
멘토님 추천으로 Edwith의 kaggel 실습으로 배우는 데이터 사이언스 수강
Chap1. 설문조사 결과 분석과 시각화
데이터 파일
# 노트북 안에서 그래프를 그리기 위해
%matplotlib inline
# Import the standard Python Scientific Libraries
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
# Suppress Deprecation and Incorrect Usage Warnings
import warnings
warnings.filterwarnings('ignore')
question = pd.read_csv('https://raw.githubusercontent.com/corazzon/KaggleStruggle/master/kaggle-survey-2017/data/schema.csv')
question.shape
- 데이터는 강사님 github에서 가져왔음
- github에서 데이터를 다운로드 하기가 어려운 경우 아래처럼 진행하면 됨.
- 데이터 파일에서 raw를 클릭한 후 링크를 복사해서 판다스의 read_csv 매서드 안에 인자로 주면 작업 공간 내에 csv 파일이 없어도 데이터 프레임 생성 가능

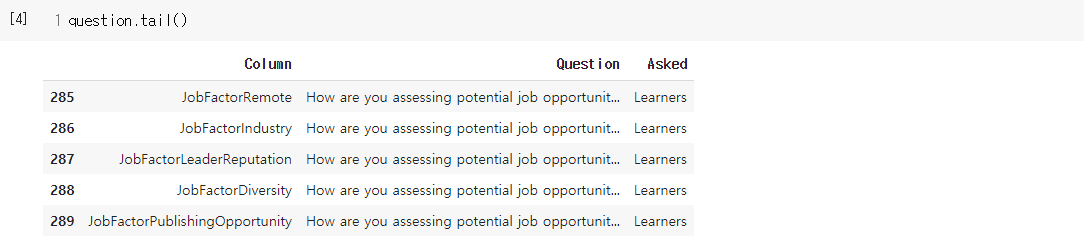
- df.tail() 매서드를 이용해서 하위 5개 로우를 출력(default가 5. 지정 가능)
