텍스트 전처리(Text preprocessing)
자연어 처리에 있어 전처리는 매우 중요.
용도에 맞게 텍스트를 사전에 처리하는 작업을 뜻함.
만약 제대로 전처리되지 않았다면 자연어 처리 기법들이 제대로 동작 X
01) 토큰화(Tokenization)
자연어 처리에서 크롤링 등으로 얻어낸 코퍼스 데이터(텍스트 뭉치들)가 필요에 맞게 전처리되지 않은 상태라면, 사용하고자 하는 용도에 맞게 토큰화 & 정제 & 정규화를 해 줌.
토큰화란? 주어진 corpus에서 token이라 불리는 단위로 나누는 작업을 뜻함. 토큰의 단위는 상황마다 다르지만, 보통 의미있는 단위로 정함.
1. 단어 토큰화
토큰의 기준을 단어로 하는 경우. word 외에도 단어 구, 의미를 갖는 문자열로 간주되기도 함.
ex> 입력으로부터 구두점(punctuation)과 같은 문자는 제외시키는 간단한 작업을 한다 생각.
구두점은 '.', ',', '?', '!'와 같은 기호를 뜻함
입력: Time is an illusion. Lunchtime double so!
출력: 'Time', 'is', 'an', illusion', 'Lunchtime', 'double', 'so'
이 예제의 토큰화는 매우 간단. 구두점을 제거하고 ' '을 기준으로 잘라냄.
보통 토큰화 작업은 구두점이나 특수문자를 전부 제거하는 정제 작업을 수행하는 것만으로 해결되지 않음. 전부 제거하면 토큰이 의미를 잃어버리는 경우가 발생하기도 함. 또한, 한국어는 띄어쓰기 만으로는 단어 토큰을 구분하기 어렵다.
2. 토큰화 중 선택의 순간!
Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.라는 문자열을 토큰화 한다 생각해보자.'가 들어간 상황에서 어떻게 토큰화 할까?
원하는 결과가 나오도록 토큰화 도구를 직접 설계할 수도 있음. 기존 공개된 도구를 사용한다면 설계된게 다르므로 다르 결과를 반환하게 됨
from nltk.tokenize import word_tokenize
string = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."
print(word_tokenize(string))
- nltk의 word_tokenize의 경우 Don't를 Do와 n't로 구분했음

- WordPuctTokenizer의 경우 구두점을 별도로 분류하는 특징을 가지므로 Don과 '와 t로 분리.

- keras의 text_to_word_sequence는 기본적으로 알파벳을 소문자로 바꾸고 마침표나 컴마, 느낌표 등의 구두점을 제거함. 하지만 don't나 jone's의 경우 아포스트로피는 보존하는 것 을 알 수 있음.
3. 토큰화에서 고려해야할 사항
토큰화 작업을 단순하게 코퍼스에서 구두점을 빼고, 공백 기준으로 잘라내는 작업이라 간주할 수 없음
따라서 좀 더 섬세한 알고리즘이 필요.
1. 구두점이나 특수 문자의 단순 제외는 안됨
.과 같은 경우엔 문장 사이의 경계를 알 수 있으므로 유용한 정보가 됨. 또한, 단어 자체에서 구두점을 갖는 경우가 있음. ph.D, AT&T와 같은 경우. 또, $45.55는 가격을 의미하는데 45.55는 뭘 의미하는지 모를 뿐더러, 45와 55로 나눈다면 더 막막해지는 상황. 또, 01/02/06은 날짜를 의미하는데 010206이나 01과 02와 06으로 나뉜다면 그 의미를 손실하게 됨.2. 줄임말과 단어 내에 띄어쓰기가 있는 경우
'는 압축된 단어를 다시 펼치는 역할을 하기도 함. we're은 we are의 줄임말. re를 접어(clitic)이라 하는데, 단어가 줄임말로 쓰일 때 생기는 형태를 말함.
또, New York, rock 'n' roll과 같은 단어는 한 단어이지만 중간에 띄어쓰기가 존재. 용도에 따라 단어 사이에 띄어쓰기가 있는 경우도 한 토큰으로 봐야하므로 토큰화 작업은 저런 단어를 하나의 단어로 인식할 수 있는 능력을 가져야 함.3. 표준 토큰화 예제
- 표준으로 쓰이는 Penn Treebank Tokenization에 대해 배움
- 규칙1: 하이푼(-)으로 구성된 단어는 하나로 유지
- 규칙2: doesn't와 같은 '로 '접어'가 함꼐하는 단어는 분리

- 결과를 보면 규칙에 의해 return을 해줌. home-based는 하나의 토큰으로, does와 n't는 분리.
4. 문장 토큰화(Sentence Tokenization)
문장 단위로 토큰화를 할 때는 어떻게 해야할까? 코퍼스가 정제되지 않은 상태라면, 코퍼스는 문장 단위로 구분되어있지 않을 가능성이 높음
직관적으로 봤을 때 !, ?, .을 기준으로 잘라내면 될 것 같지만, 꼭 그렇지 않음. 이러한 구두점들은 꽤나 명확한 boundary의 역할을 하지만 아닌 경우도 너무 많음
- ex1: IP 192.168.56.31 서버에 들어가서 ~~. -> 192.168.56.31은 구분되어야 하는 요소가 아니라 하나로 인식되어야 하므로 .을 기준으로 자른다면 의미가 사라짐
사용하는 코퍼스가 어느 나라의 언어인지, 해당 코퍼스 내에서 특수문자들이 어떻게 사용되는지에 따라 규칙을 정의해볼 필요가 있음. 100% 정확도를 얻는 것은 쉬운 일이 아니고, 갖고있는 코퍼스에 오타나, 문장의 구성이 엉망이라면 정해놓은 규칙이 아무 소용 없음.
nltk는 영어 문장의 토큰화를 수행하는 sent_tokenize를 지원.
from nltk.tokenize import sent_tokenize
text="His barber kept his word. But keeping such a huge secret to himself was driving him crazy. Finally, the barber went up a mountain and almost to the edge of a cliff. He dug a hole in the midst of some reeds. He looked about, to make sure no one was near."
print(sent_tokenize(text))
- 모든 문장을 구분해줄 만큼 아주 정확함. 만약 문장 내에 .와 같은 것이 많다면?

- 그 의미를 제대로 파악해 분리해줬음. 아주 good

- 한국어도 한 번 해봄. !!를 분리하긴 했지만 나름 good.

- 한국어에 대한 토큰화 도구로 KSS(Korean Sentence Splitter)를 추천한다 함.
- !!도 제대로 붙어있음. 넘 짧은 문장이라 좋다 판단하긴 이름

-
'재미있긴 해'를 재미있긴 + 해로 나눠서 sentence split을 했음(KSS가)
모든 상황에서 가장 좋은 건 역시 없는 듯... -
5. 이진 분류기(Binary Classifier)
-
토큰화에서 예외 사항을 발생시키는 마침표의 처리를 위해 입력에 따라 두 개의 클래스로 분류하는 이진 분류기를 사용하기도 함.
-
두 개의 클래스란 1) 마침표가 일부분일 경우. 즉 약어로 쓰이는 경우. 2) 마침표가 정말로 구분자인 경우.
-
어떤 마침표가 주로 약어로 쓰이는 지 알아야 함 -> 약어 사전이 유용하게 쓰임.
-https://public.oed.com/how-to-use-the-oed/abbreviations/ -> 영어권 언어의 약어 사전
-https://www.grammarly.com/blog/engineering/how-to-split-sentences/ -> 문장 토큰화 예외사항을 룬 참고자료! -
6. 한국어에서 토큰화의 어려움
-
영어는 New York과 같은 합성어나 he's 같은 줄임말만 잘 처리한다면 띄어쓰기 기준으로 토큰화를 해도 잘 작동. 대부분의 경우에서 단어 단위로 띄어쓰기가 이뤄지기 때문에 띄어쓰기 토큰화가 단어 토큰화와 거의 같음
-
하지만 한국어는 띄어쓰기 만으로는 토큰화가 어려움. 띄어쓰기의 단위를 '어절'이라 하는데 어절 토큰화는 한국어 NLP에서 지양. 어절 토큰화가 단어와 같지 않음. 한국어는 교착어(조사, 어미 등을 붙여 말을 만드는 언어)라서 어절 토큰화와 단어 토큰화가 같지 않음!
한국어엔 '조사'가 존재. 예를 들어, 그라는 주어나 목적어가 들어간 문장이 있다면, 그라는 단어 하나에도 '그가', '그에게', '그를', '그와', '그는'과 같이 '그'라는 의미있는 단어에 띄어쓰기 없이 붙어 다른 단어로 구분됨. -> 자연어 처리가 어려워지는 이유 중 하나. 따라서 대부분 한국어 NLP에선 조사를 분리해줌
즉, 띄어쓰기 단위가 영어처럼 독립적인 단어라면 띄어쓰기 단위의 토큰화가 되지만, 한국어는 어절이 독립적인 단어로 구성되는 것이 아니라 조사와 같은 무언가가 붙어있는 경우가 많아서 이를 다 분리!!
한국어 토큰화에선 형태소(morpheme)란 개념을 반드시 이해해야 함
- 뜻을 가진 가장 작은 말의 단위
- 1) 자립 형태소
접사, 어미, 조사와 상관없이 자립해 사용할 수 있는 형태소. 그 자체로 단어가 됨. 체언(명사, 대명사, 수사), 수식언(관형사, 부사), 감탄사 등이 있음 - 2) 의존 형태소
다른 형태소와 결합해 사용되는 형태소. 접사, 어미, 조사, 어간을 말한다.
예를들면'에디가 딥러닝 책을 읽었다'라는 문장이 있다면
- 자립형태소: '에디', '딥러닝', '책'
- 의존 형태소: '-가', '-을', '읽-', '-었', '-다'
- 한국어는 어절 토큰화가 아닌 형태소 토큰화를 수행해야 한다!
또한, 한국어에선 띄어쓰기가 영어보다 잘 지켜지지 않음
- 영어권 언어에 비해 띄어쓰기가 어렵고, 잘 안지켜 짐. 한국어의 경우 띄어쓰기가 없더라도 글을 쉽게 이해할 수 있는 언어라는 특징이 있음
ex) 띄어쓰기를전혀하지않았더라도너는글을이해할수있잖아?
ex)Tobeornottobethatisthequesition(To be or not to be that is the question) - 이처럼 한국어는 이해가 가능하지만, 영어는 이해가 너무 어려움. 띄어쓰기 자체가 어려운 이유도 있고, 이런 이유도 있어서 대체로 한국어 corpus는 제대로 지켜지지 않은 경우가 다반사!
7. 품사 태깅(Part-of-speech tagging -> pos)
단어는 같지만, 품사에 따라 의미가 다르 경우가 존재.
'못'의 경우 명사로서는 망치를 사용해 목재 따위를 고정하는 물건을 뜻하지만, 부사로서는 '먹는다', '달린다'와 같은 동작 동사를 부정하는 의미로도 쓰임.
즉, 단어의 의미 파악을 위해선 어떤 품사로 쓰였는지 제대로 파악이 필요함
8. NLTK와 KoNLPy를 이용해 영어, 한국어 토큰화 실습
토큰화
from nltk.tokenize import word_tokenize
text = 'I am actively looking for Ph.D. students. and you ar a Ph.D. student'
print(word_tokenize(text))['I', 'am', 'actively', 'looking', 'for', 'Ph.D.', 'students', '.', 'and', 'you', 'ar', 'a', 'Ph.D.', 'student']품사 태깅
nltk.download('averaged_perceptron_tagger') ## pos_tag를 쓰려면 필수
from nltk.tag import pos_tag
x = word_tokenize(text)
pos_tag(x)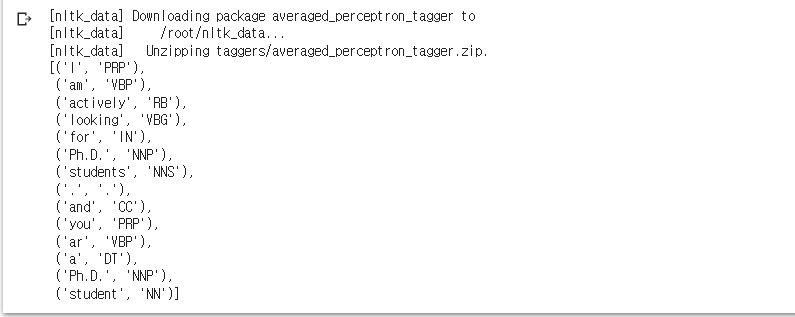
- tokenize 하고 그걸 pos_tag에 넣어줌.
