스케줄링 알고리즘
스케줄링 알고리즘은 비선점형 알고리즘(non-preemptive algorithm)과 선점형 알고리즘(preemptive algorithm)으로 나뉜다. 선점형 알고리즘은 시분할 시스템으로 어떤 프로세스가 CPU를 할당받아 실행 중이라도 운영체제가 CPU를 강제로 빼앗을 수 있다. 반면 비선점형 알고리즘은 프로세스에게 할당받은 CPU를 강제로 빼앗을 수 없어 효율이 좋지 않아 사용하지 않는다.
한국어로 ``선점```이라고 하면 헷갈리는데 preemptive는 '우선적인'이라고 생각하면 된다. 프로세스가 CPU를 점유하는데 우선적으로 해야할 일이 있다면 CPU를 빼앗아 다른 프로세스를 실행시켜준다는 것이다.
- 스케줄링 알고리즘 종류
- 비선점형 알고리즘 : FCFS 스케줄링, SJF 스케줄링, HRN 스케줄링
- 선점형 알고리즘 : 라운드 로빈 스케줄링, SRT 스케줄링, 다단계 큐 스케줄링, 다단계 피드백 큐 스케줄링
- 비선점형, 선점형 알고리즘 : 우선순위 스케줄링
1. 스케줄링 알고리즘의 선택 기준
어떤 알고리즘의 효율성 평가 기준은 다음과 같다.
- CPU 사용률 : 전체 시스템의 동작 시간 중 CPU가 사용된 시간을 측정하는 방법이다. 100%이면 CPU를 효율적으로 사용했다는 것이므로 좋은 의미이다.
- 처리량 : 단위 시간 당 작업량으로 클수록 좋다.
- 대기 시간 : 작업을 요청한 프로세스가 시작하기 전까지 대기하는 시간이다. 짧을 수록 좋다.
- 응답 시간 : 프로세스 시작 후 출력 또는 반응이 나올 때까지 걸리는 시간으로 짧을 수록 좋다.
- 반환 시간 : 프로세스가 종료되어 자원을 모두 반환하는 데까지 걸리는 시간이다. 반환 시간은 대기 시간과 실행 시간을 더한 값이다.
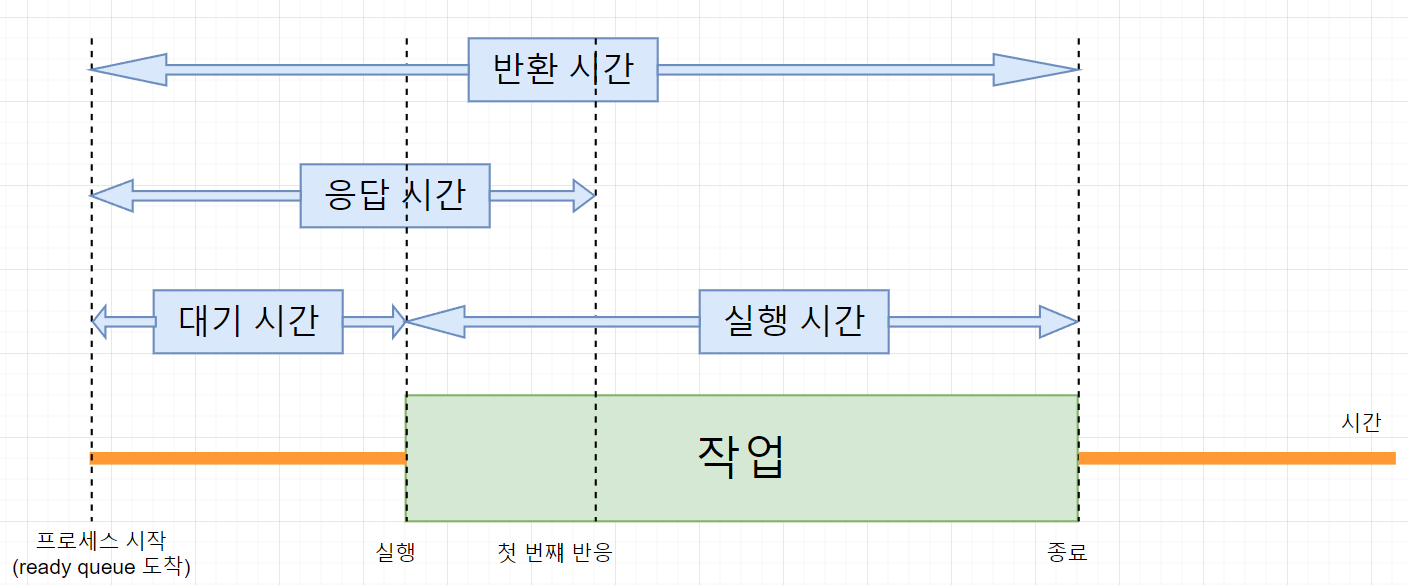
시간들이 매우 애매할 텐데 정리하면 다음과 같다.
