Kubernetes Architecture – From Docker Images to Running Pods
이번 chapter에서 배울 것은 다음과 같다.
- master 노드와 worker 노드의 차이
kube-apiservercomponentkubectlcli와 yaml 문법etcddata storekubelet과workernode componentskube-scheduler컴포넌트kube-controller-managercomponent
master와 worker 노드의 차이
kubernetes를 구동시키기 위해서는 linux machine이 필요하고 kubernetes에서는 이를 nodes라고 부른다. node는 물리적으로 존재하는 machine이 될 수도 있고, 가상 machine이 될 수도 있으며, EC2와 같은 클라우드 provider가 될 수도 있다.
kubernetes에서 node는 두 가지로 분류된다.
- Master nodes
- Worker nodes
Master nodes는 kubernetes cluster의 상태를 유지하는 책임을 가지고, Worker nodes는 개발자의 Docker container들을 실행하는 책임을 가진다. 어떤 기능을 가진 component이냐에 따라 component를 master node에 적재할 지 worker node에 적재할 지 결정할 수 있다.
기본적으로 kubernetes 자체는 하나의 monolithic한 app이 아니라, go로 만들어진 작은 프로젝트들이 모여 이루어진 분산 어플리케이션이다.
따라서, 완전히 동작하는 kubernetes cluster를 구성하기 위해서는 각 component들을 각각 설치하고 설정(configuring)하여 이들끼리의 통신이 잘 이루어지는 지 확인해야한다. '설치(installing)'와 '설정(configuring)' 요구사항이 만족하면 kubernetes를 사용하여 개발자의 container를 실행할 수 있다.
이러한 kubernetes의 component들은 하나의 원격 서버에 모두 적재되는 것이 아니라, 분산적으로 여러 개의 원격 서버, 또는 host에 배포되어 하나의 cluster를 이루는 것이 kubernetes cluster를 좀 더 가용성 좋게 만든다. 또한, 이러한 경우 fault-tolerant하게 되며, component들이 서로 간의 직접적인 영향을 주지않아 scalable한 특징을 가질 수 있다.
즉, 원격 서버에 나누어 component들을 배포하여 kubernetes cluster를 운영하면 하나이 서버가 down된다고 하여도, 전체 cluster가 down되는 것이 아닌, 일부만 down되며 이 경우는 새로운 서버를 동적으로 올려주면 cluster가 금방 복구된다.
각 kubernetes component들은 각각의 책임과 기능을 담당하고 있기 때문에 이를 아는 것은 매우 중요하다. 또한, 각 component들은 자신의 책임과 기능에 따라 master node에 배포될 지 worker node에 배포될 지 결정된다. 즉, 일부 component들은 전체 cluster의 상태를 유지하고 cluster 자체를 실행하는데 쓰이는 반면, 일부는 docker daemon과 직접 통신함으로서 개발자의 application container들을 실행하는데 사용된다. 따라서 kubernetes의 component들은 다음과 같이 두 가지 그룹으로 맵핑된다.
-
Control Plane: 해당 component들은 cluster의 상태를 유지하는 역할을 담당하므로, master node에 설치되어야 한다. 'control plane'는 kubernetes cluster에 의해 실행되는 container 리스트를 또는 cluster의 일부인 machine의 수를 유지하는 구성 요소이다. 관리자로서, kubernetes와 상호작용을 한다면 이는 control plane component들과 상호작용하는 것이다.
-
Worker Nodes: control plane component들로부터 받은 명령들에 따라 container들을 launch시키기 위해 Docker daemon과 상호작용하는 역할을 가진다. Worker node component들은 Docker machine이 실행되고 있는 linux machine에 설치되어야 한다. 개발자가 직접적으로 worker node와 상호작용하는 일은 거의없을 것이다. workder node는 kubernetes cluster의 개발자 application container를 실행하는 부분이기 때문에 master node보다 훨씬 많고, 하나의 kubernetes cluster에 여러 개의 worker node가 있을 수 있다.
정리하자면, master node는 관리자(사용자)로부터 받은 명령어에 따라 모든 operational task들을 담당하고, cluster의 관리를 담당한다. worker node는 master node로 받은 명령들을 기반으로 실제적인 workload의 실행을 담당한다.
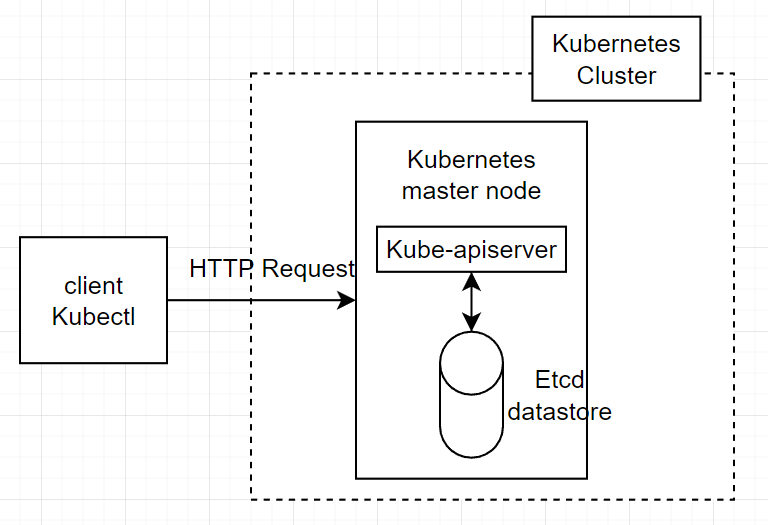
kubernetes를 사용하게 된다면 직접적으로 docker 명령어를 쓰지 않아도된다. 사용자는 master node에게 명령을 보내고 명령을 위임받은 master node가 worker node로 docker를 사용하라는 명령을 보내기 때문이다.
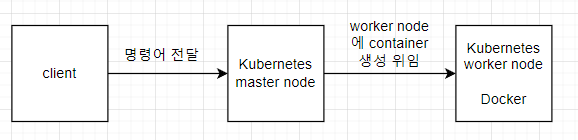
위의 그림과 같이 client와 worker node 간에는 어떠한 직접적인 상호작용이 없다.
control plane와 master node 개념은 'kubernetes cluster의 관리'라는 측면에서 거의 똑같다. 그러나, kubernetes에서는 control plane라는 말을 더 자주 사용하는데, 이유는 master node라는 말이 자칫 control plane component들으 하나의 machine에 묶어 설치한다는 말처럼 느껴지기 때문이다.
kubernetes는 분산시스템으로 control plane component는 실제로 여러 개의 machine에 나뉘어 실행이 가능하다. 즉, master node가 여러 개의 multiple machine으로 나누어 실행될 수도 있다. 하나의 control plane component가 죽는다고 해서 clustr 전체가 다운되지 않는다. 이러한 fault tolerant한 특성이 바로 kubernetes의 큰 특징이다.
control plane component들은 각각 서로 다른 host에 설치할 수 있고, 서로 상호작용이 가능하다. 이후에, 매우 advanced한 상황이지만 worker node machine에 control plan component들을 나누어 분산 설치할 수 도 있다. 이러한 특징 때문에 kubernetes에서 master node보다는 control plane라는 말을 더 선호하는 것이다.
workder node의 경우에 더 간단하다. Docker를 실행하는 machine를 구동하고, worker node component들을 Docker runtime에 설치하면 된다. 이러한 component들은 machine에 설치된 local container engine과 인터페이스 작업을 하고, 사용자가 control plane component들에게 전달한 명령어에 따라 container들을 실행할 것이다. 개발자는 worker node machine 덕분에 kubernetes로 부터 Docker의 모든 것들을 제어할 수 있다. 가령, container 생성, network 관리, scaling containers 등등이 있다. 단지 worker node를 추가함으로서 cluster에 더욱 더 많은 computing 자원을 줄 수 있다.