- PRP(인칭 대명사), VBP(동사), RB(부사), VBG(현재 부사), IN(전치사), NNP(고유 명사), NNS(복수형 명사), CC(접속사), DT(관사)
한국어 자연어 처리를 위해선 코엔엘파이(KoNLPy)를 사용한다. 사용 가능한 형태소 분석기로는
1) Okt(Open Korea Text), 2) Mecab(메캅), 3) Komoran(코모란), 4) Hannanum(한나눔),
5) Kkma(꼬꼬마)가 있음
한국어 형태소 분석기를 사용하는 것은 단어 토큰화가 아니라 정확히 형태소 단위로 토큰화를 수행하는 것을 뜻한다. 이 중 Okt, Kkma로 실습을 해봄
from konlpy.tag import Okt
okt = Okt() ## 형태소 분석기 생성
print(okt.morphs('열심히 코딩한 당신, 연휴에는 여행을 가라'))['열심히', '코딩', '한', '당신', ',', '연휴', '에는', '여행', '을', '가라']- 좀 오래걸리긴 함. 형태소(자립+의존) 단위의 토크화가 이뤄진 결과.
print(okt.pos('열심히 코딩한 당신, 여행 가라'))[('열심히', 'Adverb'), ('코딩', 'Noun'), ('한', 'Josa'), ('당신', 'Noun'), (',', 'Punctuation'), ('여행', 'Noun'), ('가라', 'Noun')]각 형태소에 품사 태깅이 되어있음.
print(okt.nouns('열심히 코딩한 당신, 여행지로 떠나라'))['코딩', '당신', '여행지']- morphs: 형태소 추출
- pos: 품사 태깅
- nouns: 명사 추출
형태소 추출과 품사 태깅을 보면 조사를 기본적으로 분리하고 있음. 한국어 NLP에서 전처리에 형태소 분석기를 사용하는 것은 꽤 유용.
꼬꼬마를 이용해서 형태소 단위 토큰화를 진행
from konlpy.tag import Kkma
kkma = Kkma() ## 꼬꼬마 분석기 생성
print(kkma.morphs('열심히 코딩한 당신, 연휴에는 여행을 가라'))['열심히', '코딩', '하', 'ㄴ', '당신', ',', '연휴', '에', '는', '여행', '을', '가라']print(kkma.pos('열심히 코딩한 당신, 여행 가라'))[('열심히', 'MAG'), ('코딩', 'NNG'), ('하', 'XSV'), ('ㄴ', 'ETD'), ('당신', 'NP'), (',', 'SP'), ('여행', 'NNG'), ('가라', 'VV')]print(kkma.nouns('열심히 코딩한 당신, 여행지로 떠나라'))['코딩', '당신', '여행', '여행지로', '지로']- Okt와 결과가 다르것을 볼 수 있음. 각 형태소 분석기 마다 설계된 것이 다르기 때문에 성능과 결과가 다름. 따라서 필요한 용도에 따라 어떤 분석기가 가장 적절할지 판단하고 사용해야 함.
만일 속도를 중시한다면 Mecab을 사용.
-참고-
한국어 형태소 분석기 성능 비교 : https://iostream.tistory.com/144
http://www.engear.net/wp/%ED%95%9C%EA%B8%80-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-%EB%B9%84%EA%B5%90/
윈도우10 메캅 설치 :
https://cleancode-ws.tistory.com/97
02) 정제(Cleansing) and 정규화(Normalization)
용도에 맞게 토큰을 분류하는 작업을 토큰화, 토큰화 작업 전, 후에는 텍스트 데이터를 용도에 맞게 정제 및 정규화 하는 일이 항상 함께 함.
정제: 갖고 있는 코퍼스로부터 노이즈를 제거
정규화: 표현 방법이 다르 단어들을 통합시켜 같은 단어로 만들어 줌.
정제 작업은 토큰화에 방해가 되는 부분을 배제하고 토큰화 하기 위해 선행되기도 함. 작업 이후에 남아있는 노이즈들을 제거하기 위해 지속적으로 이뤄짐. 완벽한 정제 작업은 어렵기 때문에 만족할만한 수준이라는 합의점을 찾아야 함.
1. 규칙에 기반한 표기가 다른 단어들의 통합
필요에 따라 직접 코딩을 통해 정의할 수 있는 정규화 규칙의 예로서 같은 의미를 갖고 있어도, 표기가 다르단어들을 하나의 단어로 정규화 하는 방법을 사용
USA, US는 같은 의미를 가지고, uh-huh와 uhhuh는 형태는 다르지만 같은 의미를 갖고 있으므로 하나의 단어로 정규화를 해 줌.
2. 대, 소문자 통합
영어권 언어에선 대, 소문자를 통합하는 것은 단어의 수를 줄일 수 있는 또 다른 정규화 방법. 문장의 맨 앞과 같은 특정한 상황에만 쓰이므로 소문자 변환작업이 이뤄짐. 컴퓨터는 Apple과 apple을 다르다고 인식하므로.
검색 엔진에서 페라리에 관심이 있어 검색한다 생각해보면, 엄밀히 말해서 사용자가 검색을 통해 찾고자 하는 결과는 'Ferrari'이지만, 소문자 변환을 적용했을 것이기 때문에 'ferrari'만 입력해도 원하는 결과를 얻게 됨. 하지만, 미국을 뜻하는 US와 우리를 뜻하는 us는 뜻이 다르고, 회사 이름이나 사람 이름은 대문자로 유지되는 것이 옳으므로 그 뜻에 따라 변환을 해야함... 이래서 어려움. 조건이 많으니까
모든 토큰을 소문자로 만드는 게 문제를 야기한다면, 또 다른 대안은 일부만 소문자로 변환하는 것
문장의 맨 앞에서 나오는 단어의 대문자만 소문자로 바꾸고, 다른 단어들은 대문자로 놔두는 것.
이런 작업은, 더 많은 변수를 사용해서 소문자 변환을 언제 사용할 건지 결정하는 머신러닝 시퀀스 모델로 정확하게 진행시킬 수 있음
만약, 훈련에 사용하는 코퍼스가 사용자들이 단어의 대문자, 소문자의 올바른 사용 방법과 상관 없이 소문자를 사용하는 사람들에게 나온 데이터라면 이 방법 또한 도움이 그다지 안됨.
결국엔 예외 사항을 크게 고려하지 않고 모든 코퍼스를 소문자로 바꾸는 것이 종종 더 실용적임.
3. 불필요한 단어의 제거(Removing Unnecessary Words)
노이즈 데이터는 자연어가 아니면서 아무 의미도 없는 글자들(특수 문자 등)을 의미도 하지만, 목적에 맞지 않는 불필요한 단어들을 뜻하기도 한다.
불필요한 단어 제거 방법은 불용어 제거(불용어 사전을 이용한)와 등장 빈도가 적은 단어, 길이가 짧은 단어들을 제거하는 방법이 존재.
(1) 등장 빈도가 적은 단어
- ex) 스팸 메일 분류기를 설계한다 가정하고, 10만개의 메일 중 정상 메일에선 어떤 것들이, 비정상 메일에선 어떤 것들이 등장하는지를 가지고 설계한다 했을 때, 만약 10만개 메일 중 특정 단어의 빈도가 5번도 안된다면 이 단어는 직관적으로 분류에 별 도움이 되지 않는다는 것을 알게 됨
(2) 길이가 짧은 단어
- 영어권 언어에선 길이 짧은 단어를 삭제하는 것으로도 어느정도 의미없는 단어를 제거하는 효과를 볼 수 있음. 이를 하는 2차적인 이유는, 길이를 조건으로 텍스트를 삭제하면서 구두점들까지도 한 번에 제거하기 위함.
- 영어 단어는 평균 6~7글자, 한국어는 평균 2~3정도로 추정. 따라서 한국어는 짧다고 제거하면 안되는 경우 발생.
- 예를 들어, 한국어로 학교는 두 글자인데, 영어로는 school 6글자. 또, 전설속 동물 용을 예로 들면 한국어는 한 글자이지만, 영어로는 dragon으로 총 6글자.
- 따라서, 영어에선 2~3글자 이하 단어를 제거하는 것만으로도 크게 의미가 없는 단어들을 줄일 수 있는 효과를 가짐. 3글자는 조금 위험할 수도 있음.
길이가 1~2 단어들을 정규표현식을 이용해 삭제
import re
text = 'I was wondering if anyone out there could enlighten me on this car.'
shortword = re.compile(r'\W*\b\w{1,2}\b')
print(shortword.sub('', text))was wondering anyone out there could enlighten this car.compile을 이용해 조건을 설정해주고 sub를 이용해 조건에 해당되는 문자열을 ''으로 변경!
4. 정규 표현식
- 얻어낸 코퍼스의 노이즈 특성을 잡아낼 수 있다면 정규 표현식을 이용해 이를 제거할 수 있는 경우가 많음. 위처럼 길이가 짧은 단어를 제거할 때도 유용하게 사용!!
03) 어간 추출(Stemming) and 표제어 추출(Lemmatization)
정규화 기법 중 코퍼스 내 단어의 개수를 줄일 수 있는 기법.
눈으로 봤을 때는 서로 다른 단어지만, 하나의 단어로 일반화시킬 수 있다면 하나로 일반화 시켜 문서내의 단어 수를 줄여주는 것
이런 방법들은 단어의 빈도수를 기반으로 문제를 풀고자 하는 BoW표현을 사용하는 자연어 처리 문제에서 주로 사용됨.
1. 표제어 추출(Lemmatization)
표제어는 한글로 표제어 또는 기본 사전형 단어 정도의 의미를 가짐. 각 단어들이 다른 형태라도 그 뿌리를 찾아가서 같은지 파악해서 단어의 개수를 줄일 수 있는지 판단! am, are, is는 서로 다른 스펠링이지만 뿌리 단어는 be. 따라서 이 단어들의 표제어는 be!
표제어 추출은 단어의 형태학적 파싱을 먼저 진행. 형태소란 '의미를 가진 가장 작은 단위'를 뜻하고, 형태학 이란, 형태소로부터 단어들을 만들어 가는 학문!
형태소의 두 가지 종료
1) 어간(stem): 단어의 의미를 담고 있는 단어의 핵심 부분
2) 접사(affix): 단어에 추가적인 의미를 주는 부분.
형태학적 파싱은 이 두가지 요소를 분리하는 작업을 말함
NLTK에서는 표제어 추출을 위한 도구인 WordNetLemmatizer를 지원.
import nltk
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
n = WordNetLemmatizer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love',
'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print([n.lemmatize(w) for w in words]) ['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']- 리스트 컴프리헨션을 이용해 리스트를 생성했고 하나의 단어의 표제어를 추출. 어간 추출과는 달리 단어의 형태가 적절하게 보존되어 있음
n.lemmatize('dies', 'v'), n.lemmatize('watched', 'v'), n.lemmatize('has', 'v')('die', 'watch', 'have')- lemmatize는 입력으로 단어의 품사를 알려줄 수 있음. 이 정보를 알려준다면 정확한 Lemma를 추출하게 됨!
- 표제어 추출은 문맥을 고려하며, 수행했을 때 결과는 해당 단어의 품사 정보를 보존(Pos tag를 보존한다고 말할 수 있음)
- 하지만, 어간 추출은 품사 정보가 보존되지 않음(Pos tag 고려 X). 더 정확히, 어간 추출을 한 결과는 사전에 존재하지 않는 단어인 경우가 많음!
