코딩테스트 연습
1.하루에 하나-1
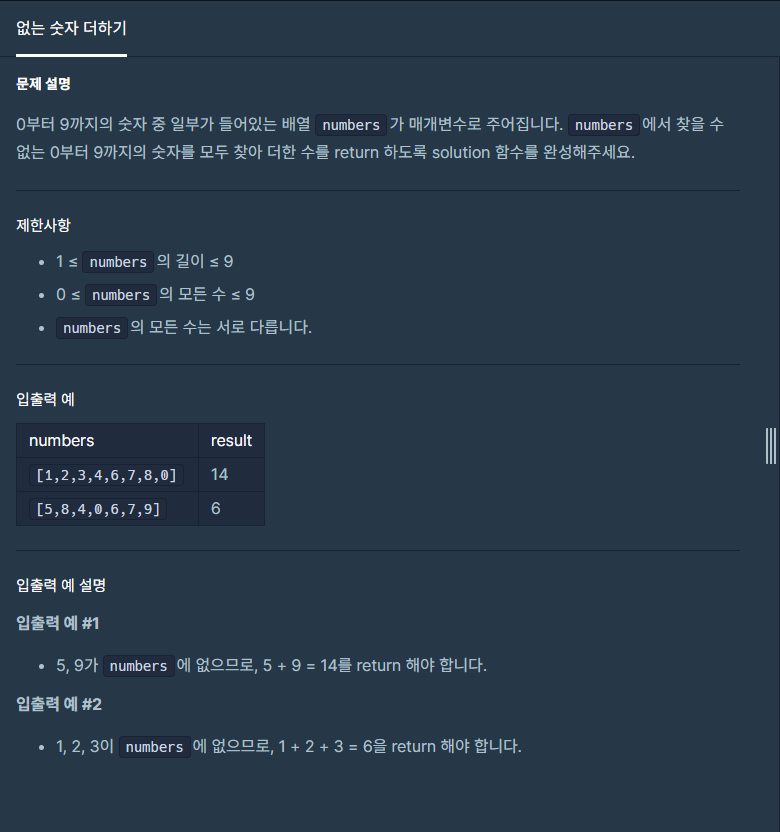
0~9 사이의 숫자 중 일부가 리스트로 주어지고중복되는 숫자는 없습니다. 이게 포인트0에서 9를 다 더하면 45. 45에서 numbers의 합을 빼면 존재하지 않는 숫자의 합!이런 문제들만 나온다면.... 너무나 행복할 것 같은데 말이죠...아무튼 재밌게 잘 풀었습니다
2.하루에 하나-2

하나씩 차근차근 구현했습니다우선 각 문자열의 원소의 n번째 원소로 정렬해야하므로 key에 x의 n번째 원소를 주어 정렬정렬된 원소를 한 번씩 돌면서 다음 문자열과 n번째 원소가 같다면 둘을 비교해서 앞에 오는게사전 순서상 더 뒤라면 둘의 교체를 해줬습니다.이 방법은 만
3.하루에 하나-3
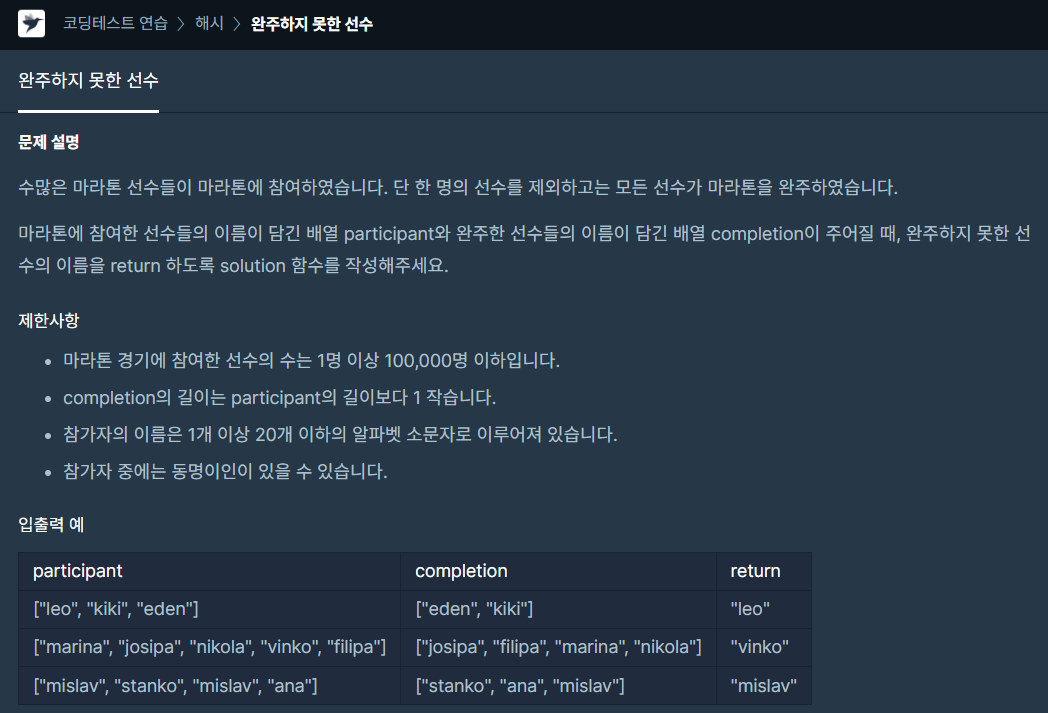
