Pod:Kubernetes에 동작하는 container
Pod란?
이미 이전에 pod는 관련된 container들의 그룹으로 kubernetes에서 가장 기본적인 building block을 구성한다고 하였다. pod안에 container 몇 개 있는 것인지는 중요하지 않다. 중요한 것은 각 worker node에서 pod들을 공유하지 않는다는 것이고, pod들도 각 worker node안에 pod들 끼리 container를 공유하지 않는다는 것이다. 즉 완전히 독립적인 구성으로 실행된다는 것이다.
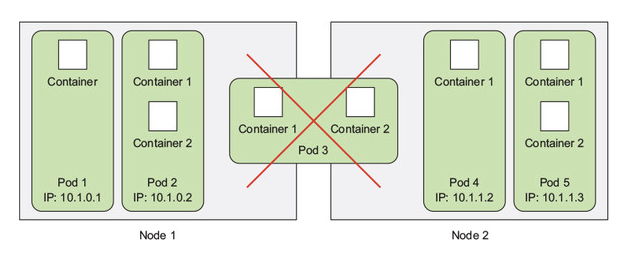
왜 pod가 필요한가?
그렇다면 왜 container 그 자체로 구동하지 않고 pod를 필요로 했을까? 여러 개의 container들을 하나의 pod로 실행할 것이라면, 여러 개의 process들을 하나의 container에 담는 것도 있지 않는가?
그러나 이는 굉장히 좋지 못하는 아이디어이다. 하나의 container에는 하나의 process만을 구동하는 것이 원칙이다. 이는 여러 개의 process들이 하나의 container들에 실행되는 순간부터 logging, debugging, networking 모두 개발자의 몫으로 돌아간다. 만약 하나의 process가 죽어라도 docker는 이를 해주지 않는다. 개발자가 process가 crash가 날 때마다 새롭게 deploy해주는 스크립트를 만들어야 할 것이다. 때문에 하나의 container에 여러 개의 process를 넣는 것은 매우 좋지 않은 방법이다.
pod는 여러 개의 container들을 묶어낼 수 있고, 각 container들의 실행을 마치 독립적인 machine에 구동중인 것처럼 만들 수 있다. 이는 logging부터 시작하여 debugging, networking에 있어서 매우 파워풀하다.
Pod의 이해
container들이 묶인 pod는 각 process들을 함께 묶어주고 같은 환경에서 구동중인 것처럼 해주어 마치 하나의 container에 여러 개의 process들이 독립적으로 실행 중인 것처럼 보이게 해준다. 그러나 실제로는 분리되어 있어서, logging, debugging, networking에 있어 충돌이나거나 개발자가 직접해주어야 할 부분이 없다. 즉, container의 이점을 가지고 가면서도, 마치 여러개의 process들이 하나의 container에 실행되는 것 같은 환상을 주는 것이다.
container들을 하나의 pod에 독립적이고 분리된 상태로 구동한다해도 특정 resource들에 대해서는 서로 공유하고 싶을 수 있다. kubernetes는 Docker를 설정함으로서 pod의 모든 container들이 같은 linux namespace들을 공유하도록 할 수 있다. 즉, 각 container들이 자신의 set을 가지지 않도록 할 수 있다는 것이다.
pod의 모든 container들이 같은 Network와 UTS namespace에서 동작하기 때문에 container들은 같은 hostname과 network interface들을 공유한다. 유사하게 pod의 모든 container들은 같은 IPC namespace에서 동작하고 IPC를 통해서 통신할 수 있다. 최신 kubernetes와 Docker version에서는 conatiner들이 같은 PID namespace도 공유할 수 있지만, 이는 기본적으로 제공하는 것은 아니다.
filesystem은 각 container들의 base image에 따라 다르기 때문에 container들 끼리는 filesystem은 격리되어 있다. 그러나 kubernetes concept인 Volume이라는 개념을 통해서 이들은 file directories를 공유하고 가질 수 있다.
한 가지 중요하게 생각해야할 것은 pod의 container들은 같은 Network namespace에서 동작하기 때문에, 이들은 같은 IP address와 Port 공간을 공유한다. 이는 같은 pod의 container들에서 동작하는 process들이 같은 port number로 바인딩되거나 port conflict가 발생하지 않도록 신경써야 한다는 것이다. 그러나 이는 오직 pod안의 container들끼리는 같은 Network namespace이기 때문에 신경써야한다는 것이다. 다른 말로 다른 pod들의 container들은 절대로 port conflict가 발생하지 않는다는 것이다. 왜냐하면 각 pod는 분리된 IP address , port space를 가지기 때문이다. pod의 모든 container들은 또한 같은 loopback network interface를 가지고 있기 때문에 container들은 서로서로 localhost를 통해서 같은 pod 내의 통신이 가능하다.
모든 kubernetes cluster 상의 pod들은 평평하고 공유되는 network address space 상에서 존재한다. 이는 모든 pod가 모든 다른 pod의 IP adress로 접근 가능하다는 것이다. 이들 사이에는 어떠한 NAT시스템이 없다. 두 pod들이 서로 packet들을 전달할 때 그들은 서로의 IP address를 확인하고 packet에 상대의 IP address를 전달할 것이다.