2. 어간 추출(Stemming)
- 어간 추출은 형태학적 분석을 단순화한 버전, 정해진 규칙만 보고 단어의 어미를 자르는 어림짐작의 작업. 섬세한 작업이 아니므로 어간 추출 후 나오는 단어는 사전에 존재하지 않을 수 있음
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
s = PorterStemmer()
text="This was not the map we found in Billy Bones's chest, but an accurate copy, complete in all things--names and heights and soundings--with the single exception of the red crosses and the written notes."
words=word_tokenize(text)
print(words)['This', 'was', 'not', 'the', 'map', 'we', 'found', 'in', 'Billy', 'Bones', "'s", 'chest', ',', 'but', 'an', 'accurate', 'copy', ',', 'complete', 'in', 'all', 'things', '--', 'names', 'and', 'heights', 'and', 'soundings', '--', 'with', 'the', 'single', 'exception', 'of', 'the', 'red', 'crosses', 'and', 'the', 'written', 'notes', '.']- nltk의 word_tokenize를 이용해 단어 토큰화!
print([s.stem(w) for w in words])['thi', 'wa', 'not', 'the', 'map', 'we', 'found', 'in', 'billi', 'bone', "'s", 'chest', ',', 'but', 'an', 'accur', 'copi', ',', 'complet', 'in', 'all', 'thing', '--', 'name', 'and', 'height', 'and', 'sound', '--', 'with', 'the', 'singl', 'except', 'of', 'the', 'red', 'cross', 'and', 'the', 'written', 'note', '.']- This -> thi, Was -> wa... 처럼 어간 추출은 단순 규칙에 기반해 이뤄지기 대문에 사전에 존재하지 않는 단어들도 포함
- 포터 알고리즘의 어간 추출은 다음과 같은 규칙을 가짐
- ALIZE -> AL
- ANCE -> 제거
- ICAL -> IC
words = ['formalize', 'allowance', 'electricical']
print([s.stem(w) for w in words])['formal', 'allow', 'electric']- 위의 규칙에 맞게 단어들이 변환 됨
- 포터 스테머의 규칙은 마틴 포터의 홈페이지에 자세하게 설명되어 있음
어간 추출 속도는 표제어 보다 일반적으로 빠름, 포터 추출기는 정밀하게 설계돼 정확도가 높아 영어 자연어 처리에서 어간 추출을 하고자 한다면 good.
NLTK엔 포터 말고도 랭커스터 스태머를 지원. 이 둘을 비교!
from nltk.stem import PorterStemmer
s=PorterStemmer()
words=['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print([s.stem(w) for w in words])['polici', 'do', 'organ', 'have', 'go', 'love', 'live', 'fli', 'die', 'watch', 'ha', 'start']from nltk.stem import LancasterStemmer
l = LancasterStemmer()
print([l.stem(w) for w in words])['policy', 'doing', 'org', 'hav', 'going', 'lov', 'liv', 'fly', 'die', 'watch', 'has', 'start']- 동일한 단어들에 대해서 두 스테머는 다르 결과를 보여줌. 서로 다른 알고리즘을 사용하기 때문에 그럼
- 따라서, 사용하고자 하는 코퍼스에 스테머를 적용해보고 적합한 스테머를 사용해야 함
- 규칙 기반 알고리즘은 종종 제대로 된 일반화를 수행 못 할 수 있음. 어간 추출을 하고 나서, 일반화가 지나치게 되거나, 덜 되거나 하는 경우에 그럼.
- 포터에선 organization을 organ으로 변환. organization과 organ은 전혀 다른 단어임. organ도 어간 추출을 하면 organ. 두 단어에 대해 어간 추출을 한다면 다른 어간임에도 같은 어간을 갖게 됨. 이런 게 규칙기반의 한계
같은 단어에 대해서 표제어 추출과 어간 추출을 했을 때 어떤 차이가 있는지 파악
- Stemming(어간 추출)
: am -> am / the going -> the go / having -> hav - Lemmatization(표제어 추출)
: am -> be / the going -> the going / having -> hav
3. 한국어에서 어간 추출
- 한국어는 5언 9품사의 구조를 가짐
- 체언: 명사, 대명사, 수사
- 수식언: 관형사, 부사
- 관계언: 조사
- 독립언: 감탄사
- 용언: 동사, 형용사 - 용언에 해당되는 '동사'와 '형용사'는 어간(stem)과 어미(ending)의 결합으로 구성!!
(1) 활용(conjugation)
: 용언의 어간이 어미를 가지는 일을 말함
- 어간: 용언(동사, 형용사)을 활용할 때 원칙적으로 모양이 변하지 않는 부분. 활용에서 어미에 선행하는 부분. 때런 어간의 모양도 바뀔 수 있음(예: 긋다, 긋고, 그어서, 그어라)
- 어미(ending): 용언의 어간 뒤에 붙어 활용하면서 변하는 부분, 여러 문법적 기능을 수행
- 활용은 어간이 어미를 취할 때, 어간의 모습이 일정하다면 규칙 활용, 어간이나 어미의 모습이 변하는 불규칙 활용으로 나뉨
(2) 규칙 활용
: 어간이 어미를 취할 때 어간의 모습이 일정.
예를 들면 잡(어간) + 다(어미) = 잡다로 어간이 어미와 붙고 나서도 형태가 유지.
이런 경우엔 규칙 기반으로 단순히 어미를 분리해주면 어간 추출이 됨.
(3) 불규칙 활용
: 어간이 어미를 취할 때 모습이 바뀌거나 취하는 어미가 특수한 경우.
예를들어, '듣-, 돕-, 잇-, 오르-, 노랗-'등이 '듣/들-, 돕/도우-, 곱/고우-, 잇/이-, 올/올-, 노랗/노라-'와 같이 어간의 형식이 달라지거나 '오르+ 아/어 -> 올라, 하 + 아/어 -> 하여, 이르 + 아/어 -> 이르러, 푸르 + 아/어 -> 푸르러'와 같이 일반적 어미가 아닌 특수한 어미를 취하는 경우 불규칙활용에 속함
- 이 경우엔 어간이 어미가 붙는 과정에서 어간의 모습이 바뀌었으므로 단순한 분리만으로 어간 추출이 되지 않고 복잡한 규칙을 필요로 함
참고: https://namu.wiki/w/한국어/불규칙%20활용
04) 불용어(Stopword)
갖고있는 토큰 중 유의미한 토큰만을 선별하려면 큰 의미가 없는 것을 제거해야 함. 의미가 없다는 것은 자주 등장하지만, 분석에 별 도움이 되지 않는 단어를 말함. 예를 들면, I, my, me, over, 조사, 접미사 같은 단어들은 자주 등장하지만 실제 의미 분석엔 별 기여를 못함. 이런 단어들을 불용어(Stopword)라고 하고, NLTK에선 100여개 이상의 불용어를 패키지 내에서 미리 정의하고 있음. 한국어도 불용어 사전이 있음!! 구글에 검색하면 다양한 사람들이 만들어 둔 것이 있으므로 이를 활용
1. NLTK에서 불용어 확인하기
nltk.download('stopwords')
from nltk.corpus import stopwords
stopwords.words('english')[:10]['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]- 리스트 내 앞에 10개만 출력.
2. NLTK를 통해 불용어 제거하기
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example = "Family is not an important thing. It's everything."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example)
result = []
for w in word_tokens:
if w not in stop_words:
result.append(w)
print(word_tokens)
print(result)['Family', 'is', 'not', 'an', 'important', 'thing', '.', 'It', "'s", 'everything', '.']
['Family', 'important', 'thing', '.', 'It', "'s", 'everything', '.']- 토큰화 된 것과 불용어 처리를 한 후를 출력. is, not, an등이 제거 됨!
3. 한국어에서 불용어 제거하기
간단하게는 토큰화 후 조사, 접속사 등을 제거. 하지만, 불용어를 제거하려 하다보면 조사나 접속사와 같은 단어 뿐만 아니라 명사, 형용사와 같은 단어들 중에서 불용어로 제거하고 싶은 단어들이 생기기도 함. 결국엔 사용자가 직접 불용어 사전을 만들게 되는 경우가 많음. 직접 불용어를 정의해보고 문장으로부터 불용어를 제거!
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example = '고기를 아무렇게나 구우려고 하면 안돼. 고기라고 다 같은 게 아니거든. 예컨대 삼겹살을 구울 때는 중요한 게 있지.'
### 그냥 단순하게 불용어로 선정한 것임. 단어 하나하나 ''를 써서 구분해야 하므로 띄어쓰기로 구분해 한 번에 쓰고 split을 이용해서 개별 불용어 리스트를 생성
stop_words = '아무거나 아무렇게나 어찌하든지 같다 비슷하다 예컨대 이럴정도로 하면 아니거든'
stop_words = stop_words.split(' ')
word_tokens = word_tokenize(example)
result = []
for w in word_tokens:
if w not in stop_words:
result.append(w)
### result = [w for w in word_tokens if w not in stop_words] 와 같음
print(word_tokens)
print(result)['고기를', '아무렇게나', '구우려고', '하면', '안돼', '.', '고기라고', '다', '같은', '게', '아니거든', '.', '예컨대', '삼겹살을', '구울', '때는', '중요한', '게', '있지', '.']
['고기를', '구우려고', '안돼', '.', '고기라고', '다', '같은', '게', '.', '삼겹살을', '구울', '때는', '중요한', '게', '있지', '.']05) 정규 표현식(Regular Expression)
1. 정규 표현식 문법과 모듈 함수
- 파이썬에선 모듈 re를 지원하므로, 이를 활용해 특정 규칙이 있는 텍스트를 빠르게 정제할 수 있음.
1) 정규 표현식 문법
- .(온점): 한 개의 임의의 문자를 나타냄. 줄바꿈 문자인\n은 제외
- ?: 앞의 문자가 존재할 수도 있고, 존재하지 않을 수도 있음(문자가 0개 또는 1개)
- : 앞의 문자가 무한개로 존재할 수도 있고, 존재하지 않을 수도 있음(문자가 0개 이상)
- : 앞의 문자가 최소 하나 이상 존재(문자가 1개 이상)
- ^: 뒤의 문자로 문자열이 시작됨. ^a -> a로 시작!
- $: 앞의 문자로 문자열이 끝남.
- {숫자}: 숫자만큼 반복
- {숫자1, 숫자2}: 숫자1 이상 숫자2 이하 만큼 반복. ?, *, +를 대체 가능
- {숫자,}: 숫자 이상만큼 반복
- [ ]: 대괄호 안의 문자들 중 한개 문자와 매치. [amk]라면 a 또는 m 또는 k 중 하나라도 존재하면 매치를 의미. [a-z]처럼 범위를 지정할 수 있음. [a-zA-Z]는 알파벳 전체. 문자열에 알파벳이 존재하면 매치를 의미.
- [^문자]: 해당 문자를 제외한 문자를 매치.
- |: A|B와 같이 쓰이고 A또는 B의 의미를 가짐
- \: 역슬래쉬 문자 자체를 의미
- \d: 모든 숫자를 의미. [0-9]를 의미
- \D: 숫자를 제외한 모든 문자를 의미. [^0-9]와 동일
- \s: 공백을 의미. [ \t\n\r\f\v]와 의미가 동일.
- \S: 공백을 제외한 문자를 의미. [^ \t\n\r\f\v]와 의미가 동일
- \w: 문자 또는 숫자를 의미. [a-zA-Z0-9]와 동일
- \W: 문자 또는 숫자가 아닌 문자를 의미. [^a-zA-Z0-9]
2) 정규표현식 모듈 함수
- re.compile(): 정규표현식을 미리 컴파일 하는 함수. 찾고자 하는 패턴이 빈번하다면 미리 컴파일 해놓고 사용하면 속도와 편의성 면에서 유리
- re.search(): 문자열 전체에 대해 정규표현식과 매치되는지 검색
- re.match(): 문자열의 처음이 정규표현식과 매치되는지를 검색
- re.split(): 정규 표현식을 기준으로 문자열을 분리해 리스트로 리턴
- re.findall(): 문자열에서 정규 표현식과 매치되는 모든 경우의 문자열을 찾아 리스트로 맅턴. 매치되는 문자열이 없다면 빈 리스트를 리턴!
- re.finditer(): 정규 표현식과 매치되는 모든 경우의 문자열에 대한 이터레이터 객체를 리턴. enumerate(re.findall())과 같은 의미인 듯.
- re.sub(): 문자열에서 정규 표현식과 일치하는 부분에 대해서 다른문자열로 대체
2.정규 표현식 실습
1) . 기호
예를 들어서 정규 표현식이 'a.c'라면 a와 c 사이에 어떤 1개의 문자라도 올 수 있음. 즉, akc, apc, asc와 같은 형태는 모두 a.c와 매치 됨.
import re
r = re.compile('a.c')
r.search('kkk')- 해당되는 문자가 없으므로 아무런 결과도 출력 x
r.search('abc')<re.Match object; span=(0, 3), match='abc'>search의 입력인 abc에 정규 표현식 패턴이 존재하는지 확인하는 코드.
abc라는 문자열은 'a.c'에 해당되는 것을 알 수 있음.
