
자주 묻는 질문 FAQ
Q1. Python과 R중 어떤 언어를 배워야 할까요?
#노트북 안에서 그래프를 그리기 위해
%matplotlib inline
# Import the standard Python Scientific Libraries
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
# Suppress Deprecation and Incorrect Usage Warnings
import warnings
warnings.filterwarnings('ignore')
question = pd.read_csv('https://raw.githubusercontent.com/corazzon/KaggleStruggle/master/kaggle-survey-2017/data/schema.csv')
# 판다스로 선다형 객관식 문제에 대한 응답을 가져 옴
mcq = pd.read_csv('https://raw.githubusercontent.com/corazzon/KaggleStruggle/master/kaggle-survey-2017/data/multipleChoiceResponses.csv', encoding="ISO-8859-1", low_memory=False)
sns.countplot(y='LanguageRecommendationSelect', data=mcq)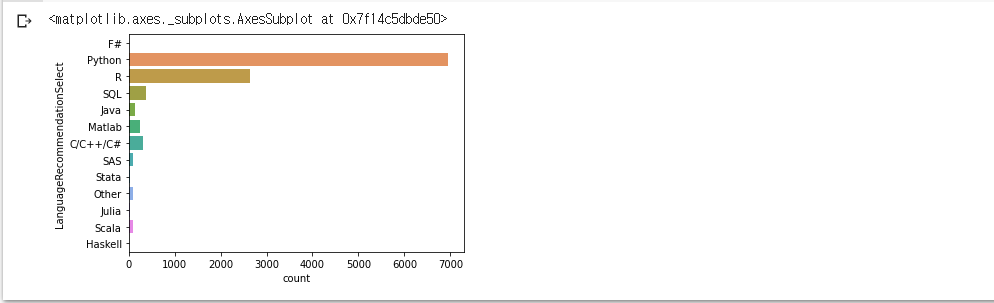
- 많은 응답자의 대부분이 사용하는 언어로 'Python'을 선택
- R과 SQL이 그 뒤를 이음
- 응답자 기준으로는 Python이 압도적인 비중을 차지.
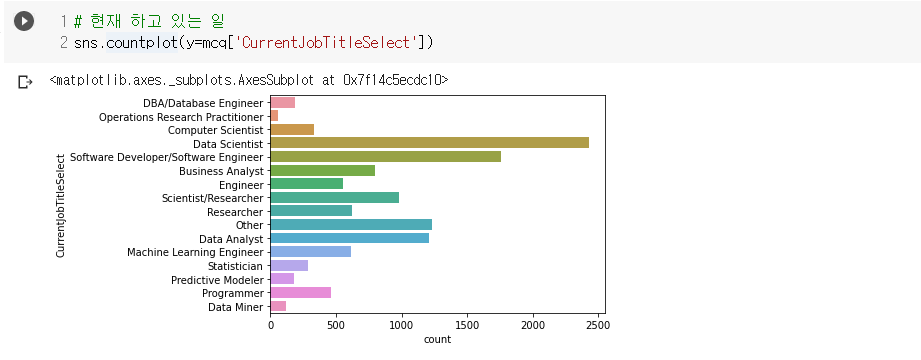
- 응답자의 현재 하고 있는 일은 데이터 사이언티스트가 가장 높고 그 다음이 소프트웨어 개발/엔지니어.
- kaggle 유저를 대상으로 설문을 한 것이라 대부분이 그런 것 같음.