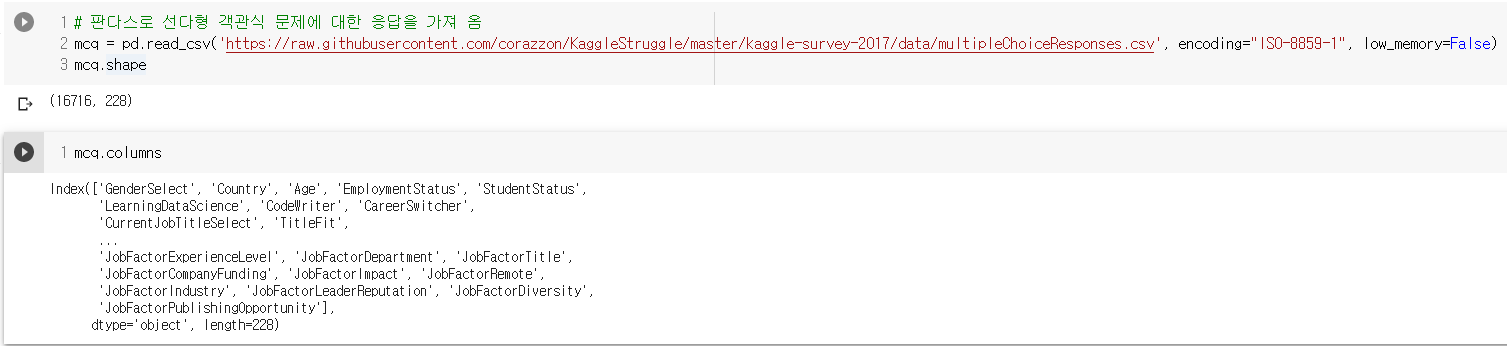
- 위와 같은 방식으로 데이터 프레임 생성. 이번엔 컬럼수가 훨씬 많음
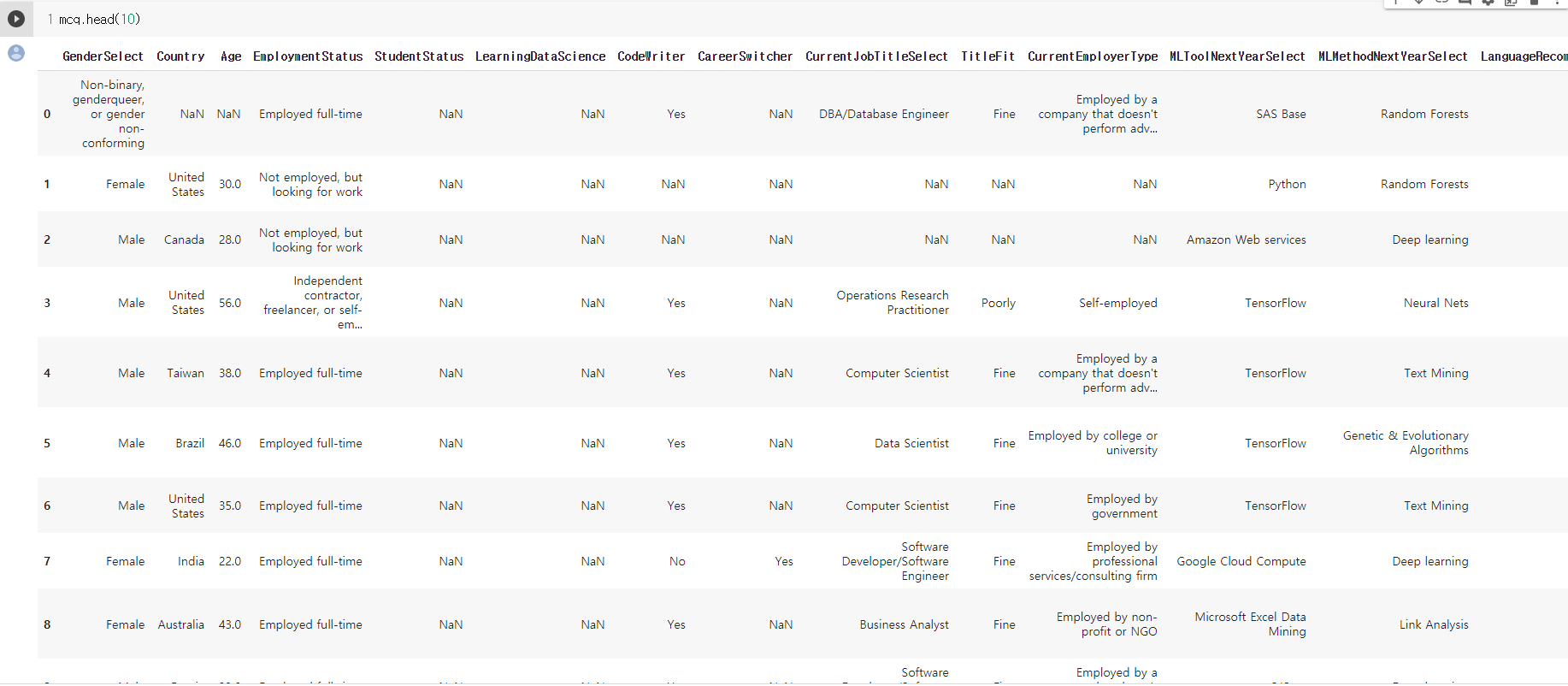
- 이번엔 head를 이용해서 상위 10개의 row를 출력했다. 레이아웃의 한계로 전체 테이블을 넣지 못했지만 아무튼 상위 10개의 row와 모든 컬럼에 대해 출력해준다.
- tail과 head를 사용하면 row에 대해 필터링을 통한 subsetting이 가능함. 유용한 매서드!
# missingno는 NaN 데이터들에 대해 시각화를 해준다.
# NaN 데이터의 컬럼이 많아 아래 그래프만으로는 내용을 파악하기 어렵다.
import missingno as msno
msno.matrix(mcq, figsize=(12,5))
- missingno를 이용해 모든 컬럼에 대해 결측치를 시각화 해준다
- 흰 부분이 결측치가 존재하는 것이고, 검정 부분이 결측치가 아닌 것.
일단 설문조사 항목이 200개가 넘어가고 객관식+주관식이라 응답하지 않은 항목이 상당함!
- 간혹 다양한 요소를 플로팅 하는 경우 그래프 좌상단 부분의 메시지가 출력이 많이 될 수가 있는데 이걸 보기 싫다면 맷플로립의 show 매서드를 같이 써주면 된다. ex) plt.show()
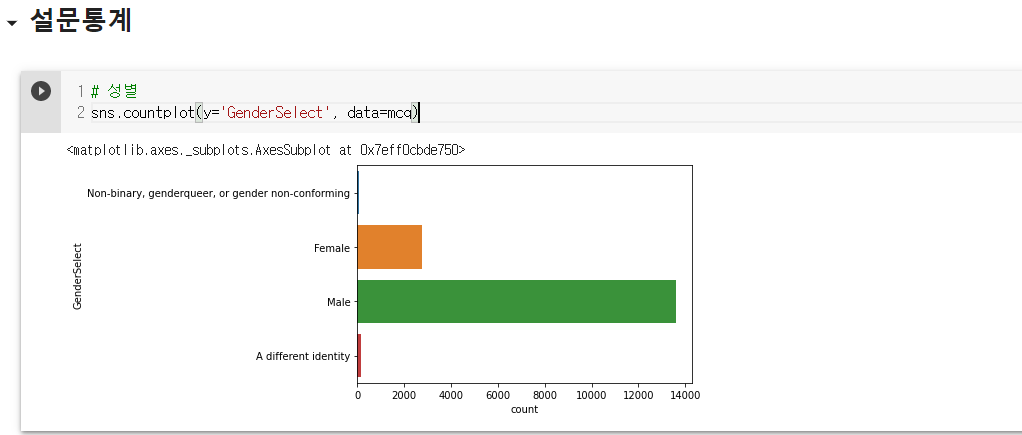
- 데이터 사이언티스트에 대한 설문조사 중 응답한 사람의 성비를 보면 남자가 훨씬 많음을 알 수 있다.