2) ? 기호
?는 앞의 문자가 존재할 수도 있고, 안 할수도 있음. ab?c라면 b는 있다고 취급 혹은 없다고 취급 가능. 즉 abc와 ac모두 매치 가능
import re
r = re.compile('ab?c')
r.search('abbc')아무런 결과 출력이 안됨. ?는 b가 0개 또는 1개인 경우엔 매치지만, 이 경우엔 2개가 있으므로 매치 X
r.search('abc')<re.Match object; span=(0, 3), match='abc'>b가 한개 있으므로 abc를 매치
r.search('ac')<re.Match object; span=(0, 2), match='ac'>b가 한개도 없으므로 ac를 매치
3) *기호
은 바로 앞의 문자가 0개 이상인 경우를 나타냄. 앞의 문자는 존재하지 않을 수도 있고 여러 개일 수도 있음. 정규표현식이 ab*c라면 ac, abc, abbc, abbbc 등과 매치할 수 있고 갯수가 무수히 많아도 매치 가능
import re
r = re.compile('ab*c')
r.search('a')'a'는 패턴과 매치되지 않으므로 아무런 결과가 없음
r.search('ac')<re.Match object; span=(0, 2), match='ac'>ac 사이에 비가 하나도 없으므로 매치
r.search('abc')<re.Match object; span=(0, 3), match='abc'>ac 사이에 b가 있으므로 매치
r.search('abbbbbbbbbc')<re.Match object; span=(0, 11), match='abbbbbbbbbc'>a와 c 사이에 b가 9개 있으므로 매치
4) + 기호
+는 *와 유사함. 하지만 앞의 문자가 최소 1개 이상이어야 매치가 됨. 'ab+c'라면 'ac'는 매치되지 않음.
r = re.compile('ab+c')
r.search('ac')a c사이에 b가 하나도 없어서 매치되지 않음
r.search('abc')<re.Match object; span=(0, 3), match='abc'>ac 사이에 b가 하나 있으므로 매치
r.search('abbbbbc')<re.Match object; span=(0, 7), match='abbbbbc'>ac사이에 b가 5개 있으므로 매치
5) ^ 기호
^는 시작되는 글자를 지정. '^a'라면 a로 시작되는 문자열만을 찾아냄
r = re.compile('^a')
r.search('bbc')a로 시작하는 문자열이 아니므로 아무것도 반환 안함
r.search('ab')<re.Match object; span=(0, 1), match='a'>a로 시작해서 매치.
6) {숫자} 기호
문자에 해당 기호를 붙이면 해당 문자를 숫자만큼 반복한 것을 나타냄.
예를 들어, 'ab{2}c'라면 a와 c사이에 b가 존재하고 2개인 문자열에 대해 매치
r = re.compile('ab{2}c')
r.search('ac')
r.search('abc')abc엔 b가 하나 있지만 두개가 아니므로 아무것도 return X
r.search('cabbc')<re.Match object; span=(0, 4), match='abbc'>match엔 정규표현식이 들어있음. cabbc엔 a와 c사이에 b가 두 개 들어있으므로 match!
r.search('abbbbbbbbc')a와 c사이 b의 개수가 2개가 아니므로 아무것도 출력 X
7) {숫자1, 숫자2} 기호
문자에 해당 기호를 붙이면, 해당 문자를 숫자1 이상 숫자2 이하만큼 반복
ex) ab{2,8}c라면 a와 c사이에 b가 존재하면서 b가 2~8이하인 문자열이 매치 됨
import re
r = re.compile('ab{2,8}c')
r.search('ac')
r.search('abc')ac 사이에 b가 없거나 1개 있으므로 아무런 결과가 출력되지 않는다.
r.search('abbc')<re.Match object; span=(0, 4), match='abbc'>a와 c사이에 b가 두 개 있으므로 매치됨
8) {숫자,} 기호
문자에 해당 기호를 붙이면 해당 문자를 숫자 이상만큼 반복함.
ex) a{2,}bc라면 뒤에 bc가 붙으면서 a가 2개 이상인 경우의 문자열과 매칭 됨.
{0,}을 쓴다면 *와 동일, {1,}을 쓴다면 +와 동일.
그리고 이런 기호들은 바로 앞에 있는 문자열 하나에 대해 적용되는 것임!!
import re
r = re.compile('a{2,}bc')
r.search('bc')
r.search('abcc')
r.search('aabc')<re.Match object; span=(0, 4), match='aabc'>bc는 앞에 a가 없고, abcc는 bc 앞에 a가 하나 뿐이라 출력 결과가 없고, aabc가 해당 조건에 부합하므로 결과물이 존재!
r.search('aaaaaaabc')<re.Match object; span=(0, 9), match='aaaaaaabc'>bc 앞에 a가 두 개 이상 있으므로 매치!
9) [ ] 기호
[ ] 안에 문자열을 넣으면 그 문자들 중 한 개와 매치라는 의미를 가짐.
[abc]라면 a또는 b또는 c가 들어있는 문자열과 매치. [a-zA-Z]나 [0-9] 처럼 범위 지정도 가능
r = re.compile('[abc]')
r.search('zzz')
r.search('a')<re.Match object; span=(0, 1), match='a'>zzz는 아무런 abc 중 하나도 없으므로 매칭이 안됨.
r.search('apoppkokpokpokpkkplkplkoklk')<re.Match object; span=(0, 1), match='a'>a가 있기 때문에 매칭!
r.search('bac')<re.Match object; span=(0, 1), match='b'>가장 맨 앞에 오는 b가 매칭 되었음.
r = re.compile('[a-z]')
r.search('AAA')소문자에 대해서 표현식을 지정했기 때문에 AAA는 대문자만 있어 아무 매칭 X
r.search('aBC')<re.Match object; span=(0, 1), match='a'>a로 시작하므로 매칭!
r.search('111')영어 소문자가 없으므로 아무 매칭 X
10) [^문자] 기호
5)에서의 ^와 다른 의미. ^기호 뒤에 붙은 문자들을 제외한 모든 문자를 매칭.
ex) [^abc]라면 a또는 b또는 c를 제외한 모든 문자와 매칭
r = re.compile('[^abc]')
r.search('a')
r.search('ab')
r.search('b')abc 중 하나가 들어있으므로 아무런 결과가 출력되지 않음!
r.search('d')<re.Match object; span=(0, 1), match='d'>abc 중 하나에 해당되지 않으므로 매칭!
r.search('znjbha')<re.Match object; span=(0, 1), match='z'>맨 뒤에 a를 제외하고 매칭되는 것!
3. 정규 표현식 모듈 함수 예제
(1) re.match() vs re.search()
- search()는 정규 표현식 전체에 대해 문자열이 매치하는지를 봄
- match()는 문자열의 첫 부분부터 매치하는지 확인
- 중간에 찾는 패턴이 있다해도 match는 문자열 시작부터 일치하지 않으면 찾지 않음!!
r = re.compile('ab.')
r.search('kkkabc')<re.Match object; span=(3, 6), match='abc'>ab.은 ab 뒤에 문자열 하나 오는 것. ab뒤에 c 오므로 매칭
r.match('kkkabc')ab.가 해당되지만 문자열 시작이 아니므로 결과 출력 X
r.match('abckkk')<re.Match object; span=(0, 3), match='abc'>abc로 시작하므로 매칭! 즉, 문자열 맨 처음에 대해 표현식에 해당되는 부분을 찾고 싶은거면 match를 쓰고 전체를 돌면서 찾는거면 search. search는 끝까지 다 도는 것이라 만약 앞으로 시작하는게 중요한 거라면 search를 쓰면 효율성이 떨어지는 것!
(2) re.split()
split()은 정규표현식 기준으로 문자열들을 분리해 리스트로 리턴. 토큰화에 상당히 유용하게 사용됨!
text = '사과 딸기 수박 메론 바나나'
re.split(" ", text)['사과', '딸기', '수박', '메론', '바나나']null space가 정규 표현식이고 이걸 기준으로 split! 근데 이건 text.split(' ')와 다를 게 없음
text = '''사과
딸기
수박
메론
바나나'''
re.split('\n', text)['사과', '딸기', '수박', '메론', '바나나']\n 즉, 엔터를 기준으로 문자열을 분리. 이것도 text.split('\n')과 같은 것
text = '사과+딸기+수박+메론+바나나'
re.split('+', text)이렇게 입력하면 정규표현식 +는 앞의 문자열이 하나 이상 반복되는 경우를 매치하는데 + 앞에 아무것도 없으므로 오류가 발생.
re.split('\+', text)['사과', '딸기', '수박', '메론', '바나나']\를 붙여줘서 정규표현식이 아니라 기호로 인식하게 해줘야 함. '도 문자열 구분이 아니라 그냥 문자로 인식시키고 싶을 때 \'로 표현하기도 함. 특수문자들을 기호로 인식시키고 싶을 때 \를 씀
위의 결과는 text.split('+') 와 똑같음
(3) re.findall()
findall()은 정규 표현식과 매치되는 모든 문자열을 리스트로 반환하고, 매치되는 문자열이 없다면 빈 리스트를 반환한다.
text = '''이름 : 김철수
전화번호 : 010 - 1234 - 5678
나이 : 30
성별 : 남'''
re.findall('\d+', text)['010', '1234', '5678', '30']정규표현식을 \d+는 숫자 중 길이가 1 이상이 모든 문자열에 대해 매칭됨. 만약 \d였다면 0, 1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 3, 0을 리턴. 아주 유용한 표현식!
re.findall('\d+', '문자열입니다')[]문자열입니다엔 숫자가 존재하지 않으므로 빈 리스트를 반환
(4) re.sub()
sub() 함수는 정규 표현식 패턴과 일치하는 문자열을 찾아 다르문자열로 대체
text="Regular expression : A regular expression, regex or regexp[1] (sometimes called a rational expression)[2][3] is, in theoretical computer science and formal language theory, a sequence of characters that define a search pattern."
re.sub('[^a-zA-Z]',' ',text)'Regular expression A regular expression regex or regexp sometimes called a rational expression is in theoretical computer science and formal language theory a sequence of characters that define a search pattern' a-zA-Z가 아닌 것 즉 영어 대소문자가 아닌 모든 것은 null space로 대체!!따라서 :도 사라지고 [1], [2], [3]와 구문자도 다 사라짐!!
str의 replace와 같은 기능을 한다 생각!!
5. 정규 표현식 텍스트 전처리 예제
text = '''100 John PROF
101 James STUD
102 Mac STUD'''
re.split('\s+', text)['100', 'John', 'PROF', '101', 'James', 'STUD', '102', 'Mac', 'STUD']\s는 공백을 의미. +를 붙여서 최소 한 개 이상의 공백을 찾겠다는 것. 만약 \s면 이름과 신분 구분 사이에 tab이 있으므로 tab은 4칸의 null space이므로 null space도 같이 나오게 됨
re.findall('\d+', text)['100', '101', '102']\d+를 해줘 1자리 이상의 모든 숫자를 매치. 만약 \d라면 1, 0, 0,... 이런식으로 하나씩만 매치!
re.findall('[A-Z]', text)['J', 'P', 'R', 'O', 'F', 'J', 'S', 'T', 'U', 'D', 'M', 'S', 'T', 'U', 'D']대문자 A-Z에 대해서만 매칭. 하지만 이는 우리가 원하는 결과가 아님. PROF, STUD이런 식을 원하는 것
re.findall('[A-Z]+', text)['J', 'PROF', 'J', 'STUD', 'M', 'STUD']PROF, STUD를 가져오긴 하는데 +를 해주면 1이상인 것들을 모두 return 하는 것이므로 이름도 대문자로 시작하니까 원하는 결과는 아님!!
re.findall('[A-Z]{4}', text)['PROF', 'STUD', 'STUD']{4}를 이용해서 4자리의 대문자를 매칭!! 원하는 결과를 리턴!!
