제목은 하루에 하나지만... 심심할 때 혹은 그냥 하고싶을 때 업로드!
목표가 최소 하루에 하나 입니다!

def solution(strings, n):
answer = sorted(strings, key = lambda x: x[n])
for i in range(len(answer)-1):
tmp = answer[i]
if answer[i][n] == answer[i+1][n]:
if answer[i] > answer[i+1]:
answer[i] = answer[i+1]
answer[i+1] = tmp
return answer- 하나씩 차근차근 구현했습니다
- 우선 각 문자열의 원소의 n번째 원소로 정렬해야하므로 key에 x의 n번째 원소를 주어 정렬
- 정렬된 원소를 한 번씩 돌면서 다음 문자열과 n번째 원소가 같다면 둘을 비교해서 앞에 오는게
- 사전 순서상 더 뒤라면 둘의 교체를 해줬습니다.
- 이 방법은 만약 n번째 원소가 같은게 1 2 4 5 3 처럼 여러개 있다면
- 1,2 는 그대로, 2,4도 그대로, 4,5도 그대로, 5와 3만 바뀌어 12435로 정렬되기 때문에
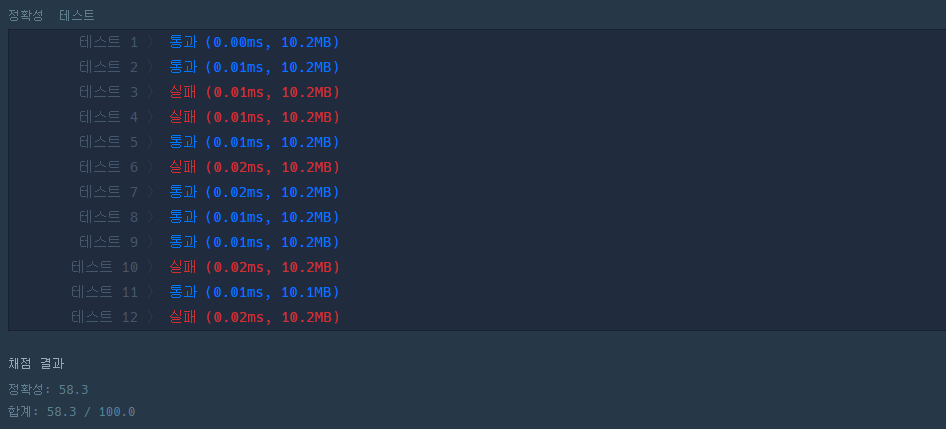
- 모든 상황을 고려해주지 않아서 아래처럼 100점을 받지 못했습니다. 이걸 다 고려해줘야 함!
def solution(strings, n):
answer = sorted(strings, key = lambda x: x[n])
lis = list(map(lambda x: x[n], answer))
for i in set(lis):
tmp = []
for idx, j in enumerate(lis):
if i == j:
tmp.append(idx)
if len(tmp) > 1:
answer[min(tmp): max(tmp)+1] = sorted(answer[min(tmp): max(tmp)+1])
return answer- 맨 처음 x[n]번째 정렬하는 건 그대로 두고 lis에 n번째 원소들만 리스트로 넣어줍니다.
- set(lis)를 해서 유니크한 x[n] 원소들로 for문을 돌고
- i와 j가 같은 경우 즉 x[n]이 같은 것끼리 인덱스를 모아둡니다
- 어차피 x[n]을 기준으로 정렬되어 있으므로 순서대로 쭉 뽑히게 됩니다.
- 또한 tmp에 인덱스를 다 모아주고, len(tmp)가 1보다 크다면 x[n]이 같은 문자열이 여러개 있는 것이므로 이런 경우에 sorted를 해서 그 부분만 다시 변경해줍니다. max(tmp)에 +1을 해준 이유는 max(tmp)를 제외하고 슬라이싱 해서 정렬하기 때문
- 맨 처음에 제대로 정렬되어 있다면 sorted를 괜히 하는 것이므로 효율성이 떨어지지만, 더 좋은 방법이 지금은 생각이 안나네요...
- sorted를 맨 처음에 하지말고 정렬 코드를 짠다면 더 효율적이지 않을까 싶습니다!

Data science