Python의 hash 함수를 이용누적된 hash value를 key로 dictionary를 생성했고 value와 각 참가자의 이름을 매핑완주자의 각 원소의 해시값을 누적. 해시값에서 계속 빼주면서 완주자를 하나씩 빼주는 것결국 누적 합에서 완주자에 있는 모든 원소의
4.하루에 하나-4(미해결)
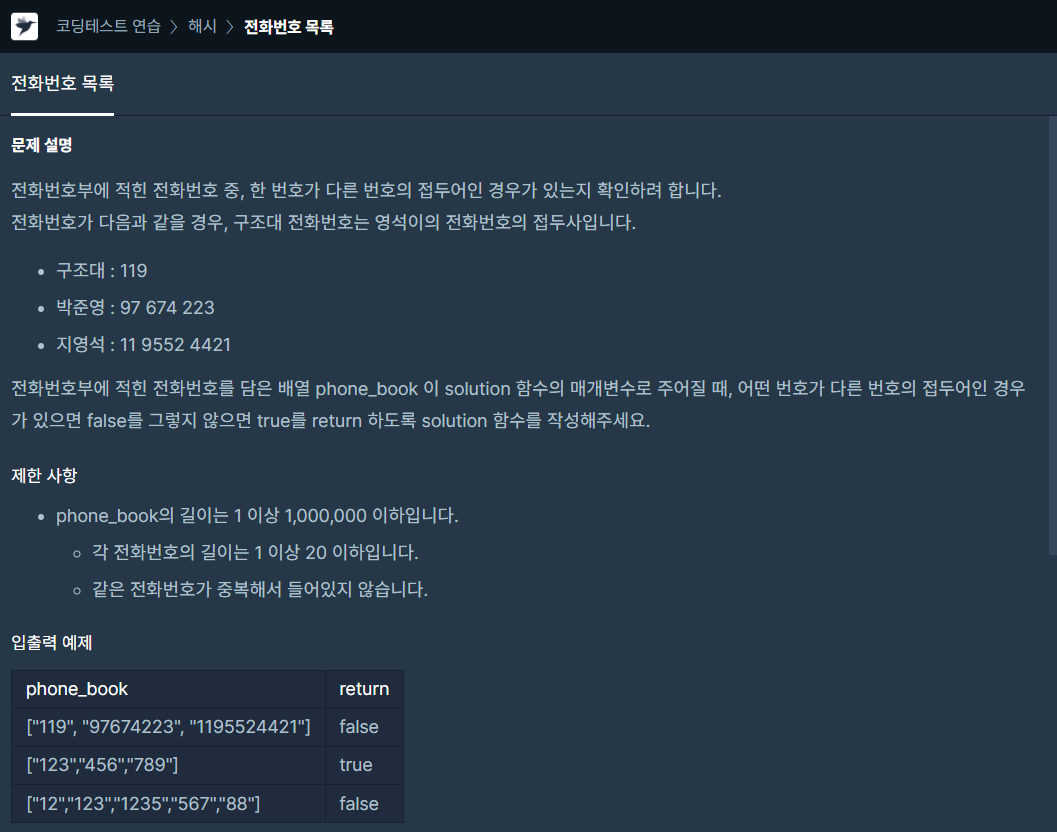
우선 구현을 해보기 위해 코드를 작성해봤습니다.phone_book 전체를 하나씩 돌면서 현재 원소를 tmp로 할당이후의 모든 원소들에 대해 tmp로 문자열이 시작되면 for문을 종료하고 answer는 False로. 우선 phone_book의 원소의 수가 최대 100만개
5.하루에 하나-5(미해결)