- 설문 응답자 중 11830명이 하는 일에 대해 답했고, 하지 않은 사람도 7천명 가량 되는듯
# 현재 하고 있는 일에 대한 응답을 해준 사람 중 Python과 R을 사용하는 사람
# 응답자들이 실제 업무에서 어떤 언어를 주로 사용하는지 볼 수 있다.
data = mcq[(mcq['CurrentJobTitleSelect'].notnull()) & (
(mcq['LanguageRecommendationSelect'] == 'Python') | (
mcq['LanguageRecommendationSelect'] == 'R'))]
print(data.shape)
plt.figure(figsize=(8, 10))
sns.countplot(y='CurrentJobTitleSelect',
hue='LanguageRecommendationSelect',
data=data) 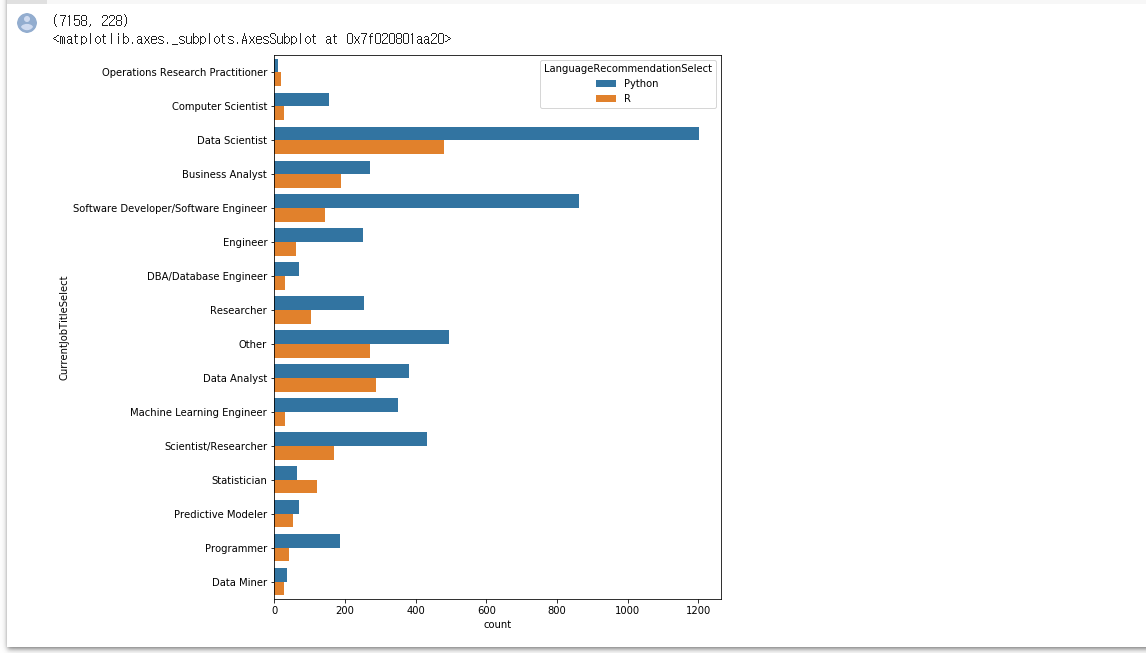
-
Data Scientist의 대부분은 R보단 Python을 사용
-
대부분의 직업군이 R보단 Python을 더 많이 사용
-
통계학자들이 거의 유일하게 R을 더 많이 사용. 학부때 교수님들도 파이썬보단 R을 위주로 사용하심.
Q2. 데이터 사이언스 분야에서 앞으로 크게 주목받을 것은 무엇일까요?
- 관련 분야의 종사자가 아니더라도 빅데이터, 딥러닝, 뉴럴네트워크 같은 용어에 대해 알고 있다. 응답자들이 내년에 가장 흥미로운 기술이 될 것이라 응답한 것이다.
