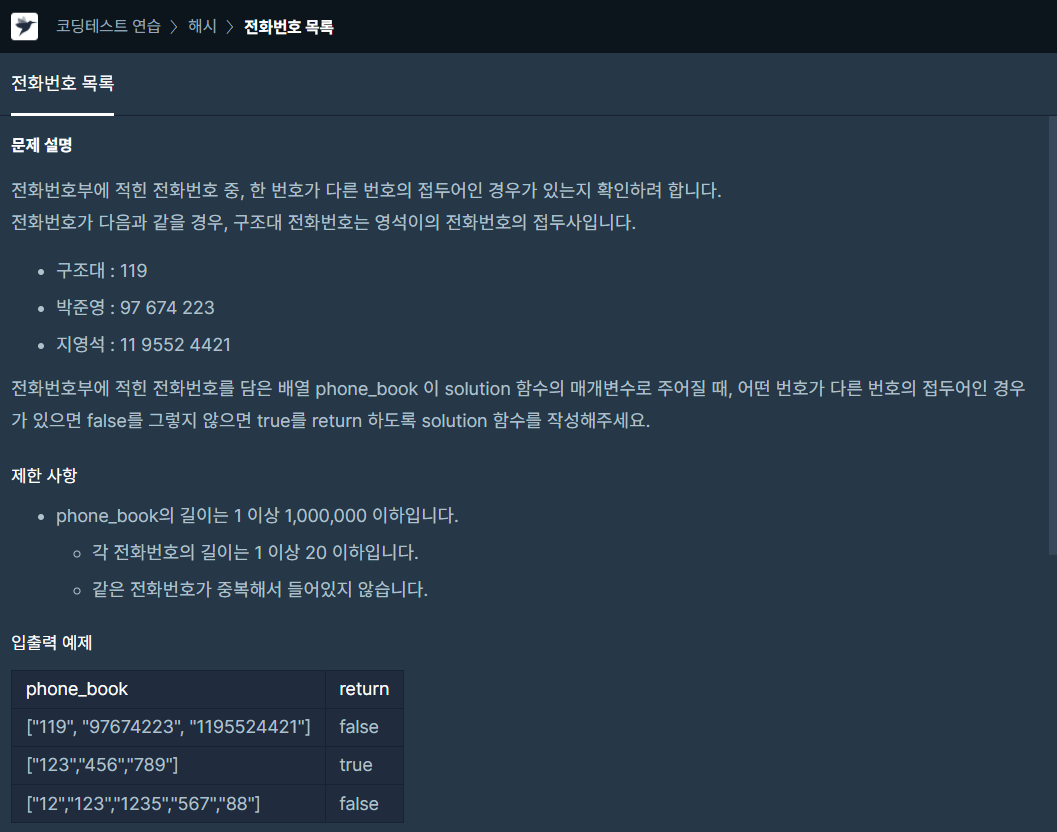
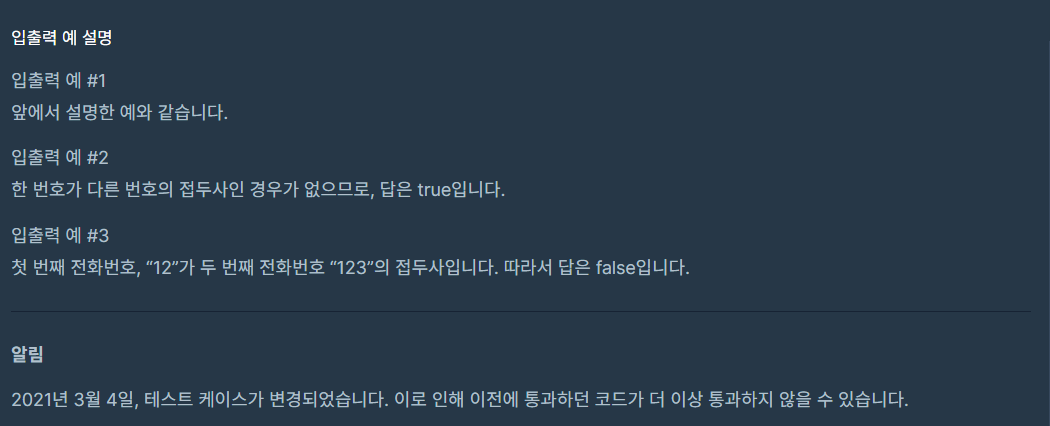
- 우선 구현을 해보기 위해 코드를 작성해봤습니다.
def solution(phone_book):
answer = True
for i in range(len(phone_book)-1):
tmp = phone_book[i]
for j in range(i+1, len(phone_book)):
if phone_book[j].startswith(phone_book[i]):
answer = False
break
return answer- phone_book 전체를 하나씩 돌면서 현재 원소를 tmp로 할당
이후의 모든 원소들에 대해 tmp로 문자열이 시작되면 for문을 종료하고 answer는 False로. - 우선 phone_book의 원소의 수가 최대 100만개. for문이 2중이면 . 12승이 이상하게 표현되네..