서로 다른 시스템의 control plane와 worker node components를 분리함으로써, cluster를 더욱 available하게 만들고 scalable하게 만든다. kubernetes는 모든 cloud-native 문제들과 함께 만들어졌다. component들은 stateless하고, scale하기 쉬워야 하며, 서로 다른 host사이에 분산되어 빌드되어야 하는 문제 등이 있다. 이를 위해 같은 host에 모든 component들을 그룹핑함으로서 버그를 발생시키지 않도록 만드는 것이다. 같은 host라 하여도 사실은 여러 개의 host에 따로 배포된 component를 가상의 host 한 개로 묶어둔다는 것을 말한다.
아래는 모든 control plane component들이 하나의 master node machine에 설치된 모습을 보여준다.
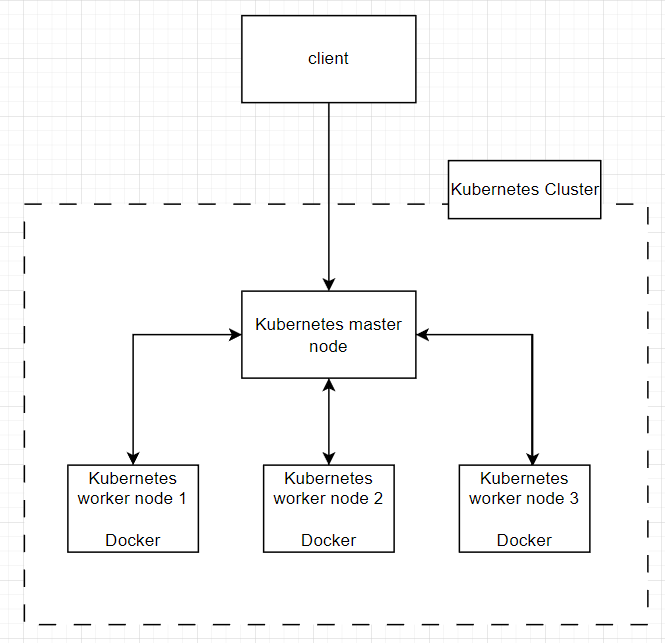
한 개의 master node와 3개의 worker node로 이루어져 있다.
아래는 kubernetes component들이다.
| Component name | Control plane, worker node or client |
|---|---|
| Kube-apiserver | Control plane(master node) |
| Etcd | Control plane(master node) |
| Kube-scheduler | Control plane(master node) |
| Kube-controller-manager | Control plane(master node) |
| Kubelet | Worker node |
| Kube-proxy | Worker node |
| Container Engine(Docker ... ) | Worker node |
| Kubectl | client |
kubernetes는 버전에 따라 변화하기도 하고, Amazon EKS나 Red Hat Openshift 등 여러 가지 다양한 버전들이 있다. 우리가 다룰 것은 bare kubernetes으로 위의 kubernetes component list들이 default으로 이들이 kubernetes의 backborn이다.
위 리스트 중에 kube라는 접두사가 붙지 않은 것이 두 개 있는데, Etcd와 Container Engine(docker...)은 명확히 말하자면 kubernetes 프로젝트 자체가 아니라 외부의 dependency이기 때문에 kube라는 접두사가 붙지 않은 것이다.
Etcd: kubenetes project에서 쓰이는 third party database이다.container runtime: third-party engine으로CRI-O,Docker Engine등이 있다. 우리는 docker를 사용한다. (사실상 'docker engine'이나 'containerd'는 같다. 실제로 docker는 하나의 플랫폼으로서의 기능을 한다는 의미로 kubernetes는 1.20부터 docker를 사용하지 않고 containerd를 사용한다.)
kube-apiserver component
kube-apiserver는 kubernetes에서 가장 중요한 component이다. kube-apiserver는 REST API로 kubernetes의 모든 feature들을 노출시킨다. client는 직접 REST API를 호출하지않고 kubectl cli를 사용하여 kub-apiserver REST API를 호출함으로서 kubernetes와 상호작용 할 수 있다.
kube-apiserver는 control plane의 파트를 차지하는 component이며, master node에 설치되고, 실행된다. kube-apiserver는 kubernetes에서 굉장히 중요한데, 일부는 이를 kubernetes 그 자체라고 여긴다. 그러나, kube-apiserver는 단순히 orchestrator의 한 component일 뿐이다.
go로 구현되어있고, 오픈소스로 github에 hosting되어 있다.
kubernetes의 동작은 굉장히 단순한데, client가 kubernetes에 명령을 내리려면 HTTP request를 kube-apiserver에 전달해야한다. 즉, client가 container의 생성, 삭제, 수정을 원한다면 kube-apiserver의 REST API endpoint를 호출함으로서 실행할 수 있다.
kube-apiserver는 orchestrator와 관련된 모든 operation에 대한 단일 entry point 역할을 한다. 이는 client가 직접 docker daemon과 상호작용 하지않도록 만드는 좋은 방법으로, client는 kube-apiserver에 HTTP request를 전달하여 docker daemon에 관한 명령어를 실행하면 된다.
그림으로 표시하면 다음과 같다.
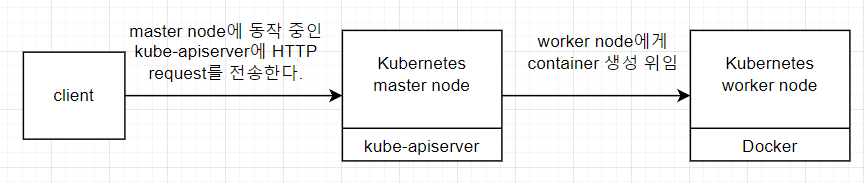
kube-apiserver는 그저 REST API server에 불과하다. 또한, stateless이며 resource들에 대한 상태는 Etcd라 불리는 database engine에 의존한다. 이는 kube-apiserver를 horizontally하게 scale할 수 있다는 것인데, 즉, 어러 개의 machine에 나누어 배포함으로서 7 layer load balancer를 사용해 데이터의 손실없이 최적화를 이루어낼 수 있다.
client에서 직접 kube-apiserver REST API를 호출하진 않는다. 공식적으로 지원하는 kubectl cli를 통해 kube-apiserver를 호출하고 kubernetes와 상호작용 할 것이다. 또한, kube-apiserver는 유저를 위한 resource가 아니라, container들을 관리하는데 필요한 것들이다. 따라서, kube-apiserver에서 찾을 수 있는 resource들은 일반적으로 container 관리와 networking 그리고 computing과 관련되어 있다.
