딥 러닝 개요
01) 퍼셉트론
인공 신경망은 머신 러닝 방법 중 하나. 인공 신경망을 복잡하게 쌓아올린 딥 러닝이 각광받고 있음.



구조는 똑같음. activation function이 계단이냐, 시그모이드냐 그 차이.
단층 퍼셉트론
: 값을 보내는 단계와 출력하는 두 단계로만 이뤄짐. 즉 입력과 출력층만 존재
단층을 이용해 AND, NAND, OR 게이트 쉽게 구현 가능.
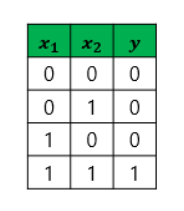
1) AND: 두 개의 입력값이 1인 경우만 1이 출력
2) NAND: 두개의 입력값이 1인 경우에만 0을 출력.
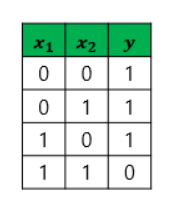
3) OR: 둘 다 0인 경우만 0을 출력. F & F = F
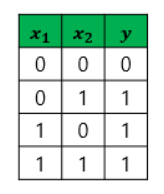
4) XOR: 두개가 다른 경우에만 1, 같은 경우엔 0을 출력
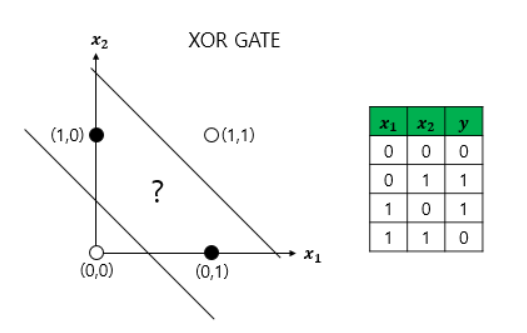
단층 퍼셉트론은 선 하나만 있는 것이므로 하나의 선을 그어 이 두 클래스를 완벽하게 구분할 수가 없음. 이게 한계였음
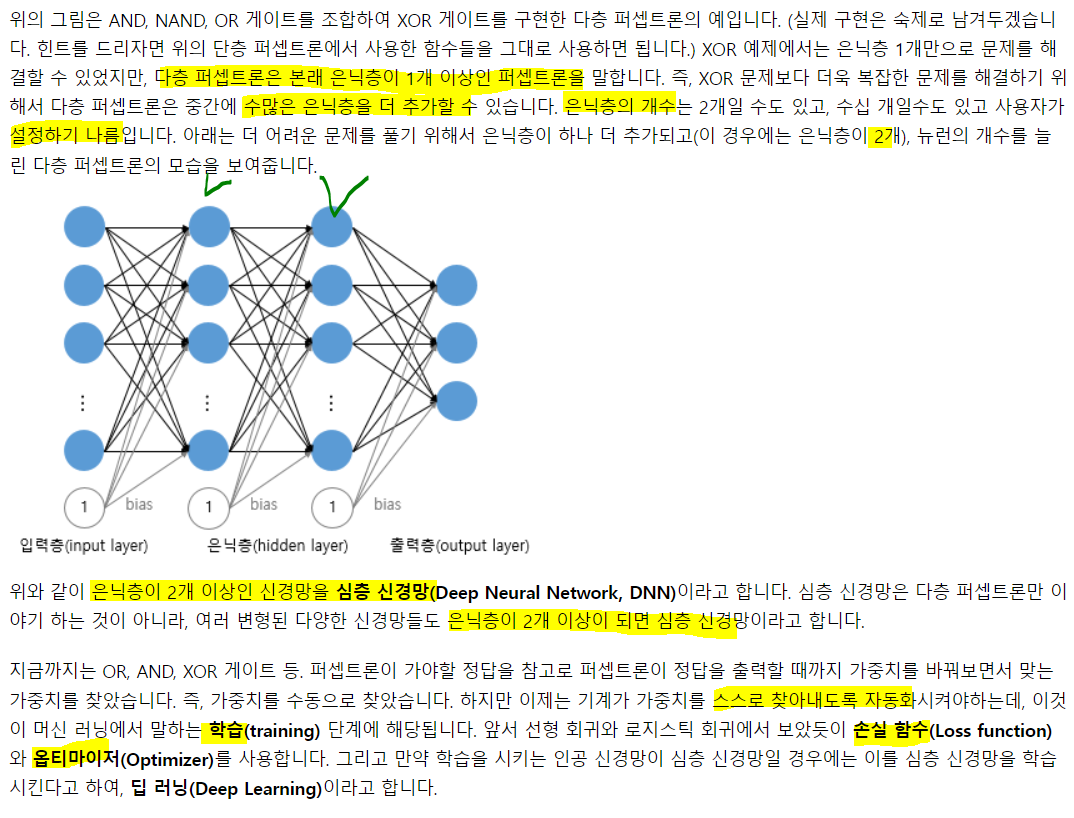

Fully Connected layer
: 모든 뉴런이 연결되어 있는 층을 전결합층이라 함.
Activation Function
: 선형 함수가 아닌 비선형 함수여야 함. 인공 신경망의 은닉층을 추가해 능력을 높이는데, 활성화 함수로 선형 함수를 사용하면 층을 쌓을 수가 없음.