아무튼 상당히 시간복잡도가 올라가기 때문에 이 방법은 비효율적 - 아까 공부했던 hash를 이용해보자
- 각 원소의 중복도 없다고 했으므로!
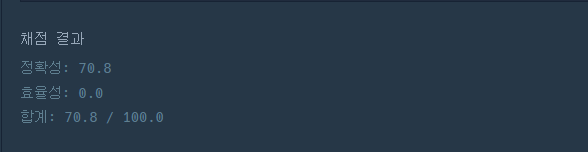
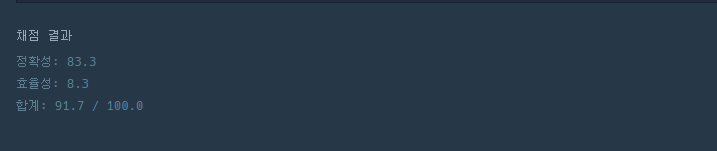
- 우선 구현도 제대로 못했다.... 100점이 아니므로.. 당연히 효율성은 0점!
def solution(phone_book):
phone_book = sorted(phone_book, key = lambda x: len(x))
tmp = set(phone_book)
answer = True
for i in phone_book:
tmp.remove(i)
for j in tmp:
if j.startswith(i):
answer = False
break
return answer
- 구현은 제대로... 하지만 효율은 여전히 0
- phone_book을 문자열의 크기 순으로 정렬해주고 for문을 돌면서 tmp에서 'i'를 제외한 set에 대해 반복을 돌면서 접두어인 경우는 False가 되고, break!
- j for문에 대해서만 break되는 것이고 i는 계속 돌아서 효율성은 당연히....
- 그래서 break 되는 순간 i도 break되도록 break를 또 추가해줌
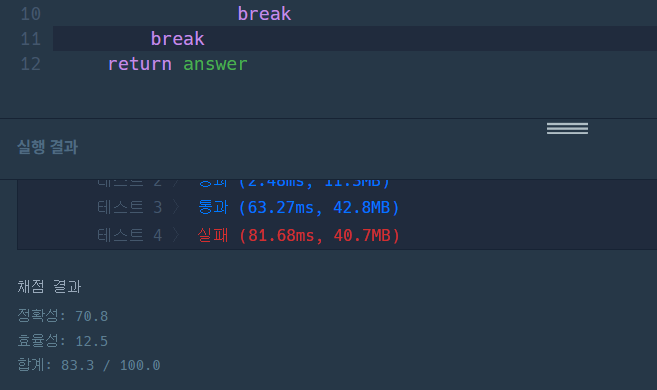
- 그랬더니 이번엔 또 정확하질 않네... hash table을 제대로 이용하지 못해서 그런게 아닐까...
- 리턴 바로 위에 저렇게 break를 넣어주면 다 돌지 않았음에도 원하는 조건이 되지 않아도 for문이 종료되어 안되는 것
def solution(phone_book):
phone_book = sorted(phone_book, key = lambda x: len(x))
tmp = set(phone_book)
answer = True
for i in phone_book:
tmp.remove(i)
for j in tmp:
if j.startswith(i):
answer = False
break
if not answer:
break
return answer- if 를 하나 더 걸어줘야 모든 조건을 다 맞는 코드가 된다.
- 구현은 제대로 되었지만, 효율성이 많이 부족하다. 왜냐면 phone_book은 최대 백만까지 길이를 가지므로 for문을 돌면 만약 정답이 True인 경우라면 최대 반복 두 번이므로 100만 * 100만의 시간복잡도에 100만번의 비교 + 100만번의 비교가 되므로 엄청 높은 복잡도를 초래.
따라서 효율성을 추구할 수 있도록 다른 방향을 생각해봐야함.

Data science