# 국가별 응답수
con_df = pd.DataFrame(mcq['Country'].value_counts())
# print(con_df)
# 'country' 컬럼을 인덱스로 지정해 주고
con_df = con_df.reset_index().rename(columns = {'index': 'Country'})
# 컬럼의 순서대로 응답 수, 국가로 컬럼명을 지정해 줌
con_df.columns = ['응답 수', '국가']
# index 컬럼을 삭제하고 순위를 알기위해 reset_index()를 해준다.
# 우리 나라는 18위이고 전체 52개국에서 참여했지만 20위까지만 본다.
con_df = con_df.reset_index().drop('index', axis=1)
con_df.head(20)
- 판다스의 밸류 카운트는 아주 유용한 매서드. unique한 원소에 대해 count를 리턴해줌. (내림차순 정렬까지)
- 응답수 기준 상위 20개 국가까지 출력. 미국과 인도의 수가 압도적으로 높음
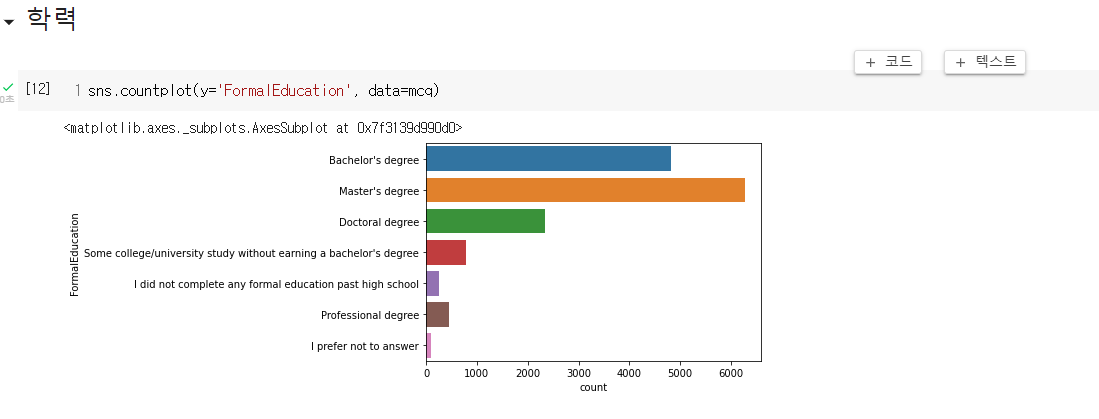
- 학력에 대해 빈도수를 보면 석사 > 학사 > 박사 순
- 국내 기업의 채용 현황을 보면 석사 이상을 요구하는 경우가 많았어서 학사는 갈 곳이 별로 없을 것이라 생각
- 이 데이터는 다양한 국가가 포함되어 있으므로 예상과는 다른 결과가 나온 것 같음
- 그렇다 해도 학사 인력 자체가 훨씬 많음에도 더 많은 비율을 차지하지 못한다는 것은 학사 출신이 석/박과 경쟁해야 하는 경우가 많지 않을까란 생각
- 어느정도 직급인지에 대한 정보는 여기 없기 때문에 대단한 인사이트를 얻긴 힘들고, 이 차트에서 파악 가능한 부분은 '석사 출신이 더 많다' 정도
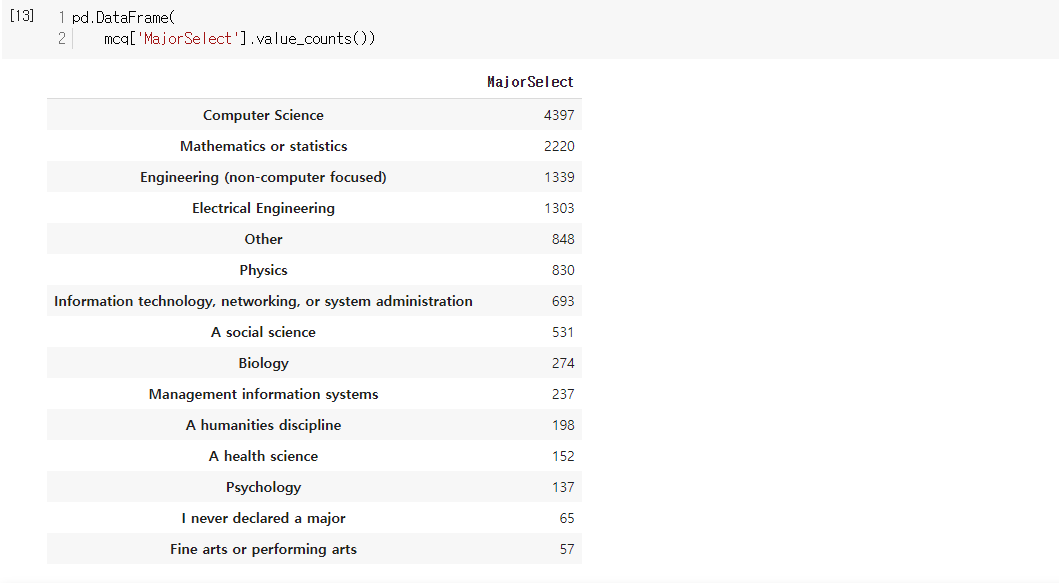
- 데이터 사이언티스로서 일하는 사람들의 전공은 CS, 수학 or 통계, 공학이 많음
- 데이터 사이언티스트가 되기 위해선 CS, 수학/통계, 공학 쪽을 전공하면 좋지 않을까.