왜냐, 라 가정. 여기에 은닉층을 두 개 추가하면가 됨. 로 다시 선형 함수가 됨. 즉 선형함수는 n번 추가해도 1회 추가한 것과 다름이 없음.
하지만, 연속과 1회의 차이가 없단거지, 아무 의미가 없단건 아님. 선형함수를 사용한 층을 활성화 함수 사용하는 은닉층과 구분하기 위해 선형층 or 투사층등의 다른 표현을 씀. 은닉층은 선형층과 대비되는 비선형층임.
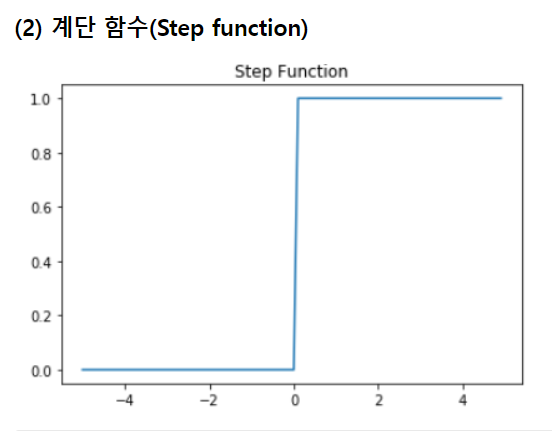
계단의 꼴을 가지고, 값은 0에서 1사이.
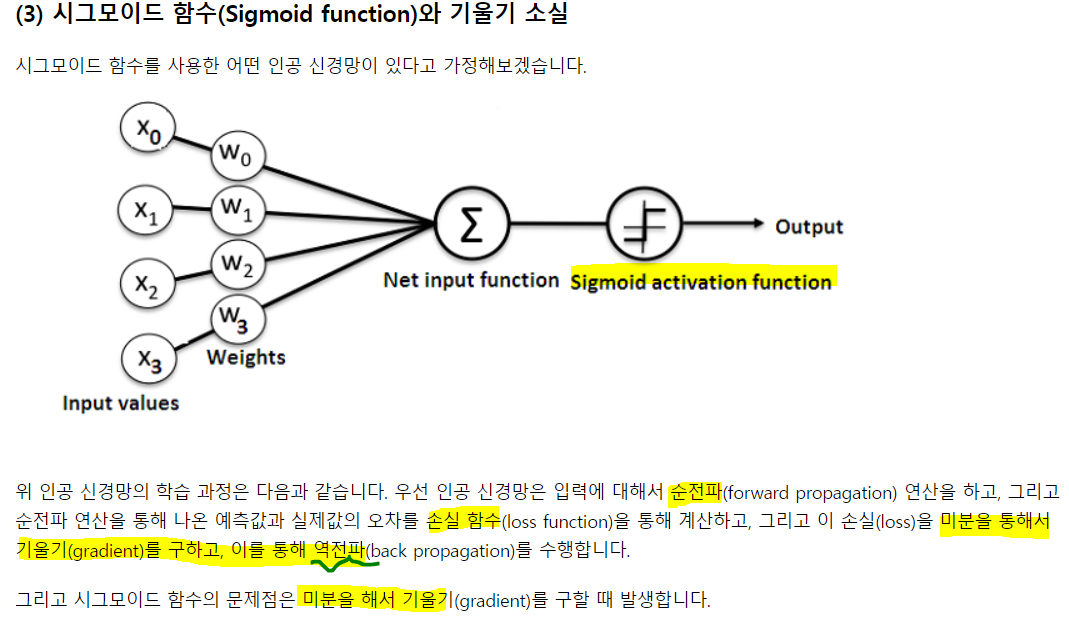
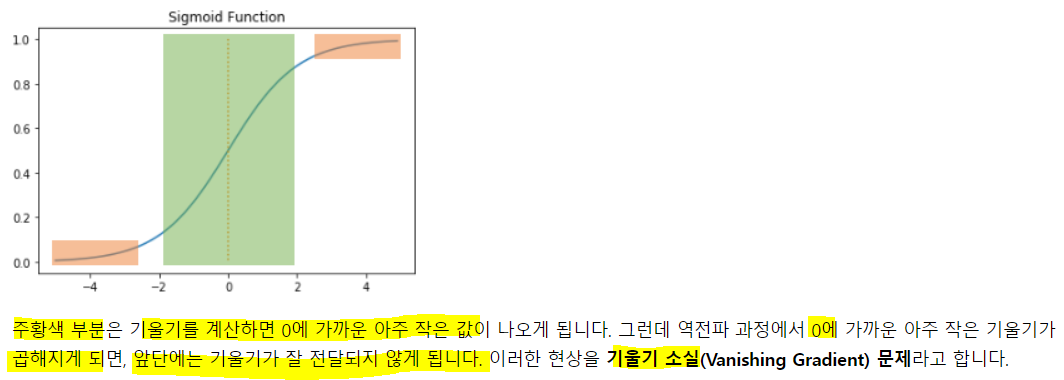
기울기 소실의 문제로 시그모이드를 활성화로 잘 안씀
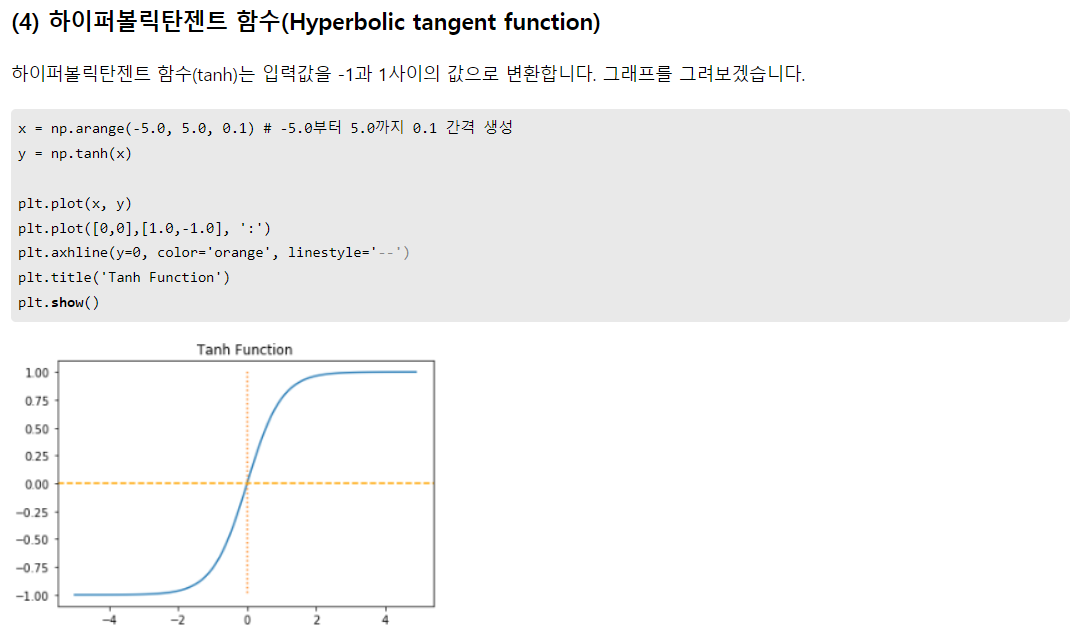
하이퍼볼릭 탄젠트의 경우 시그모이드의 꼴과 유사함. 하지만 -1과 1사이 값을 가지고, (0, 0)이 중심. 기울기 소실이 안되진 않지만, 그래도 시그모이드에 비해 기울기 소실이 덜함. 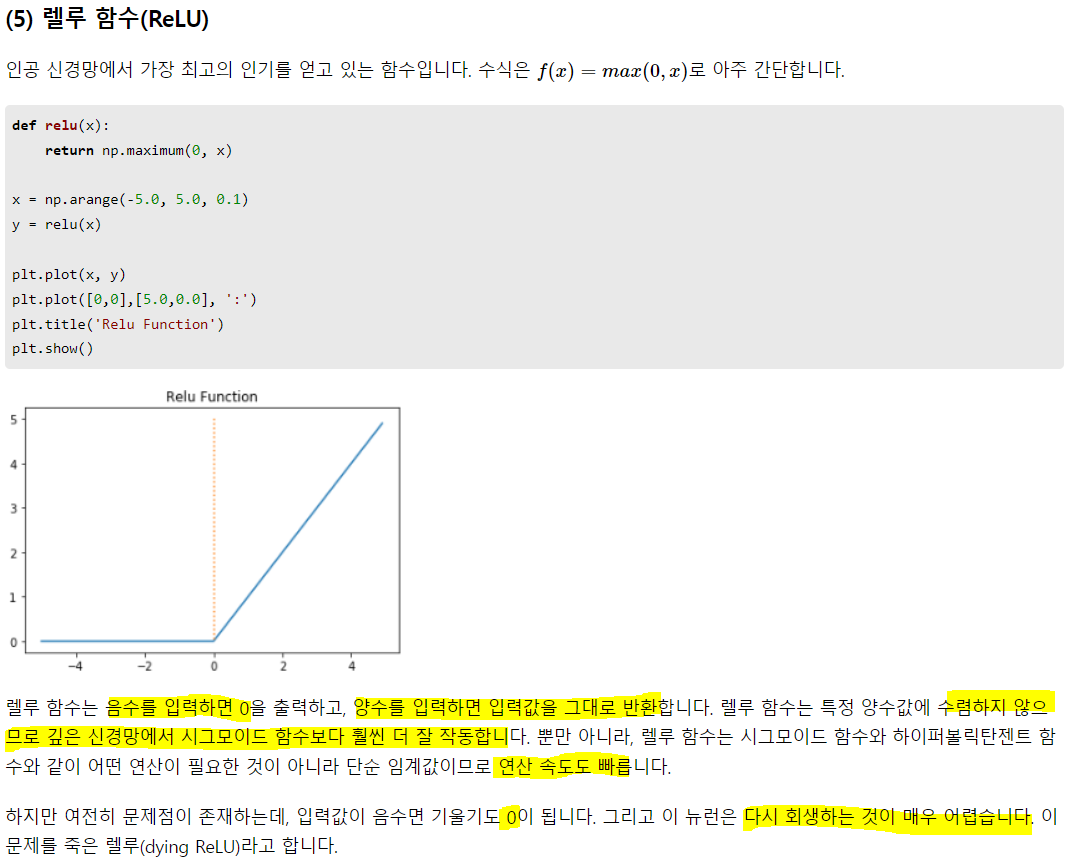
렐루 -> 0보다 작으면 0, 크면 y = x.
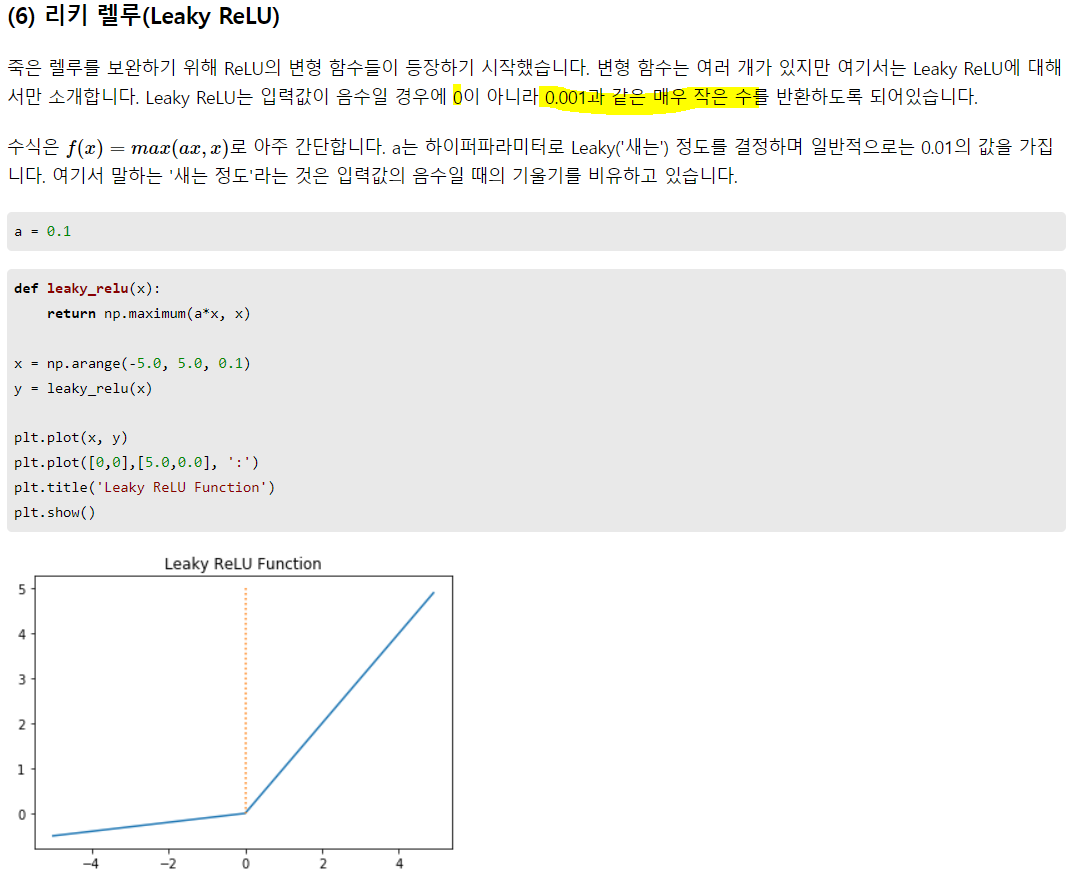
신호가 약하더라도 신호는 신호이므로 아예 죽여버릴 수는 없어서 0이 아닌 아주 작은 값으로라도 살려놓는 듯.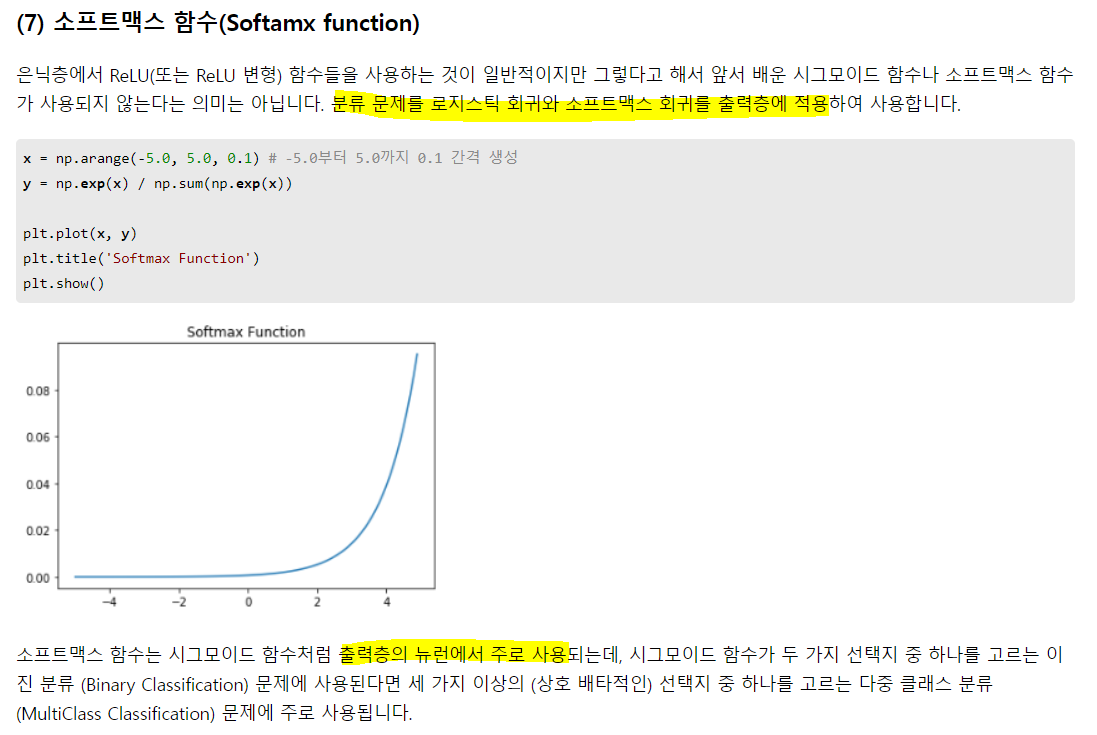
다중 분류(2개 이상)에 소프트맥스, 이진 분류엔 시그모이드. 은닉층의 활성화 함수는 아니더라도, 출력층에서 사용 됨.