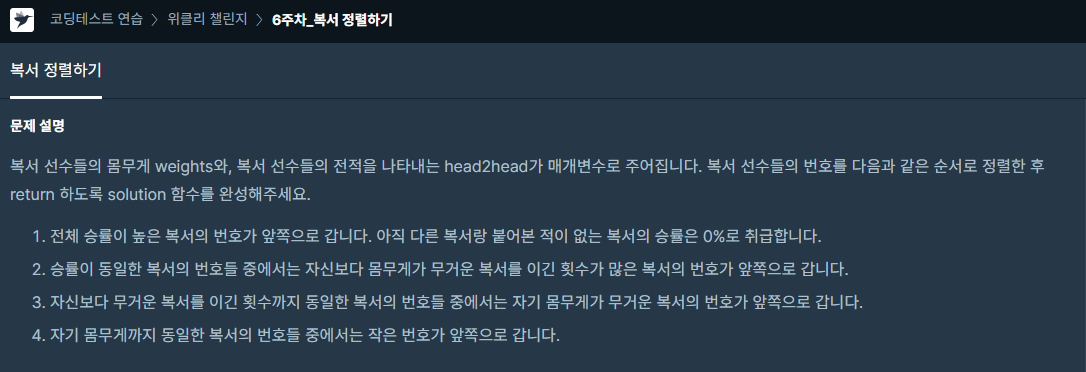
처음엔 sort에 대한 이해가 부족해서 아래와 같이 구현을 했습니다.우선 승리 횟수로 정렬하고, 제한 조건을 차례대로 구현이는 테스트 케이스에 대해서는 다 맞았지만, 100점이 되진 않았습니다. 정렬을 너무 어렵게 생각해 제대로 못한 것 같습니다.tmp에 복서번호, 승
6.하루에 하나-6
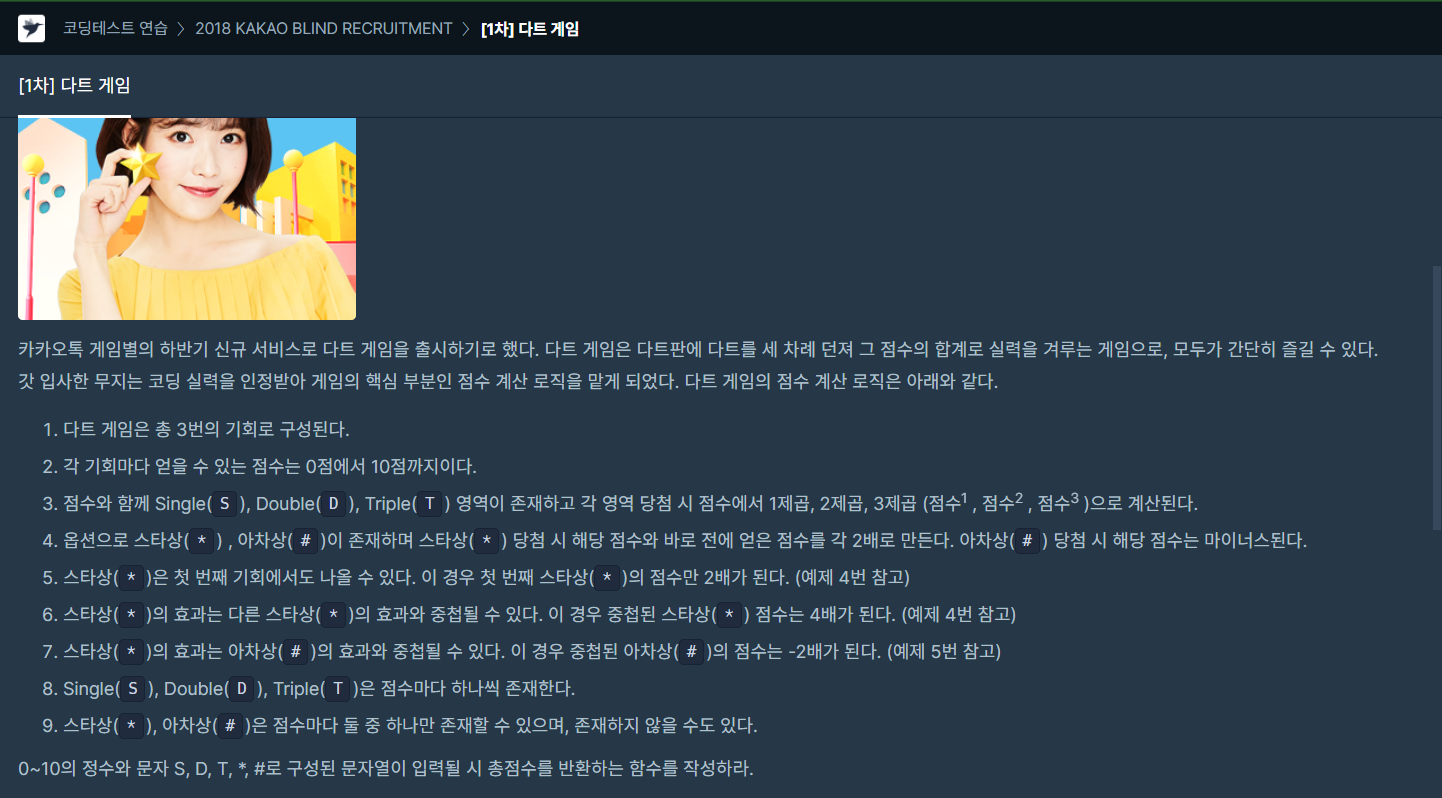
우선 점수|SDT|\*
7.하루에 하나-7
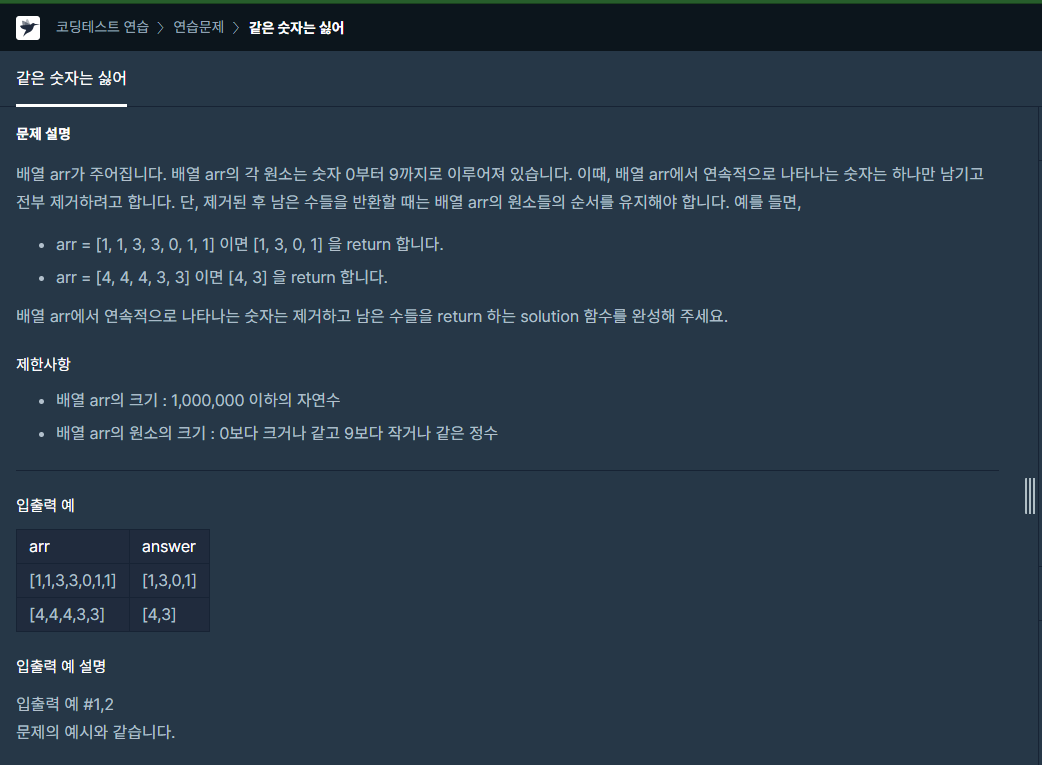
중복을 제거한다는 말에 바로 set을 생각했지만 순서가 보장되지 않아서 일단 패스순서를 가지는 set이 있다는 말을 친구에게 들었었는데, 검색을 해봐도 명확하게 나오는 게 없어서 우선 구현했습니다.arr이 $10^6$ 이하이므로 어차피 중첩 for문이 아니라서 괜찮겠다