mcq_major_count = pd.DataFrame(
mcq['MajorSelect'].value_counts())
mcq_major_percent = pd.DataFrame(
mcq['MajorSelect'].value_counts(normalize=True))
mcq_major_df = mcq_major_count.merge(
mcq_major_percent, left_index=True, right_index=True)
mcq_major_df.columns = ['응답 수', '비율']
mcq_major_df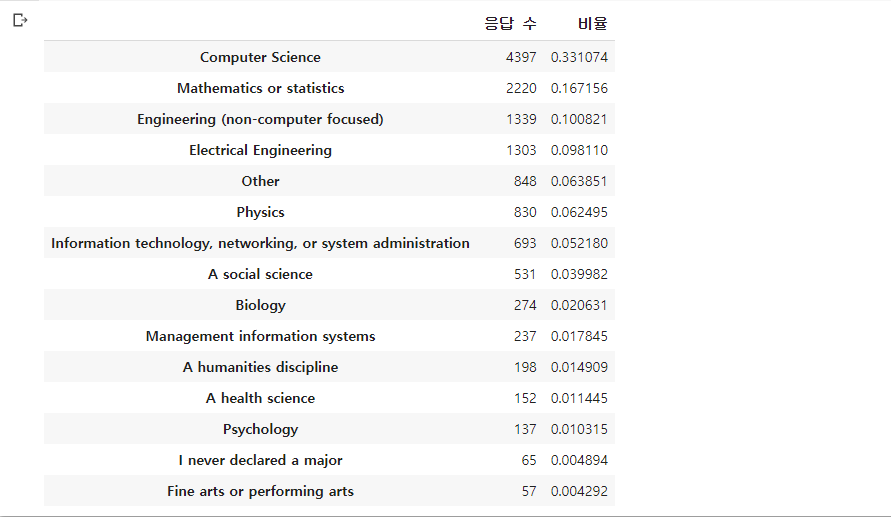
- value_counts에 normalize = True를 주면 unique한 원소의 빈도수에 대해 전체 데이터 대비 차지하는 비율을 반환
- CS가 33% 정도로 압도적인 비율을 차지함.
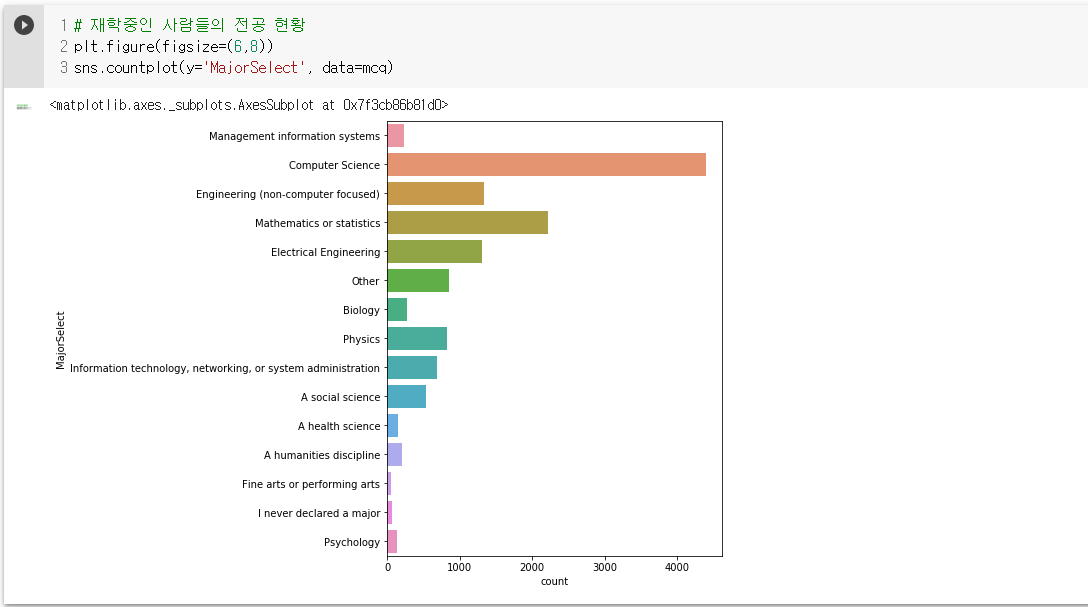
- seaborn의 countplot은 해당 원소의 빈도수를 바탕으로 bar plot을 그려줌.