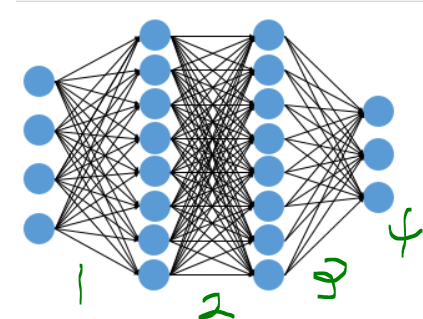
이런 신경망을 코드로 구현한다면?
model = Sequential()
model.add(Dense(8, input_dim = 4, activation = 'relu')
model.add(Dense(8, activation = 'relu')
model.add(Dense(3, activation = 'softmax')1 -> 입력층: 4개의 입력과 8개의 출력
2 -> 은닉층1: 8개의 입력과 8개 출력
3 -> 은닉층2: 8개의 입력과 3개의 출력
4 -> 3개의 입력과 3개의 출력


layer1의 가중행렬: 4 x 8
layer2의 가중행렬: 8 x 8
layer3의 가중행렬: 8 x 3
3)딥 러닝의 학습 방법
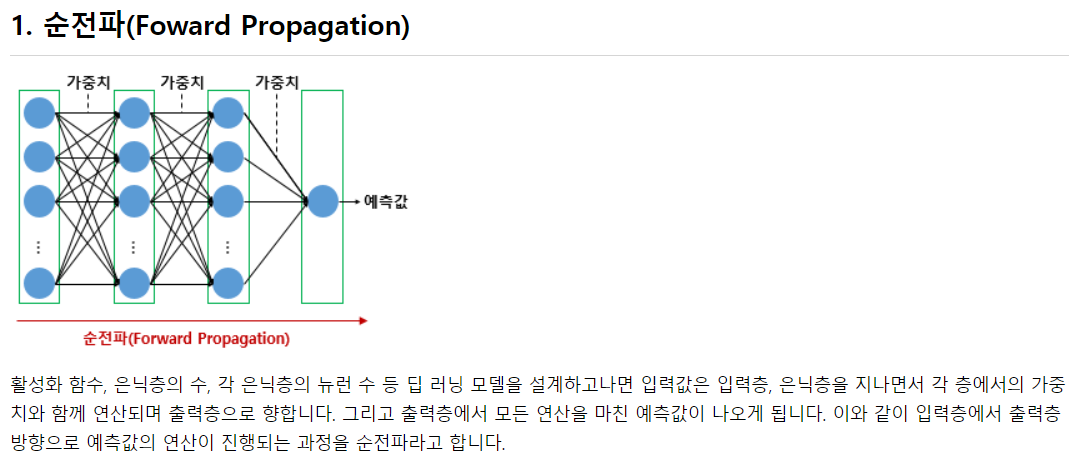
순전파는 입력에서 출력으로 순방향으로 전개하며 출력을 얻는 것

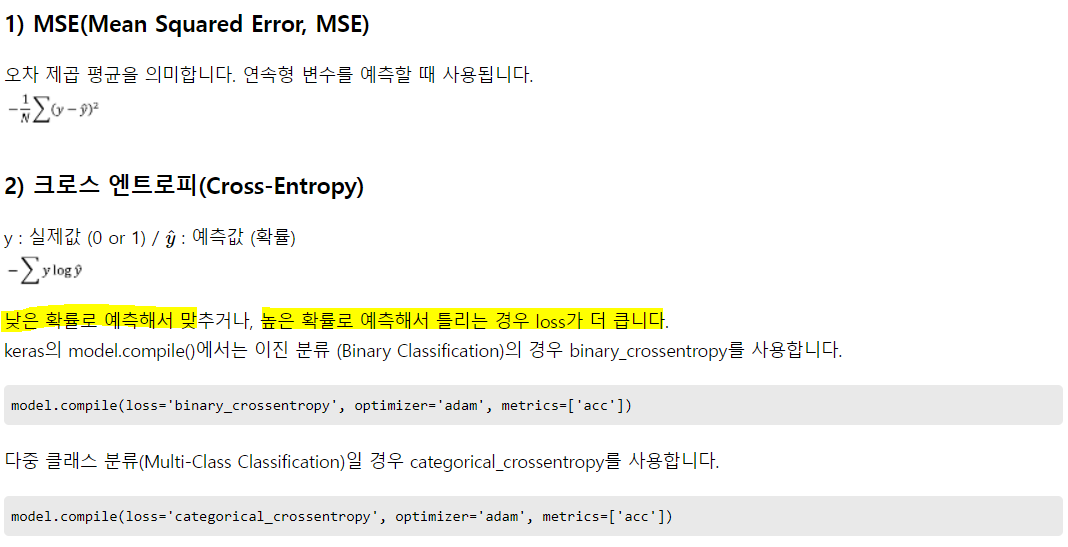 수치예측을 할 땐 MSE, 분류를 할 땐 크로스 엔트로피.
수치예측을 할 땐 MSE, 분류를 할 땐 크로스 엔트로피.
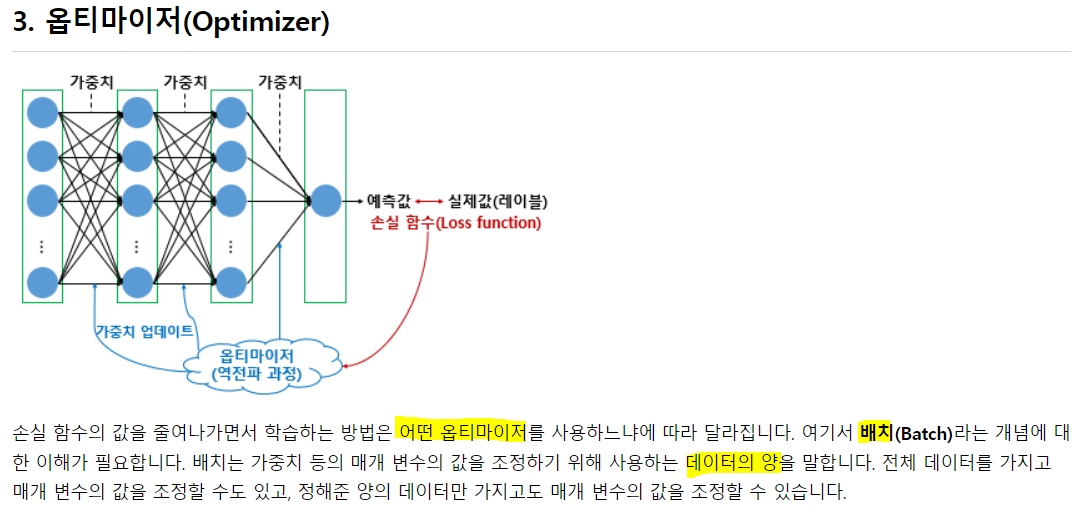
1) 배치 경사 하강법: Batch Gradient Descent
가장 기본적. 오차를 구할 때 전체 데이터를 고려. 1 epoch 마다 모든 매개변수 업데이트를 단 한 번 수행. 전체 데이터를 고려해 시간이 오래 걸리지만, global minimum을 찾을 수 있다는 장점이 존재
model.fit(X_train, y_train, batch_size = len(train_X))
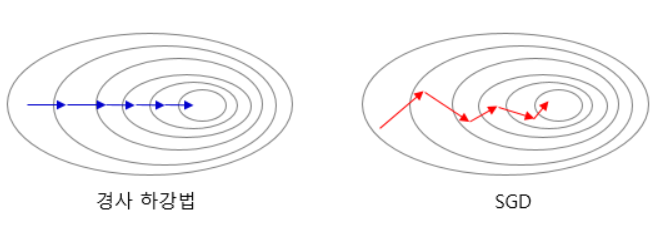
2) 확률적 경사 하강법: Stochastic Gradient Descent, SGD
매개변수 조정 시 전체가 아니라 랜덤하게 선택해 하나의 데이터에 대해서만 계산.
더 적은 데이터를 사용하므로 더 빠름. 매개변수 변경 폭이 불안정하고 BGD보다 정확도가 낮을 순 있지만, 속도만큼은 배치보다 빠름
```py
model.fit(X_train, y_train, batch_size = 1)3) 미니 배치 경사 하강법
전체도 아니고, 1개도 아니고, 정해진 양에 대해서만 조정을 하는게 미니배치 경사 하강법. 전체보다 빠르며, SGD보다 안정적.
model.fit(X_train, y_train, batch_size = 32) # 배치를 32로 했을 경우4) 모멘텀
:물리학의 법칙을 응용. 모멘텀 경사 하강에 관성을 더해줌. 계산된 접선 기울기에 한 시점 전의 접선의 기울기 값을 일정한 비율만큼 반영. momentum 인자가 그 비율인듯 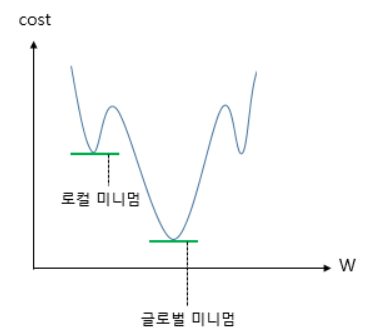
관성의 힘을 빌려 조절되면서 로컬 미니멈에서 탈출하는 효과를 얻을 수 있음
keras.optimizers.SGD(lr = 0.01, momentum = 0.9)5) 아다그라드
: 각자 의미하가 다른 매개변수에 동일한 학습률을 적용하는 건 비효율. 각 매개변수에 서로 다른 학습률을 적용. 변화가 많은 매개변수는 학습률이 작게 설정, 적은 매개변수는 학습률을 높게.
keras.optimizers.Adagrad(lr = 0.01, epslion = 1e-6)6) 알엠에스프롭(RMSProp)
: 아다그라드는 학습을 계속 진행한 경우, 나중 가면 학습률이 지나치게 떨어짐. 다른 수식으로 대체해 이런 문제를 해결
keras.optimizers.RMSprop(lr = 0.01, roh = 0.9, epsilon = 1e-6)7) Adam(아담)
: 아담은 RMSprop과 모멘텀 두 가지를 합침. 방향과 학습을 모두 잡기 위한 방법
keras.optimizers.Adam(lr = 0.01, beta_ = 0.9, beta_2 = 0.999, epsilon = None, decay = 0., amsgrad = False)epoch, iteration, batch

1) 에포크: 전체 데이터에서 순전파와 역전파가 모두 끝난 상태. 모든 문제를 다 풀고, 정답지로 채점을 하며 문제지에 대한 공부를 한 번 끝난 상태
2) 배치 크기: 몇 개의 데이터 단위로 매개변수를 업데이트 하는지. 문제지에서 몇 개씩 풀고 정답지를 확인하느냐에 문제. 사람이 문제를 풀고 정답지를 보며 부족했던 점을 깨닫고 지식을 업데이트 하는 것 처럼, 기계도 오차를 계산하고, 옵티마이저가 매개변수를 업데이트. 배치사이즈 말고 전체 배치의 수를 iteration
3) 이터레이션: 한 에포크를 끝내기 위한 배치의 수. 또는 한 번의 에포크 내 매개변수의 업데이트 횟수. SGD를 설명한다면, 배치 크기가 1이므로 모든 이터레이션 마다 하나의 데이터를 선택하며 경사 하강법을 수행.
