
현재 진행중인 산학협력 프로젝트의 주제는
LG AI Research가 주최하는 AI 기반 회의 녹취록 요약 경진대회를 참여하고, 생성된 모델을 바탕으로 Web 구현하는 것으로 정했습니다.
자연어 처리 경험이 부족하므로 학습을 통해 채우고자 WikiDocs의
'딥 러닝을 이용한 자연어 처리 입문'을 공부합니다.
공부하며 배운 내용들을 정리할 계획입니다!
01. 자연어 처리(natural language processing)란?
자연어 -> 우리가 일상 생활에서 사용하는 언어를 뜻함
자연어 처리 -> 자연어의 의미를 분석해 컴퓨터가 처리할 수 있도록 하는 일
음성인식, 내용 요약, 번역, 감성 분석, 텍스트 분류 작업(스팸 분류, 뉴스 카테고리 분류), 질의 응답 시스템, 챗봇과 같은 곳에서 사용
필요 프레임워크와 라이브러리
Numpy, Pandas, Jupyter notebook, scikit-learn, matplotlib, seaborn, nltk는 Anaconda 설치 했다면 기본적으로 깔려있음. 안깔린 것들을 위주로 소개
1. 텐서플로우(Tensorflow)
- 구글의 머신 러닝 오픈소스 라이브러리로써 머신 러닝과 딥 러닝을 직관적이고 손쉽게 할 수 있도록 설계
명령어:pip install tensorflow
- 구글의 머신 러닝 오픈소스 라이브러리로써 머신 러닝과 딥 러닝을 직관적이고 손쉽게 할 수 있도록 설계
2. 케라스(Keras)
- 딥 러닝 프레임워크인 텐서플로우에 대한 추상화 된 API를 제공. 백엔드로 텐서플로우를 사용하며, 좀 더 쉽게 딥 러닝을 사용할 수 있게 지원. 쉽게 말해, 텐서플로우 코드를 훨씬 간단하게 작성 가능!
명령어:pip install keras. 최신 버전에선 굳이 keras install 필요 없음
- 딥 러닝 프레임워크인 텐서플로우에 대한 추상화 된 API를 제공. 백엔드로 텐서플로우를 사용하며, 좀 더 쉽게 딥 러닝을 사용할 수 있게 지원. 쉽게 말해, 텐서플로우 코드를 훨씬 간단하게 작성 가능!
3. 젠심(Gensim)
- 머신 러닝을 사용해 토픽 모델링과 자연어 처리 등을 수행할 수 있게 해주는 오픈 소스 라이브러리.
명령어:pip install gensim
- 머신 러닝을 사용해 토픽 모델링과 자연어 처리 등을 수행할 수 있게 해주는 오픈 소스 라이브러리.
4. 사이킷런(Scikit-learn)
- 파이썬의 대표적인 머신러닝 라이브러리. 나이브 베이즈, 서포트 벡터 머신 등 다양한 모듈을 불러올 수 있음. 또한, 머신러닝 연습을 위한 datasets -> 아이리스, 당뇨병 등 제공.
pip install scikit-learn
- 파이썬의 대표적인 머신러닝 라이브러리. 나이브 베이즈, 서포트 벡터 머신 등 다양한 모듈을 불러올 수 있음. 또한, 머신러닝 연습을 위한 datasets -> 아이리스, 당뇨병 등 제공.
5. 주피터 노트북(Jupyter Notebook)
- 주피터 노트북은 웹에서 코드를 작성하고 실행할 수 있는 오픈소스 웹 어플리케이션.
pip install jupyter
설치가 완료되었다면 명령어를 통해 주피터 노트북을 사용 가능
jupyter notebook. 개인적으로 notebook 보단 lab이 더 보기 깔끔
- 주피터 노트북은 웹에서 코드를 작성하고 실행할 수 있는 오픈소스 웹 어플리케이션.
자연어 처리를 위한 NLTK와 KoNLPy 설치하기
1. NLTK
- 자연어 처리를 위한 파이썬 패키지. 마찬가지로 아나콘다를 설치했다면 기본적으로 설치
- NLTK 기능을 제대로 사용하기 위해선 NLTK Data라는 여러 데이터의 추가적 설치가 필요.
install nltk
nltk.download()를 통해 각종 패키지와 코퍼스를 다운받을 수 있음.
2. KoNLPy
- 한국어 자연어 처리를 위한 형태소 분석기 패키지.
pip install konlpy - 윈도우에서 KoNLPy를 설치하거나 실행 시 JDK 관련 오류나 JPype 오류에 부딪힣는 경우가 있음. KoNLPy가 JAVA로 구성되어 있기 때문에 그런거라 오류 해결을 위해선 JDK 1.7 이상 버전과 JPype가 설치되어 있어야 함.
링크 참고: [wikidocs.net/22488]
- 한국어 자연어 처리를 위한 형태소 분석기 패키지.
판다스 프로파일링(Pandas-Profilling)
- 머신러닝을 통해 좋은 결과를 얻고 싶다면 데이터의 성격 파악이 선행되어야 함. 투입이 좋아야 산출도 좋으므로!