여기서 대기 시간이 매우 중요하다. 보통 스케줄링 성능을 비교할 때 주로 평균 대기 시간을 본다. 평균 대기 시간은 모든 프로세스의 대기 시간을 합한 뒤 프로세스의 수로 나눈 값이다.
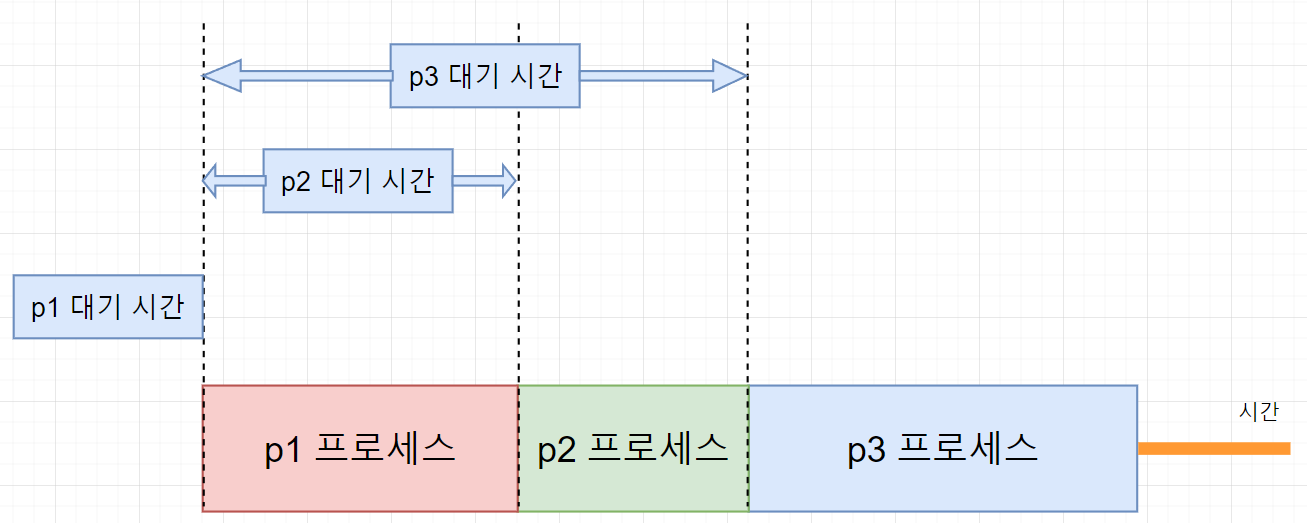
즉, 위의 예제에서 평균 대기 시간은 (p1 대기시간 + p2 대기시간 + p3 대기시간) / 3이 된다.
참고로 p1은 대기 시간없이 바로 실행되므로 대기 시간이 0이다.
2. FCFS 스케줄링
FCFS(First Come First Served) 스케줄링은 ready 큐에 도착한 순서대로 CPU를 할당하는 비선점형 방식이다. 다른 말로 FIFO(first in first out)라고도 한다.
즉, 프로세스가 ready queue에 도착한 순서대로 실행되며 비선점형 방식이기 때문에 한 번 실행되면 그 프로세스가 끝나야만 다음 프로세스를 실행할 수 있다. 게다가 큐가 하나라 모든 프로세스는 우선순위가 동일하다.