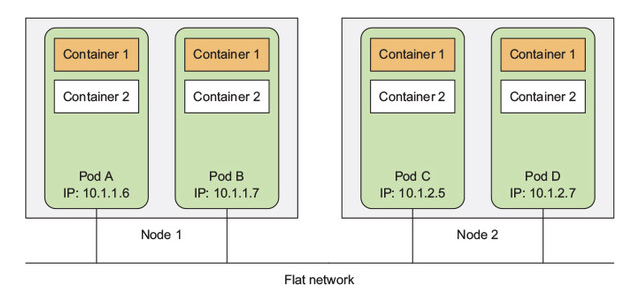
결과적으로, pod들끼리의 통신은 항상 간단하다. 두 개의 pod들이 항상 같은 worker node에 스케줄링될 필요가 없으며, 각 pod들의 container들은 flat NAT-less network를 통해서 pod의 IP로 직접 통신할 수 있다. 마치 LAN(local area network)에 있는 컴퓨터들끼리의 통신과 같이 pod들끼리 통신이 가능하다는 것이다. 이는 실제 네트워크에 추가적인 SDN(software-defined network) layered를 통해 만들 수 있던 것이다. 즉, kubernetes는 flat network model을 사용하는데, 이는 Container Network Interface(CNIs)라 불리는 component에 의해서 구현된다.
정리하자면 pod는 logical hosts를 가지고 있고 마치 physical host 또는 VM과 같은 역할을 한다. 같은 pod에서 동작하는 process들은 container로 감싸져 있으며 이들은 마치 physical machine, VM의 process들과 같이 동작한다.
그러나 pod에는 대부분 하나의 메인 container만 있는 것이 일반적인 경우이다. 이는 pod 자체가 매우 light해서 이기도 하다. 굳이 여러 개의 container들을 하나의 pod에 동작할 필요가 없으며, 각 container들을 하나의 pod에 대응하여 배포해도 된다. 또한, 이전에도 언급했듯이 pod는 잘 죽는다. 그리고 죽어도 문제가 없어야 한다. 만약 pod에 container로 server가 있고, 이를 뒷받침하는 DB가 있다면 pod가 죽을 경우 DB데이터도 다 날라가는 문제가 생긴다. 이를 방지하기 위해서는 DB를 하나의 POD로 빼내거나 kubernetes의 volumn을 이용하는 방법이 있다.
때문에, pod는 main container 하나로 쓰이거나, 이를 받쳐주는 supporting container 여러 개가 같이 구성되기도 한다.
imperative(명령형) syntac로 pod 생성하기
imperative로 pod를 만드는 방법은 이전에 사용했던 kubectl 명령줄로 만드는 방법이다. 아주 기본적으로 두개의 파라미터가 필요한데
- pod 이름
- docker images
imperative syntax로 pod를 생성하기 위해서는 kubectl run 명령어를 사용한다. nginx pod를 만들어보도록 하자.
kubectl run nginx-pod --image nginx:latestpod이름은 nginx-pod이고 image는 nginx:latest이다. 해당 pod name은 하나의 식별자로 update나 delete에 반드시 필요하다. --image flag는 pod로 실행될 Docker container를 만들기 위한 image를 의미한다.
위의 명령어를 통해서 kubectl에서 nginx:latest image르 DockerHUB에서 찾아서 pod의 container로 만들고 pod이름을 nginx-pod로 만들었다. 재밌는 것은 pod를 먼저 만들고 image에서 container로 만든다는 것이다. 때문에 image를 찾지 못해도 pod는 생긴다.
declarative(선언향) syntax로 YAML또는 JSON descriptor를 통해서 Pod를 만들기
pod와 다른 kubernetes resource들은 대게 JSON 또는 YAML manifest를 만들어서 Kubernetes REST API Endpoint에 posting함으로서 만들 수 있다.
또한, 이러한 방식 말고도 kubectl run command로도 resource들을 생성할 수 있다. 그러나 이러한 방식은 오직 제한된 property들의 set만 configuration한다는 문제가 있다. 추가적으로 YAML과 같은 파일로 kubernetes object들을 정의하는 것은 여러 제어 시스템에서 이들을 저장하게 할 수 있고, 여러 혜택들을 가져다 준다.
resource들의 각 타입을 설정하기 위해서, Kubernetes API object 정의들에 대해서 알아야 할 필요가 있다. 해당 시리즈에서 전반적인 내용을 다루지만, 모든 것들을 다루진 않는다. 이들에 대해서는 다음의 링크를 참고하여 확인하도록 하자.
https://kubernetes.io/docs/reference/
declarative(선언형) syntax로 pod를 만드는 방법은 json또는 yaml으로 된 파일을 하나 만들고, kubectl create -f 명령어를 써주면 된다.
nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:latestyaml file은 오직 key/value 쌍으로 이루어져 있다. pod의 이름은 nginx-pod이며 spec에는 array로 container들이 있다. 해당 파일에는 하나의 container만 있으므로 nginx-contaienr라는 container만 만들어지고 image가 nginx:latest인 것이다.