- 데이터 내 값의 분포, 변수 간의 관계, 결측값 존재 유무등을 파악하는 EDA를 profilling을 이용해 탐색!!
pip install -U pandas_profiling 명령어를 통해 설치하고 코랩의 런타임 재시작을 해주고 아래의 import를 진행하기
1. 실습 파일 불러오기
import pandas as pd
import pandas_profiling
data = pd.read_csv('/content/drive/MyDrive/산학협력프로젝트/딥러닝을 이용한 자연어 처리 입문/spam.csv', encoding = 'latin1')data의 위치는 각자 본인이 저장한 위치를 입력!
2. 리포트 생성하기
dr = data.profile_report() # 프로파일링 결과 리포트를 dr에 저장
pr.to_file('./pr_report.html') # html형식의 파일로도 저장 가능!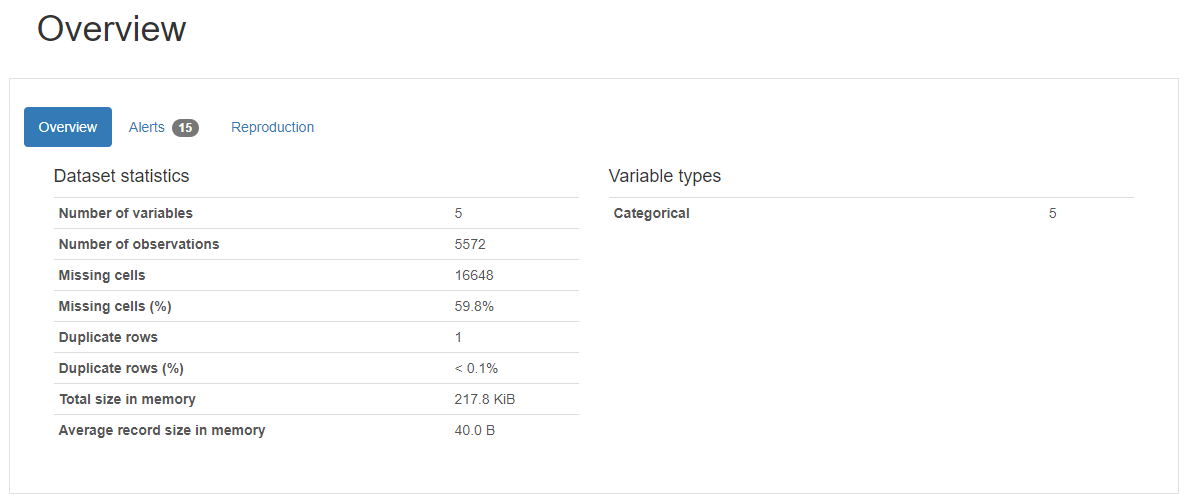
- 개요를 보면 우선 rows는 5572, columns는 5.
하나의 행, 열을 cell로 봤을 때 5 * 5572개의 셀이 존재하고, 그 중 16,648(59.8%)가 결측값으로 확인됨
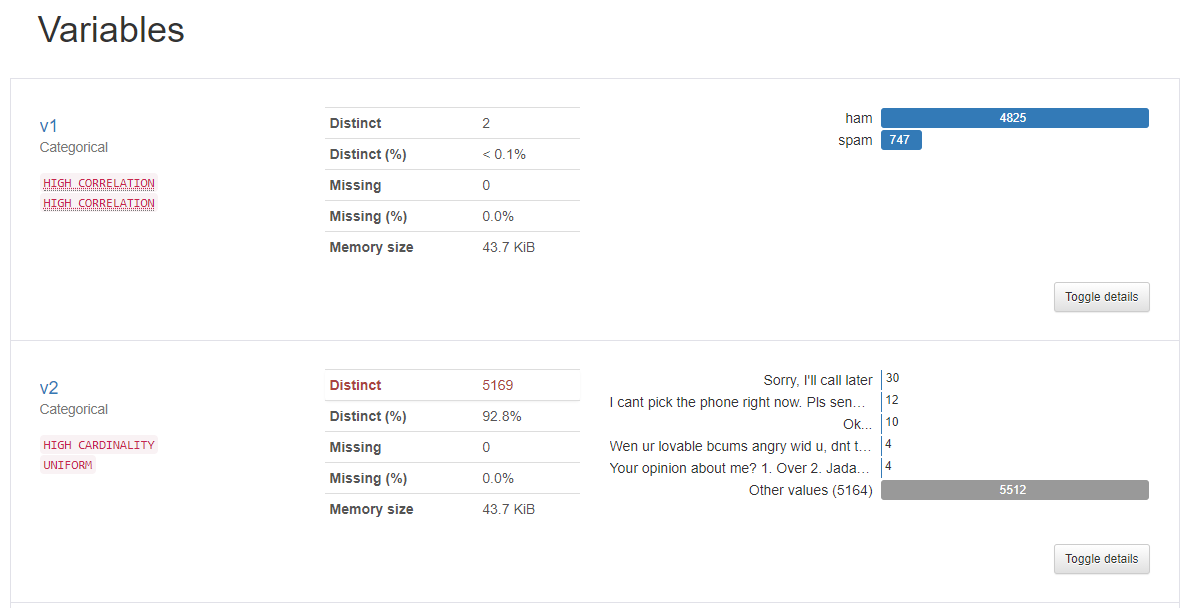

- Unnamed: 2, 3, 4가 99% 이상씩 결측값을 가지고 있어 데이터 셋에서 별다른 의미가 없음.