- 원래는 value_counts를 해서 이걸 바탕으로 바플롯을 그려야 하지만 그럴 필요가 없으므로 유용!
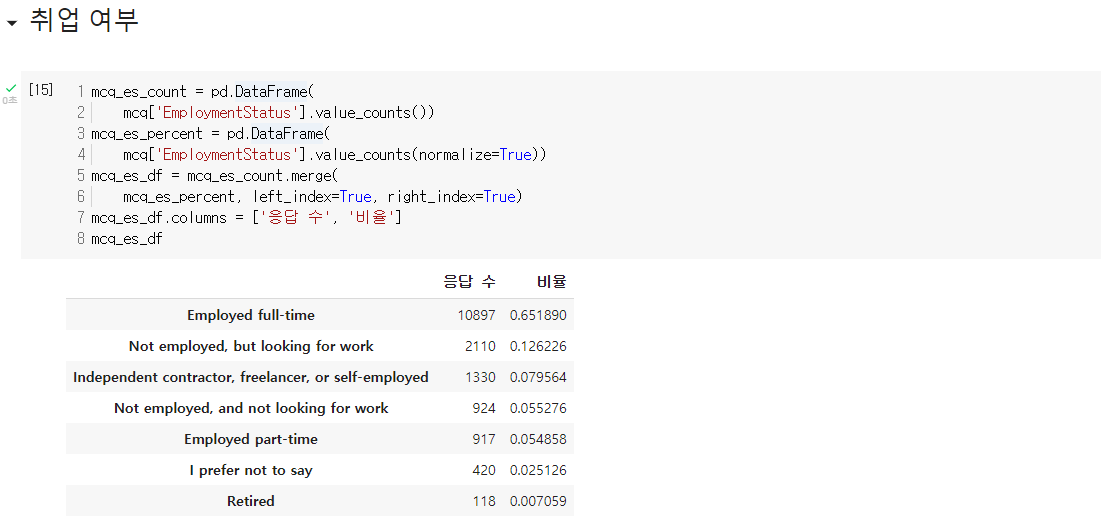
- 응답한 사람 중 full-time 근무자가 압도적으로 많고 그 다음이 구직자.
- 데이터 사이언티스트 분야를 공부한 사람 중 취업율은 63% 정도
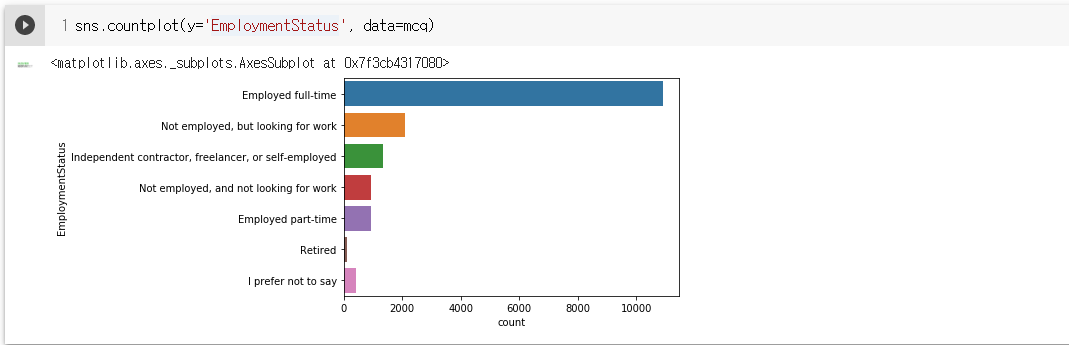
- 마찬가지로 countplot을 이용해 빈도수 시각화. 풀타임 근무자가 압도적으로 많음을 알 수 있다.