8.하루에 하나-8
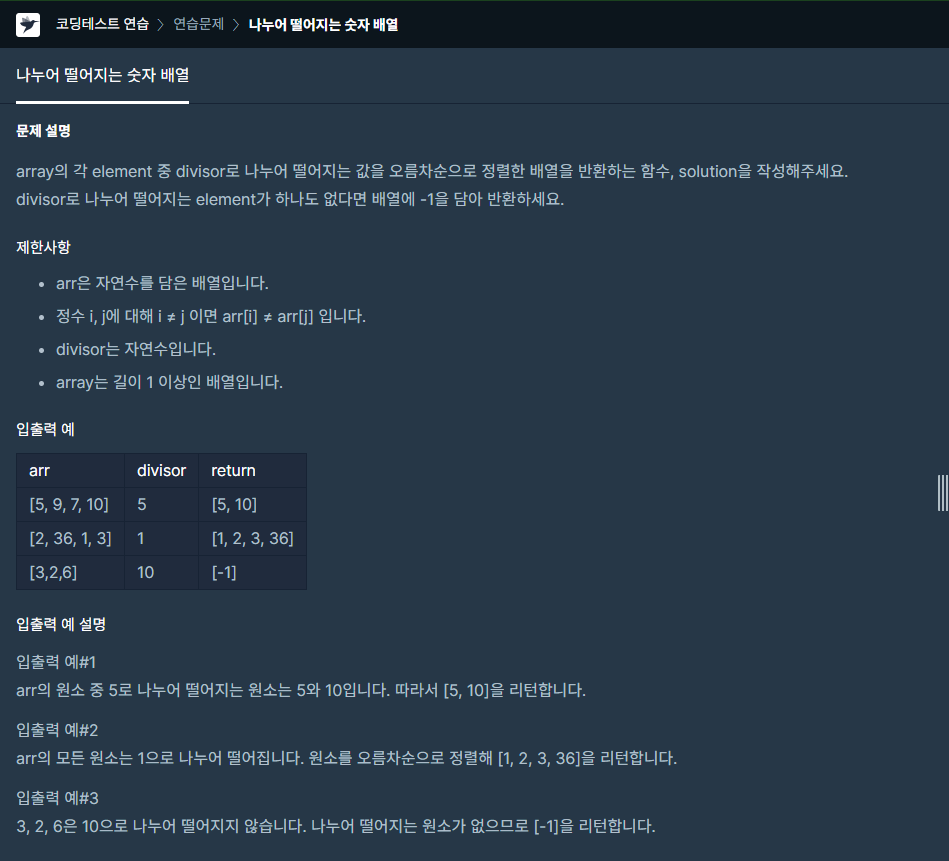
임의의 정수 i, j에 대해 i != j라면 arri != arrj 이므로 중복되는 숫자는 없습니다.list comprehension을 이용해서 divisor로 나눠 떨어지는 경우만 append 해줬고혹시 아무런 원소도 없다면 answer에 -1을 담아주고오름차순으로
9.하루에 하나-9
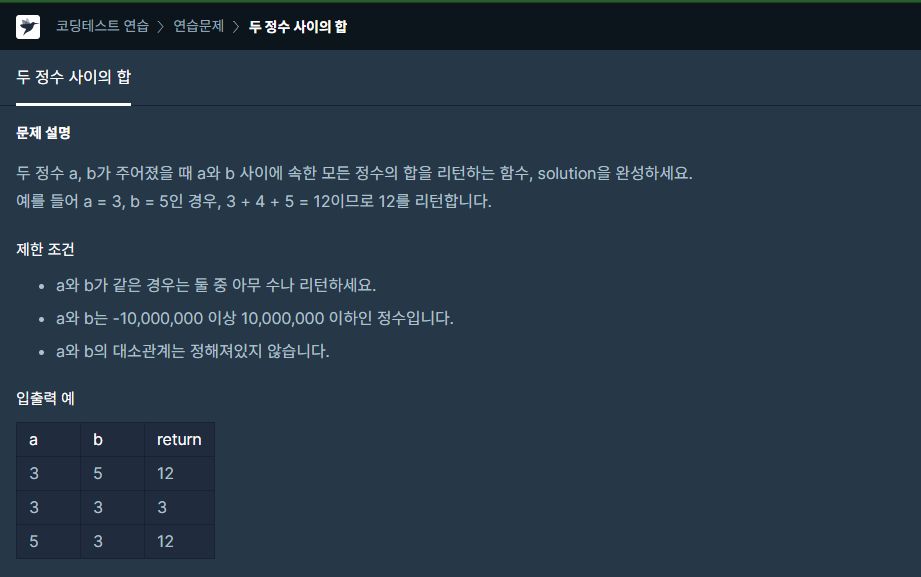
a가 b보다 큰 경우가 존재하므로 조건을 걸어 a<=b라면 a ~ b+1까지의 숫자를 합하고 a>b라면 b ~ a+1까지의 숫자를 합한 결과를 answer에 담아줬습니다.a or b보다 +1을 한 이유는 range(a, b)는 a에서 b-1까지만 return 하는