실행시키는 방법은 다음과 같다.
kubectl create -f nginx-pod.yaml # kubectl apply -f nginx-Pod.yaml
pod/nginx-pod created참고로 kubectl apply -f nginx-pod.yaml도 동작한다.
kubernetes 상에서는 같은 이름의 pod를 두 개 이상 올릴 수 없다. 만약, 이미 nginx-pod라는 이름의 pod가 있다면 위의 요청은 실패할 것이다.
pod의 information과 metadata를 읽는 방법
kubernetes cluster를 읽는 것은 kubectl 명령어의 kubectl get과 kubectl describe 명령어를 사용함으로서 이루어진다.
-
kubectl get: 해당 명령어는 list 연산으로 kubernetes object의 set를 list로 확인하고 싶을 때 사용할 수 있다. 가령node들이 무엇이 있는 지 보고싶다면kubectl get nodes를 하면되고, pod가 무엇이 있는 지 보고 싶다면kubectl get pods를 하면 된다. 그러나kubectl get은 각 object들의 개략적인 정보들만 보여주고 나열할 뿐이다. -
kubectl describe: 해당 명령어는 특정 object의 완전한 정보 set을 보기위해서 사용된다. 이를 위해서 해당 object를 식별할 수 있는 object의 종류와 이름이 필요하다. 가령,pod인nginx-pod에서 어떤 docker 이미지 파일이 쓰이고, 현재 events 상황이 어떤지 알고싶다면kubectl describe pods nginx-pod를 사용할 수 있다. 여기에 사용된 docker image와 할당된 IP, events 정보들이 나열된다.
object들을 json또는 yaml으로 나열하기
-o option은 kubectl 명령어 라인에 의해 제공되는 가장 쓸모있는 옵션이다. 이는 kubectl command line의 output을 customizing할 수 있는데, 기본적으로 kubectl get pods 명령어는 kubernetes cluster에서의 pod list를 보여준다. 이 결과를 json 형식 또는 yaml 형식으로 보고 싶다면 -o 옵션을 주면 된다.
kubectl get pods -o yaml
kubectl get pods -o json
kubectl get pods <pod_name> -o yaml
kubectl get pods <pod_name> -o json이를 통해서 스크립트 친화적인 output format을 가져올 수 있는 것이다.
list operation을 통한 resource backup
만약, 누군가가 만든 pod이거나 imperative 방식으로 만든 pod라면 pod에 대한 어떠한 yaml, json 파일이 없을 수 있다. 그런데, 지금 당장 해당 pod를 삭제하고 추후에 다시 돌려야하는 상황에서는 어떻게 해야할까??
위에서 언급한 kubectl get pods <pod_name> -o yaml을 통해 우리는 declarative 방식의 pod파일을 만들 수 있다.
kubectl get pods/nginx-pod -o yaml > nginx-pod.yaml
kubectl delete pod nginx-pod
kubectl create -f nginx-pod.yaml잘 생성되는 것을 볼 수 있다.,
kubectl get pods/nginx-pod -o yaml > nginx-pod.yaml을 통해서 nginx-pod resource에 대한 yaml backup 파일을 가질 수 있다.
list operation으로부터 더 많은 정보가져오기
-o wide format도 있는데 이는 list에서 가져오는 데이터의 정보를 더욱 많이 가져오는 옵션이다.
kubectl get pods -o wide이전보다 더 많은 정보를 가져오는 것을 확인할 수 있다. -o 옵션에는 다양한 포맷들이 사용될 수 있다는 것을 알아두자. 가령 jsonpath와 같은 포맷을 써서 jq로 원하는 정보만 얻어내거나 변경할 수 있다.
외부에서 pod로 접근하기
이제 nginx http server를 kubernetes cluster에 배포하였으니, 이를 웹 브라우저에서 접근 할 수 있다. 그러나 이는 약간 복잡하다.
기본적으로, 우리의 kubernetes cluster는 pod를 internet에 노출시키지않는다. 때문에 우리는 service라는 다른 resource를 사용해야하는 것이다. 이는 추후에 다를 예정이지만, 지금은 pod를 외부에 연결시켜준다고 생각하자. kubectl의 port-forward를 통해서 쉽게 service를 만들 수 있다.
kubectl port-forward pod/nginx-pod 8080:80port-forward를 하되 로컬 머신의 8080포트에 nginx-pod의 80 port를 맵핑하라는 것이다.
curl localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>성공적으로 접근할 수 있는 것을 확인할 수 있다.
pod 내부로 접속하기
pod가 launch되면 pod에 접근할 수 있다. docker에서는 docker exec 명령이 있었듯이 kubectl exec 명령어가 있다.
kubectl exec -it nginx-pod -- bash위의 명령어를 실행하면 nginx-pod 내부 container의 bash를 실행하게 된다. 참고로 docker에서와 마찬가지로 -it을 사용해야 해당 명령어를 실행한 shell에서 container에 접속해있는다.
pod 삭제하기
kubectl delete pod <pod-name>을 통해서 pod를 삭제할 수 있다.
kubectl delete pod nginx-pod
pod "nginx-pod" deleted다음과 같이 pod의 이름으로 삭제하는 방법도 있고 declarative file이 있다면 이를 통해서 삭제할 수도 있다.
kubectl delete -f nginx-pod.yamlLabeling and annotating the pods
label은 key/value 쌍으로 kubernetes object들에 붙일 수 있다. label들은 kubernetes object들을 정의한 key/value 쌍으로 태깅해준다. 일단 kubernetes object들이 라벨링된다면, 특정 kubernetes object들을 label에 기반하여 호출하도록 query를 만들 수 있다.