해당 resource를 정리하면 다음과 같다.
- Pod
- ReplicaSet
- PersistentVolume
- NetworkPolicy
- Deployment
물론 이외에도 더 있다.
kubernetes는 'container' resource를 따로 두지 않는데, 'container'들을 관리하기 위해 'pod'라고 불리는 자원을 만들었기 때문이다. 'pod'는 container들이 한 개 이상있는 하나의 resource이다. 이에 대해서는 다음 chapter에서 더 자세히 배워보도록 하자.
각 resource들은 전용 URL 경로와 연결되고, HTTP 메서드를 변경하여 다양한 효과를 줄 수 있다. 이 모든 behavior들은 kube-apiserver와 관련되어있다.
kubernetes object들이 Etcd database에 저장된 후에, 다른 kubernetes component들은 이러한 object를 'raw Docker 명령어'로 변경한다. 이러한 방식으로 Docker daemon은 Etcd datastore에 저장될 수 있고, kube-apiserver에서 설명하는 cluster의 상태를 미러링 할 수 있는 것이다.
한 가지 더 kube-apiserver에 관해서 중요한 점은 kube-apiserver가 모든 cluster에 대한 단일 진입 지점(single entry point)라는 것이다. 즉, kubernetes에 관한 모든 것들이 kube-apiserver를 주위로 설계되었다는 것이다. client는 정말 드문 케이스를 제외하고, 대부분의 경우 kubernetes cluster에 직접 접근하는 것이 아닌 kube-apiserver REST API를 호출한다는 것이다.
kube-apiserver는 단지 cluster의 상태만을 관리하는 것이 아니라, 인증, 인가 그리고 HTTP 응답 포맷팅에 관한 여러가지 다른 메커니즘을 가진다. 따라서, 직접 kubernetes를 다루는 것은 좋은 아이디어가 아니다.
kubernetes cluster를 설치하면 자동으로 설치되는데, 직접 설치할 수 있는 방법도 있다.
먼저 kube-apiserver 파일을 인터넷에서 가져온다.
wget -q --show-progress --https-only –timestamping https://storage.googleapis.com/kubernetes-release/release/v1.14.0/bin/linux/amd64/kube-apiserverkube-apiserver를 제대로 실행하기 위해서는 다른 kubernetes component들도 필요하다. 그러나, 실행만을 시킬 수 있는데, linux에서 default로 사용 가능한 daemon 관리 tool인 systemd를 사용하여 kube-apiserver를 실행할 수 있다. 다만, 이렇게까지해서 실행하는게 좋은 방법은 아니니, 따라하지 말도록 하자.
- 먼저 다음의 경로에 파일을 하나 만든다.
etc/systemd/system/kube-apiserver.service - 파일에 다음의 내용을 추가한다. 기본적으로 이
systemdunit file은 위에서 우리가 설치한 kube-apiserver 바이너리를 configuration과 함께 실행한다.
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-apiserver
--advertise-address=${INTERNAL_IP}
--allow-privileged=true
--apiserver-count=3
--audit-log-path=/var/log/audit.log
--authorization-mode=Node,RBAC
--bind-address=0.0.0.0
--client-ca-file=/var/lib/kubernetes/ca.pem
--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota
--etcd-cafile=/var/lib/kubernetes/ca.pem
--etcd-certfile=/var/lib/kubernetes/kubernetes.pem
--etcd-keyfile=/var/lib/kubernetes/kubernetes-key.pem
--etcd-servers=https://10.240.0.10:2379,https://10.240.0.11:2379,https://10.240.0.12:2379
--encryption-provider-config=/var/lib/kubernetes/encryption-config.yaml
--kubelet-certificate-authority=/var/lib/kubernetes/ca.pem
--kubelet-client-certificate=/var/lib/kubernetes/kubernetes.pem
--kubelet-client-key=/var/lib/kubernetes/kubernetes-key.pem
--kubelet-https=true \\
--runtime-config=api/all \\
--service-account-key-file=/var/lib/kubernetes/service-account.pem \\
--service-cluster-ip-range=10.32.0.0/24
--service-node-port-range=30000-32767
--tls-cert-file=/var/lib/kubernetes/kubernetes.pem
--tls-private-key-file=/var/lib/kubernetes/kubernetes-key.pem
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target- unit file이 만들어졌다면
systemddaemon을 reload하도록 하고, 새로운 service를 실행한다.
systemctl daemon-reload
systemctl enable kube-apiserver
systemctl start kube-apiserver절대 예제는 참고만하고 동작하지 말도록 하자. 여러가지 부족하여 제대로 동작하지 않을 수 있다.
kubectl cli와 yaml 문법
kubectl은 kubenetes에서 client가 kubernetes와 상호작용하기 위해 사용되는 공식 cli tool이다. 사용하려면 local machine에 설치해야하지만, 설치는 kubernetes cluster를 설치한 이후에 해보고, 지금은 role을 이해하는데 집중해보도록 하자.
kubectl은 http client로 kubernetes와 상호작용하기 위해 최적화되어있으며 kubernetes cluster에게 command를 발행한다.
kubectl의 역할
직접 kube-apiserver REST API를 호출하는 것은 매우 어려운 일이고, 기억하기 쉽지 않다. 때문에 kubectl을 사용하여 복잡하고 다양한 kube-apiserver의 REST API를 대신 호출하는 것이다.
또한, kubectl은 인증과 관련된 kubernetes layer를 관리하며, cluster의 context와 그 이상을 관리한다.
kubectl을 호출하면 parameter들을 읽고 이에 기반하여 HTTP request를 kube-apiserver에 전달한다.
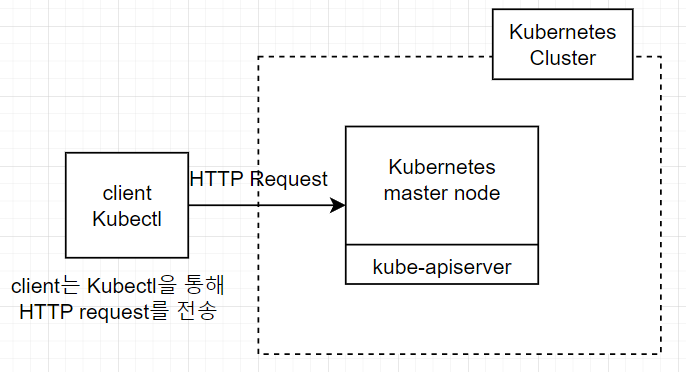
kubectl을 통해서 kube-apiserver의 REST API 호출하면 kube-apiserver에서 client가 전달한 요청에 기반하여 cluster의 상태를 수정한다. 만약, 명령어가 쓰기 연산과 관련되었다면, 가령 실행중인 container의 image를 변경하는 것이라면 kube-apiserver는 Etcd에 있는 cluster의 상태를 변경한다. 그 다음 image가 변경된 container가 호스팅된 worker node에 실행중인 component는 새로운 image에 기반한 새로운 container를 만들기위한 적절한 Docker 명령어를 발행할 것이다. 따라서, Docker daemons의 실제 state는 항상 Etcd에 있는 state를 반영한다.