이름의 경우엔, 대문자와 소문자가 섞여있는 상황. 이름에 대해 가져오고 싶다면 처음에 대문자가 등장하고, 뒤에 소문자 여러개가 등장하므로 이에 맞는 표현식을 써야함!
re.findall('[A-Za-z]', text)['J',
'o',
'h',
'n',
'P',
'R',
'O',
'F',
'J',
'a',
'm',
'e',
's',
'S',
'T',
'U',
'D',
'M',
'a',
'c',
'S',
'T',
'U',
'D']이 패턴은 A-Z 혹은 a-z인 단어 하나를 매칭하는 것!! 잘못된 결과를 가져옴
re.findall('[A-Z][a-z]+', text)['John', 'James', 'Mac'][]를 두개 써서 두 문자열로 이뤄진이라는 조건을 준 것!! [a-z]에 +를 해서 소문자가 하나 이상 나오는 문자열을 매치!! 이름에 보면 소문자의 수가 3개, 4개, 2개로 들쑥날쑥 하므로!!
6. 정규 표현식을 이용한 토큰화
NLTK에선 RegexpTokenizer를 지원. 괄호 안에 원하는 표현식을 넣어 토큰화를 수행!!
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('[\w]+')
print(tokenizer.tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphange is as cheery as cheery goes for a pastry shop"))['Don', 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'Mr', 'Jone', 's', 'Orphange', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']\w는 문자 또는 숫자가 1개를 뜻하고, +를 넣어 1개 이상인 모든 경우를 매칭!! 따라서 문자와 숫자를 제외한 모든 다른 문자열에서 split이 일어남!
RegexpTokenizer의 parameter로 gaps가 있는데 이걸 True로 준다면 토큰화의 결과는 공백만 나옴! 원래는 False가 공백만 나왔는데 바뀜. default도 False!
06) 정수 인코딩(Integer Encoding)
컴퓨터는 텍스트보다 숫자를 더 잘 처리. 이를 위해 자연어를 텍스트를 숫자로 바꾸는 방법이 여러가지 있음. 이걸 적용하기 위한 첫 단계로 각 단어를 "고유한" 정수에 매핑시키는 작업이 필요!!
1. 정수 인코딩
단어에 정수를 부여하는 방법으로 빈도수 순으로 정렬한 단어 집합을 만들고, 빈도수가 높은 순서대로 차례로 낮은 숫자부터 정수를 부여.
이 방법의 문제는 만약, 단어가 5000개라서 0에서 4999까지의 정수가 매칭된다면 1과 4999는 4999배 차이로 인식을 함. 이게 맞는것? 아무튼 일단 진행.
1) dictionary 사용하기
from nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
text = "A barber is a person. a barber is good person. a barber is huge person. he Knew A Secret! The Secret He Kept is huge secret. Huge secret. His barber kept his word. a barber kept his word. His barber kept his secret. But keeping and keeping such a huge secret to himself was driving the barber crazy. the barber went up a huge mountain."여러 문장이 있는 텍스트로부터 문장 토큰화 수행
nltk.download('punkt')
text = sent_tokenize(text)
print(text)['A barber is a person.', 'a barber is good person.', 'a barber is huge person.', 'he Knew A Secret!', 'The Secret He Kept is huge secret.', 'Huge secret.', 'His barber kept his word.', 'a barber kept his word.', 'His barber kept his secret.', 'But keeping and keeping such a huge secret to himself was driving the barber crazy.', 'the barber went up a huge mountain.']문장 단위로 토큰화가 이뤄짐! 정제 작업을 병행하며 단어 토큰화 수행!
# 정제와 단어 토큰화
nltk.download('stopwords')
vocab = {}
sentences = []
stop_words = set(stopwords.words('english'))
for i in text:
sentence = word_tokenize(i) # 단어 토큰화
result = []
for word in sentence:
word = word.lower() # 모든 단어를 소문자화
if word not in stop_words: # 단어 토큰화 된 결과에 대해서 불용어를 제거
if len(word) > 2: # 단어 길이가 2이하인 경우에 대하여 추가로 단어를 제거
result.append(word)
if word not in vocab:
vocab[word] = 0
vocab[word] += 1
sentences.append(result)
print(sentences)[['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]각 문장별로 토큰화와 정제가 병행된 것!
print(vocab){'barber': 8, 'person': 3, 'good': 1, 'huge': 5, 'knew': 1, 'secret': 6, 'kept': 4, 'word': 2, 'keeping': 2, 'driving': 1, 'crazy': 1, 'went': 1, 'mountain': 1}vocab엔 각 단어의 빈도수가 기록!
vocab_sorted = sorted(vocab.items(), key = lambda x: x[1], reverse = True)
vocab_sorted[('barber', 8),
('secret', 6),
('huge', 5),
('kept', 4),
('person', 3),
('word', 2),
('keeping', 2),
('good', 1),
('knew', 1),
('driving', 1),
('crazy', 1),
('went', 1),
('mountain', 1)]dictonary.items()는 키와 밸류를 한 쌍으로 tuple로 묶어 return 해줌.
sorted를 이용해 정렬이 되고, key에 labda x: x[1]을 주어 1번쨰에 위치한 values를 기준으로 정렬. 또한, sorted의 default는 내오름차순 이므로, reverse = True를 주어 내림차순으로 정렬!
word_to_index = {}
i = 0
for (word, frequency) in vocab_sorted:
if frequency > 1:
i += 1
word_to_index[word] = i
print(word_to_index){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7}빈도수가 1 이하인 것은 제외했고 이미 빈도수 높은 순서대로 정렬되어 있으므로 높은 순으로 1부터 부여!
자연어 처리를 하다보면 텍스트 내 모든 단어를 쓰기보단, 빈도수가 가장 높은 n개만 사용하고 싶은 경우가 많다고 한다. 상위 n개만 쓰고 싶다면 vocab에서 정수값이 1부터 n까지인 단어만 쓰면 됨
# 상위 5개만 사용
n = 5
words_frequency = [w for w, c in word_to_index.items() if c >= n + 1] # 인덱스 5초과 제외
for w in words_frequency:
del word_to_index[w]
print(word_to_index){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5}del을 이용해서 5 초과하는 인덱스는 삭제!
이제 각 단어를 인덱스로 바꾸는 작업! ['barber', 'good', 'person']과 같이 인덱스가 존재하지 않는 'good'같은 경우가 있다. 이처럼 존재하지 않는 단어들을 Out-Of_Vocabulary라 하고 'OOV'라 함. word_to_index에 'OOV'를 추가하고 집합에 없는 단어들은 'OOV'의 인덱스로 코딩!
word_to_index['OOV'] = len(word_to_index) + 1encoded = []
for s in sentences:
temp = []
for w in s:
try:
temp.append(word_to_index[w])
except KeyError:
temp.append(word_to_index['OOV'])
encoded.append(temp)
print(encoded)[[1, 5], [1, 6, 5], [1, 3, 5], [6, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [6, 6, 3, 2, 6, 1, 6], [1, 6, 3, 6]]senetences를 반복하면서, w는 각 sentences의 단어를 뜻함. word_to_index[w]를 해서 w의 인덱스를 temp에 담아줌. 근데 OOV에 해당되는 단어들은 word_to_index에 존재하지 않으므로 key Error가 발생하게 됨.
try~except~를 이용해서 keyError가 발생하면 'OOV'의 인덱스를 넣는 예외 처리를 해줬음!
그 결과, 단어들이 정수로 인코딩 된 것을 알 수 있음!(빈도수 기준으로)
이것은 기본 원리이고, 더 쉬운 Counter, FreqDist, enumerte 또는 케라스의 토크나이저를 이용!
2) Counter 사용
from collections import Counter
# sentences엔 단어 토큰화 결과가 저장. 단어 집합을 만들기 위해
# 문장 경계를 제거하고 단어들을 하나의 리스트로 만들어 줌!
print(sentences)
## np.hstack(sentences)와 동일
words = sum(sentences, [])
print(words)[['barber', 'person'], ['barber', 'good', 'person'], ['barber', 'huge', 'person'], ['knew', 'secret'], ['secret', 'kept', 'huge', 'secret'], ['huge', 'secret'], ['barber', 'kept', 'word'], ['barber', 'kept', 'word'], ['barber', 'kept', 'secret'], ['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'], ['barber', 'went', 'huge', 'mountain']]
['barber', 'person', 'barber', 'good', 'person', 'barber', 'huge', 'person', 'knew', 'secret', 'secret', 'kept', 'huge', 'secret', 'huge', 'secret', 'barber', 'kept', 'word', 'barber', 'kept', 'word', 'barber', 'kept', 'secret', 'keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy', 'barber', 'went', 'huge', 'mountain']vocab = Counter(words)
print(vocab)Counter({'barber': 8, 'secret': 6, 'huge': 5, 'kept': 4, 'person': 3, 'word': 2, 'keeping': 2, 'good': 1, 'knew': 1, 'driving': 1, 'crazy': 1, 'went': 1, 'mountain': 1})단어를 key로, 빈도수를 value로 저장되어 있음.
most_common()은 주어진 수 만큼의 상위 빈도 단어만을 리턴.
n = 5
vocab = vocab.most_common(n)
vocab[('barber', 8), ('secret', 6), ('huge', 5), ('kept', 4), ('person', 3)]이 기능은 collections의 Counter를 통해 생성된 dict에 대해서만 적용. 단순 dict엔 적용 안됨.
word_to_index = {}
i = 0
for (word, frequency) in vocab:
i += 1
word_to_index[word] = i
print(word_to_index){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5}정수를 인코딩해준 결과. 맨 처음 일일히 구현한 것 보다 훨씬 간단.
3) NLTK의 FreqDist 사용
collections의 Counter와 같은 방법으로 사용 가능
from nltk import FreqDist
import numpy as np
vocab = FreqDist(np.hstack(sentences))
print(vocab['barber'])8barber의 빈도는 총 8. most_common 다시 사용
n = 5
vocab = vocab.most_common(n)
vocab[('barber', 8), ('secret', 6), ('huge', 5), ('kept', 4), ('person', 3)]리스트 안에 각 원소와 빈도를 쌍으로 갖는 튜플이 원소로 들어있음!
앞에서 했던 i += 1로 인덱스를 부여하기 보단 smart하게 해보자.
word_to_index = {word[0]: index + 1 for index, word in enumerate(vocab)}
print(word_to_index){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5}vocab엔 단어와 빈도수가 쌍으로 들어있기 때문에 word[0]을 해준 것.
enumerate에 대해 간단히 설명하자면, iterable한 리스트, 튜플 등등 다양한 객체가 있다고 치면, 그 원소가 들어있는 순서대로 인덱스가 존재할 것이다. set은 제외. 예를들면 ['a', 'c', 'b']라는 객체가 주어진다면 a는 0번째, c는 1번째, b는 2번째의 원소! 이런 숨겨진 인덱스를 함께 생성해 iter 객체가 되는 것이 enumerate.
zip(range(len(list)), list)와 동일한 결과임. 각 원소가 들어있는 순서를 함께 리턴해주는 것이라 생각!! 생각보다 유용하게 많이 쓰임.
2. 케라스(Keras)의 텍스트 전처리
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
print(tokenizer.word_index){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7, 'good': 8, 'knew': 9, 'driving': 10, 'crazy': 11, 'went': 12, 'mountain': 13}fit_on_texts를 통해 코퍼스에 대해 fitting을 함. word_index엔 word의 빈도수 높은 순으로 인덱스가 부여되어 있음!
print(tokenizer.word_counts)OrderedDict([('barber', 8), ('person', 3), ('good', 1), ('huge', 5), ('knew', 1), ('secret', 6), ('kept', 4), ('word', 2), ('keeping', 2), ('driving', 1), ('crazy', 1), ('went', 1), ('mountain', 1)])dictionary나 set이나 입력받은 순서대로 쌓이지 않아 입력 순서를 보장하지 않는단 단점이 있음. OrderDict는 입력받은 순서를 보장해준다. OrderDict 아주 유용.
print(tokenizer.texts_to_sequences(sentences))[[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [7, 7, 3, 2, 10, 1, 11], [1, 12, 3, 13]]앞서 빈도수 높은 n개의 단어만 사용하기 위해 most_common()을 썻음. 케라스 토크나이저는 num_words를 인자로 줘 상위 몇개의 단어만 쓰겠다고 지정 가능.
n = 5
## n+1을 하는 이유는 range(n)과 같은 의미라서 그럼. 0~n-1을 포함하게 됨
## 따라서 1 ~ n-1을 출력.
## 존재하지 않는 단어에 대해선 제로 패딩을 해주므로 0도 의미가 있다고 인식하므로
## n+1을 해줌. 여기선 0가 존재하지 않으므로 0~n+1로 인식시켜도 상관 없음
tokenizer = Tokenizer(num_words = n + 1)
tokenizer.fit_on_texts(sentences)
print(tokenizer.word_index)
print(tokenizer.word_counts)
print(tokenizer.texts_to_sequences(sentences)){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5, 'word': 6, 'keeping': 7, 'good': 8, 'knew': 9, 'driving': 10, 'crazy': 11, 'went': 12, 'mountain': 13}
OrderedDict([('barber', 8), ('person', 3), ('good', 1), ('huge', 5), ('knew', 1), ('secret', 6), ('kept', 4), ('word', 2), ('keeping', 2), ('driving', 1), ('crazy', 1), ('went', 1), ('mountain', 1)])
[[1, 5], [1, 5], [1, 3, 5], [2], [2, 4, 3, 2], [3, 2], [1, 4], [1, 4], [1, 4, 2], [3, 2, 1], [1, 3]]index, counts엔 모든 index가 표현이 된다. 하지만 texts_to_sequences를 할 때 적용이 됨!!