무엇을 labeling하고 왜 써야하는 지?
label은 key/value 쌍으로 만들어진 object에 붙일 수 있다. 가령 pod에도 붙일 수 있다. label에는 어떠한 특별한 rule이 없다. label들은 attributes로 개발자가 kubernetes cluster에서 object들의 그룹을 조직해주도록 한다. 일단 object가 라벨링된다면 label을 통해서 listing과 query를 작업할 수 있다. 가령 environment=production라는 라벨링을 pod에 주었다고 하자. 그리고 kubectl get pods로 environment 라벨링에 매칭되는 pod들을 리스팅해보도록 하자.
kubectl get pods --label "environment=production"--label 파라미터로 라벨의 key/value 쌍을 넣어주어도 되고, --l과 같은 축약형을 써도 된다.
위의 명령어로 environment key에서 production value를 가진 라벨을 모두 찾아낸다. 물론 우리의 경우는 어떠한 결과도 나오지 않을 것이다. 왜냐면 이전에 만든 pod 중에서 lable을 붙인 pod가 없기 때문이다.
pod뿐만 아니라 kubernetes의 대부분의 object들은 라벨링된다. 라벨을 통해서 cluster를 조직화하고 깔끔하게 만들 수 있기 때문이다.
또한, label을 통해서 다른 kubernetes object들 간의 관계를 만들 수 있다. kubernetes object들은 특정 pod들에 의해 전달된 label들을 읽고, 해당 object들에 특정 연산을 수행할 수 있다.
label을 사용하는 것에는 어떠한 naming rule도 없다. kubernetes에서 따르는 naming rule도 없다. 따라서, 개발자가 이 rule을 만들고, 따르는 것이 중요하다.
label은 63 characters로 제한되기 때문에 적절하게 사용해야한다. 여기 많은 사람들이 사용하는 lable 예제들이 있다.
- enviroment: prod, dev, uat
- stack: blue, green
- tier: frontend, backend
- app_name: wordpress, magento, mysql
- team: business, developers
label들은 object들 사이에서 유니크할 필요는 없다. 가령, production=environment lable을 가진 pod들을 모두 listing하고 싶을 수 있다. 이 경우 같은 label을 가진 다른 pod들이 여러개 있을 수 있다. 심지어는 이렇게 같은 label을 여러 개의 resource들에 사용하는 것이 권장된다.
이제 object들에 metadata를 할당할 수 있는 또 다른 방법인 annotation들에 대해서 알아보자.
Annotations는 무엇이고, label과 무엇이 다른가?
kubernetes는 또 다른 metadata type인 annotations를 사용한다. 이는 label들과 매우 유사하게 key/value 쌍으로 이루어져 있지만, annotations는 lable처럼 같은 이름을 가질 수 없고, 권장되지도 않는다. label들은 resource들을 식별하고, 해당 resource들 간의 관계를 표현하기 위해서 사용되지만, annotations는 annotation이 정의된 resource에 대한 문맥적인 정보를 제공하기 위해서 사용된다.
가령, pod를 만들 때 app이 동작히지 않을 경우를 대비하여 연락처(email)을 annotation에 담아서 제공할 수도 있다. 이러한 정보는 label과는 관련이 없다.
label은 무엇을 할 때든 정의할 것이 권장되지만, annotation은 아니다. label보다 훨씬 덜 중요하게 표현되기도 하며, 딱히 쓸모있게 사용하진 않는다. 단, 특정 kubernetes object가 annotation들을 읽고 하나의 설정값으로 쓰는 경우가 있다. 이러한 경우의 annotation들은 docs에 미리 설명되었을 것이고, 그래야한다.
가령, calico같은 경우가 그런데, pod에 annotaiton으로 cni.projectcalico.org/podIP: <IP>를 달아준다.
label 달기
우리가 이전에 만든 nginx-pod에 대해서 label을 달아주도록 하자. tier=frontend라는 라벨을 추가하여 pod를 배포해주도록 하자.
kubectl run nginx-pod --image nginx:latest --labels "tier=frontend"pod가 생성될 것이다. --lables 또는 -l 옵션 다음에 라벨의 key/value 값을 넣어주면 된다. 라벨이든 annotation이든 하나 이상을 넣을 수 있으므로 다음도 가능하다.
kubectl run nginx-pod --image nginx:latest -l "tier=frontend" -l "environment=prod"또 다른 방법으로는 declarative syntax로 label을 yaml에 붙이는 방법이다.
nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
environment: prod
tier: frontend
spec:
containers:
- name: nginx-container
image: nginx:latest다음의 파일을 만들고, metadata 상에서 labels라는 list 형식의 키를 만들어주고 key/value쌍을 계속해서 만들어주면 된다.
kubectl 명령어로 pod를 만들어 주도록 하자.
kubectl create -f ./nginx-pod.yamlpod를 만드는데 성공하였다면, 이제 label을 이용하여 pod를 가져와보도록 하자.
kubectl get pods -l environment=prod
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 2m37s라벨을 통해서 원하는 pod만을 가져올 수 있는 것을 확인하였다.
pod에 붙은 label listing하기
kubectl get pods만으로는 label에 대한 정보들을 가져올 수 없다. 이를 위해서 --show-labels라는 옵션을 추가하도록 하자.
kubectl get pods --show-labels다음의 결과가 나온다.