10.하루에 하나-10
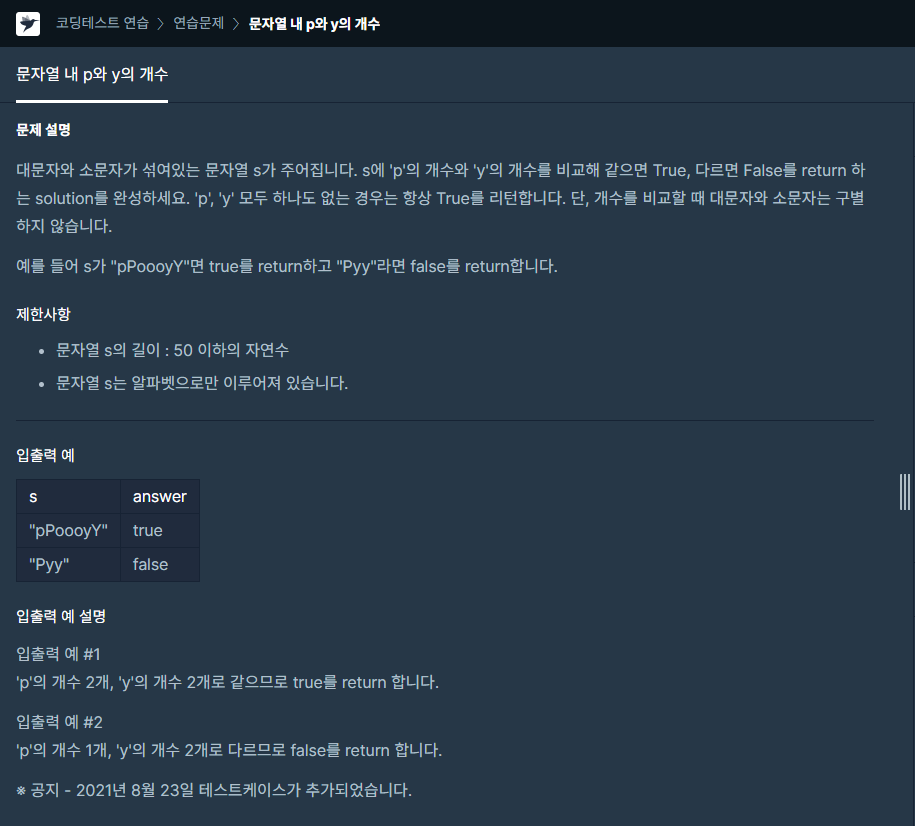
대소문자 상관없으므로 lower함수를 이용해 모두 소문자로 변경하고p엔 p의 개수, y엔 y개수를 할당해서 p와 y가 다르다면 False!맨 처음 answer를 True로 둔 이유는 p == y 혹은 p, y가 존재하지 않는 경우를 모두 고려해준 것!p != y인 경우
11.하루에 하나-11
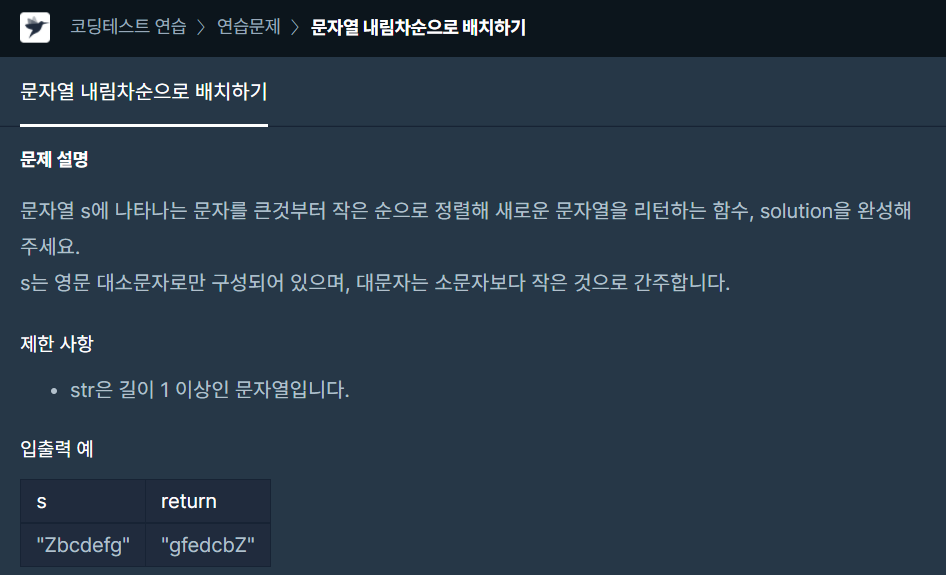
sorted를 이용해 내림차순으로 정렬해줬고, sorted의 결과는 문자열의 한 문자열을 원소로 갖는 리스트 형태로 return되기 때문에 '' 공백을 기준으로 join 해서 하나의 문자열을 return!