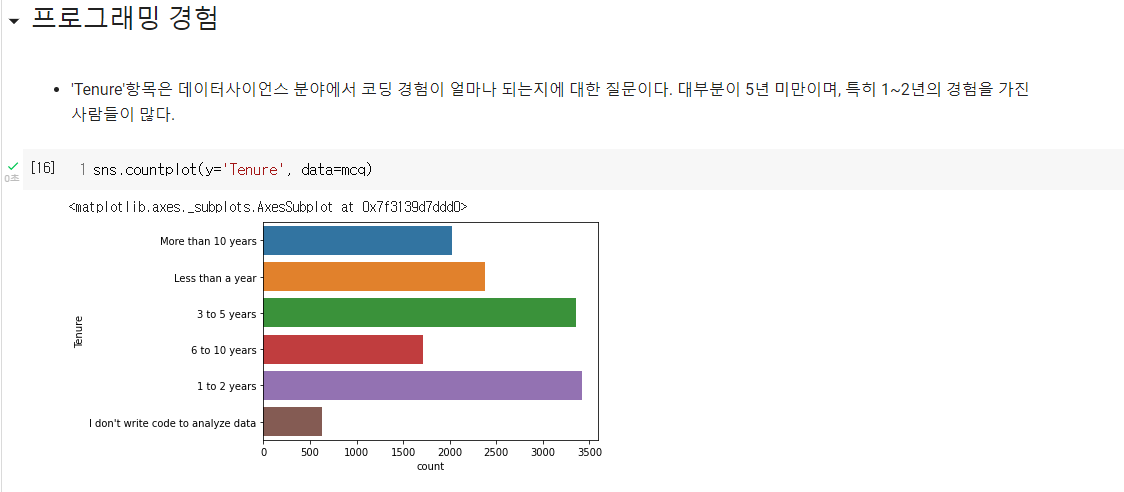
- 코딩 경력에 대한 시각화. 1~2년 / 3~5년이 가장 많음.
- 취업자에 대해서만 조사한 자료가 아니라 취업자 / 구직자 등등 다양한 사람들의 응답결과 이므로
저 만큼은 해야 취업 가능하다 이런건 아님. -> 취업 여부와 주어진 변수들간의 관계를 파악해서 어떤 점이 큰 영향을 미치는지 파악 가능할 듯
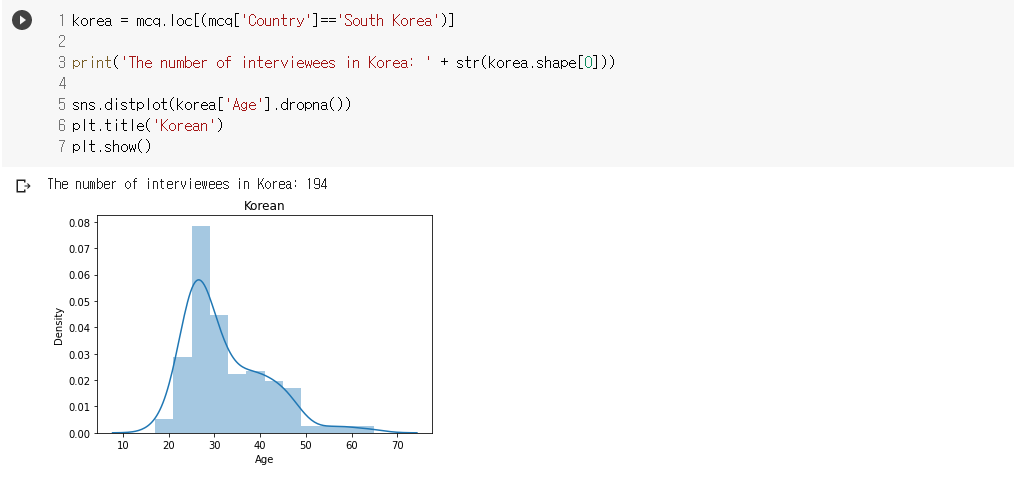
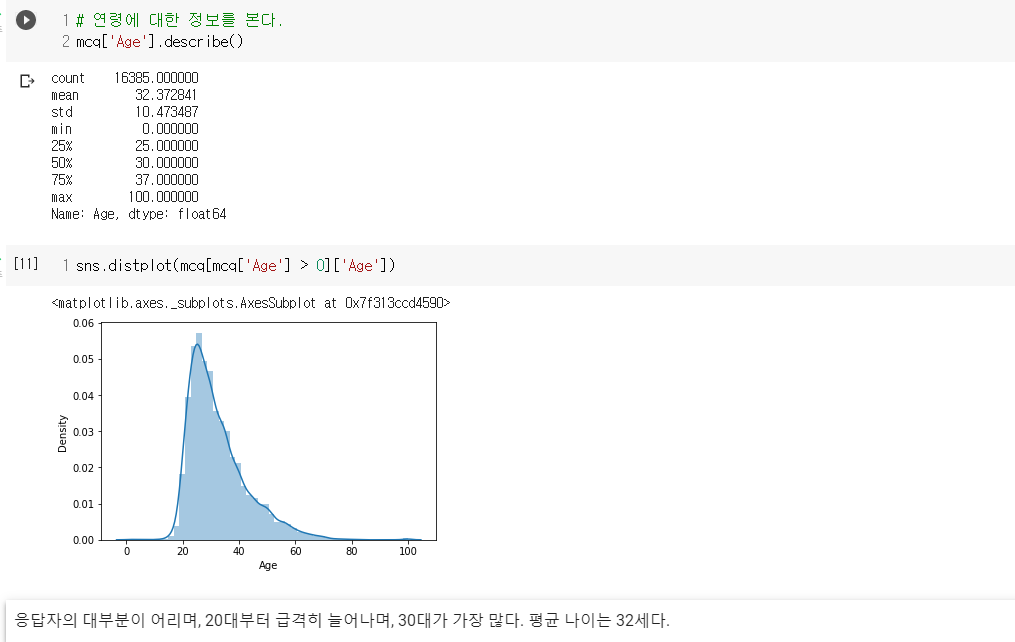
- 한국 응답자에 대해 연령대를 시각화 해본 결과이다
- 20대 중반에서 30대 중반 사이가 많은 비율을 차지하고 있음
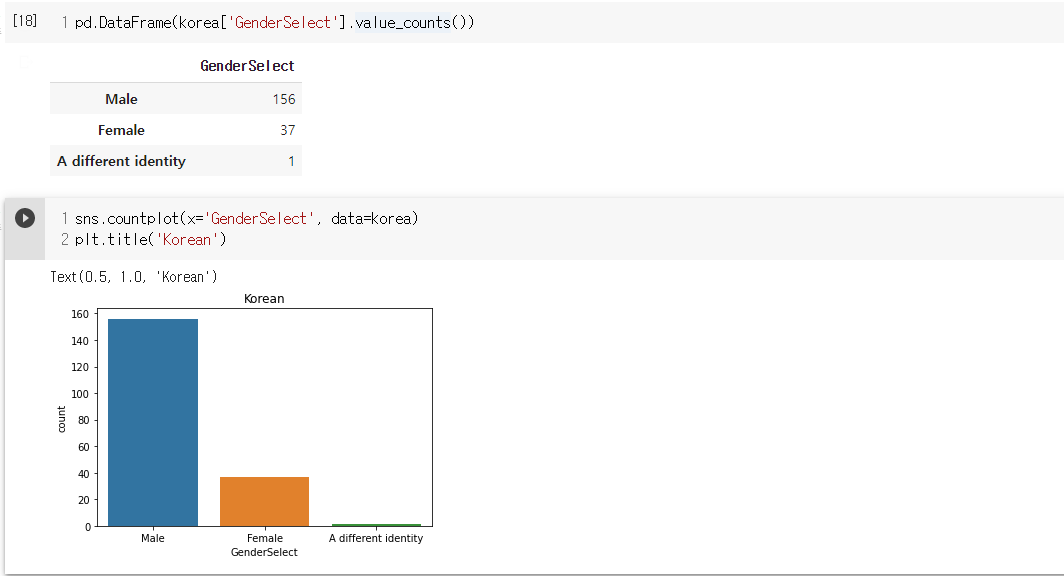
- 한국인 응답자의 성별을 비교해보면 전체적인 성비에서도 그랬듯 남성이 압도적으로 높음
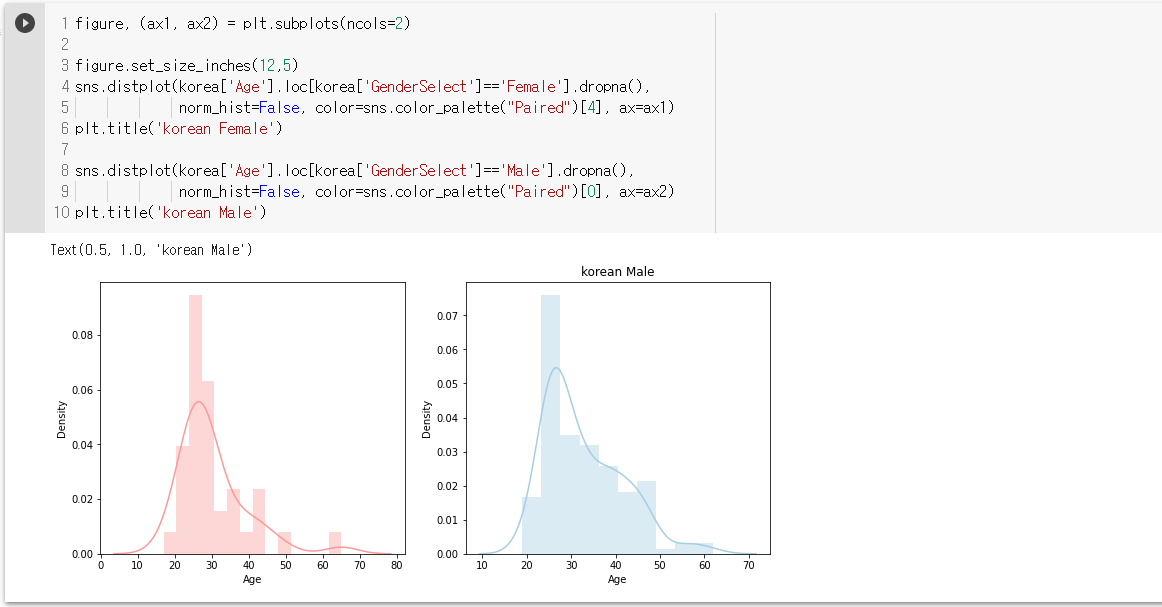
