
seed_text=seed_text + char # 현재 시퀀스 + 예측 글자를 현재 시퀀스로 변경
sentence=sentence + char # 예측 글자를 문장에 저장
# for문이므로 이 작업을 다시 반복
sentence = init_text + sentence
return sentenceprint(sentence_generation(model, char_to_index, 10, 'I get on w', 80))I get on with life as a programmer, I like to contemplate beer. But when I stap my tmaeenn이전 실습보단 덜 개판이다. 왜냐면 이번 텍스트는 애초에 하나의 의도를 가지고 만들어진 노래였고, 이전 텍스트는 뉴스 헤드라인을 합쳐놓은 것으로 다 각기 다른 문장들이 합해져 있었기 때문이다. 이처럼 누가 하나의 의도를 가진 문장이라면 문자 기준(한 글자)의 RNN을 해도 괜찮을 것 같단 생각이 든다?
안하는 덴 다 이유가 있겠지...