- text가 들어있는 v2를 보면 5169개의 unique한 관측치가 있음 -> 총 rows는 5572이므로 5572 - 5169 = 403개의 메일의 중복이 있다는 것을 알 수 있음
머신러닝 워크플로우
데이터를 수집하고 머신 러닝을 하는 과정은 크게 6개로 나누면 아래와 같음.
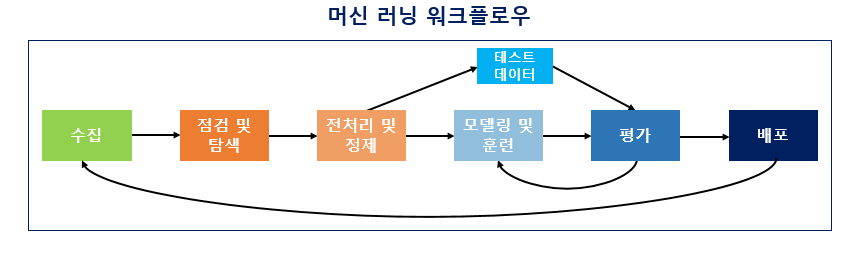
1. 수집(Acquisition)
머신러닝을 하기 위해선 학습시켜야 할 데이터가 필요. 자연어 처리의 경우, 자연어 데이터를 말뭉치 또는 코퍼스라고 부르는데 의미를 풀이하자면, 조사나 연구 목적에 의해서 특정 도메인으로부터 수집된 텍스트 집합을 말함. -> 그냥 텍스트 뭉치 or 덩어리로 생각!
텍스트 파일의 형식은 txt, csv, xml 등 다양하고 그 출처도 음성 데이터, 웹 수집기를 통해 수집된 데이터, 영화 리뷰 등 다양함!2. 점검 및 탐색(Inspection and exploration)
데이터가 수집 됐다면, 데이터를 점검하고 탐색해야 함. 데이터의 구조, 노이즈 데이터, 머신 러닝 적용을 위해 어떻게 정제를 해야할지 파악
EDA라고도 하는데 독립 변수, 종속 변수, 변수 유형, 변수의 데이터 타입 등을 점검하며 데이터의 특징과 내재하는 구조적 관계를 알아내는 과정을 의미.
이 과정에서 시각화와 간단한 통계 테스트를 진행(가설 검정)3. 전처리 및 정제(Preprocessing and Cleaning)
가장 까다로운 작업 중 하나. 많은 단계를 포함하고, 자연어 처리의 경우 1) 토큰화, 2)정제, 3)정규화, 4)불용어 제거 등의 단계를 포함. 빠르고 정확한 전처리를 위해선 사용하는 언어에 대한 다양한 라이브러리 지식이 필요. 정말 까다로운 전처리의 경우엔 전처리 과정에서 머신러닝을 사용함.
4. 모델링 및 훈련(Modeling and Training)
전처리 후에 머신 러닝에 대한 코드를 작성하는 단계임. 적절한 머신러닝 알고리즘을 선택해 기계에게 학습. 기계가 데이터에 대한 학습이 제대로 되었다면 우리가 원하는 Task인 기계 번역, 음성 인식, 텍스트 분류 등의 자연어 처리 작업을 수행!
학습이 제대로 되었는지 확인을 위해서 train, validation, test set의 구분이 필요. 그래야 기계의 성능 평가가 가능하고 Over-fitting(train은 good, predict는 bad)인 상황을 피할 수 있음
- 시험에 비유하자면, train은 문제집, valid는 모의고사, test는 수능 시험이라 생각
- valid는 현재 모델이 train data로 얼마나 학습을 잘 했는지 평가에 사용. 모델의 성능 개선에 사용
- test는 모델의 최종 성능을 평가하는 데이터. 성능 개선에 사용되는 것이 아니라 성능을 수치화 해 평가하기 위해 사용. 이걸 활용해 여러 모델간의 비교 가능
5. 평가(evaluation)
기계가 학습이 다 되었다면 테스트용 데이터로 성능을 평가. 평가 방법은 기계가 예측한 데이터가 실제 정답인 테스트용 데이터에 얼마나 가까운지를 측정!
6. 배포(Deployment)
5번 단계에서 기계가 성공적으로 훈련이 되었다면 완성된 모델의 배포가 이뤄짐. 완성된 모델에 대한 전체적인 피드백에 대해 모델을 변경하는 상황이 온다면 다시 처음부터 돌아가야 하는 상황이 올 수 있음...

Data science