03-4) 역전파 이해하기


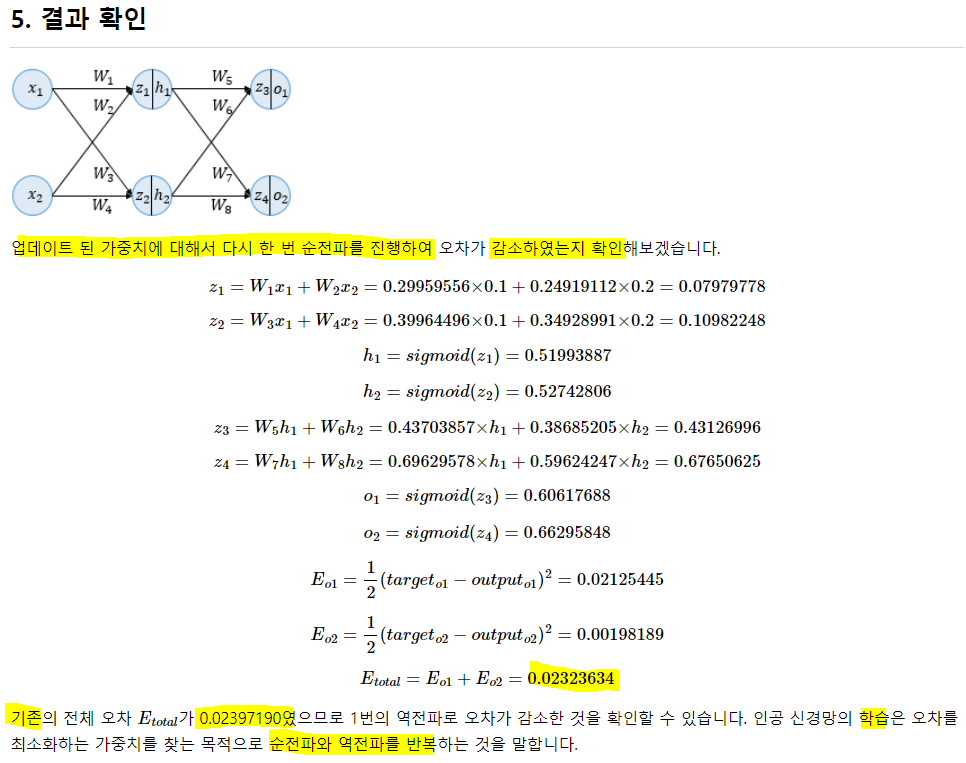
순전파는 결국 각 입력층에 가중치를 곱해 가중합을 계산하고, 활성화 함수를 통과한 값을 다음 층의 입력값으로 쓴다. 이 과정을 반복해서 출력층 까지 가서 출력층의 뉴런 수 만큼 출력 값을 내놓는 것.

바로 앞 가중치 업데이트.

04) 과적합을 막는 방법
모델이 과적합되면 훈련에 대한 정확도는 높더라도, 예측을 잘 못함. 불필요할 정도로 과하게 암기 훈련해 훈련에 포함된 노이즈까지 학습한 상태라고 해석.
해결책
-
데이터 양을 늘리기
- 양이 적을 경우, 특정 패턴이나 노이즈까지 학습. -> 과적합 발생가능
양을 늘릴수록 모델은 일반적 데이터의 패턴을 학습해 과적합을 방지
만약 데이터 양이 적을 경우, 의도적으로 조금씩 변형하고 추가해 양을 늘리기도 하는데 이를 증식 또는 증강(Augmentation).
이미지와 같은 경우엔, 많이 사용. 돌리거나 노이즈를 추가하고, 일부분을 수정하는 등으로 증식 시킴
- 양이 적을 경우, 특정 패턴이나 노이즈까지 학습. -> 과적합 발생가능
-
모델의 복잡도 줄이기
- 인공 신경망의 복잡도는 은닉층의 수나 매개변수의 수로 결정. 모델에 대해 취할수 있는 조치는 복잡도를 주이는 것. 모델에 있는 매개변수들의 수(많은 wegihts와 bias들)를 모델의 수용력이라고 함.
-
가중치 규제 적용하기

- 복잡한 모델이 과적합될 가능성이 높다. 간단한 모델은 적은 수의 매개변수를 가진 모델. 복잡도를 낮추는 방법으론 규제가 이음
- L1 규제: w들의 절대값 합계를 비용 함수에 추가. L1-norm(Lasso 회귀의 그 규제와 같음)
- L2 규제: w들의 제곱합을 비용 함수에 추가. L2-norm(Ridge의 규제와 같음) -
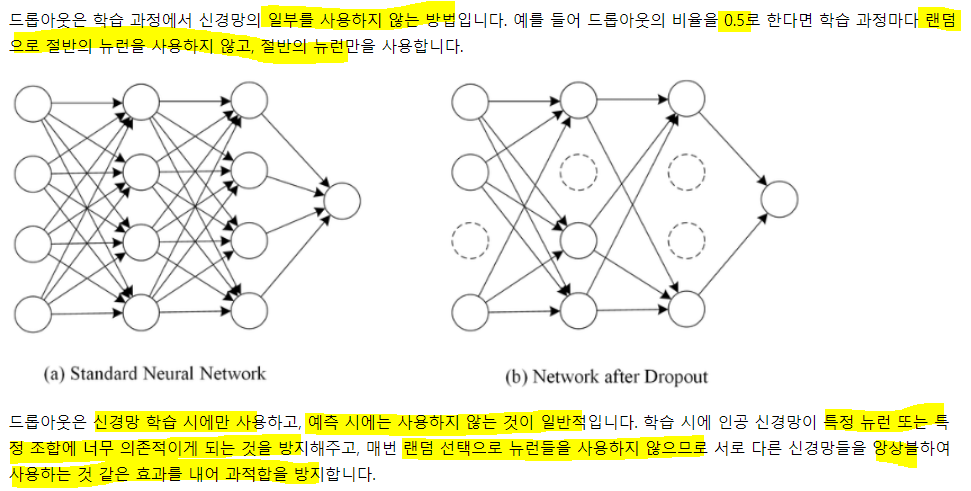
드롭아웃
model = Sequential()
model.add(Dense(256, input_dims, activation = ))
model.add(Dropout(비율)) # 덴스와 덴스 사이에 드롭아웃 추가
model.add(Dense(128, input_dims, activation = ))
model.add(Dropout(비율)) # 덴스와 덴스 사이에 드롭아웃 추가
model.add(Dense(classes, activation = soft or relu))
이런 로직으로 돌아감.05) 기울기 소실과 폭주
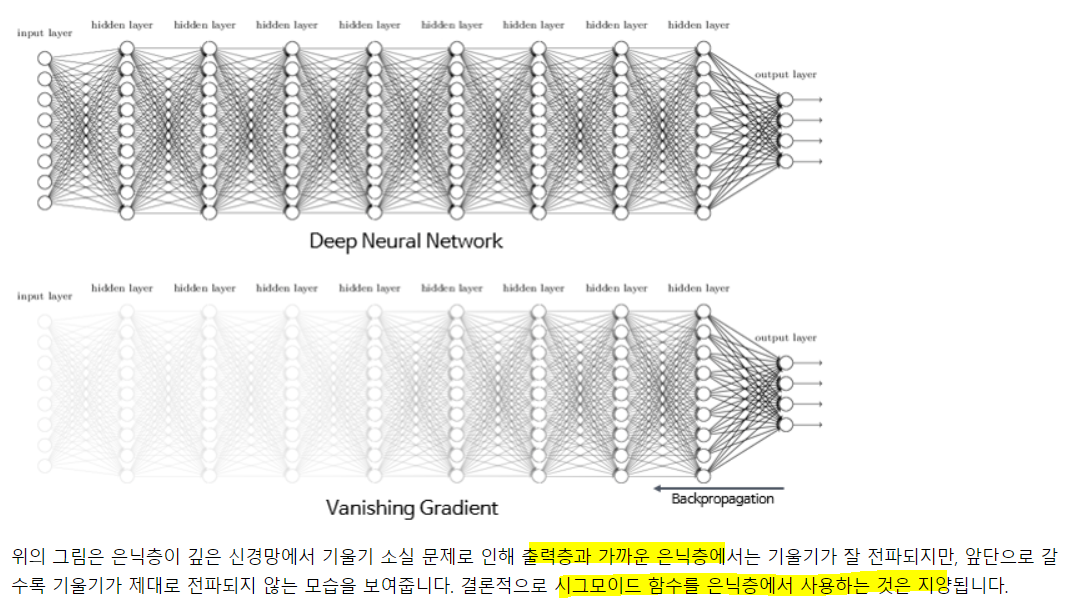
역전파 과정중 입력층으로 갈 수록 기울기가 점차적으로 작아지는 현상 발생. 입력층에 가까운 값들의 업데이트가 제대로 되지 않으면 최적 모델 못찾음. 이를 기울기 소실이라 함.
기울기가 점차 커지더니 가중치들이 비정상적으로 커져 결국 발산되기도 함. 이를 기울기 폭주라고하며, RNN에서 발생할 수 있음
이를 방지하기 위한 방법들!
1. ReLU와 변형 ReLU
시그모이드는 기울기 소실의 문제가 있었음. 이를 완화하는 방법은 활성화로 시그모이드나 하이퍼볼릭 대신 렐루나 리키렐루.
렐루는 0보다 작은 값은 모두 0이므로 작은 값의 신호, 약한 신호는 다 죽어버림. 이 문제를 해결하기 위해서 레키릴루가 등장. 조금씩이라도 살려둠.
2. 그래디언트 클리핑(Gradient Clipping)
기울기 값을 자르는 것을 말함. 폭주를 막기 위해 임계값을 넘지 않도록 설정. 임계치 만큼 크기를 감소시킴. RNN에서 유용하게 사용.
Bert에서 시점을 역행하며 기울기를 구할 때 너무 커질 수 있는데 이를 방지.
from tensorflow.keras import optimizers
Adam = optimizers.Adam(lr = 0.0001, clipnorm = 1.)
##clipnorm을 활용해서 폭주를 막음. 3. 가중치 초기화(Weight Initialization)
같은 모델을 훈련해도 초기 값이 어떤 값이냐에 따라 훈련의 결과가 달라지기도 함. 가중치만 적절히 초기화 해줘도 기울기 소실 문제를 완화 함. 초기화는 reset이 아니라 시작할 때 값을 어떻게 지정할지!
1) 세이비어 초기화
 시그모이드, 하이퍼탄젠트와 같은 S자 shape의 activation과 함께 쓰면 세이비어(글로럿)은 성능이 좋지만 ReLU와 함께 쓰면 별로. ReLU는 He 초기화!