- subplot을 이용하여 한 figure 내에 여러개의 plot이 표현 가능
- 한국인 응답자의 남성과 여성에 대해 age의 분포를 파악
- 20~30세 사이가 가장 많음
sns.barplot(x=korea['EmploymentStatus'].unique(), y=korea['EmploymentStatus'].value_counts()/len(korea))
plt.xticks(rotation=30, ha='right')
plt.title('Employment status of the korean')
plt.ylabel('')
plt.show()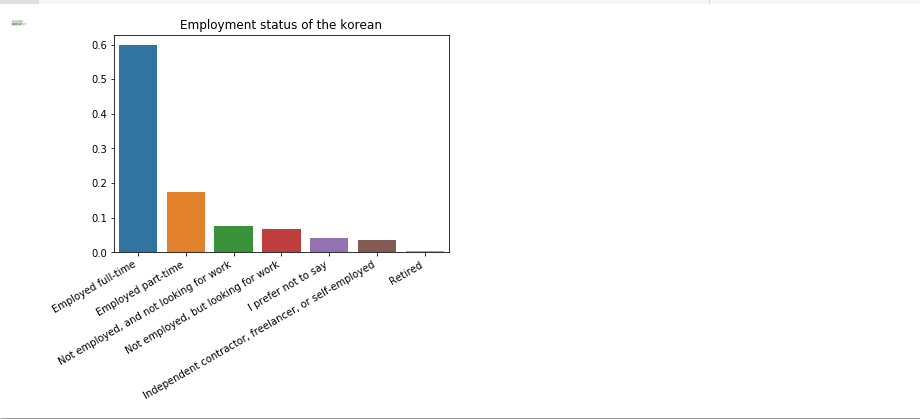
한국인의 경우도 풀타임 근무자가 가장 많았다.
korea['StudentStatus'] = korea['StudentStatus'].fillna('No')
sns.countplot(x='StudentStatus', data=korea)