12.하루에 하나-12
1. int()를 이용하기 계속 테스트 케이스 5, 6 번이 틀리길래 왜 그런가 이유를 파악해보니 맨 처음 조건 문자열의 길이가 4 혹은 6을 빼먹었습니다..... 따라서, 4 or 6이라면 문자열 s를 int로 변환하고 된다면 answer는 True, ValueE
13.하루에 하나-13
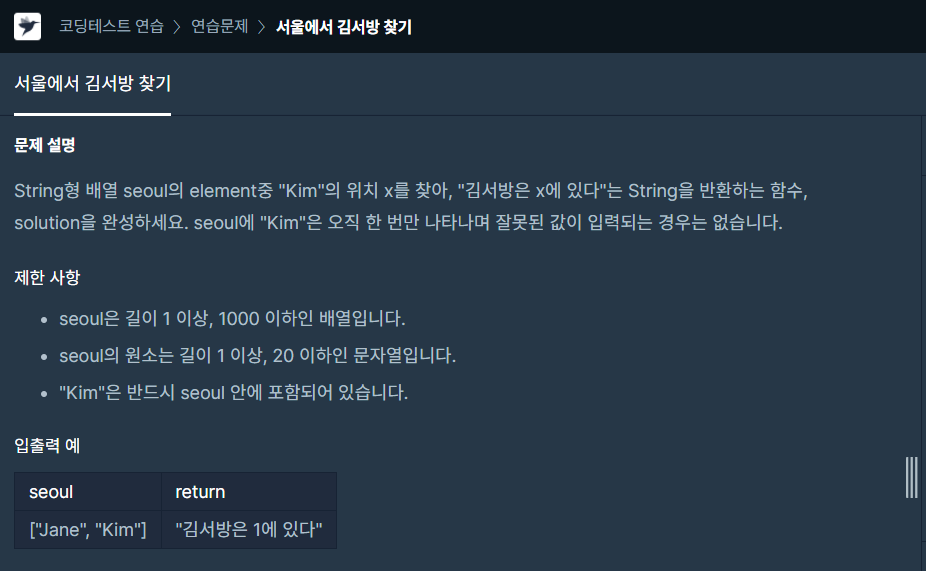
list의 index 함수를 이용해 'Kim'의 위치를 찾고 format함수를 이용해서 {} 안을 채워줌.Kim은 반드시 seoul 안에 있고, 중복은 없음!
14.하루에 하나-14(미완성)
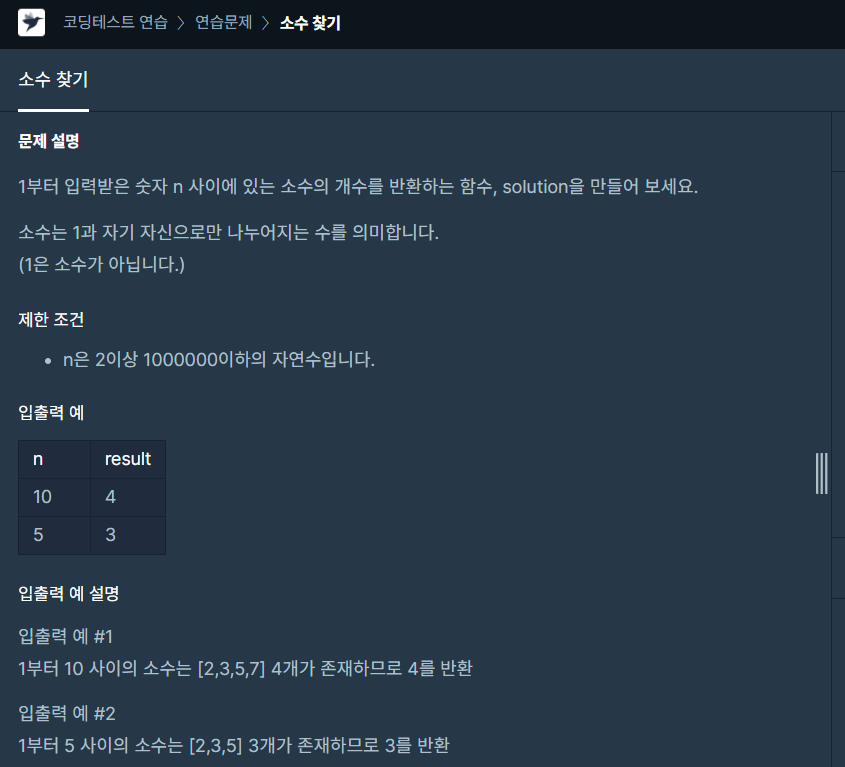
소수가 아닌 숫자를 찾아서 전체에서 빼주는 게 나을거라 생각했습니다.시간 복잡도가 for문 $O(n^2)$에 이중비교까지... 효율성은 개나 줘버렸습니다.구현도 제대로 하지 못했는데 이유가 뭘까요....우선 재귀함수를 써서 수정해보겠습니다!