시그모이드, 하이퍼탄젠트와 같은 S자 shape의 activation과 함께 쓰면 세이비어(글로럿)은 성능이 좋지만 ReLU와 함께 쓰면 별로. ReLU는 He 초기화!

4. 배치 정규화

위의 Regularization이 아닌 Normalization. 각 뉴런의 입력층을 정규화 해서 넣어주는 것
한계점:
1. 미니 배치의 크기에 의존적. 단적인 예로, 배치 크기를 1로 한다면? 분산은 0. 따라서 너무 작은 크기보단 어느정도 작은 미니 배치에서 하는 게 좋음
2. RNN에 적용하기 어려움
RNN은 각 시점마다 다른 통계치를 가짐. 이는 배치 정규화를 적용하기 어렵게 함. 이를 해결하기 위해 층정규화를 사용
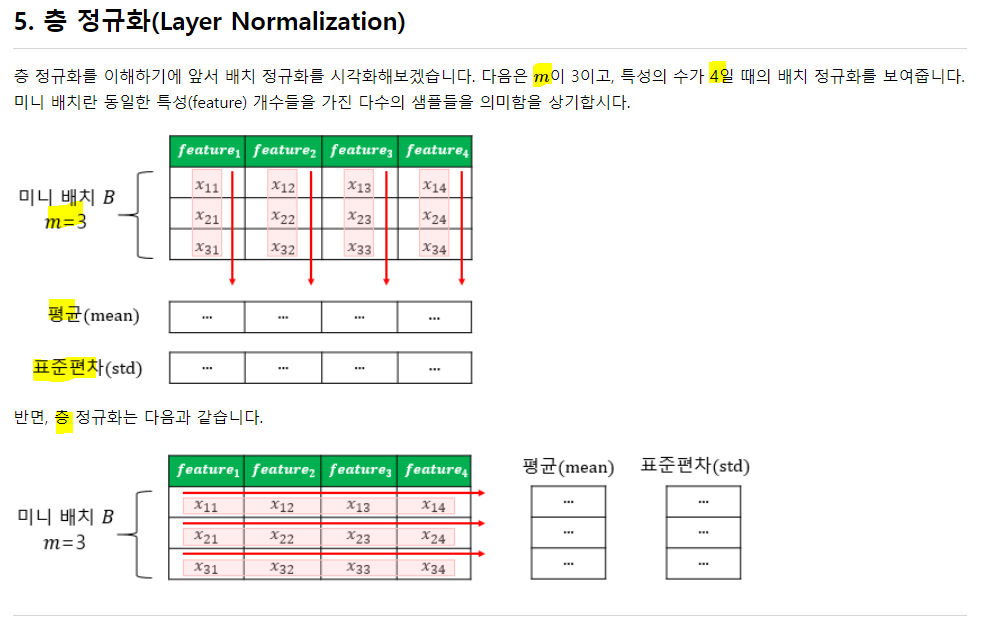
배치정규화는 각 피쳐별로 정규화를 진행하고, 층 정규화는 관측치 기준으로 정규화를 진행!
06) 케라스 훌터옵기
케라스는 유저가 손쉽게 딥 러닝을 구현할 수 있도록 도와주는 인터페이스.
케라스 공식
1. 전처리(Preprocessing)
Tokenizer()
- 토큰화와 정수 인코딩을 위해 사용
from tensorflow.keras.preprocessing.text import Tokenizer
t = Tokenizer() #토크나이저 생성
fit_text = 'The earth is an awesome place live'
t.fit_on_texts([fit_text])
test_text = 'The earth is an great place live'
sequences = t.texts_to_sequences([test_text])[0]
print('sequence: ', sequences) # great은 voca에 없으므로 출력 x
print('word_index: ', t.word_index)sequence: [1, 2, 3, 4, 6, 7]
word_index: {'the': 1, 'earth': 2, 'is': 3, 'an': 4, 'awesome': 5, 'place': 6, 'live': 7}fit_text로 fit을 했으므로 사전엔 fit 기준으로만 토큰이 존재한다. 따라서 sequences를 보면 the earth is an place live로 graet이 빠짐.
pad_sequence()
: 각 단어의 수는 제각각이므로 문장의 길이도 제각각! 이를 맞춰줘야 할 경우가 있고, 맞춰주는 걸 패딩이라 함. 정해준 길이보다 긴건 채워주고, 짧은 건 일부 자름.
from tensorflow.keras.preprocessing.sequence import pad_sequences
pad_sequences([[1,2,3], [3,4,5,6], [7,8]], maxlen = 3, padding = 'pre')
# 인코딩이 끝났다고 가정하고 array([[1, 2, 3],
[4, 5, 6],
[0, 7, 8]], dtype=int32)pad_sequences의 인자로는 1. 패딩 진행할 데이터, 2. 모든 데이터에 대해 맞춰줄 길이, 3. 'pre'를 선택하면 앞에 0을 채우고, 'post'를 선택하면 뒤에 0을 채움
이 채워주는 패드는 본인이 선택 가능! 그리고 길이가 길어 잘리는 경우엔 앞에서부터 잘림.
2. 워드 임베딩
텍스트 내 단어들을 밀집 벡터로 만드는 것을 말함. 원-핫과 비교해서 생각해보자. 원-핫은 대부분이 0이고, 하나만 1을 가지는 벡터. 또한 차원이 대체적으로 크다는 한계. 이런 벡터를 희소 벡터(sparse vector)!!
원핫은 토큰의 수만큼 벡터 차원을 가지고, 단어간 유사도가 모두 동일하단 단점..
표기상, 의미상으로 반대인 벡터가 있음. 대부분이 실수, 상대적으로 저차원인 밀집 벡터(dense vector).

이해를 돕기 위한 수도 코드.
#문장 토큰화와 단어 토큰화
text=[['Hope', 'to', 'see', 'you', 'soon'],['Nice', 'to', 'see', 'you', 'again']]
# 각 단어에 대한 정수 인코딩
text=[[0, 1, 2, 3, 4],[5, 1, 2, 3, 6]]
# 위 데이터가 아래의 임베딩 층의 입력이 된다.
Embedding(7, 2, input_length=5)
# 7은 단어의 개수. 즉, 단어 집합(vocabulary)의 크기이다.
# 2는 임베딩한 후의 벡터의 크기이다.
# 5는 각 입력 시퀀스의 길이. 즉, input_length이다.
# 각 정수는 아래의 테이블의 인덱스로 사용되며 Embeddig()은 각 단어에 대해 임베딩 벡터를 리턴한다.
+------------+------------+
| index | embedding |
+------------+------------+
| 0 | [1.2, 3.1] |
| 1 | [0.1, 4.2] |
| 2 | [1.0, 3.1] |
| 3 | [0.3, 2.1] |
| 4 | [2.2, 1.4] |
| 5 | [0.7, 1.7] |
| 6 | [4.1, 2.0] |
+------------+------------+
# 위의 표는 임베딩 벡터가 된 결과를 예로서 정리한 것이고 Embedding()의 출력인 3D 텐서를 보여주는 것이 아님.첫번째 인자 = 단어 집합의 크기. 즉, 총 단어의 개수
두번째 인자 = 임베딩 벡터의 출력 차원. 결과로서 나오는 임베딩 벡터의 크기
input_length = 입력 시퀀스의 길이
3. 모델링
Sequential(): 층을 구성하기 위해 사용
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(...) # 층 추가
model.add(...)
model.add(...)임베딩을 통해 생겨나는 임베딩 층 또한 신경망 층 하나이므로 model.add로 추가
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Embedding(사전의 크기, 임베딩 벡터의 크기, 입력 시퀀스 길이))Dense(): 전결합층을 추가
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(출력 뉴런 수, 입력 뉴런 수, 활성화...)
----------------------------------------------------------
첫번째 인자 = 출력 뉴런의 수.
input_dim = 입력 뉴런의 수. (입력의 차원)
activation = 활성화 함수.
- linear : 디폴트 값으로 별도 활성화 함수 없이 입력 뉴런과 가중치의 계산 결과 그대로 출력. Ex) 선형 회귀
- sigmoid : 시그모이드 함수. 이진 분류 문제에서 출력층에 주로 사용되는 활성화 함수.
- softmax : 소프트맥스 함수. 셋 이상을 분류하는 다중 클래스 분류 문제에서 출력층에 주로 사용되는 활성화 함수.
- relu : 렐루 함수. 은닉층에 주로 사용되는 활성화 함수.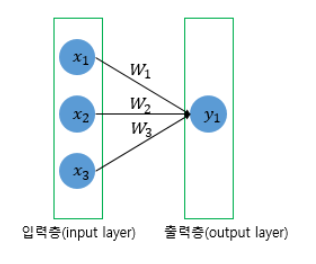
이런 층을 구성한 것!
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
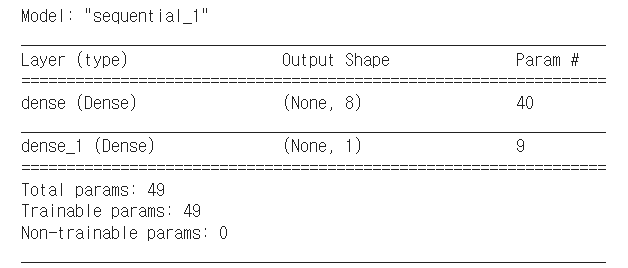
model.add(Dense(units = 8, input_dim = 4, activation = 'relu')) # 은닉
model.add(Dense(units = 1, activation = 'sigmoid')) # 출력
model.summary()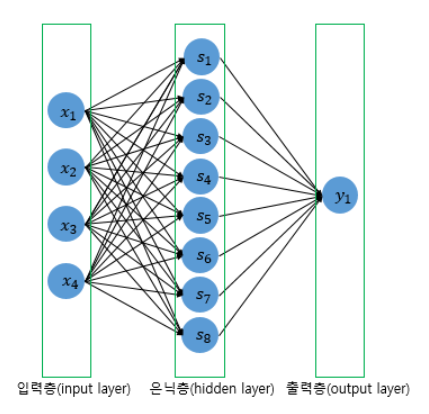
4. 컴파일과 훈련
- 컴파일은 모델을 기계가 이해할 수 있도록 함. 오차 함수, 최적화 방법, 매트릭 선택
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['acc'])
optimizer: 옵티마이저. 문자열로 지정 혹은 생성해서 지정 가능
loss: 손실함수 설정. 이것도 생성해서 지정 가능
metrics: 모니터링 하기 위한 성능 지표를 선택하는 것. 이것도 생성 지정 가능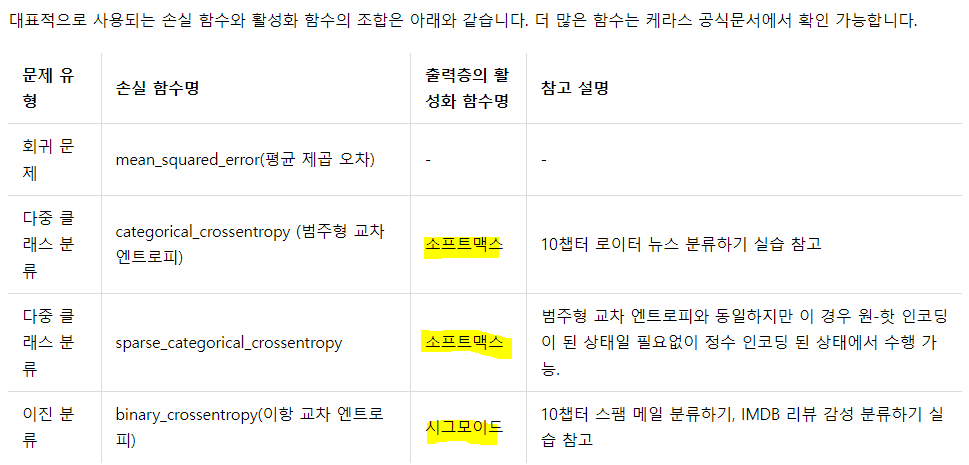
model.fit()
model.fit(X_train, y_train, epochs = 10, batch_size = 32)
미니배치 하강법을 쓰고싶다면 batch_size = None!