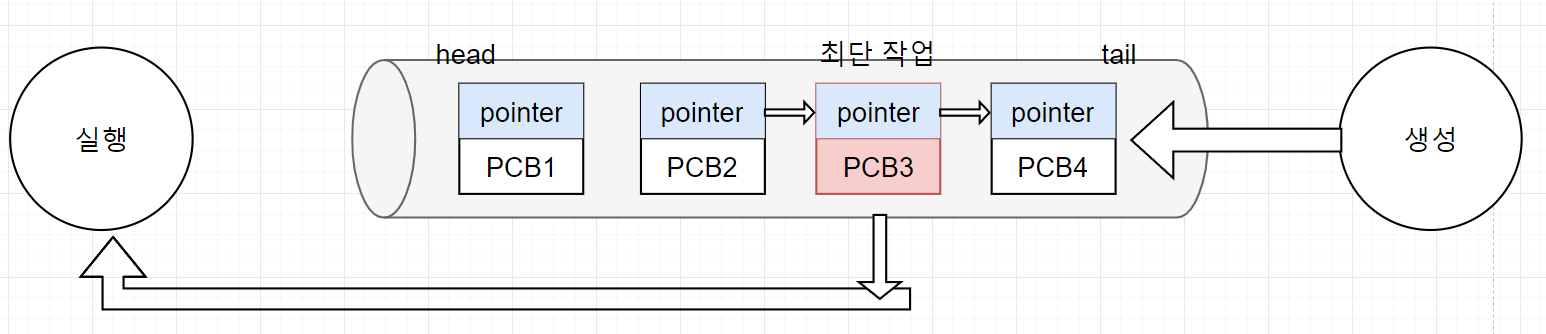
다음과 같이 ready 큐는 head, tail이 있는 linked list 형태로 만들어져 있고, head에서 실행할 프로세스를 하나씩 빼낸다. 또한 tail에는 앞으로 실행할 프로세스들을 차곡차곡 쌓아둔다.
이렇게 실행 상태로 간 프로세스는 CPU 자원을 할당받고, 프로세스가 완료될 때까지 CPU를 놓지않는다.(비선점)
2.1 FCFS의 성능
FCFS 스케줄링 알고리즘은 단순하고 공평하지만, 처리 시간이 긴 프로세스가 CPU를 차지하면 다른 프로세스들은 하염없이 기다려 시스템의 효율성이 떨어지는 문제가 있다. 이를 convoy effect 또는 호위 효과라고 한다.
즉, 화장실을 기다리는데 있어서 소변보는 사람은 20초만을 쓰고 대변보는 사람은 5분을 쓴다고하자, 소변보는 사람이 먼저들어가면 대변보는 사람은 20초 기다린다. 그러나 대변보는 사람이 먼저들어가면 소변보는 사람은 5분이나 기다려야 한다.