개발자가 kubernetes 상에서 Docker와 직접적으로 상호작용 할 일이 없고, Etcd를 건드릴 필요없다는 것을 알면, kubernetes를 다루는 대부분은 kubectl에 기반한 다는 사실을 알 수 있다.
kubectl의 동작
kubectl 명령어를 호출하면, kubectl에서는 $HOME/.kube/config 파일의 configuration을 읽으려고 시도한다. 해당 configuration 파일은 kubeconfig라고 불린다.
해당 configuration에서는 kube-apiserver의 endpoint와 port들이 있고, kube-apiserver에 인증을 하기위해 사용되는 client certificate도 있다. 해당 config파일의 위치는 변경할 수 있는데, 다음은 KUBECONFIG와 --kubeconfig 파라미터를 사용함으로서 위치를 변경하는 방법이다.
export KUBECONFIG="/custom/path/.kube/config"
kubectl --kubeconfig="/custom/path/.kube/config"kubectl 명령어를 매번 사용할 때마다 kubectl cli tool은 kubeconfig 파일을 확인하여 configuration을 다음의 순서로 로드한다.
- 먼저,
--kubeconfig파라미터가 설정되었는 지 확인하고, 설정되었다는 해당 위치의 config file을 가져온다. - 만약
kubeconfig에서 config 파일이 발견되지 않았다면, kubectl은KUBECONFIG환경 변수에서 확인한다. - 만약 둘 다 실패하면
/.kube/config에서 config파일을 가져온다.
현재 local kubectl 설치에 사용된 config file을 보기위해서는 다음의 명령어를 입력하면 된다.
kubectl config viewkubeconfig파일은 kubernetes cluster와 interact하기 위해서 kubernetes cluster에 대한 다양한 정보를 가지고 있다. 해당 정보는 kube-apiserver의 URL을 포함하고, kube-apiserver에 대한 설정된 인증 유저 정보를 가지고 있다. 이 정보를 바탕으로 kube-apiserver에 대한 REST API를 호출하는 것이다.
다음의 명령어는 가장 많이 사용할 kubectl 명령어이다.
kubectl get pods위의 명령어는 Pods 리스트를 호출하는 명령어이다. 사실 해당 명령어는 GET 요청으로 kube-apiserver에 전달하는 것으로 cluster에 있는 container(pod)의 list를 호출하는 것이다. kubectl은 pod에 관련된 URL path인 /api/v1/pods로 kube-apiserver에 GET 요청을 전달하는 것이다.
여기 다른 명령어가 있다.
kubectl run nginx --restart Never --image nginx다음의 명령어는 kubectl에서 Docker hub에 있는 nginx라는 image에 기반하여 nginx라는 container의 creation을 POST요청으로 전달하는 것이다. 사실 해당 명령어는 container를 만든다기 보다는 pod를 만드는 것이다.
YAML syntax
kubectl은 두 가지 문법을 지원한다.
- imperative syntax(명령형 문법)
- declarative syntax(선언형 문법)
기본적으로 imperative syntax는 kubectl 명령어를 shell session에 실행하는 방법이다. sub-commands와 argument들을 전달함으로서 kube-apiserver component에 대한 명령어를 호출할 수 있다. 다음의 kubectl명령어들은 일단 실행되면 주어진 kube-apiserver endpoint에 대하여 HTTP request를 발행한다.
- 해당 명령어는
busybox:latest라는 Docker image에 기반하여my-pod라 불리는 pod를 만든다.
kubectl run my-pod --restart Never --image busybox:latest- 다음의 명령어는
my-namespace에 있는 모든RepolicaSetresources를 리스트로 보여준다.
kubectl get rs -n my-namespace- 다음은 default namespace에서
my-pod라는 pod를 삭제하는 명령어이다.
kubectl delete pods my-podimperative syntax는 간단하고, 쓰기 편하다는 장점이 있다. 다만, 수많은 명령어를 외워야 하고, 단계에 따라 cluster의 상태를 변경해야하는 경우는 기억하기 쉽지않다는 문제가 많다.
이러한 문제 때문에 imperative syntax는 디버깅 용으로 많이 사용되고, declarative syntax 문법이 배포나 개발에 있어 많이 사용된다. declarative syntax는 json또는 yaml로 쓰여진 파일을 사용하며, kubectl명령어로 실행할 수 있다. kubernetes에서는 json보다는 yaml이 자주 사용되며, yaml을 중심으로 설명하도록 하겠다.
declarative syntax으로 kubectl명령어를 사용하려면 disk에 yaml format으로 쓰여진 파일을 만들어야 한다. 해당 파일의 key:value 쌍으로 수정하고 싶거나, 생성하고 싶은 kubernetes resource를 설정하면 된다.
다음은 imperative command를 통해 busybox:latest라는 Docker image를 가지는 my-pod라는 pod를 만드는 방법이다.
kubectl run my-pod --restart Never --image busybox:latest위와 똑같은 기능을 하는 declarative syntax은 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: busybox-container
image: busybox:latest다음의 파일을 pod.yaml으로 저장하고 다음의 명령어로 pod를 생성해주도록 하자.
kubectl create -f pod.yamlpod가 생성될 것이다.
각 kubernetes에서 사용되는 yaml file은 반드시 포함되어야 할 필수적인 key들이 있다.
apiVersion: 선언되는 자원의 API veersion에 대해 기재하는 부분이다. 각 resource type은apiVersionkey를 가지며 이는 반드시 설정되어야 한다. 우리의 pod resource type은 API version이v1인 것이다.Kind:kind필드는 YAML file에서 만들 resource type이 무엇인 지를 알려준다. 위의 경우는pod를 만드는 것이다.Metadata: 생성되는 resource의 이름을 지정한다. 위의 경우 pod의 이름은my-pod이며 kubernetes resource를 의미하는 것이지 docker를 의미하는 것이 아니다. 즉,Metadata는 kubernetes를 위한 것이지 Docker를 위한 것이 아니다.Spec: kubernetes에게 resource가 어떤 것들로 이루어지는 지 알려주는 것이다. 위의 경우pod는busybox:lastestimage를 기반으로busybox-container라는 컨테이너로 구성된pod를 만들어낸다. 즉, Docker를 통해 생성될 container들을 기술하는 것이다.
또다른 declarative syntax의 중요한 점은 여러 개의 resource들을 하나의 파일에 쓸 수 있다는 것이다. resource들 사이에 ---로 표시하여 구분해주기만 하면 된다. 아래의 예시를 확인해보자.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: busybox-container
image: busybox:latest
---
apiVersion: v1
kind: Pod
metadata:
name: my-second-pod
spec:
containers:
- name: nginx-container
image: nginx:latest위의 예시는 두 개의 pod를 하나의 file에서 기술하여 deploy할 수 있다.
declarative syntax는 imperative syntax보다 만들기도 어렵고 시간도 많이 걸린다. 그러나 이는 두 개의 주요한 장점을 제공해주는데
- Infrastructure as Code(IaC) management: IaC로 configuration을 관리하고 kubernetes resource 버전 관리를 할 수 있다. 만약, cluster가 자신의 state를 잃어버리면 YAML 파일을 통해서 resource를 다시 생성할 수 있다.