validation_data(X_val, y_val): 검증 데이터. 에폭마다 훈련 과정을 평가. 훈련엔 반영X
validation_split: 위 대신 사용 가능.별도로 존재하는 검증 데이터를 넣는 것이 아니라
훈련 셋에서 일정 비율을 떼어 사용. 훈련 자체에 반영 X
verbose: 출력되는 문구 설정. 0 -> 아무것도 X, 1 -> 훈련 진행 막대,
2 -> 미니배치마다 손실 정보를 출력5. 평가와 예측
evaluate(): 테스트데이터로 학습 모델에 대한 정확도 평가
model.evaluate(X_test, y_test, batch_size = 32)
X_test: 테스트 피쳐, y_test: 테스트 정답, batch_size: 배치 크기predict(): 입력에 대한 모델의 출력
model.predict(X_input, batch_size = 32)
X_input: 예측하고자 하는 데이터
batch_size: 배치 사이즈
model(input_data) 이것도 가능. 근데 둘이 같은 결과를 반환하는지는 모르겠음..6. 모델의 저장과 로드
복습을 위한 스터디, 실제 앱 개발 단계의 구현 모델을 저장하고 불러오는 건 중요. 저장한다는 것은 학습이 끝난 신경망의 구조를 보존하고 계속해서 사용!
save(): 신경망 모델을 저장
model.save('모델이름.확장자') 보통 확장자는 h5load_model(): 저장해둔 모델 불러오기
from tensorflow.keras.models import load_model
model = load_model('모델이름.확장자')07) 케라스의 함수형 API
1. Sequential API
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(...))직관적이고 편리함. 단순히 층을 쌓는 것만으로는 구현할 수 없는 복잡한 신경망을 구현할 수 없음. 전문가가 되기 위해선 Functional API를 학습해야 함
2. Functional API
각 층을 일종의 함수로서 정의. 각 함수를 조합하기 위한 연사자를 제공해 신경망을 설계.
1) Fully connected FFNN
Sequential과 다르게 functional은 입력 데이터의 크기를 인자로 정의해야 함. 입력 차원이 1인 전결합을 만든다고 가정
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
## 텐서를 리턴
inputs = Input(shape = (10, ))
## 10개의 입력을 받는 입력층을 뜻함.
## dense 옆에 인풋을 넣어주면서 쌓아감.
hidden1 = Dense(64, activation = 'relu')(inputs)
## 은닉2의 입력은 은닉1!
hidden2 = Dense(64, activation = 'relu')(hidden1)
output = Dense(1, activation = 'sigmoid')(hidden2)
## 최종 모델
model = Model(inputs = inputs, outputs = output)- Input() 함수의 입력의 크기를 정한다. 10개의 뉴런이라면 (10,)
- 이전층을 다음 함수의 입력으로 사용하고, 변수에 할당하며 적층
- Model()에 입/출력을 지정
model.compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.fit(data, labels)이렇게 까지하면 functional api를 활용한 FFNN의 생성과 학습까지 끝.
각 층의 이름을 함수의 인풋처럼 x로 통일해도 상관은 없음. 하지만 각 층별로 이름을 지정해주는게 직관적으로 이해하기에도 좋을듯?
2) 선형회귀 구현
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.models import Model
from tensorflow.keras import optimizers
X = [1,2,3,4,5,6,7,8,9]
y = [11,22,33,44,53,66,77,87,95]
inputs = Input(shape = (1,)) # 인풋 뉴런이 x 하나이므로
output = Dense(1, activation = 'linear')(inputs)
lm = Model(inputs= inputs, outputs = output)
sgd = optimizers.SGD(lr = 0.01)
lm.compile(optimizer = sgd, loss = 'mse', metrics = ['mse'])
lm.fit(X, y, batch_size = 1, epochs = 100, shuffle = False)3) 로지스틱 회귀
inputs = Input(shape = (뉴런수, ))
output = Dense(카테고리 수, activation = sig or soft)(inputs)
logistic = Model(inputs = inputs, outputs = output)4) 다중 입력받는 모델
functional api를 이용하면 다중 입력도 가능하다.
model = Model(inputs = [a1, a2], outputs = [b1, b2, b3])이런 식으로 다중 입력이 가능. Sequential은 이렇게 input에 저렇게 다중을 넣어줄 수가 없음. 리스트에 적재해나가는 느낌이기 때문에.
from tensorflow.keras.layers import Input, Dense, concatenate
from tensorflow.keras.models import Model
# 두 개의 입력을 정의
inputA = Input(shape = (64, ))
inputB = Input(shape = (128, ))
# 첫번째 입력으로부터 분기되어 진행되는 신경망 정의
x = Dense(16, activation = 'relu')(inputA)
x = Dense(8, activation = 'relu')(x)
x = Model(inputs = inputA, outputs = x)
# 두번째 입력으로부터 분기되어 진행되는 신경망 정의
y = Dense(64, activation = 'relu')(inputB)
y = Dense(32, activation = 'relu')(y)
y = Dense(8, activation = 'relu')(y)
y = Model(inputs = inputB, outputs = y)
# 두개의 신경망 출력 연결
result = concatenate([x.output, y.output])
# 연결된 값을 입력받는 Dense 추가
z = Dense(2, activation = 'relu')(result)
# 선형 회귀를 위해
z = Dense(1, activation = 'linear')(z)
# 결과적으로 이 모델은 두 개의 입력층으로부터 분기되어 진행된 후 마지막엔
# 하나의 출력을 예측하는 모델이 됨
model = Model(inputs = [x.input, y.input], outputs = z)
model.summary()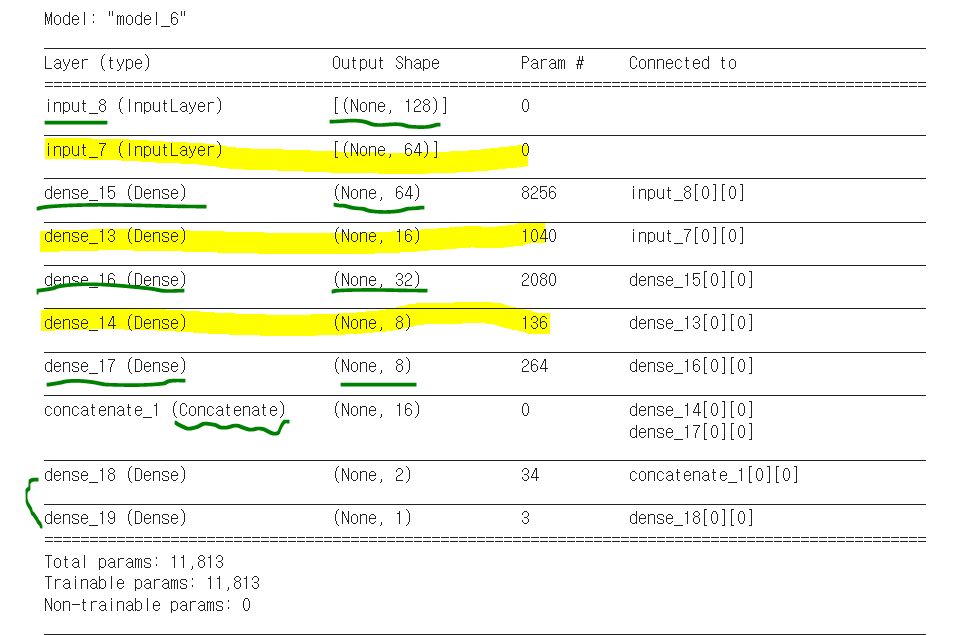
두 개의 신경망을 하나로 합쳐 결과적으로 회귀 모델을 만듦
5) RNN 은닉층 사용하기
50개의 time-step(시점)을 입력으로 받는 모델 설계
from tensorflow.keras.layers import Input, Dense, LSTM
from tensorflow.keras.models import Model
inputs = Input(shape = (50, 1))
## (50,)이 아닌 (50, 1)을 넣어줌
## data가 1열로 쭉 있는 경우인듯
## 주가처럼 주가자료만 쭉 나열된 경우
lstm_layer = LSTM(10)(inputs) # RNN계열인 LSTM 사용
x = Dense(10, activation = 'relu')(lstm_layer)
output = Dense(1, activation = 'sigmoid')(x)
model = Model(inputs = inputs, outputs = output)
model.summary()
6) 다르게 보이지만 동일한 결과
result = Dense(128)(input)이 둘은 다르 표기같지만 위의 방식이 pipeline과 같은 표기
dense = Dense(128)
result = dense(input)08) 케라스 서브클래싱
케라스의 구현 방식엔 1) Sequential api, 2) Functional api, 3) Subclassing API
모두를 위한 딥러닝을 들을 때 파이썬의 클래스 개념이 부족해서 잘 못했었음..
1. 서브클래싱으로 구현한 선형 회귀
import tensorflow as tf
class LinearRegression(tf.keras.Model):
def __init__(self):
super(LinearRegression, self).__init__() # 초기화?