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 4m6s environment=prod,tier=frontendLABELS에 대한 정보가 나오며, 우리가 의도한 라벨 정보들이 나온다. 이 명령어와 -o wide를 함께써서 추가적인 정보들도 얻을 수 있다.
kubectl get pods --show-labels -o widelabel도 나오고 더 많은 정보들(IP, Node)들이 나온다.
동작중인 pod에 label 추가 및 수정하기
이제 label을 넣어서 pod를 생성하는 방법에 대해서 알아봤으니, 동작중인 pod에 label을 넣어보도록 하자.
kubectl label 명령어를 통해서 resource의 label을 추가하고 삭제하고 수정할 수 있다. 우리는 nginx-pod pod에 stack=blue이라는 label을 추가해보도록 하자.
kubectl label pods nginx-pod stack=blue
pod/nginx-pod labeled위의 명령어는 stack이라는 label이 해당 pod에 없을 때만 동작한다. --show-labels로 label이 잘 있는 지 확인해보도록 하자.
kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 30m environment=prod,stack=blue,tier=frontend현재 존재하는 label을 수정하려고 한다면 --overwrite라는 파라미터를 추가해주어야 한다. 이제 stack=blue를 stack=green으로 바꾸어보자.
kubectl label pods nginx-pod stack=green --overwrite결과를 확인하면 다음과 같다.
kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 32m environment=prod,stack=green,tier=frontend사실 kubectl label로 label을 변경하고 추가하는 것은 매우 위험한 작업이다. 위에서 label을 통해서 서로 다른 kubernetes object 간의 관계를 만든다고 했다. label을 수정하고 추가함에 따라 이러한 관계를 부술수도 있고, resource들이 기대한 대로 동작하지 않을 수 있다. 이 때문에 label을 추가하는 것은 pod를 생성할 때만 넣고 kubernetes configuration은 immutable하게 관리하는 것이 좋다. 따라서, 수정하고 추가하는 것보다 언제나 삭제하고 다시 만드는 것이 더 configuration 설정이다.
동작하는 pod에 붙은 label을 삭제하는 방법
동작하는 pod에 label을 추가하고 변경했던 것처럼, label을 삭제할 수도 있다. 해당 command는 조금 이상한데 label을 지울 수 있다는 장점이 있다. stack label을 지워보도록 하자. 지우는 것은 key부분에 -을 넣어주면 된다.
kubectl label pods nginx-pod stack-정말 사라졌는 지 확인해보도록 하자.
kubectl get pods nginx-pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 40m environment=prod,tier=frontend- symbol을 key 부분 마지막에 추가함으로서 label을 삭제하는 문법은 어딘가 이상하긴한데, 어찌됐든 지울 수 있다는 장점이 있다.
Annotation 추가하기
pod에 annotation을 추가하는 방법에 대해서 배워보자. 굉장히 간단한데, yaml 파일에서 labels부분 옆에 annotations를 key-value로 붙여주면 된다.
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
annotations:
tier: webserver
labels:
environment: prod
tier: frontend
spec:
containers:
- name: nginx-container
image: nginx:latestmetadata부분에 annotations list를 하나씩 써주면 된다. 물론 아무것도 안써주고 생략해도 된다.
job 만들어보기
이제 pod에서 파생된 또 다른 kubernetes resource인 job resource에 대해서 알아보도록 하자. kubernetes에서 컴퓨팅 resource는 pod이다. 그리고 모든 것들은 pod를 manipulate하기 위한 중간 단계의 resource이다.
job이 딱 그러한 경우인데, 이는 특정한 computing task를 완료하기 위하여 하나 또는 그 이상의 pod들을 만든다. 가령, linux command 같은 것들이 있다.
job은 무엇인가?
job은 kubernetes API에 의해 노출된 또 다른 자원의 일종으로, 개발자가 원하는 특정 command를 실행하는 pod를 하나 또는 그 이상을 실행한다. job은 pod를 실행시키는 것이다. job은 pod와 뗄레야 뗄 수 없는 관계이다. job은 pod를 시작하는 것이고 pod를 관리하는 것이다. job은 특정한 task를 실행하고 종료한다. kubernetes job에 대한 전형적인 예시들이 있다.
- database backup
- sending an email
- consuming some message in queue
pod는 cluster에 문제가 생기지 않는 이상 영원히 구동된다. 그런데, 특정 task만 만족하고 끝나면 좋은 것 같은 일들이 있다. 이런 경우 pod로 만들면 영원히 반복되게 되는데, 특정 task만 딱 완료하면 종료하는 것이 바로 job인 것이다.
근데 그럼 pod를 만들고 특정 작업을 한 후에 멈추게 하면 되는게 아닐까? 하는 생각이 든다. 그러면 굳이 job을 만들 필요가 없을 것이다. 그러나, job은 단순히 pod를 실행하고 종료한다는 기능말고도 다음의 기능을 수행할 수 있다.