- Create mulriple resource at the same time: 같은 yaml 파일에 여러 개의 resource들을 선언할 수 있기 때문에, 같은 장소에서, 같은 시간에서 전체 application과 dependency들을 가질 수 있다. 추가적으로 하나의 커맨드로 수 많은 복잡한 application을 다시 생성하고 업데이할 수 있다.
추가적으로, kubectl 명령어를 kubernetes cluster가 설치된 local machine이 아닌 ci tool이 구동되는 서버에 배포하여도, kubeconfig 설정만 잘해주어 kubernetes cluster와 연결만 되면 상호작용이 가능하다. 이를 통해 자동으로 배포하고 테스트하는 CI/CD가 가능한 것이다. 따라서, kubectl은 인간만 사용하는 tool이 아닌 bot도 사용할 수 있는 generic한 tool이라는 것이다.
Etcd datastore
위에서 kube-apiserver는 stateless API로 수평적인 스케일링이 가능하다고 했다. 그러나, 어딘가에는 cluster의 state를 kube-apiserver에서 저장해야할 필요가 있다. 가령, 만들어진 container의 수, pod들의 이름, 사용된 docker image이름 등이 있는데, 이를 위해서 Etcd database를 사용하는 것이다.
Etcd datastore의 역할
Etcd는 control plane의 한 파트로, kube-apiserver 컴포넌트는 distributed NOSQL인 Etcd에 의존한다. 엄밀히 말하자면 Etcd는 kubernetes의 project가 아니다. 즉, kubernetes와 완전히 독립적인 프로젝트인 것이다.
MYSQL이나 PostgreSQL와 같은 완전한 relational database를 사용하는 대신에 kubernetes는 NoSQL 분산 datastore인 Etcd를 사용해 kubernetes의 state를 persistent하게 저장한다. Etcd는 kubernetes와 독립적인 프로젝트이므로, 따로 구동할 수 있지만, kubernetes는 Etcd를 필요로 하므로 Etcd가 없으면 kubernetes는 동작하지 않는다. 이는 kubernetes가 external dependence를 가진다는 의미으로, database engine으로 처음부터 만드는 대신에 Etcd를 사용하기로 한 것이다. 단, 그렇다해서 kubernetes에 다른 database를 적용할 수는 없다.
kube-apiserver가 호출될 때마다 kubernetes API를 사용함으로서 read, write 연산을 실행하고, Etcd로부터 데이터를 가져오거나 저장하게 된다. 따라서, Etcd는 kubernetes cluster의 메인 메모리며, kube-apiserver는 Etcd에 대한 하나의 프록시이다.
다음의 예를 보자.
Etcd는 굉장히 민감한 cluster의 요소인데, 만약 Etcd에 있는 데이터를 잃어버리면 kubernetes cluster는 완전히 unusable한 상태로 변하게 될 것이다. kube-apiserver에 크래쉬가 발생한다면 그냥 다시 launch시키면 된다. 그러나 만약 Etcde datastor에 있는 data를 잃어버린다면 또는 데이터가 손상된다면 backup file이 있지 않는 한 kubernetes cluster는 죽을 것이다.
다행스럽게도, 사용자가 직접 Etcd를 다루는 일은 거의없다. 또한, kubernetes에서도 사용자가 Etcd를 다루는 것을 권장하지 않는다. 이는 data를 손상시키거나 삭제시키는 가능성이 있기 때문이다.
kube-apiserver를 사용해야만 kubernetes 아키텍처에서 Etcd를 호출해 state(data)를 저장, 로드할 수 있다. 즉, 다른 모든 component들은 직접 Etcd로부터 데이터를 저장하거나 가져오는 일을 할 수 없고, 오직 kube-apiserver를 호출해야지만 Etcd 데이터를 다룰 수 있는 것이다.
재밌는 것은 Etcd또한 REST API로 디자인되었고 default port는 2379이다.
kubectl run nginx --restart Never --image nginx위의 명령어를 실행하면 HTTP post 요청이 kube-apiserver에 전달된다. kube-apiserver는 Etcd에 새로운 entry를 만들고, disk에 persistent하게 저장된다.
재밌는 것은 Etcd는 in-memory database가 아니기 때문에 kubernetes가 호스팅된 서버를 다운시켜도 data를 잃지않고 disk에 저장하고 있다.
Kubelet과 worker node components
여태까지 kubernetes control plane의 주요한 component인 kube-apiserver component, Etcd datastore를 알아보았다. kube-apiserver component와 통신하기위해서는 kubectl cli를 사용하여 Etcd로부터 데이터를 저장하거나, 받을 수 있다는 것도 알았다.
그러나, 이 모든 것들은 worker node에 있는 구동중인 container들에 명령어들이 어디에 또는 어떠한 결과를 초래할 지 알려주지 않는다. 이번 챕터에서 동작하는 3개의 component들에 대해서 설명함으로서 worker node를 자세히 파헤쳐 보도록 하자.
- the container engine
worker node에 가장 먼저 설치되어야 하는 것은 Docker daemon이다. kubernetes는 Docker에 국한되지만 않는데, 다른 container engine들도 사용할 수 있다.
kubernetes worker node에 실행중인 docker daemon은 plain old docker installation으로, local machine에 실행 중인 docker daemon과 다를바가 없다.
kubelet agent
kubelet는 kubernetes의 worker node의 일부로, worker node에서 가장 중요한 부분이다. 왜냐하면 이를 통해 worker node에 설치된 local docer daemon과 상호작용 할 수 있기 때문이다.
kubelet은 daemon으로 시스템 위에 동작한다. kubelet은 docker container 그 자체로서 동작하지 않고, host system에 동작한다. 이 때문에 systemd를 사용하여 이를 setup하는것이다. kubelet은 다른 kubernetes component와 다른데, 왜냐하면 오직 유일하게 Docker container로 동작하지않는 부분이기 때문이다. kubelet은 엄밀히 말하자면 host machine에 구동되므로, 이를 실행시켜줄 주체가 필요할 뿐이다.
kubelet이 실행되면 기본적으로 /etc/kubernetes/kubelet.conf에 있는 configuration file을 읽는데, 해당 configuration은 kubelet에서 동작하는데 정말 필요한 두 가지 값을 갖는다.