# Dense 구현, 입력1, 출력1인
self.linear_layer = tf.keras.layers.Dense(1, input_dim = 1, activation = 'linear')
def call(self, x):
## 위의 내용을 다 호출
y_pred = self.linear_layer(x)
return y_pred
model = LinearRegression()x = [1,2,3,4,5,6,7,8,9]
y = [11,22,33,44,53,66,77,87,95]
sgd = tf.keras.optimizers.SGD(lr = 0.01)
model.compile(optimizer = sgd, loss = 'mse', metrics = ['mse'])
model.fit(x, y, batch_size = 1, epochs =10, shuffle = False)Epoch 1/10
9/9 [==============================] - 0s 2ms/step - loss: 434.4261 - mse: 434.4261
Epoch 2/10
9/9 [==============================] - 0s 1ms/step - loss: 2.4132 - mse: 2.4132
Epoch 3/10
9/9 [==============================] - 0s 1ms/step - loss: 2.4028 - mse: 2.4028
Epoch 4/10
9/9 [==============================] - 0s 1ms/step - loss: 2.3929 - mse: 2.3929
Epoch 5/10
9/9 [==============================] - 0s 1ms/step - loss: 2.3834 - mse: 2.3834
Epoch 6/10
9/9 [==============================] - 0s 2ms/step - loss: 2.3744 - mse: 2.3744
Epoch 7/10
9/9 [==============================] - 0s 2ms/step - loss: 2.3656 - mse: 2.3656
Epoch 8/10
9/9 [==============================] - 0s 2ms/step - loss: 2.3573 - mse: 2.3573
Epoch 9/10
9/9 [==============================] - 0s 2ms/step - loss: 2.3493 - mse: 2.3493
Epoch 10/10
9/9 [==============================] - 0s 1ms/step - loss: 2.3416 - mse: 2.3416
<keras.callbacks.History at 0x7f64e0c09c90>클래스 형태의 모델은 tf.keras.Model을 상속받는다
init()에서 모델의 구조와 동작을 정의하는 생성자를 정의.
파이썬에서 객체가 갖는 속성값을 초기화(initialize) 하는 역할로, 객체가 생성될 때 자동으로 호출된다. call() 함수는 데이터를 입력받아 예측값을 리턴하는 forward 연산을 진행시키는 함수!
- H(x) 식에 입력 x로부터 예측된 y를 얻는 것을 forward 연산이라 함.
2. 서브클래싱 api는 언제?
Sequential은 간단한 모델 구현에 적합. functional은 시퀀셜로 구현할 수 없는 복잡 모델 구현이 가능. but, Subclassing은 functional이 구현할 수 없는 모델조차 구현이 가능한 경우가 있음. functional api는 딥 러닝 모델은 DAG(directed acyclic graph)로 취급. 대부분 딥러닝이 이에 속하지만, 항상 그렇진 않음. 재귀 네트워크나 트리 RNN은 이 가정을 따르지 않고 functional api에서 구현할 수 없음
딥러닝 모델의 대부분은 functional api 수준에서는 구현이 가능. 따라서 밑바닥부터 새로운 수준의 아키텍쳐 구현해야 하는 연구를 하는 연구자들에게 적합. 즉 나는 Functional만 잘써도 된다는 듯?

09) 다층 퍼셉트론(MLP)로 텍스트 분류하기
1. 다층 퍼셉트론
- 단층 형태에서 은닉층이 1개 이상 추가된 신경망
- 가장 기본형태는 FFNN(피드포워드). 입력에서 출력으로 오직 한방향 연산
2. 케라스의 texts_to_matrix()
MLP로 텍스트 분류 수행 전, Tokenizer의 texts_to_matrix()를 이해.
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
texts = ['먹고 싶은 사과', '먹고 싶은 바나나', '길고 노란 바나나 바나나', '저는 과일이 좋아요']
## 정수 인코딩 진행
t = Tokenizer()
t.fit_on_texts(texts)
print(t.word_index){'바나나': 1, '먹고': 2, '싶은': 3, '사과': 4, '길고': 5, '노란': 6, '저는': 7, '과일이': 8, '좋아요': 9}texts_to_matrix()는 4개의 모드를 지원 'binary', 'count', 'freq', 'tfidf'
## 입력은 texts -> 문장 덩어리들
print(t.texts_to_matrix(texts, mode = 'count'))[[0. 0. 1. 1. 1. 0. 0. 0. 0. 0.]
[0. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 2. 0. 0. 0. 1. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1.]]count는 앞서 배운 DTM을 생성한다.
다만 주의할 점은, 단어의 인덱스는 1부터 시작하지만, 완성되는 행렬의 컬럼은 총 10개. 첫번째 열이 공열인듯.
DTM은 BoW기반이라 순서 정보는 보존 X. 4개 모드 전부 안되긴 함
print(t.texts_to_matrix(texts, mode = 'binary'))[[0. 0. 1. 1. 1. 0. 0. 0. 0. 0.]
[0. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 1. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1.]]DTM과 유사함. 하지만, DTM에서 빈도가2인 값들이 1로 바뀜. 왜냐면 binary 모드는 존재하는지에만 관심을 가지고 빈도엔 관심 x. 관심을 갖냐 안갖냐라서 binary인듯?
print(t.texts_to_matrix(texts, mode = 'tfidf').round(2))[[0. 0. 0.85 0.85 1.1 0. 0. 0. 0. 0. ]
[0. 0.85 0.85 0.85 0. 0. 0. 0. 0. 0. ]
[0. 1.43 0. 0. 0. 1.1 1.1 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 1.1 1.1 1.1 ]]TF-IDF를 만듦. 사이킷런의 TfidfVectorizer나 기본식이랑 idf가 계산이 좀 달랐음. 분자 분모에 +1씩을 해줬었음!!. 그치만 의도는 같음!
단어의 문장 내 빈도와, 전체 문서내 빈도를 고려!!!!!
print(t.texts_to_matrix(texts, mode = 'freq').round(2))[[0. 0. 0.33 0.33 0.33 0. 0. 0. 0. 0. ]
[0. 0.33 0.33 0.33 0. 0. 0. 0. 0. 0. ]
[0. 0.5 0. 0. 0. 0.25 0.25 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 0.33 0.33 0.33]]각 문서에서 각 단어의 비율을 표현.
3. 20개 뉴스그룹 데이터 이해
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
## 훈련 데이터만 return
newsdata = fetch_20newsgroups(subset = 'train')
print(newsdata.keys())
print('=============================================================')
print('훈련용 샘플의 수:', len(newsdata))
print('=============================================================')
print('총 주제의 수:', len(newsdata.target_names))
print(newsdata.target_names)dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])
=============================================================
훈련용 샘플의 수: 5
=============================================================
총 주제의 수: 20
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']테스트 데이터에서 이메일 본문을 보고 20개 주제 중 어떤 주제인지 맞추는 것
print('첫 샘플의 레이블: {}'.format(newsdata.target[0]))
print('첫 샘플의 주제: {}'.format(newsdata.target_names[7]))첫 샘플의 레이블: 7
첫 샘플의 주제: rec.autosprint(newsdata.data[0])From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----이메일의 내용은 스포츠 카에 대한 글. 레이블은 7, rec.autos란 주제.
data = pd.DataFrame(newsdata.data, columns = ['email'])
data['target'] = pd.Series(newsdata.target)
data.head()
이런식으로 구성됨
#탐색적 분석
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 11314 entries, 0 to 11313
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 email 11314 non-null object
1 target 11314 non-null int64
dtypes: int64(1), object(1)
memory usage: 176.9+ KBtarget은 정수형, email은 Object
info를 이용해 변수의 타입과 null이 존재하는지 확인 가능
# null이 있는지 확인
data.isnull().values.any()False단점은 어느 컬럼에 null이 있는지는 모름
print('중복을 제외한 샘플의 수: {}'.format(data['email'].nunique()))
print('중복을 제외한 주제의 수: {}'.format(data['target'].nunique()))중복을 제외한 샘플의 수: 11314
중복을 제외한 주제의 수: 20# target 빈도 시각화
data['target'].value_counts().plot(kind = 'bar')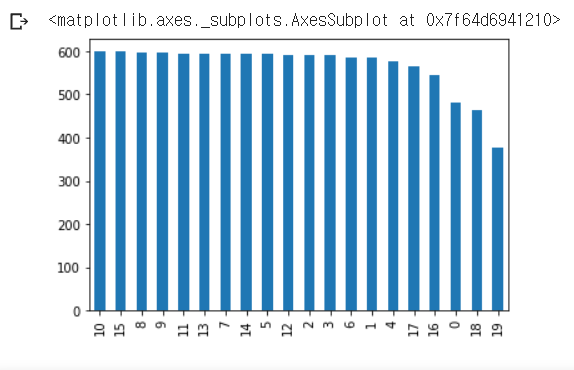
19번 레이블이 다른 범주에 비해 좀 부족
구체적으로 어느정도인지 확인
# data.target.value_counts()
print(data.groupby('target').size().reset_index(name = 'count')) target count
0 0 480
1 1 584
2 2 591
3 3 590
4 4 578
5 5 593
6 6 585
7 7 594
8 8 598
9 9 597
10 10 600
11 11 595
12 12 591
13 13 594
14 14 593
15 15 599
16 16 546
17 17 564
18 18 465
19 19 377newsdata_test = fetch_20newsgroups(subset='test', shuffle = True)
train_email = data['email']
train_label = data['target']
test_email = newsdata_test.data
test_label = newsdata_test.targetmax_words = 10000 # 단어 최대 개수
num_classes = 20 # 레이블의 수
def prepare_data(train_data, test_data, mode): #전처리 함수
t = Tokenizer(num_words = max_words) # max만큼만 토큰 생성
t.fit_on_texts(train_data)
X_train = t.texts_to_matrix(train_data, mode = mode) # 샘플 수 * maw_words 크기 행렬 생성
X_test = t.texts_to_matrix(test_data, mode = mode) # 동일
return X_train, X_test, t.index_wordX_train, X_test, index_to_word = prepare_data(train_email, test_email, 'binary') # binary 모드로
# label one-hot
y_train = to_categorical(train_label, num_classes)
y_test = to_categorical(test_label, num_classes)
print('훈련 샘플 본문의 크기 : {}'.format(X_train.shape))
print('훈련 샘플 레이블의 크기 : {}'.format(y_train.shape))
print('테스트 샘플 본문의 크기 : {}'.format(X_test.shape))
print('테스트 샘플 레이블의 크기 : {}'.format(y_test.shape))훈련 샘플 본문의 크기 : (11314, 10000)
훈련 샘플 레이블의 크기 : (11314, 20)
테스트 샘플 본문의 크기 : (7532, 10000)
테스트 샘플 레이블의 크기 : (7532, 20)rows는 email의 수, 컬럼은 max_length의 수
print('빈도수 상위 1번 단어: {}'.format(index_to_word[1]))
print('빈도수 상위 9999번 단어: {}'.format(index_to_word[9999]))빈도수 상위 1번 단어: the
빈도수 상위 9999번 단어: mic빈도대로 정렬되어 있기 때문에 가능한 것!