plt.title('korean')
plt.show()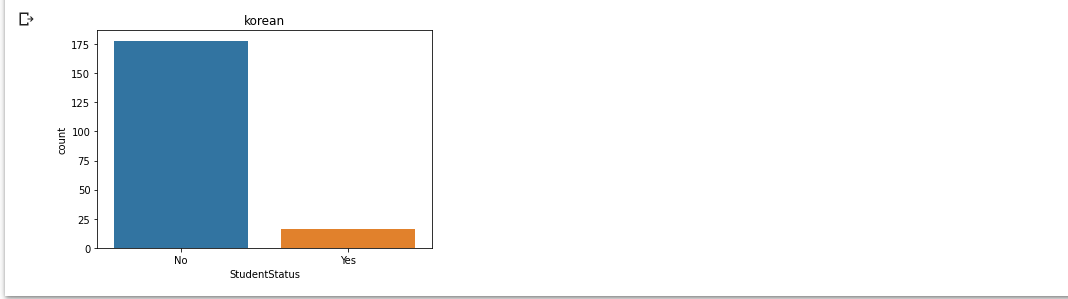
- StudentStatus 컬럼의 빈 부분에 대해선 임의로 'No'로 채워주었고 이를 시각화.
- No의 비율이 많아보이지만 이는 결측치를 다 No로 채워줬기 때문에 학생이 아닌 경우가 많다라는 결론을 내릴 순 없음

- loc은 보여지는 인덱스(컬럼명과, 인덱스 명)를 기준으로 필터링을 할 때 사용하고 iloc은 내부적인 인덱스를 기준으로 필터링 할 때 사용.
- boolean indexing을 할 땐 보통 loc을 사용.
- EmployStatus가 full-time인 것들로 subset을 만들었고 그 row size는 10897로 응답자 중 10897명이 풀타임 근무자임을 알 수 있다.
- 구직중인 사람의 경우 2110명!
- 구직중인 사람보단 풀타임 근무자가 더 많음을 알 수 있다.

Data science