상위 5개만을 사용한다 했으므로 그를 제외한 나머지 단어들은 제거가 되었다. 만약 이걸 남기고 싶다면 아래와 같은 방법을 사용하길
tokenizer = Tokenizer() # n을 지정 안함
tokenizer.fit_on_texts(sentences)
n = 5
words_frequency = [w for w, c in tokenizer.word_index.items() if c >= n + 1]
for w in words_frequency:
del tokenizer.word_index[w]
del tokenizer.word_counts[w]
print(tokenizer.word_index)
print(tokenizer.word_counts)
print(tokenizer.texts_to_sequences(sentences)){'barber': 1, 'secret': 2, 'huge': 3, 'kept': 4, 'person': 5}
OrderedDict([('barber', 8), ('person', 3), ('huge', 5), ('secret', 6), ('kept', 4)])
[[1, 5], [1, 5], [1, 3, 5], [2], [2, 4, 3, 2], [3, 2], [1, 4], [1, 4], [1, 4, 2], [3, 2, 1], [1, 3]]위와 결과는 같음. 케라스의 tokenizer는 OOV를 제거하는 특징이 있지만 이를 보존하기 위해선 oov_token을 이용
n = 5
tokenizer = Tokenizer(num_words = n + 2, oov_token = 'OOV')
tokenizer.fit_on_texts(sentences)
print('단어 OOV의 인덱스: {}'.format(tokenizer.word_index['OOV']))단어 OOV의 인덱스: 1OOV도 넣었으므로 n+2를 해주고, oov에 대해선 'OOV'로 표시하게 해둠.
print(tokenizer.texts_to_sequences(sentences))[[2, 6], [2, 1, 6], [2, 4, 6], [1, 3], [3, 5, 4, 3], [4, 3], [2, 5, 1], [2, 5, 1], [2, 5, 3], [1, 1, 4, 3, 1, 2, 1], [2, 1, 4, 1]]OOV에 대해서도 정수 라벨링이 되어있는 것을 알 수 있음!
07) 패딩(Padding)
각 문장은 서로 길이가 다른 경우가 많음. 기계는 길이가 전부 동일한 문서들에 대해 하나의 행렬로 보고 묶어서 처리 가능. 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 것이 필요할 때가 있고, 이를 패딩이라 함.
1. Numpy로 패딩
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
encoded = tokenizer.texts_to_sequences(sentences)
print(encoded)[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [7, 7, 3, 2, 10, 1, 11], [1, 12, 3, 13]]모든 단어가 고유한 인덱스로 바뀐 것을 알 수 있음. 하지만 각 문장의 길이가 다 제각각. 이를 맞춰주겠음
max_len = max(len(item) for item in encoded)
print(max_len)7가장 단어의 수가 많은 문장은 7개 임을 알 수 있음. 모든 문장을 이 7을 기준으로 맞추고 제로 패딩을 해줌
for item in encoded:
## item의 길이가 같아질 때 까지 0 append
while len(item) < max_len:
item.append(0)
padded_np = np.array(encoded)
padded_nparray([[ 1, 5, 0, 0, 0, 0, 0],
[ 1, 8, 5, 0, 0, 0, 0],
[ 1, 3, 5, 0, 0, 0, 0],
[ 9, 2, 0, 0, 0, 0, 0],
[ 2, 4, 3, 2, 0, 0, 0],
[ 3, 2, 0, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 2, 0, 0, 0, 0],
[ 7, 7, 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 0, 0, 0]])2. Keras 전처리 도구로 패딩하기
케라스에선 pad_sequences()를 제공
from tensorflow.keras.preprocessing.sequence import pad_sequences
encoded = tokenizer.texts_to_sequences(sentences)
print(encoded)
padded = pad_sequences(encoded)
padded[[1, 5], [1, 8, 5], [1, 3, 5], [9, 2], [2, 4, 3, 2], [3, 2], [1, 4, 6], [1, 4, 6], [1, 4, 2], [7, 7, 3, 2, 10, 1, 11], [1, 12, 3, 13]]
array([[ 0, 0, 0, 0, 0, 1, 5],
[ 0, 0, 0, 0, 1, 8, 5],
[ 0, 0, 0, 0, 1, 3, 5],
[ 0, 0, 0, 0, 0, 9, 2],
[ 0, 0, 0, 2, 4, 3, 2],
[ 0, 0, 0, 0, 0, 3, 2],
[ 0, 0, 0, 0, 1, 4, 6],
[ 0, 0, 0, 0, 1, 4, 6],
[ 0, 0, 0, 0, 1, 4, 2],
[ 7, 7, 3, 2, 10, 1, 11],
[ 0, 0, 0, 1, 12, 3, 13]], dtype=int32)제로 패딩이 훨씬 간결하게 잘 되었음. numpy로 채웠을 때와는 결과가 다르다. 왜냐면 원래 있던 단어들 뒤로 0을 append 했기 때문.
pad_sequences의 default는 padding = 'pre'임. 이를 바꿔줄 거면 post로 주면 됨.
padded = pad_sequences(encoded, padding = 'post')
paddedarray([[ 1, 5, 0, 0, 0, 0, 0],
[ 1, 8, 5, 0, 0, 0, 0],
[ 1, 3, 5, 0, 0, 0, 0],
[ 9, 2, 0, 0, 0, 0, 0],
[ 2, 4, 3, 2, 0, 0, 0],
[ 3, 2, 0, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 6, 0, 0, 0, 0],
[ 1, 4, 2, 0, 0, 0, 0],
[ 7, 7, 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 0, 0, 0]], dtype=int32)numpy를 이용한 것과 똑같음. 실제로 동일한지 확인
(padded == padded_np).all()Truepadded == padded_np는 모든 원소에 대해 동일한 위치의 원소끼리 같은지를 비교. .all()을 해서 모두 같으면 True를 리턴
패딩 시에 꼭 가장 긴 문서의 길이로 패딩할 필요는 없음. 평균 20정도의 길이인데 어떤 하나가 5000의 길이를 갖는다면 이렇게 하면 불필요. max_len 인자를 줘 사이즈를 조절할 수 있음
padded = pad_sequences(encoded, padding = 'post', maxlen = 5)
paddedarray([[ 1, 5, 0, 0, 0],
[ 1, 8, 5, 0, 0],
[ 1, 3, 5, 0, 0],
[ 9, 2, 0, 0, 0],
[ 2, 4, 3, 2, 0],
[ 3, 2, 0, 0, 0],
[ 1, 4, 6, 0, 0],
[ 1, 4, 6, 0, 0],
[ 1, 4, 2, 0, 0],
[ 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 0]], dtype=int32)길이가 5보다 짧은 문서들은 0로 패딩, 긴 문서들은 손실이 됨. 길이가 7인 문장에 대해선 앞에 두 개가 잘림. 이건 post든, pre든 같은 결과를 리턴.
만약, 0 말고 다른 숫자로 패딩하고 싶다면 value를 지정해주면 됨.
last_value = len(tokenizer.word_index)+1
padded = pad_sequences(encoded, padding = 'post', value = last_value)
paddedarray([[ 1, 5, 14, 14, 14, 14, 14],
[ 1, 8, 5, 14, 14, 14, 14],
[ 1, 3, 5, 14, 14, 14, 14],
[ 9, 2, 14, 14, 14, 14, 14],
[ 2, 4, 3, 2, 14, 14, 14],
[ 3, 2, 14, 14, 14, 14, 14],
[ 1, 4, 6, 14, 14, 14, 14],
[ 1, 4, 6, 14, 14, 14, 14],
[ 1, 4, 2, 14, 14, 14, 14],
[ 7, 7, 3, 2, 10, 1, 11],
[ 1, 12, 3, 13, 14, 14, 14]], dtype=int32)제로 패딩 대신 가장 마지막 인덱스 + 1인 14로 채워짐!
08) 원-핫 인코딩(One-Hot Encoding)
1. 원-핫 인코딩이란?
단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1을 부여하고, 나머지엔 0을 부여하는 벡터 표현 방식.
(1) 각 단어에 고유한 인덱스를 부여(정수 인코딩)
(2) 표현하고 싶은 단어 인덱스에 1을 부여하고, 다른 단어의 인덱스는 0을 부여
from konlpy.tag import Okt
okt = Okt()
token = okt.morphs('나는 자연어 처리를 배운다')
print(token)['나', '는', '자연어', '처리', '를', '배운다']Okt 형태소 분석기를 사용해서 형태소 단위 토큰화를 했음
word2index = {}
for voca in token:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
print(word2index){'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5}각 토큰에 대해 고유한 인덱스를 붙여 줌. 리스트의 순서대로.
def one_hot_encoding(word, word2index):
## word2index 길이만큼 0 리스트 생성
one_hot_vector = [0] * (len(word2index))
## 대상 단어의 인덱스 추출
index = word2index[word]
## 그 단어의 인덱스만 1로
one_hot_vector[index] = 1
return one_hot_vector
one_hot_encoding('자연어', word2index)[0, 0, 1, 0, 0, 0]자연어가 가지는 인덱스 2를 제외한 나머지는 다 0으로. 이 벡터를 리턴!
2. 케라스를 이용한 원-핫 인코딩
위의 방법은 어떤 로직인지 파악하기 위해 한 것이고, 실제로 저렇게 하면 비효율적.
to_categorical()을 이용해 편하게 해보자.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
text = '나랑 점심 먹으러 갈래 점심 메뉴는 햄버거 갈래 갈래 햄버거 최고야'
t = Tokenizer()
t.fit_on_texts([text])
print(t.word_index){'갈래': 1, '점심': 2, '햄버거': 3, '나랑': 4, '먹으러': 5, '메뉴는': 6, '최고야': 7}위와같이 생성된 단어 집합 내에 있는 단어들로만 구성된 텍스트가 있다면 text_to_sequences()를 통해 정수 시퀀스로 변환 가능. 생성된 단어 집합 내 일부로만 sub_text를 만들어 봄.
sub_text = '점심 먹으러 갈래 메뉴는 햄버거 최고야'
encoded = t.texts_to_sequences([sub_text])
print(encoded)
[[2, 5, 1, 6, 3, 7]]
이 결과를 가지고 원 핫 인코딩을 진행!
```py
one_hot = to_categorical(encoded[0])
print(one_hot)[[0. 0. 1. 0. 0. 0. 0. 0.] ## 인덱스 2의 oh-vec
[0. 0. 0. 0. 0. 1. 0. 0.] ## 인덱스 5의 oh-vec
[0. 1. 0. 0. 0. 0. 0. 0.] ## 인덱스 1의 oh-vec
[0. 0. 0. 0. 0. 0. 1. 0.] ## 인덱스 6의 oh-vec
[0. 0. 0. 1. 0. 0. 0. 0.] ## 인덱스 3의 oh-vec
[0. 0. 0. 0. 0. 0. 0. 1.]] ## 인덱스 7의 oh-vecencoded가 이중 리스트로 되어있어서 [0]을 통해 접근.
각 원소의 oh-vec를 이중 리스트로 배열의 형태로 리턴을 해줌!!