4. 다층 퍼셉트론 사용해 분류
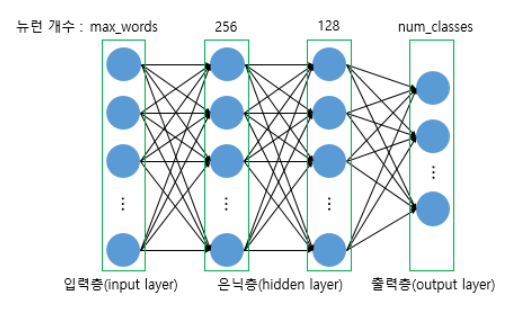
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Input
def fit_and_eval(X_train, y_train, X_test, y_test):
inputs = Input(shape = (max_words,))
dense1 = Dense(256, activation = 'relu')(inputs)
drop1 = Dropout(rate = 0.5)(dense1)
dense2 = Dense(128, activation = 'relu')(drop1)
drop2 = Dropout(rate = 0.5)(dense2)
output = Dense(num_classes, activation = 'softmax')(drop2)
model = Model(inputs = inputs, outputs = output)
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
# train set에서 10%만큼 떼어서 valid 용으로 사용. 파라미터 튜닝을 하거나 그러진 않고 그냥 평가만
model.fit(X_train, y_train, batch_size = 128, epochs = 5, verbose = 1, validation_split= .1)
score = model.evaluate(X_test, y_test, batch_size = 128, verbose = 0)
return score[1]교재는 Sequential API로 구현했지만, 난 functional로 구현
dense 2개인 DNN.
modes = ['binary', 'count', 'tfidf', 'freq']
for mode in modes:
X_train, X_test, _ = prepare_data(train_email, test_email, mode) # 모드에 따라 전처리
score = fit_and_eval(X_train, y_train, X_test, y_test) # 모델 생성, 훈련과 평가까지
print(mode + ' 모드의 테스트 정확도:',score)Epoch 1/5
80/80 [==============================] - 4s 41ms/step - loss: 2.2983 - accuracy: 0.3262 - val_loss: 0.9538 - val_accuracy: 0.8295
Epoch 2/5
80/80 [==============================] - 3s 40ms/step - loss: 0.8658 - accuracy: 0.7634 - val_loss: 0.4415 - val_accuracy: 0.9037
Epoch 3/5
80/80 [==============================] - 3s 40ms/step - loss: 0.4377 - accuracy: 0.8847 - val_loss: 0.3361 - val_accuracy: 0.9064
Epoch 4/5
80/80 [==============================] - 3s 39ms/step - loss: 0.2586 - accuracy: 0.9321 - val_loss: 0.3100 - val_accuracy: 0.9090
Epoch 5/5
80/80 [==============================] - 3s 40ms/step - loss: 0.1774 - accuracy: 0.9572 - val_loss: 0.2852 - val_accuracy: 0.9170
binary 모드의 테스트 정확도: 0.8276686072349548
Epoch 1/5
80/80 [==============================] - 4s 42ms/step - loss: 2.7982 - accuracy: 0.2296 - val_loss: 1.6439 - val_accuracy: 0.7155
Epoch 2/5
80/80 [==============================] - 3s 40ms/step - loss: 1.4684 - accuracy: 0.6180 - val_loss: 0.7234 - val_accuracy: 0.8463
Epoch 3/5
80/80 [==============================] - 3s 40ms/step - loss: 0.8058 - accuracy: 0.7921 - val_loss: 0.5035 - val_accuracy: 0.8781
Epoch 4/5
80/80 [==============================] - 3s 40ms/step - loss: 0.5592 - accuracy: 0.8681 - val_loss: 0.4128 - val_accuracy: 0.9011
Epoch 5/5
80/80 [==============================] - 3s 40ms/step - loss: 0.3793 - accuracy: 0.9096 - val_loss: 0.3893 - val_accuracy: 0.8984
count 모드의 테스트 정확도: 0.8143919110298157
Epoch 1/5
80/80 [==============================] - 4s 41ms/step - loss: 2.2342 - accuracy: 0.3571 - val_loss: 0.7945 - val_accuracy: 0.8463
Epoch 2/5
80/80 [==============================] - 3s 40ms/step - loss: 0.8638 - accuracy: 0.7642 - val_loss: 0.4233 - val_accuracy: 0.9028
Epoch 3/5
80/80 [==============================] - 3s 40ms/step - loss: 0.4384 - accuracy: 0.8854 - val_loss: 0.3345 - val_accuracy: 0.9143
Epoch 4/5
80/80 [==============================] - 3s 39ms/step - loss: 0.2891 - accuracy: 0.9256 - val_loss: 0.3158 - val_accuracy: 0.9214
Epoch 5/5
80/80 [==============================] - 3s 40ms/step - loss: 0.1899 - accuracy: 0.9507 - val_loss: 0.3459 - val_accuracy: 0.9178
tfidf 모드의 테스트 정확도: 0.8304567337036133
Epoch 1/5
80/80 [==============================] - 4s 42ms/step - loss: 2.9764 - accuracy: 0.0944 - val_loss: 2.9301 - val_accuracy: 0.2164
Epoch 2/5
80/80 [==============================] - 3s 40ms/step - loss: 2.7499 - accuracy: 0.1856 - val_loss: 2.4634 - val_accuracy: 0.3542
Epoch 3/5
80/80 [==============================] - 3s 40ms/step - loss: 2.2700 - accuracy: 0.2953 - val_loss: 1.9856 - val_accuracy: 0.5459
Epoch 4/5
80/80 [==============================] - 3s 40ms/step - loss: 1.8366 - accuracy: 0.4290 - val_loss: 1.5777 - val_accuracy: 0.6546
Epoch 5/5
80/80 [==============================] - 3s 40ms/step - loss: 1.4691 - accuracy: 0.5592 - val_loss: 1.2348 - val_accuracy: 0.7261
freq 모드의 테스트 정확도: 0.6852097511291504freq만 혼자 정확도가 80%랑 동떨어진다. tf-idf가 성능이 제일 좋음. 끝!
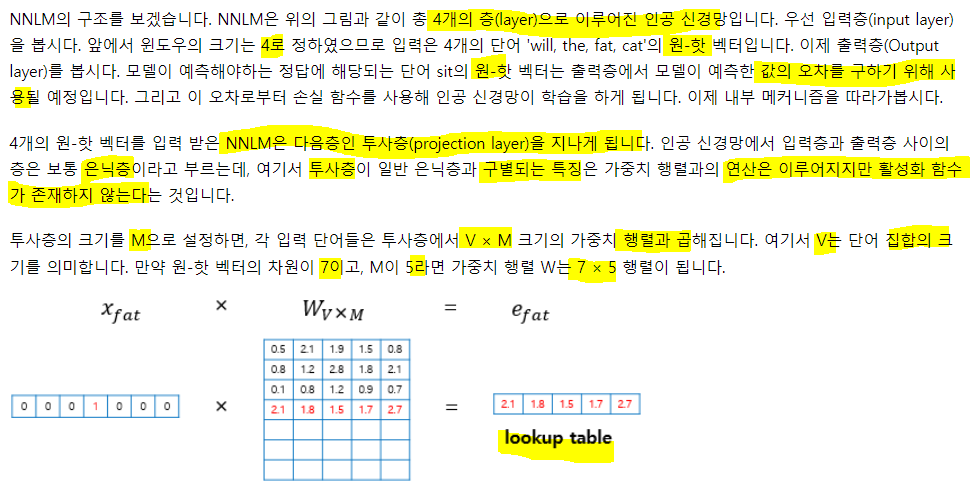
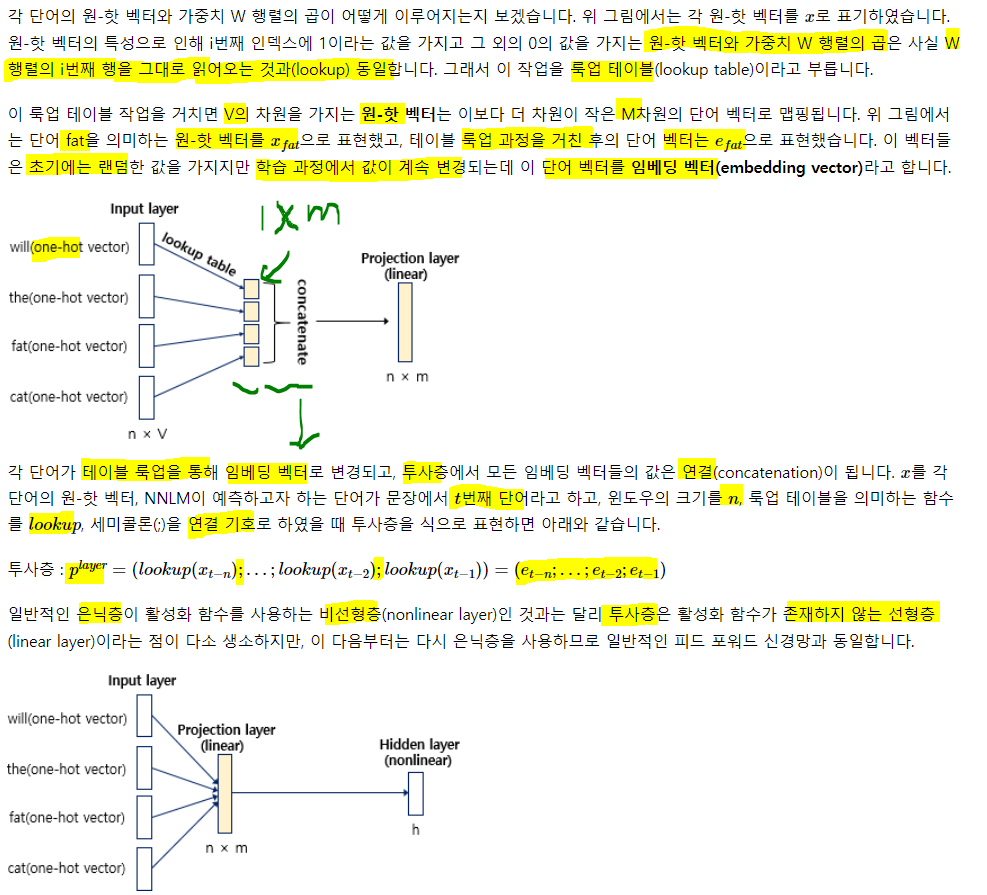
10) 피드 포워드 신경망 언어 모델(Neural Network Language Model, NNLM)
자연어는 문법이란 규칙이 있지만, 예외 사항, 시간에 따른 변화, 중의성과 모호성을 전부 명세하기란 어렵다. 기계가 자연어를 표기하도록 규칙으로 명세하기 어려운 상황에서 대안은 규칙 기반 접근이 아닌 기계까 주어진 자연어 데이터를 학습하게 하는 것
과거엔 통계적 접근 방법들 SLM, n-gram등을 사용했으나, 최근엔 신경망이 더 주목 받는다. 번역기, 음성인식과 같이 자연어 생성(Natural Language Generation, NLG)의 기반으로 사용되는 언어 모델도 마찬가지.
신경망 언어모델의 시초인 피드 포워드 신경망 언어모델에 대해 학습. NNLM이라고 함.
1. 기존 N-gram의 한계
언어 모델은 문장에 확률을 할당하는 모델, 문맥으로부터 모르는 단어를 예측하는 것을 언어모델링!

- 쓰는건 좋다 이건데, 코퍼스 내에 충분한 샘플이 존재 하니?... 의문
2. 단어의 의미적 유사성

3. 피드포워드 신경망 언어 모델(NNLM)