데이터사이언스 툴
mcq_ml_tool_count = pd.DataFrame(
mcq['MLToolNextYearSelect'].value_counts())
mcq_ml_tool_percent = pd.DataFrame(
mcq['MLToolNextYearSelect'].value_counts(normalize=True))
mcq_ml_tool_df = mcq_ml_tool_count.merge(
mcq_ml_tool_percent, left_index=True, right_index=True).head(20)
mcq_ml_tool_df.columns = ['응답 수', '비율']
mcq_ml_tool_df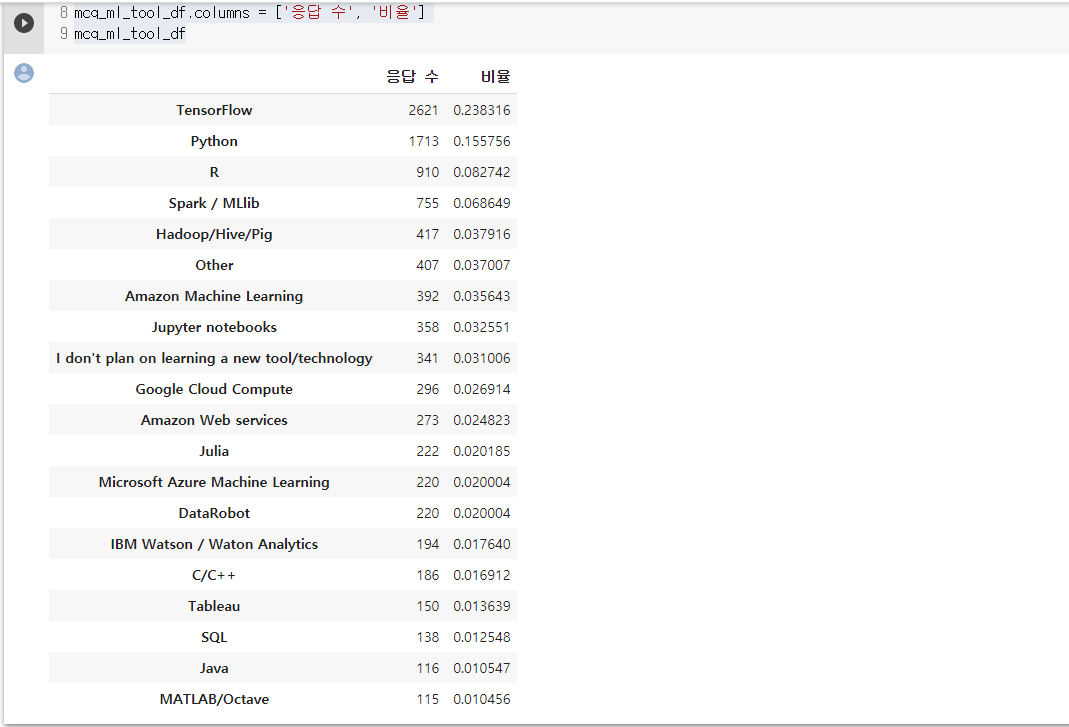
- 앞으로 주목받을 툴로 Tensorflow를 선택. 아무래도 딥러닝 하는데 있어서 유용한 점들이 많기 때문에 그렇지 않을까.
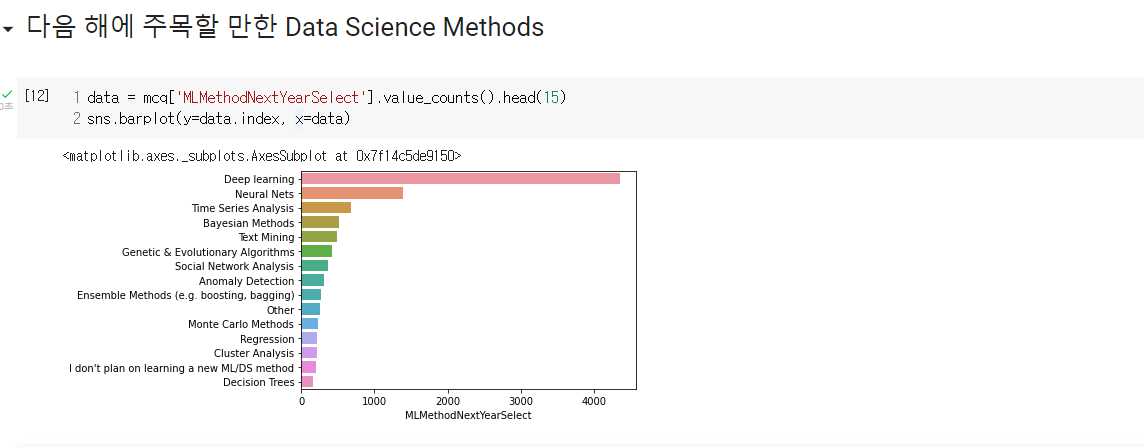
- 딥러닝이 가장 높고 그 다음이 신경망, 시계열 등이 있음
- 이 설문이 수행된 건 2017년. 이미 많은 시간이 흘렀고 지나서 생각해보면 많은 사람들의 생각대로 흘러갔다고 생각된다.
Q3. 어디에서 데이터 사이언스를 배워야 할까요?

Data science