3. 원-핫의 한계
이런 표현 방식은 단어의 수가 늘어날 수록 벡터를 저장하기 위한 공간이 계속 늘어남. -> 벡터의 차원이 계속 늘어나게 됨. 만약 단어가 1000개인 코퍼스로 원 핫 벡터를 만들게 된다면 1000개의 차원을 가진 벡터가 됨. 999개의 값은 0을 가지므로 저장 공간 측면에선 비효율 적.
또한, 원-핫은 단어의 유사도를 표현하지 못함. 예를 들어, 늑대, 호랑이, 강아지, 고양이에 대해 원핫을 하면 [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]이 됨. 원핫 벡터로는 강아지와 늑대, 호랑이와 고양이가 유사하다는 것을 표현할 수 없음. 좀 더 극단적으로는 개, 강아지, 냉장고가 있다면 강아지가 개와 유사하지만 개와 냉장고 중 어떤 것과 유사한지 알 수가 없음
단어간 유사성을 알 수 없는 것은 검색 시스템에서 심각한 문제. 예를 들어, 여행을 가기 위해 '부산 숙소'를 입력하면 '부산 게스트하우스', '부산 펜션', '부산 호텔'등의 유사 단어를 보여줘야 함. 하지만 유사성 계산이 안되면 '숙소'와 유사도가 높은 '게스트하우스', '펜션', '호텔'등의 연관 검색어를 보여줄 수 없게 됨.
이런 단점 해결을 위해 잠재 의미를 반영해 다차원 공간에 벡터화 하는 기법이 크게 두 가지 있음
카운트 기반 벡터화 방법인 LSA, HAL이 있고, 예측 기반의 NNLM, RNNLM, Word2Vec, FastText등이 있음. 카운트+예측 모두 쓰는 것은 Glove가 존재.
09) 데이터의 분리
2. X와 y분리하기
1) zip 함수를 이용해 분리
X, y = zip(['a', 1], ['b', 2], ['c', 3])
print(X)
print(y)('a', 'b', 'c')
(1, 2, 3)- 각 데이터에서 첫번째로 등장한 원소끼리 묶이고, 두번째로 등장한 원소끼리 묶인것을 볼수 있음
sequences = [['a', 1], ['b', 2], ['c', 3]]
X, y = zip(*sequences)
print(X)
print(y)('a', 'b', 'c')
(1, 2, 3)*sequences로 sequences 전체에 접근하고, zip을 이용해 X, y에 첫번째 등장 원소 묶음, 두 번째 등장 원소 묶음을 할당
2) 데이터 프레임을 이용해 분리하기
import pandas as pd
values = [['당신에게 드리는 마지막 혜택!', 1],
['내일 뵐 수 있을지 확인 부탁드...', 0],
['도연씨. 잘 지내시죠? 오랜만입...', 0],
['(광고) AI로 주가를 예측할 수 있다!', 1]]
columns = ['메일 본문', '스팸 메일 유무']
df = pd.DataFrame(values, columns=columns)
df
데이터 프레임은 열의 이름으로 각 열에 접근이 가능하므로 손 쉽게 X, y분리가 가능함
X = df['메일 본문']
y = df['스팸 메일 유무']
print(X)
print(y)0 당신에게 드리는 마지막 혜택!
1 내일 뵐 수 있을지 확인 부탁드...
2 도연씨. 잘 지내시죠? 오랜만입...
3 (광고) AI로 주가를 예측할 수 있다!
Name: 메일 본문, dtype: object
0 1
1 0
2 0
3 1
Name: 스팸 메일 유무, dtype: int643) Numpy를 이용해 분리하기
import numpy as np
ar = np.array(0, 16).reshape((4, 4))
print(ar)
X = ar[:, :3]
print(X)
y = ar[:, 3]
print(y)[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
[[ 0 1 2]
[ 4 5 6]
[ 8 9 10]
[12 13 14]]
[ 3 7 11 15]array는 리스트 슬라이싱 처럼 행 열에 접근이 가능!!
3. 테스트 데이터 분리하기
X, y가 분리된 데이터에 대해서 train/test를 분리
1) 사이킷 런을 이용
from sklearn.model_selection import train_test_split
X_trina, X_test, y_train, y_test = train_test_split(X, y, test_size = .2, random_state = 1234)X : 독립 변수 데이터. (배열이나 데이터프레임)
y : 종속 변수 데이터. 레이블 데이터.
test_size : 테스트용 데이터 개수를 지정한다. 1보다 작은 실수를 기재할 경우, 비율을 나타낸다.
train_size : 학습용 데이터의 개수를 지정한다. 1보다 작은 실수를 기재할 경우, 비율을 나타낸다.
(test_size와 train_size 중 하나만 기재해도 가능)
random_state : 난수 시드
import numpy as np
from sklearn.model_selection import train_test_split
X, y = np.arange(10).reshape((5, 2)), range(5)
print(X)
print(list(y))[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
[0, 1, 2, 3, 4]임의로 생성해 줌
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .33, random_state = 1234)
print(X_train)
print(X_test)[[2 3]
[4 5]
[6 7]]
[[8 9]
[0 1]]1/3만 test set에 할당. 5/3은 1.6666인데 반올림 해서 2개 관측치를 넣어준 듯
2) 수동으로 분리하기
X, y = np.arange(0, 24).reshape((12, 2)), range(12)
print(X)
print(list(y))[[ 0 1]
[ 2 3]
[ 4 5]
[ 6 7]
[ 8 9]
[10 11]
[12 13]
[14 15]
[16 17]
[18 19]
[20 21]
[22 23]]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]## 데이터의 80%에 해당하는 길이를 구하고, 소수가 되는 경우는 정수 값만 리턴을 함
n_of_train = int(len(X) * .8)
n_of_test = int(len(X) - n_of_train)
print(n_of_train)
print(n_of_test)9
3## 데이터 누락을 방지하기 위해 n_of_train만 이용
## n은 단순 개수를 담고 있으므로 n_of_test를 이용하면 잘못된 결과를 초래.
## 인덱스를 이용한 슬라이싱 이므로!! 주의해야함
X_test = X[n_of_train:] # 전체 중 뒤에서 20%만큼 저장
y_test = y[n_of_train:]
X_train = X[:n_of_train]
y_train = y[:n_of_train]
print(X_test)
print(list(y_test))[[18 19]
[20 21]
[22 23]]
[9, 10, 11]10) 한국어 전처리 패키지
유용한 한국어 전처리 패키지들이 존재. 형태소와 문장 토크나이징에 썼던 KoNLPy나 KSS와 함께 유용하게 사용 가능
1. PyKoSpacing
: 띄어쓰기가 되어있지 않은 문장을 띄어쓰기를 한 문장으로 변환해주는 패키지. 대용량 코퍼스를 학습해 만들어진 띄어쓰기 딥 러닝 모델로 준수한 성능 보유!!
!pip install git+https://github.com/haven-jeon/PyKoSpacing.gitsent = '김철수는 극중 두 인격의 사나이 이광수 역을 맡았다. 철수는 한국 유일의 태권도 전승자를 가리는 결전의 날을 앞두고 10년간 함께 훈련한 사형인 유연재(김광수 분)를 찾으러 속세로 내려온 인물이다.'
new_sent = sent.replace(" ", '') # 띄어쓰기가 없는 문장 임의로 만들기
print(new_sent)김철수는극중두인격의사나이이광수역을맡았다.철수는한국유일의태권도전승자를가리는결전의날을앞두고10년간함께훈련한사형인유연재(김광수분)를찾으러속세로내려온인물이다.이를 PyKoSpacing을 이용해 원 문장과 비교
from pykospacing import Spacing
spacing = Spacing() # 모델 생성
kospacing_sent = spacing(new_sent)
print(sent)
print(kospacing_sent)김철수는 극중 두 인격의 사나이 이광수 역을 맡았다. 철수는 한국 유일의 태권도 전승자를 가리는 결전의 날을 앞두고 10년간 함께 훈련한 사형인 유연재(김광수 분)를 찾으러 속세로 내려온 인물이다.
김철수는 극중 두 인격의 사나이 이광수 역을 맡았다. 철수는 한국 유일의 태권도 전승자를 가리는 결전의 날을 앞두고 10년간 함께 훈련한 사형인 유연재(김광수 분)를 찾으러 속세로 내려온 인물이다.정확히 일치함.
2. Py-Hanspell
: 네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지.
!pip install git+https://github.com/ssut/py-hanspell.gitfrom hanspell import spell_checker
sent = "맞춤법 틀리면 외 않되? 쓰고싶은대로쓰면돼지 "
spelled_sent = spell_checker.check(sent)
## 맞춤법 체크된 문장 할당
hanspell_sent = spelled_sent.checked
print(hanspell_sent)맞춤법 틀리면 왜 안돼? 쓰고 싶은 대로 쓰면 되지이 패키지는 맞춤법 외에 띄어쓰기도 보장.
spelled_sent = spell_checker.check(new_sent)
hanspell_sent = spelled_sent.checked
print(hanspell_sent) # hanspell 결과
print(kospacing_sent) # 앞서 사용한 kospacing 패키지에서 얻은 결과김철수는 극 중 두 인격의 사나이 이광수 역을 맡았다. 철수는 한국 유일의 태권도 전승자를 가리는 결전의 날을 앞두고 10년간 함께 훈련한 사형인 유연제(김광수 분)를 찾으러 속세로 내려온 인물이다.
김철수는 극중 두 인격의 사나이 이광수 역을 맡았다. 철수는 한국 유일의 태권도 전승자를 가리는 결전의 날을 앞두고 10년간 함께 훈련한 사형인 유연재(김광수 분)를 찾으러 속세로 내려온 인물이다.거의 똑같지만, 띄어쓰기가 조금 다름.
3. SOYNLP를 이용한 단어 토큰화
품사 태깅, 단어 토큰화를 지원하는 토크나이저. 비지도 학습으로 토큰화를 하고, 데이터에 자주 등장하는 단어로 분석. 내부적으로 단어 점수표로 동작하고 이 점수는 응집확률(cohension prob)와 브랜칭 엔트로피(branching entropy)를 사용
1. 신조어 문제
기존의 형태소 분석기는 신조어나 형태소 분석기에 등록되지 않은 단어는 제대로 구분하지 못했음
from konlpy.tag import Okt
tokenizer = Okt()
print(tokenizer.morphs('에이비식스 이대휘 1월 최애돌 기부 요청'))['에이', '비식스', '이대', '휘', '1월', '최애', '돌', '기부', '요청']에이비식스, 이대휘, 최애돌 등은 한 단어이지만, 형태소 분석기에 의해서 다 분리되엇음.
텍스트 데이터에서 특정 문자 시퀀스가 빈도가 높고, 앞 뒤로 조사 또는 완전히 다른 단어가 등장하는 것을 고려해 해당 문자 시퀀스를 형태소라고 판단하는 토크나이저는 어떨까?