이것이 처리 시간이 긴 프로세스를 앞에 둠으로서 효율성이 쭉 떨어지는 convoy effect이다.
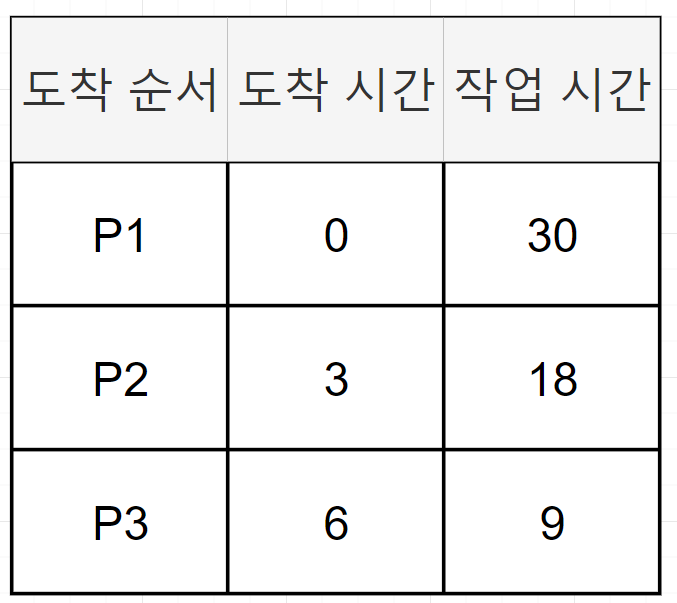
다음의 예제를 보자
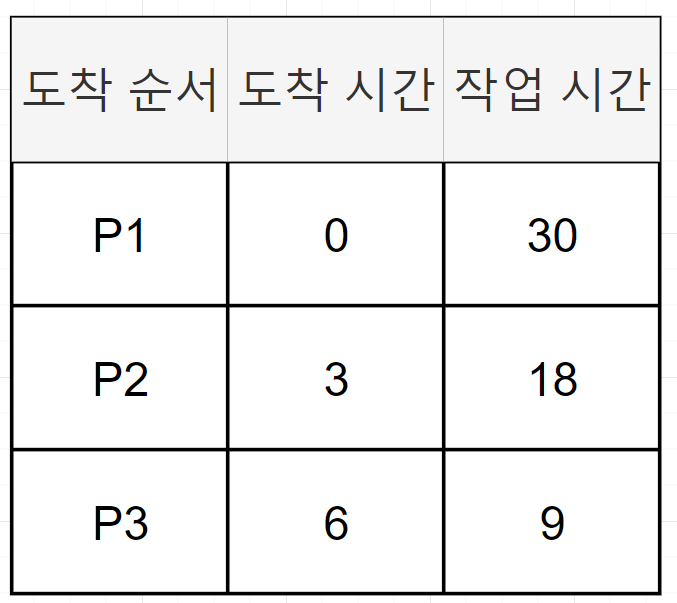
위의 테이블을 기반으로 FCFS 스케줄링의 그림을 그려보자
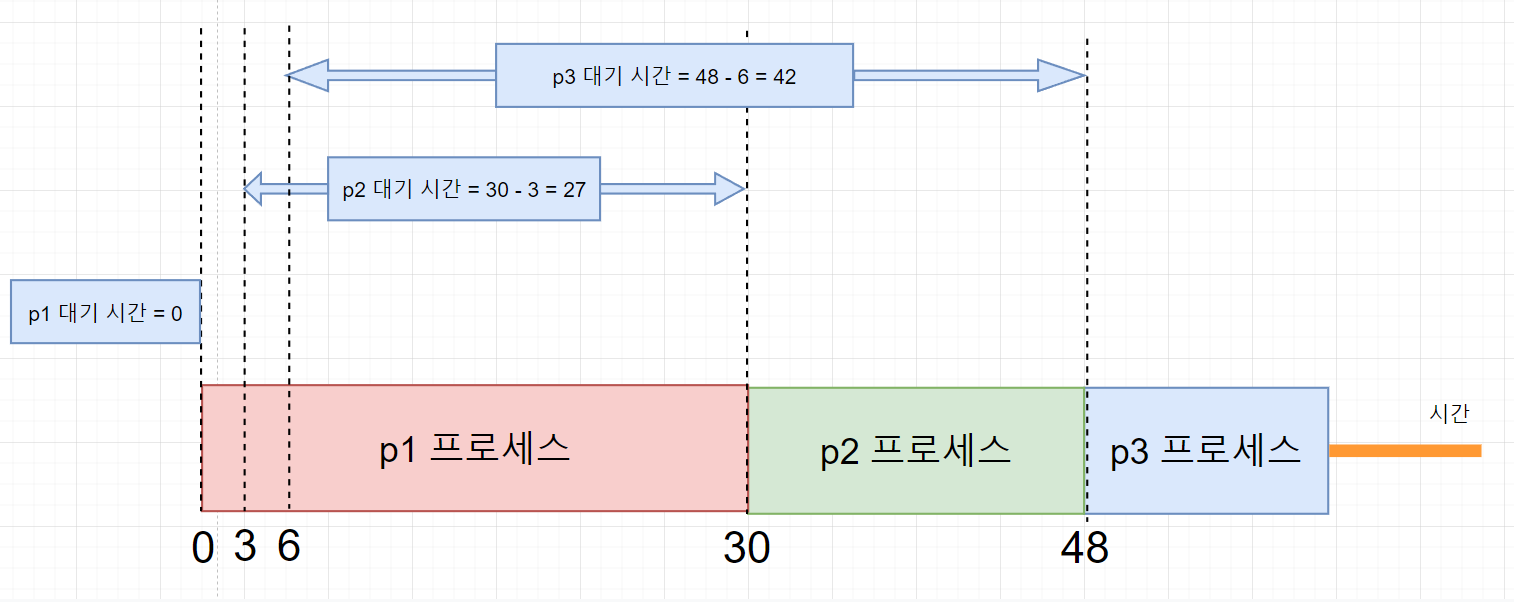
p1, p2 , p3가 순서대로 ready queue에 도착했다고 가정하자. p1은 0ms, p2는 3ms, p3는 6ms에 도착했다.
- p1는 도착하자마자 시작되므로 대기시간이 0이다.
- p2는 3ms에 도착했지만 p1이 끝나기 전까지 시작하지 못한다. 따라서, 30ms까지 기다리게되고 30-3=27ms 대기시간을 가지게 된다.