- pod를 여러 번 실행
- pod를 여러 번 병렬적으로 실행
- 만약 pod들이 에러를 만난다면 pod를 재시작하도록 함
- 특정 시간 후에 pod를 죽임
job은 pod를 관리하고 더욱 정교하고, advanced한 기능을 제공하는 것이다. 또 다른 좋은 point는 job은 pod의 label들을 관리한다는 것으로 pod의 label을 직접적으로 개발자가 관리하지 않아도 된다.
물론 job없이도 위의 일들이 가능하다. 다만, 이는 매우 어려운 일이며 직접 만들기에는 꽤나 피곤한 일이다.
restartPolicy를 가진 job만들기
job을 만드는 것은 advanced한 configuration을 요구하기 때문에 declarative syntax를 쓰는 것이 좋다. 우리는 pod가 만들어져서 Hello world라는 메시지를 출력하도록 하는 job을 만들도록 할 것이다.
hello-world-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", -c]
args: ["echo 'Hello world'"]kind부분의 resource가 Job인 것에 집중하도록 하자. 이는 우리가 만들 resource가 pod가 아닌 job이라는 것을 kubernetes에게 알려주는 것이다. 또한, apiVersion을 보면 pod와 다른 것을 볼 수 있다. job의 경우는 batch/v1을 써준다.
위의 job에서 만들 pod의 docker image는 busybox이다. busybox는 실행되고 echo 'Hello world'라는 메시지를 /bin/sh -c로 실행하는 것이다.
마지막으로, restartPolicy option이 .OnFailure인데 이는 kubernetes에게 해당 job이 실패하게되면 pod 또는 container를 다시 실행하라는 것이다. 만약 job을 실행해서 pod가 실패하면 다시 새로운 pod가 시작되게 된다. 만약, container가 실패한다면 해당 container는 같은 node에 다시 실행될 것이다. 왜냐하면 pod는 계속해서 가만히 남아있는 상태이기 때문에 pod는 여전히 같은 machine에 스케줄링된다는 것이고, container도 같은 machine(woroker node)에서 다시 생성된다는 것이다.
restartPolicy 파라미터는 두 가지 옵션들을 가질 수 있다.
1. Never
2. OnFailure
Never로 설정하면 pod가 실행에 실패하여도 pod가 재설치되는 것을 막는다. 추후에 job을 디버깅할 때 restartPolicy를 Never로 두는 것이 좋다. 안그러면 계속해서 새로운 pod들이 생겨나기 때문이다.
이제 우리의 job을 실행시켜보도록 하자.
kubectl create -f hello-world-job.yaml
job.batch/hello-world-job created실행이 완료되었다면, 원하는대로 job이 실행되었는 지 확인해야한다. 즉, Hello world를 출력했는가 이다. 이를 확인하기 위해서 kubectl logs를 사용하면 된다. kubectl logs <pod-name>을 사용하면 stdout, stderr에 찍힌 내용들을 볼 수 있다.
kubectl logs hello-world-job-dxstw
Hello world성공한 것을 볼 수 있다. 만약 실패한 경우 restartPolicy가 OnFailure이기 때문에 10초후에 재시작, 20초후에 재시작, 40초후에 재시작... 이렇게 2배를 곱한 시간 후에 재시작을 했다가 6분이 지나면 재시작도 멈춘다.
Job의 backoffLimit
기본적으로 kubernetes job은 6분 동안의 6번의 시도가 끝나면 pod의 재시작을 포기한다. backoffLimit 옵션을 수정하여 이 옵션을 수정할 수 있다. 이 횟수를 정하면 횟수만큼만 pod를 다시 시작한다.
hello-world-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
backoffLimit: 3
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", "-c"]
args: ["echo 'Hello world'"]다시 실행해서 실패할 경우 pod를 두 번만 재시작하고 종료한다.
comletions를 사용하여 여러 번 task를 동작시키기
completions 옵션을 사용하여 job에서 실행하는 command의 횟수를 지정할 수 있다. 단, 이는 pod를 재시작시킴으로서 이루어지기 때문에 하나의 명령어 후 pod를 새로 생성하는 방식이다.
hello-world-jon.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
completions: 10
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", "-c"]
args: ["echo 'Hello world'; sleep 3"]completions option이 추가되었다. 또한, args 옵션의 sleep 3도 추가되었다. 이는 job이 끝나기 이전에 다음 pod가 실행되기 위한 충분한 시간을 주는 것이다.
kubectl create -f hello-world-job.yaml다음의 명령어로 실행 한 뒤, completions이 있는 job이 어떻게 실행되는 지를 보고 싶다면 watch로 kubectl get po -A를 감시하면 된다.
watch kubectl get po -A실시간으로 job에 의해 pod들이 실행되고 완료되고, 실행되고 완료되고가 반복되는 것을 볼 수 있다.
kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default hello-world-job-2b699 0/1 Completed 0 2m32s
default hello-world-job-2c9jc 0/1 Completed 0 102s
default hello-world-job-2nlmc 0/1 Completed 0 2m18s
default hello-world-job-98j7l 0/1 Completed 0 117s
default hello-world-job-csvwp 0/1 Completed 0 95s
default hello-world-job-hqf8j 0/1 Completed 0 2m25s
default hello-world-job-htsp5 0/1 Completed 0 2m4s
default hello-world-job-j9msf 0/1 Completed 0 2m40s
default hello-world-job-mb8mw 0/1 Completed 0 2m11s
default hello-world-job-prkg8 0/1 Completed 0 110s다음의 결과가 나올 것이다. completions를 10으로 한 만큼 10개의 pod들이 실행되었다가 종료된 것을 볼 수 있다.
task를 병력적으로 여러 번 실행시키기
completions 옵션은 하나의 pod가 생성되고 실행된 다음 종료된 후 새로운 pod가 실행되는 방식이다. 그러나 parallelism 옵션을 주면 병렬적으로 여러 개의 pod를 실행시킬 수 있다.
hello-world-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
parallelism: 5
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", "-c"]
args: ["echo 'Hello world'"]completions 부분을 parallelism으로 변경해주면 된다. 이제 실행시켜주도록 하자.
kubectl create -f hello-world-job.yaml결과를 확인하면 다음과 같다.
kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default hello-world-job-4qhpl 0/1 ContainerCreating 0 4s
default hello-world-job-6g4m2 0/1 ContainerCreating 0 4s
default hello-world-job-cbwb7 0/1 ContainerCreating 0 4s
default hello-world-job-n4c7h 0/1 ContainerCreating 0 4s
default hello-world-job-wnd48 0/1 ContainerCreating 0 4s병렬적으로 5개의 pod가 job에 의해서 병렬적으로 실행되는 것을 볼 수 있다.
특정 시간 이후에 job을 종료시키기
job의 pod(process)를 특정 시간 후에 종료시키도록 할 수도 있다. 가령, queue에 있는 message를 가져올 때 좋은데, 1분간 message를 polling하고 자동적으로 process를 죽이도록 하는 것이다. activeDeadlineSeconds 파라마터를 설정해주면 된다.
hello-world-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
backoffLimit: 3
activeDeadlineSeconds: 60
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", "-c"]
args: ["while true; do echo 'Doing something'; sleep 1; echo 'Doing other things'; done"]여기 60초 뒤에 종료되는 job이 있다. 무엇이 실행되든간에 정해진 시간동안 process를 실행되도록 하고, 종료되게 한다면 activeDeadlineSeconds를 사용하면 된다. 위의 경우는 무한 루프로 계속해서 로그를 출력하도록 하는데 정확히 60초 뒤에 Running에서 Terminating으로 바뀐 뒤 job이 종료되어 사라진다.
job이 성공한다면 무엇이 발생하는가?
만약 job이 끝났다면 kubernetes cluster 내부에 남아있고, 자동적으로 삭제되지 않을 것이다. 이는 기본적인 동작이다. 이 동작의 이유는 job이 끝난 뒤에도 log를 읽을 수 있기 때문이다. 그러나 대게의 경우 완료된 job을 남기는 것이 좋지 않을 수 있다. ttlSecondsAfterFinished라는 옵션을 사용함으로서 job이 생성한 pod들과 job을 삭제할 수 있다.
hello-world-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
ttlSecondsAfterFinished: 30
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", "-c"]
args: ["echo 'Hello world'"]위는 job이 comleted 상태로 변경된 이후 30초 후에 종료된다.
그러나 이 옵션은 kubernetes v1.20까지만 해도 alpha feature였다. kubernetes v1.21 이후에는 TTL Controller가 beta로 들어왔고 기본적으로 적용된다. v1.21이전까지에는 다른 설정을 해주어야지만 해당 option이 실행된다. 다음을 참고해보도록 하자.
https://stackoverflow.com/questions/58269983/jobs-not-deleting-after-completion-with-ttlsecondsafterfinished
job 삭제하기
kubernetes job을 직접 삭제하는 방법이 있다. job을 삭제하는 것은 job에서 관리하는 pod를 삭제하는 것도 포함된다. 따라서 job을 죽이면 pod도 죽는다.
kubectl delete jobs <pod-name>을 통해서 죽을 수 있다.
kubectl delete jobs hello-world-job
...
job.batch "hello-world-job" deleted만약 job은 없애고 싶지만 pod는 죽이고 싶지않다면 --cascade=false라는 옵션을 주면 된다.
kubectl delete jobs hello-world-job --cascade=false이를 통해서 job은 죽이고 실행 중인 pod는 남겨서 pod가 안전하게 comletion 되도록 할 수 있다.
Cronjob 시작하기
Cronjob은 두 가지 의미를 가질 수 있는데 매우 중요하다.
- UNIX cron feature
- Kubernetes Cronjob resource
Cronjobs는 cron UNIX feature를 사용하는 스케줄링 command이다. cron UNIX feature는 명령어의 실행을 스케줄링하는 가장 견고한 방법으로 이 아이디어를 kubernetes로 차용한 것이다.
kubernetes에서는 command의 실행을 스케줄링하는 것이 아니라, pod의 실행을 스케줄링하는 것이다. 이를 Cronjob resource를 사용하여 이룰 수 있다.