15.하루에 하나-15
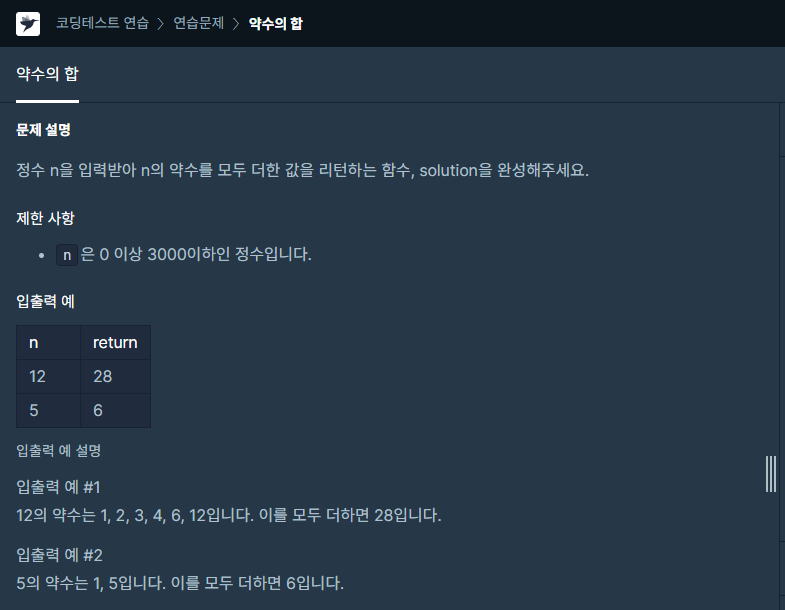
약수를 구해주는 모듈이 있지만, 사용하지 않고 풀었습니다.예를 들면 12의 약수라면 1, 2, 3, 4, 6, 12로 1, 2, 3 까지만 돌면 되고, 그 이후로는 어차피 12를 나눠준 몫이므로 굳이 돌 필요가 없습니다.따라서 sqrt(n)값의 내림을 한 값까지만 반복
16.하루에 하나 - 16
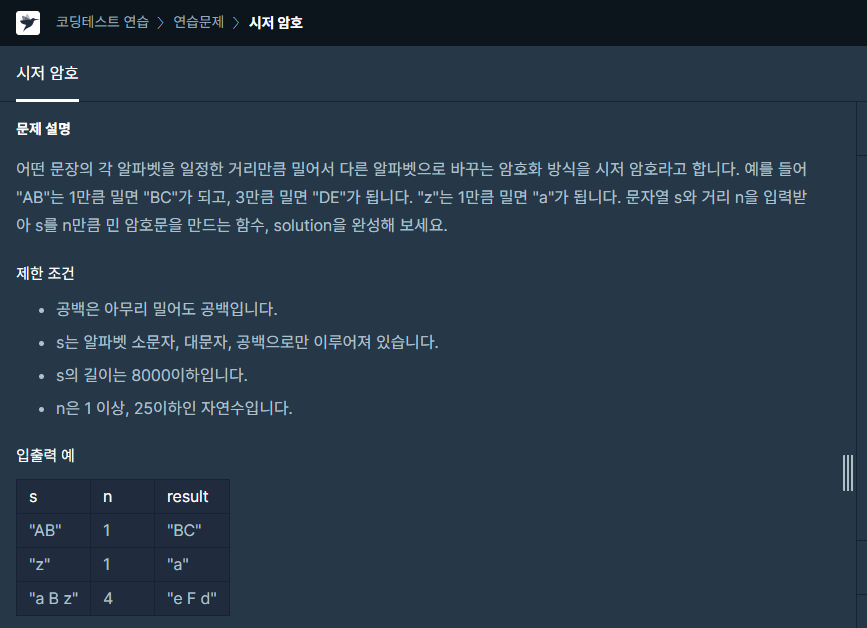
a~z까지 직접 입력해서 만들기보단 string의 ascii_lower, upper case를 이용했습니다.문자열 하나씩 돌면서 해당 문자열의 ascii의 index와 +n을 했고, z 다음은 a라고 했으니 26으로 나눈 나머지의 인덱스를 활용해 answer에 asci
17.하루에 하나-17
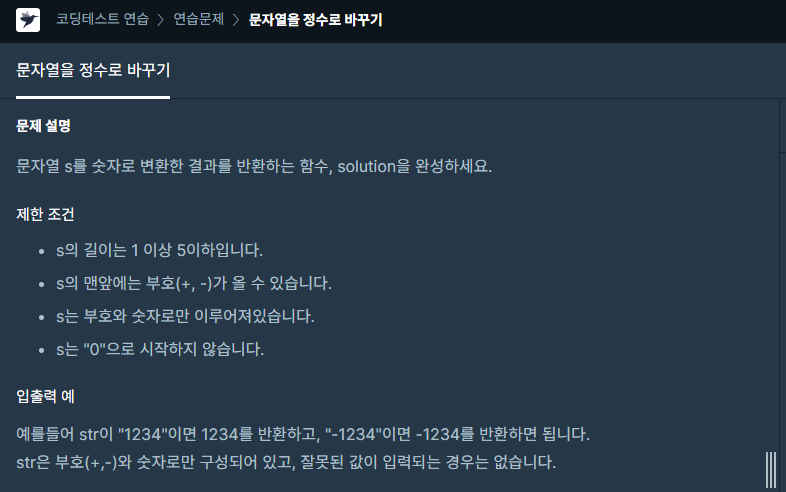