- kube-apiserver컴포너트의 endpoint
- local Docker daemon UNIX socket
worker node가 시작되면, worker node는 해당 cluster에 join하기 위해, HTTP request를 kube-apiserver component에 발행하여 Etcd에 Node entry 데이터를 추가한다. 그 다음, 아래의 kubectl 명령어를 호출하면 새로운 woker node가 확인된다.
kubectl get nodes일단 machine(worker node)가 cluster에 join되면 kubelet은 kube-apiserver와 Docker daemon 사이의 다리 역할을 한다. kubelet은 지속적으로 HTTP 요청들을 kube-apiserver에 보내어 launch해야하는 pod를 불러온다. 기본적으로 매 20초간 kubelet은 GET reuqest를 kube-apiserver에 보내어 Etcd에 생성되어 있고, 해당 worker node에서 구동되어야할 pod들의 리스트를 불러온다.
kube-apiserver로부터 HTTP 응답으로 pod spec을 받으면, 이를 Docker containers specification으로 변할 수 있다. Docker containers specification은 지정된 UNIX socker을 통해 실행되며, 실행결과는 local docker daemon에 지정한 container들을 생성하게 된다.
해당 polling 매커니즘은 watch mechanism으로 불리며, 어떻게 kubernetes에서 worker node에 정확히 적합한 양의(at scale) container들을 생성하고 삭제하는 것을 진행하는 지 보여준다. 각 worker node의 kubelet instance는 kube-apiserver를 바라보며(watching), 언제 Etcd datastore안에서 변화가 발생하는 지를 확인한다.
Etcd에 변화가 발생하면, kubelet은 해당 변화를 상응하는 Docker 명령어로 변경시켜주고, kubelet configuration file에 명시된 Docker UNIX socket을 사용하여 local Docker daemon과 통신한다. 이 두 가지 일은 주목해야하는데,
kubelet과 kube-apiserver는 반드시 HTTP를 통해서 연결(소통)할 수 있어야한다. 때문에 HTTPS port 6443은 worker와 master node들 사이에 열려있어야 한다. 즉 master node가 port번호 6443으로 TLS의 보호를 받는 HTTPS를 통신 서버를 열어야 한다는 것이다.kubelet과docker daemon은 둘 이 동시에 같은 머신(서버)에서 동작하기 때문에 이들은 UNIX socker을 사용하여 인터페이스 되어야 한다.
모든 worker node는 각자의 kubelet을 가져야 한다. 따라서, machine이 늘어나면 kubelet이 늘어나고 master node의 kube-apiserver에 대한 client가 많아진다는 것을 의미함으로, 성능에 큰 영향을 미칠 수 있다. 따라서 master node와 worker node의 수를 적절히 유지하도록 하자.
만약, worker node에서 Docker container들을 직접 만들었다면 kubelet은 이를 직접 관리할 방법이 없다. 즉, 명심해야할 것이 Kubelet은 오직 자신이 생성한 Docker container만 관리할 수 있다는 것이다. 왜냐면 container들이 Etcd datastore에서 pod의 한 부분으로 만들어질 수 없기 때문이다. 즉, Etcd에서 pod의 container들이 만들어지는 것이 아니라, pod의 container를 만드는 configuration만이 Etcd에 있어, 이를 통해 kubelet이 pod의 container를 만드는 것이지, container 자체를 다루는 것은 아니다. 따라서, kubelet의 유일한 job은 local Docker deamon이 Etcd에 저장된 configuration을 반영해 container를 만들어 pod를 생성하는 것이다.
kube-proxy component
worker node에서 구동하는 3개의 component 중 마지막이 바로 kube-proxy이다. kubernetes에서 중요한 부분 중 하나는 네트워킹이다. 네트워킹은 kubernetes pod를 외부로 노출시키거나 또 다른 kubernetes cluster에 노출시켜 통신할 수 있도록하는 방법을 말한다.
이러한 네트워킹 기능들은 kube-proxy를 통해서 구현된다. 즉, 각 worker node는 kube-proxy 인스턴스를 필요로하고, kube-proxy를 통해서 worker node에 있는 pod에 접근이 가능한 것이다.
kubernetes에는 Service라는 개념이 있는데, 이는 kube-proxy component 수준에서 구현된다. kubelet과 마찬가지로 kube-proxy component 또한 kube-apiserver과 통신한다.
worker node level에서 동작하는 몇가지 또 다른 sub-components 또는 extention들이 있는데, 가령 cAdvisor 또는 Container Network Interface(CNI)가 있다. 그러나 이는 advanced한 topic이므로 나중에 이야기하도록 하자.
kube-scheduler component
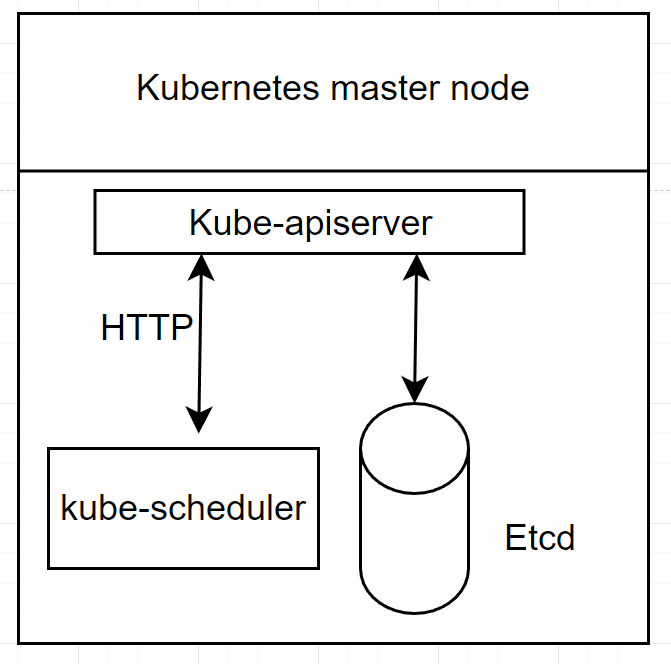
kube-scheduler component는 control plane component로 master node에서 동작해야 한다.
해당 component는 새롭게 만들어지는 pod를 구동할 수 있는 worker node를 선출하는 기능을 담당한다. 즉, kubelet을 통해 pod의 container를 만들기 전에 worker node 중 어느 것에 해당 pod의 생성을 책임지게 할 것인지 선택하는 일이 필요하고, 이것이 바로 kube-scheduler가 하는 일이다.
kubelet과 비슷하게 kube-scheduler도 kube-apiserver에 정해진 간격으로 쿼리를 전달하는데, 쿼리를 통해 아직 scheduled되지 않은 pod들의 list를 불러오기 위함이다. 생성 단계에서 pod들은 아직 scheduled되지 않는다. 이는 해당 pod를 구동하기 위한 worker node가 아직 배정(선출)되지 않았음을 의미한다. scheduled되지 않은 pod는 Etcd에 등록되지만, 할당된 worker node는 없다. 따라서, kubelet은 실행되어야할 pod를 인지하지 못하고, pod specification에 명시된 container들은 실행되지 않을 것이다.
내부적으로, Etcd에 저장된 pod객체는 nodeName이라는 property를 가지고 있다. 이름에서 알 수 있듯이 해당 property는 pod를 호스팅할 worker node의 이름을 포함해야한다. 해당 property가 설정되면 해당 pod는 scheduled되었다고 한다. 그렇지않으면 pod는 schedule에 pending되었다고 한다.