예를 들어, 에이비식스라는 문자열이 자주 연결돼 등장한다면, 한 단어로 인식하고, 에이비식스 앞, 뒤에 '최고', '가수', '실력'과 같은 독립된 단어들이 계속 등장한다면 에이비식스를 한 단어로 판단하게 된다. 이런 아이디어로 작동하는게 soynlp
2. 학습
soynlp는 학습에 기반한 토크나이저로 필요한 한국어 문서를 다운로드
pip install soynlp
import urllib.request
from soynlp import DoublespaceLineCorpus
from soynlp.word import WordExtractor
urllib.request.urlretrieve("https://raw.githubusercontent.com/lovit/soynlp/master/tutorials/2016-10-20.txt", filename="2016-10-20.txt")('2016-10-20.txt', <http.client.HTTPMessage at 0x7f6777ceea10>)txt를 다운로드 받음. 이를 다수의 문서로 분리
corpus = DoublespaceLineCorpus('2016-10-20.txt')
len(corpus)30091총 3만 91개의 문서가 존재. 상위 3개 문서만 출력해보자
i = 0
for document in corpus:
if len(document) > 0:
print(document)
i += 1
if i == 3:
breakfor 문을 돌며 i를 1씩 증가하고, 3이 되었다면 종료
19 1990 52 1 22
오패산터널 총격전 용의자 검거 서울 연합뉴스 경찰 관계자들이 19일 오후 서울 강북구 오패산 터널 인근에서 사제 총기를 발사해 경찰을 살해한 용의자 성모씨를 검거하고 있다 성씨는 검거 당시 서바이벌 게임에서 쓰는 방탄조끼에 헬멧까지 착용한 상태였다 독자제공 영상 캡처 연합뉴스 서울 연합뉴스 김은경 기자 사제 총기로 경찰을 살해한 범인 성모 46 씨는 주도면밀했다 경찰에 따르면 성씨는 19일 오후 강북경찰서 인근 부동산 업소 밖에서 부동산업자 이모 67 씨가 나오기를 기다렸다 이씨와는 평소에도 말다툼을 자주 한 것으로 알려졌다 이씨가 나와 걷기 시작하자 성씨는 따라가면서 미리 준비해온 사제 총기를 이씨에게 발사했다 총알이 빗나가면서 이씨는 도망갔다 그 빗나간 총알은 지나가던 행인 71 씨의 배를 스쳤다 성씨는 강북서 인근 치킨집까지 이씨 뒤를 쫓으며 실랑이하다 쓰러뜨린 후 총기와 함께 가져온 망치로 이씨 머리를 때렸다 이 과정에서 오후 6시 20분께 강북구 번동 길 위에서 사람들이 싸우고 있다 총소리가 났다 는 등의 신고가 여러건 들어왔다 5분 후에 성씨의 전자발찌가 훼손됐다는 신고가 보호관찰소 시스템을 통해 들어왔다 성범죄자로 전자발찌를 차고 있던 성씨는 부엌칼로 직접 자신의 발찌를 끊었다 용의자 소지 사제총기 2정 서울 연합뉴스 임헌정 기자 서울 시내에서 폭행 용의자가 현장 조사를 벌이던 경찰관에게 사제총기를 발사해 경찰관이 숨졌다 19일 오후 6시28분 강북구 번동에서 둔기로 맞았다 는 폭행 피해 신고가 접수돼 현장에서 조사하던 강북경찰서 번동파출소 소속 김모 54 경위가 폭행 용의자 성모 45 씨가 쏜 사제총기에 맞고 쓰러진 뒤 병원에 옮겨졌으나 숨졌다 사진은 용의자가 소지한 사제총기 신고를 받고 번동파출소에서 김창호 54 경위 등 경찰들이 오후 6시 29분께 현장으로 출동했다 성씨는 그사이 부동산 앞에 놓아뒀던 가방을 챙겨 오패산 쪽으로 도망간 후였다 김 경위는 오패산 터널 입구 오른쪽의 급경사에서 성씨에게 접근하다가 오후 6시 33분께 풀숲에 숨은 성씨가 허공에 난사한 10여발의 총알 중 일부를 왼쪽 어깨 뒷부분에 맞고 쓰러졌다 김 경위는 구급차가 도착했을 때 이미 의식이 없었고 심폐소생술을 하며 병원으로 옮겨졌으나 총알이 폐를 훼손해 오후 7시 40분께 사망했다 김 경위는 외근용 조끼를 입고 있었으나 총알을 막기에는 역부족이었다 머리에 부상을 입은 이씨도 함께 병원으로 이송됐으나 생명에는 지장이 없는 것으로 알려졌다 성씨는 오패산 터널 밑쪽 숲에서 오후 6시 45분께 잡혔다 총격현장 수색하는 경찰들 서울 연합뉴스 이효석 기자 19일 오후 서울 강북구 오패산 터널 인근에서 경찰들이 폭행 용의자가 사제총기를 발사해 경찰관이 사망한 사건을 조사 하고 있다 총 때문에 쫓던 경관들과 민간인들이 몸을 숨겼는데 인근 신발가게 직원 이모씨가 다가가 성씨를 덮쳤고 이어 현장에 있던 다른 상인들과 경찰이 가세해 체포했다 성씨는 경찰에 붙잡힌 직후 나 자살하려고 한 거다 맞아 죽어도 괜찮다 고 말한 것으로 전해졌다 성씨 자신도 경찰이 발사한 공포탄 1발 실탄 3발 중 실탄 1발을 배에 맞았으나 방탄조끼를 입은 상태여서 부상하지는 않았다 경찰은 인근을 수색해 성씨가 만든 사제총 16정과 칼 7개를 압수했다 실제 폭발할지는 알 수 없는 요구르트병에 무언가를 채워두고 심지를 꽂은 사제 폭탄도 발견됐다 일부는 숲에서 발견됐고 일부는 성씨가 소지한 가방 안에 있었다
테헤란 연합뉴스 강훈상 특파원 이용 승객수 기준 세계 최대 공항인 아랍에미리트 두바이국제공항은 19일 현지시간 이 공항을 이륙하는 모든 항공기의 탑승객은 삼성전자의 갤럭시노트7을 휴대하면 안 된다고 밝혔다 두바이국제공항은 여러 항공 관련 기구의 권고에 따라 안전성에 우려가 있는 스마트폰 갤럭시노트7을 휴대하고 비행기를 타면 안 된다 며 탑승 전 검색 중 발견되면 압수할 계획 이라고 발표했다 공항 측은 갤럭시노트7의 배터리가 폭발 우려가 제기된 만큼 이 제품을 갖고 공항 안으로 들어오지 말라고 이용객에 당부했다 이런 조치는 두바이국제공항 뿐 아니라 신공항인 두바이월드센터에도 적용된다 배터리 폭발문제로 회수된 갤럭시노트7 연합뉴스자료사진soynlp는 학습 기반 토크나이저이므로 konlpy의 다르형태소 분석기들과는 달리 학습을 거쳐야 함.
word_extractor = WordExtractor()
word_extractor.train(corpus)
word_score_table = word_extractor.extract()training was done. used memory 1.883 Gb
all cohesion probabilities was computed. # words = 223348
all branching entropies was computed # words = 361598
all accessor variety was computed # words = 361598학습에 시간이 꽤 걸림
3. SOYNLP의 응집 확률

word_score_table['반포한'].cohesion_forward0.088380029136451320.08로 상당히 낮음. '반포한강'은 '반포한'보다 높을까?
word_score_table['반포한강'].cohesion_forward0.19841268168224552반포한강이 반포한에 비해 응집 확률이 높음
반포한강공이 반포한강에 비해 높을까?
word_score_table['반포한강공'].cohesion_forward0.2972877884078849반포한강공이 반포한강보다 높음. 즉 하나의 단어로 등장할 가능성이 더 높음
word_score_table['반포한강공원'].cohesion_forward0.37891487632839754반포한강공원이 제일 높음
word_score_table['반포한강공원에'].cohesion_forward0.33492963377557666반포한강공원에는 오히려 떨어짐. 즉 반포한강공원이 한 단어일 가능성이 제일 높음. 응집도를 통해 파악한다면 하나의 단어로 판단하기에 가장 적절한 것은 '반포한강공원'
4. SOYNLP의 브랜칭 엔트로피
'디'라는 단어가 주어지면 다음엔 어떤 단어가 올까? 정답을 맞추기 너무 어렵다. 다음 단어는 '스'라고 주어지면 '디스'를 알고 있으니까 이를 바탕으로 유추할 단어는? '디스코', '디스코드', '디스플레이', '디스크' 등 너무 많다... 디스 다음엔 '플'이고 '디스플'을 알고 있으면 다음 글자가 비교적 유추가 쉽다. '레'가 정답이다. '디스플레'까지 주어졌다면 그 다음 글자는 아마 대부분 '이'라고 생각할 것이다.
브랜칭 엔트로피는, 하나의 완성된 단어에 가까울수록 문맥으로 인해 비교적 정확한 예측이 가능해지므로 점점 줄어드는 양상을 보인다.
word_score_table['디스'].right_branching_entropy1.6371694761537934word_score_table['디스플'].right_branching_entropy-0.0디스보다 디스플의 브랜칭 엔트로피가 확연히 줄어드는 것을 알 수 있다.
다음에 어떤 문자가 올지 문맥상으로 유추하기 명확하기 때문이다.
word_score_table['디스플레이'].right_branching_entropy3.1400392861792916그렇다면 디스플레이는 왜 높아졌을까? 그 이유는 디스플레이 다음에 조사나 다른 단어와 같은 다양한 경우가 있기 때문이다. 하나의 단어가 끝나면 그 경계부터 다시 브랜칭 엔트로피 값이 증가하게 된다. 이 값으로 단어를 판단하는 것이 가능하겠지?
5. SOYNLP의 L tokenizer
한국어는 띄어쓰기 단위로 나눈 어절 토큰은 주로 L + R의 형식을 가짐.
예를들면, '공원에'는 '공원' + '에', '공부하는'은 '공부' + '하는'의 형식으로. L토크나이저는 이처럼 L+R의 형태로 나누되, 분리 기준을 점수가 가장 높은 L토큰을 찾아내는 원리를 갖고 있다.
from soynlp.tokenizer import LTokenizer
scores = {word:score.cohesion_forward for word, score in word_score_table.items()}
l_tokenizer = LTokenizer(scores=scores)
l_tokenizer.tokenize("국제사회와 우리의 노력들로 범죄를 척결하자", flatten=False)[('국제사회', '와'), ('우리', '의'), ('노력', '들로'), ('범죄', '를'), ('척결', '하자')]6. 최대 점수 토크나이저
띄어쓰기가 되지 않는 문장에서 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저.
from soynlp.tokenizer import MaxScoreTokenizer
maxscore_tokenizer = MaxScoreTokenizer(scores=scores)
maxscore_tokenizer.tokenize("국제사회와우리의노력들로범죄를척결하자")['국제사회', '와', '우리', '의', '노력', '들로', '범죄', '를', '척결', '하자']4. SOYNLP를 이용한 반복되는 문자 정제
SNS, 채팅 데이터와 같은 한국어 데이터에는 ㅋㅋ, ㅎㅎ등의 이모티콘의 경우 불필요하게 연속되는 경우가 많은데 ㅋㅋ, ㅋㅋㅋ, ㅋㅋㅋㅋ와 같은 경우를 모두 서로 다른 단어로 처리하는 것은 불필요. 따라서 반복되는 것은 하나로 정규화
from soynlp.normalizer import * ### 모든 걸 다 임포트
print(emoticon_normalize('앜ㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠㅠㅠㅠ', num_repeats=2))아ㅋㅋ영화존잼쓰ㅠㅠ
아ㅋㅋ영화존잼쓰ㅠㅠ
아ㅋㅋ영화존잼쓰ㅠㅠ
아ㅋㅋ영화존잼쓰ㅠㅠㅋㅋ와 ㅠㅠ같은 불필요한 이모티콘을 2개만 남겨뒀다. 그 의미는 충분히 파악 가능하기 때문에.
print(repeat_normalize('와하하하하하하하하하핫', num_repeats=2))
print(repeat_normalize('와하하하하하하핫', num_repeats=2))
print(repeat_normalize('와하하하하핫', num_repeats=2))와하하핫
와하하핫
와하하핫의미없는 반복은 이모티콘에만 해당되는건 아님. 문자에도 해당됨.
5. Customized KoNLPy
띄어쓰기 만으로는 토큰화가 어려워 한국어는 형태소 분석기를 사용해 토큰화 한다고 수차례 언급했다. 만약 아래와 같은 상황이 주어진다면?
형태소 분석 입력 : '은경이는 사무실로 갔습니다.'
형태소 분석 결과 : ['은', '경이', '는', '사무실', '로', '갔습니다', '.']은경이가 총 세개로 분리가 되었다. '은경이'를 얻던, '은경'이라도 얻어야 했는데 그 의미를 잃어버렸다. 이런 경우를 대비해 형태소 분석기에 사전을 추가해줄 수 있다. '은경이'는 하나의 단어이므로 분리하지 말라고 분석기에게 알려주는 것!
사용자 사전 추가는 분석기마다 다른데, 생각보다 복잡한 경우가 많다. Customized Konlpy라는 사전 추가가 쉬운 패키지를 사용하자.
!pip install customized_konlpy
from ckonlpy.tag import Twitter
twitter = Twitter() ## 트위터라는 이름의 분석기 생성
twitter.morphs('은경이는 사무실로 갔습니다.')['은', '경이', '는', '사무실', '로', '갔습니다', '.']제대로 분리가 안되었음. 추가가 되기 전이므로
twitter.add_dictionary('은경이', 'Noun')
twitter.morphs('은경이는 사무실로 갔습니다.')['은경이', '는', '사무실', '로', '갔습니다', '.']add_dictionary()를 활용해 사전을 커스터마이즈 할 수 있다.
은경이가 제대로 인식이 됨!!