맨 앞에 + or -가 올 수도 있어 if~elif~else를 이용해 세 가지 경우를 구현했습니다.\+라면 그냥 int로 바꾸고, -라면 int에 -를 붙여주고, 아무것도 없다면 그냥 int(s).
18.하루에 하나-18
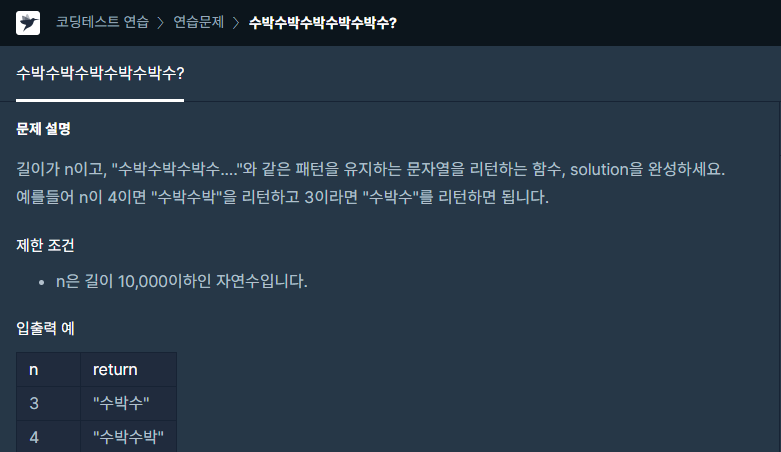
answer에 '수박'을 5000번 더한, 길이 10000짜리 수박수박...을 만들었습니다.후에 n까지만 슬라이싱!
19.하루에 하나-19
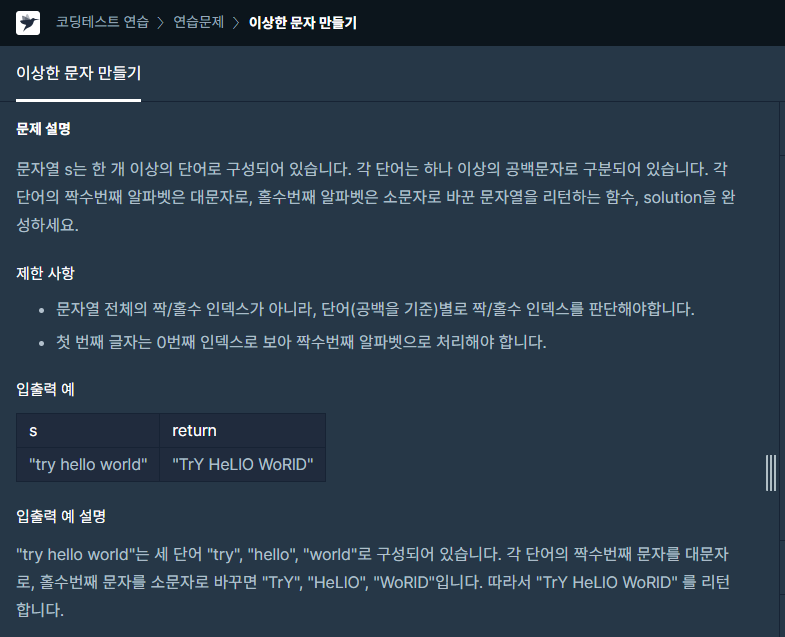
단어별로 짝수/홀수 인덱스 판별해야 하므로 공백을 기준으로 문자열을 나눴습니다.enumerate를 활용해 각 단어별로 문자열의 인덱스를 가져왔고 짝수인 경우엔 tmp에 st의 대문자를, 홀수인 경우엔 st의 소문자를 추가해줬고이를 리스트에 담아서 공백을 기준으로 joi