UNIX의 cron과 kubernetes의 CronJob이 마치 비슷해보이지만 사실은 이들은 전혀 비슷하지도 않다. UNIX는 Crontab이라 불리는 파일을 수정함으로서 명령어를 스케줄링할 수 있다. kubernetes에서는 좀 다른데, 명령어의 실행을 스케줄링하는 것이 아니라, job resource의 실행을 스케줄링하는 것으로 job 자체로 pod resource들을 생성한다. 이러한 일을 Cronjob이라고 불리는 새로운 종류의 resource를 manipulating함으로서 실행시킬 수 있다. Cronjob object는 job object를 만드는 일이라는 것을 명심하도록 하자.
사실 간단하게 생각하면 CronJob은 kubernetes 상에서 job resource의 wrapper이고, 이를 controller라고 부른다. Cronjob은 job resource가 할 수 있는 모든 것들을 할 수 있다. 왜냐하면 지정된 cron 표현에 따라 Cronjob은 job resource의 wrapper일 뿐이기 때문이다.
재밌는 점은 kubernetes의 Cronjob은 UNIX의 cron과 같은 형식을 가진다.
Cronjob의 예시들은 다음과 같다.
- database backup을 정규적으로 매 일요일 1시마다 하고싶다.
- 매 월요일 4시마다 캐시를 삭제하고 싶다.
- 매 5분마다 큐잉된 메일을 보내고 싶다
- 정규적으로 실행될 유지 보수 관리 작업을 실행하고 싶다.
use case만 보면 UNIX의 cron과 kubernetes의 Cronjob은 크게 다를바 없다. 단지 UNIX의 cron을 Kubernetes상에 맞게 가져온 것 뿐이다.
Cronjob 만들기
declarative syntax로 Cronjob을 만들기 위해서 cronjob.yaml 파일을 먼저 만들도록 하자.
cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello-world-cronjob
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
metadata:
name: hello-world-job
spec:
restartPolicy: OnFailure
containers:
- name: hello-world-container
image: busybox
command: ["/bin/sh", "-c"]
args: ["echo 'Hello world'"]apiVersion부분에 batch을 넣으며, spec의 schedule에 cron표현을 쓸 수 있다. jobTemplate부분에는 동작시킬 job을 적으면 된다.
schedule 부분에 linux의 cron format을 적용할 수 있다고 하였다. 그럼 cron format이 무엇인지 알아보도록 하자.
cron 표현은 5개의 entry들로 구성되어 있는데, 이들은 white space로 구분되어 진다. 왼쪽부터 오른족으로 해당 entry들은 다음에 상응한다.
- 분
- 시
- 날
- 달
- 요일
각 entry는 asterisk로 채워질 수 있는데 이는 모든(every)라는 의미이다. 또한, 하나의 entry에 구분자로 ,을 써서 여러 개의 값들을 넣을 수도 있다. range operation도 가능한데, 이 경우 -을 사용하면 된다. 다음의 예시를 보도록 하자.
10 11 * * *는 매일 매달, 11:10분에 실행하라10 11 * 12 *는 12월에 매일 11:10분에 실행하라10 11 * 12 1는 12월의 월요일마다 11:10분에 실행하라10 11 * * 1,2는 매달 월요일 화요일마다 11:10분에 실행하라10 11 * 2-5 *는 2월에서 5월까지 매일 11:10분에 실행하라
물론 모든 cron format을 외울 필요는 없다. 이미 많은 사람들이 예시를 적어놓았고 툴도 만들어놓았기 때문에 필요할 때마다 찾아보면 된다.
다음으로 job을 명시한 jobTemplate부분이다. 해당 부분에 job object의 정의가 포함되어있다는 것을 알 수 있다. Cronjob object를 사용할 때, job object의 생성을 Cronjob object에게 위임한다. 따라서, Cronjob을 정의할 때 jobTemplate부분이 필요한 것이다.
따라서, Cronjob object는 오직 또 다른 자원을 제어하는 자원에 불과하다.
kubernetes 상에서 Cronjob object처럼 동작하는 경우들이 굉장히 많다. 추후에 가령, pod를 만드는 special한 obejct가 있는데 이를 controllers라고 한다. 이는 그들의 logic에 따라 kubernetes resource들을 제어하는 object이다.
따라서, Cronjob처럼 다른 kubernetes object의 생성, 관리를 위임받아 처리하는 object들이 있다는 것을 알아두도록 하자.
참고로, Cronjob이 어떠한 이유로 실행에 실패하게 되면, 해당 시점의 실행될 예정인 job은 실행되지 않는다. 또한, Cronjob이 완료되면 실행이 정상적으로 성공했든 아니든 history는 kubernetes cluster에 저장된다. 해당 history setting은 Cronjob level에서 설정될 수 있어, 각 Cronjob의 history를 저장할 지 안할지 결정할 수 있다.
Cronjob 생성하기
yaml manifest file이 있다면 Cronjob object를 만드는 것은 굉장히 쉽다. 이전과 같이 kubectl create -f 명령어를 사용하면 된다.
kubectl create -f ./cronjob.yaml
cronjob.batch/hello-world-cronjob created이제 매일 매시간 1분마다 job이 실행될 것이다.
Cronjob 삭제하기
다른 kubernetes resource들과 마찬가지로 kubectl delete를 통해서 삭제할 수 있다.
kubectl delete -f ./cronjob.yaml 