해당 property 값을 채우는 일이 바로 kube-scheduler이다. 이를 위해 kube-scheduler poll은 일정 간격으로 kube-apiserver에 polling한다. kube-scheduler는 비어있는 nodeName property을 가진 pod 자원들을 찾는다. nodeName이 비어있는 property를 가진 pod들을 찾는다면, worker node를 선출하는 algorithm을 선출한다. 그런 다음, HTTP request를 kube-apiserver component에 발행함으로서 pod안에 nodeName property를 업데이트한다.
worker node가 선출되는 동안 kube-scheduler component는 선택적으로 전달할 수 있는 몇가지 configuration value들을 고려한다. 이러한 configuration들을 사용함으로서, 개발자의 의도대로 kube-scheduler component가 worker node를 어떻게 선출할 지 제어할 수 있다. worker node를 배정할 때 고려해야할 configuration 값들을 다음과 같다.
- node selector
- node affinity and anti-affinity
- taint and toleration
kube-scheduler component를 완전히 우회하는 고급 스케줄링 기술도 있다. 이에 대해서는 다음에 알아보도록 하자.
참고로 kube-scheudler component는 custom한 것으로 대체되어질 수 있다. 즉, 직접 kube-scheduler component를 만들어 worker node를 선택하는 logic를 cluster에 사용할 수 있다.
kube-controller-manager component
마지막 kubernetes component로 이번에는 굉장히 간단히 훑고 지나갈 것이다. 왜냐면 이런저런 용어들이 아직은 추상적이기 때문이다.
kube-controller-manager component는 kubernetes control plane의 한 부분으로, reconcilation loop(조정 루프)라는 것을 실행하는 바이너리이다. kube-controller-manager는 cluster의 실제적인 state를 Etcd로 관리하기 때문에 cluster안에서의 state 불일치 문제는 발생하지 않는다.
kube-controller-manager의 역할
역사적으로 kube-controller-manager component는 수많은 것들을 구현하는 큰 바이너리이었다. 본질적으로 kube-controller-manager는 Controller라 불리는 것을 임베딩하고 있다. kubenetes 개발자들은 kube-controller component의 일부분으로 실행되고 있는 다양한 controller들을 여러 개의 작은 바이너리로 분리하려는 경향이 있다. 이는 kube-controller-manager가 여러 개와 다양한 책임을 가지기 때문인데, 이 책임은 굳이 마이크로서비스 철학을 따르지 않아도 되므로, 여러 개의 controller로 나누어도 되는 것이다.
때때로, cluster의 실제적인 state가 Etcd에 저장된 의도된 state와 다를 때가 있다. 이는 주로 pod의 실패 등의 이유 때문이다. 그러므로, kube-cotnroller-manager component의 역할은 실제적인 state를 의도한 state로 조정(reconcile)하는 것이다.
가령, ReplicationController를 예시로 들면, kube-controller-manager 바이너리의 일부분으로 실행되는 controller 중 하나이다.
추후에, 다른 worker node들에 걸쳐 수많은 지정된 pod들을 생성하고 관리하는 것을 가능하도록 kubernetes에게 명령하는 것을 볼 것이다. 만약, 일부 이유 때문에, 개발자가 의도한 pod의 수와 실제 pod의 수가 다르다면, ReplicationController는 kube-apiserver component에게 request를 전달하여 Etcd를 통해 새로운 pod를 생성하라고 할 것이고, 생성에 실패했던 pod는 해당 worker node에서 교체될 것이다.
여기 controller의 몇 가지 예시가 있다.
NodeControllerNamespaceControllerEndpointsControllerServiceaccountController
kube-controller-manager component는 꽤 크다. 그러나 본질적으로 이는 바이너리로 cluster의 실제 상태를 Etcd에 저장된 의도한 상태로 조정해주는 기능을 하는 것이다.
kubernetes의 가용성을 높이는 방법
위에서 보았듯이 kubernetes는 clustering solution이다. 분산 시스템을 통해 여러 machine들에서 동작하도록 한다. 이는 수많은 component들은 여러 machine들에 나누어 배치함으로서 kubernetes cluster의 가용성을 높게 만들 수 있다. 따라서, 설치방법에 따라 kubernetes 가용성은 다를 수 있다. 다음은 다양한 kubernetes setup을 알아보도록 하자.
단일 노드 클러스터(The single-node cluster)
모든 kubernetes component들을 하나의 같은 mancine에 배포하는 방법으로 가장 안좋은 방법이다. 그러나, testing 작업에서는 문제될 것이없다.
다음은, 하나의 host 또는 virtual machine에 다양한 kubernetes component들을 그룹핑한 그림으로 하나의 single node로 구성된 방법이다.
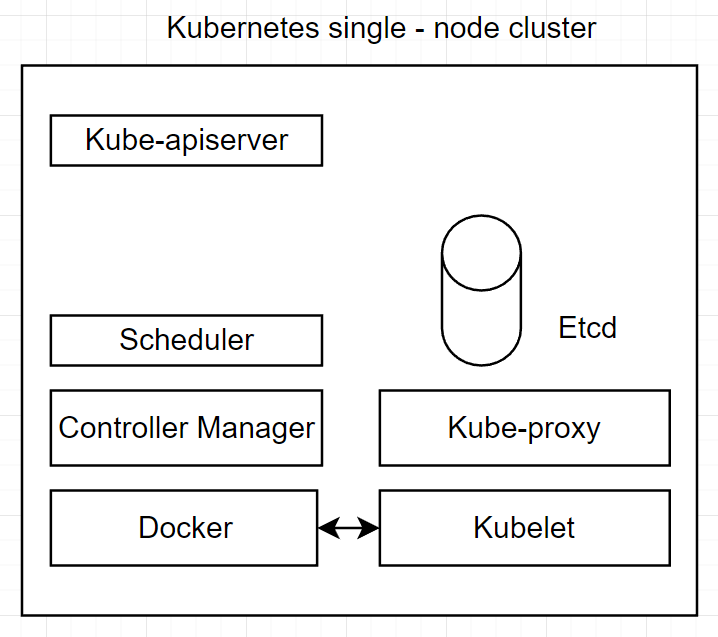
보편적으로, 테스팅할 때는 대부분 위의 구성을 사용한다. 그리고 이러한 single node로 이루어진 kbuernetes 프로젝트를 Minikube라고 한다. 이는 single-node kubernetes로 미리 configured된 모든 component들의 이미지를 적재한 virtual machine을 실행함으로서, local machine에 single-node kubernetes를 셋업한다. Minikube는 local로 testing하기 좋지만, 여러 개의 node들을 필요로 하는 예제는 Minikube에서 불가능하다.
정리하자면, 테스팅에 좋다는 장점이 있지만, 스케일링하기 어렵고 가용성이 좋지 않다는 문제가 있다.
단일 master cluster(The single-master cluster)
이는 하나의 master node와 여러 개의 worker node들로 구성되는 방식이다.
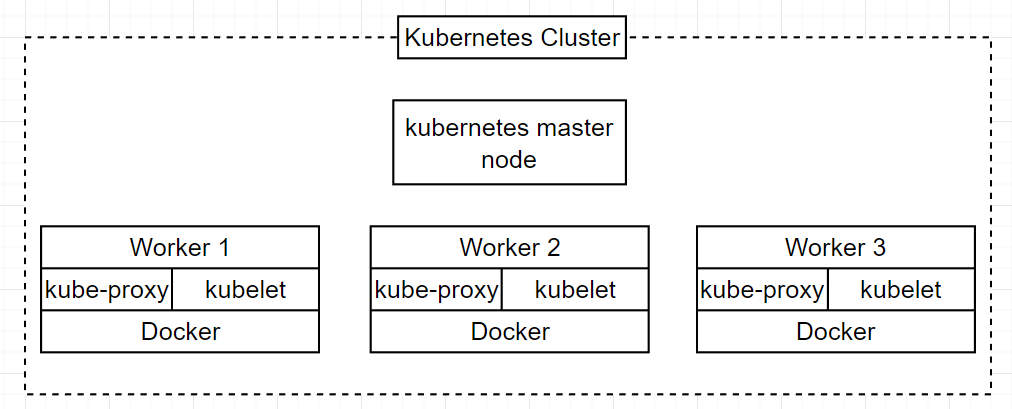
위의 구성 방식은 여러 개의 worker node들을 가지고 있어 containerized application에 대해 높은 가용성을 가능하게 해준다. 그러나 여기에도 약간의 문제가 있다.
master node가 하나이기 때문에 단일 실패 지점이 있다는 것이다. 만약 단일 master node가 실패한다면(다운된다면), kubernetes에서 동작하는 Docker container들을 관리할 수가 없다. container들을 orphans(고아)가 되고, 오직 container들을 멈추고, 수정하는 방법은 worker node에 SSH로 접근하여 docker 명령어를 직접 타이핑하는 수 밖에 없다.
또한, 주요한 문제점이 있다. Etcd 인스턴스가 하나만 존재함으로 master node가 다운되면 엄청난 리스크가 발생한다는 것이다. 만약 이러한 일이 발생하면 cluster는 recover하기 어려운 수준에 도달하게 된다.
마지막으로, worker node들을 스케일링하려고 할 때 cluster가 특정 issue를 만날 수 있다. 각 worker node는 Kubelet agent를 직접 가지고 있고, 주기적으로 kubelet은 kube-apiserver에 대해 20초마다 polling을 한다. 만약 server들을 여러 개 추가하려고 한다면 이는 kube-apiserver에 DDoS를 하는 것과 같아 control plane는 맛탱이가 가버린다. 우리의 maste node(control plane)는 반드시 worker node들과 parallel하게 스케일링되어야 한다는 것을 명심하도록 하자.
정리하자면, worker node에 대한 가용성이 있고, 프로덕션 상황에서도 충분한 성능을 발휘하지만, master node가 단일 endpoint라는 문제 때문에 state를 잃어버리거나, 성능 문제가 있을 수 있다.
다중 master, 다중 node cluster(The multi-master multi node cluster)
kubernetes cluster의 가용성을 최상으로 끌어올리기에는 다음의 방법이 최고이다. 다중 worker node이면서 단일 master node가 아닌 다중 master node를 사용하여 구동중인 container들과 control plane component을 복사하여 단일 실패 지점을 피하는 것이다.
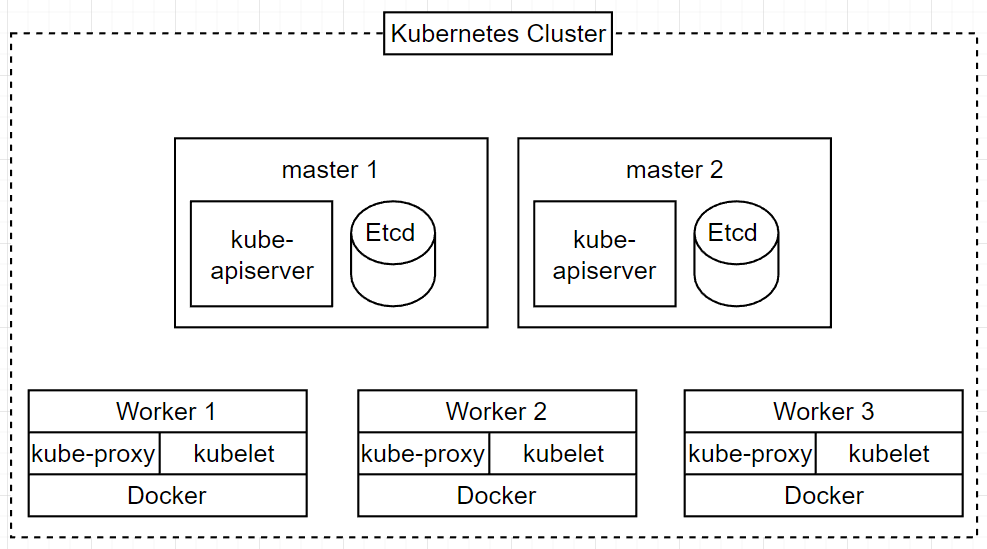
다음의 cluster를 사용함으로서, 모든 risk들을 해소할 수 있다. 왜냐하면 다중 worker node와 master node를 사용하기 때문이다. control plane component들은 scalable하며 kube-apiserver component는 stateless API이기 때문에 스케일링되는 것에 문제가 없다.
cluster에서 node들 사이에 균등한 load가 분산되기 위해서 kube-apiserver의 맨 위에 load balancer를 둘 필요가 있다.
정리하자면 다음과 같다.
| Component name | Comunicates with | Role |
|---|---|---|
| kube-apiserver | kubectl client(s), Etcd, kube-scheduler, kube-controller-manager,Kubelet, kube-proxy | HTTP REST API로 etcd에 있는 state를 읽고 쓴다. 이 component만이 직접 Etcd에 접근할 수 있다. |
| Etcd | kube-apiserver | kubernetes cluster의 state를 저장한다. |
| kube-scheduler | kube-apiserver | 매 20초간 스케줄링되지 않은 pod들을 읽어오는 API를 kube-apiserver에게 전달한다. 이후 스케줄링되지 않은 pod들의 property인 nodeName을 변경하여 worker node에 스케줄링 시켜준다. |
| kube-controller-manager | kube-apiserver | API를 polling하고 reconcilation loop를 동작시켜준다. |
| kubelet | kube-apiserver and Docker(container runtime) | kube-apiserver에게 20초마다 kubelet이 동작하는 worker node에 스케줄링된 pod spec들을 가져오는 API를 전송하고, local Docker daemon을 실행하여 해당 worker node에 스케줄링된 pod spec을 동작하는 container로 바꿔준다. |
| kube-proxy | kube-apiserver | kubernetes의 networking layer를 구현한다. |
| Container Engine(Docker ...) | kubelet | local Kubelet으로부터 명령어를 받아 container들을 실행한다. |
위의 component들이 kubernetes project의 공식 지원 component들이다.