- p3는 6ms에 도착했지만 p1, p2가 끝날 때까지 시작하지 못한다. 따라서 48ms에 시작하므로 48-6=42ms 대기시간을 갖게 된다.
따라서, 평균 대기 시간은 (0+27+42)/3 = 23ms가 된다.
3. SJF 스케줄링
SJF(Shortest Job First) 스케줄링은 ready queue에 있는 프로세스 중에서 실행 시간이 가장 짧은 작업부터 CPU를 할당하는 비선점형 방식으로 최단 작업 우선 스케줄링이라고도 한다.
대변을 보려고 준비하려고 할 때 뒤에 있는 소변보려고 하는 사람이 먼저 양해를 구하고 소변을 보게되는 알고리즘이다.
SJF 스케줄링은 프로세스에 CPU를 배정할 떄 시간이 오래 걸리는 작업이 앞에 있고 간단한 작업이 뒤에 있으면 순서를 바꾸어 실행한다. FCFS 스케줄링의 convoy effect를 완화하여 시스템의 효율성을 높이는 것이다.
다음과 같이 최단 작업이라고 평가되면 최단 작업 프로세스를 먼저 올력서 실행한다.
3.1 SJF 스케줄링의 성능
FCFS 스케줄링과 SJF 스케줄링의 성능 차이를 비교하기 위해, 위와 똑같은 예제를 SJF 알고리즘으로 평가해보았다.
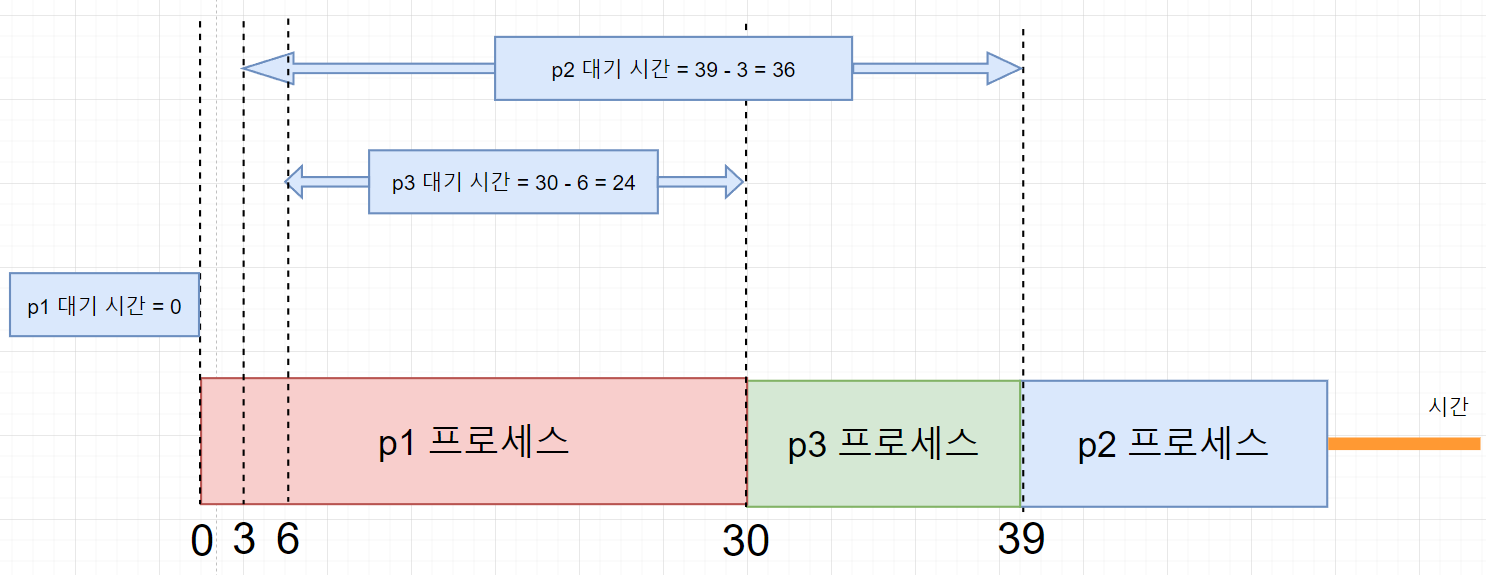
- 0ms에 프로세스 p1이 들어오고 바로 시작한다 대기시간은 0ms이다.
- 3ms에 p2가 들어오고 ,6ms에 p3가 들어온다. 비선점 방식이기 때문에 p1이 30ms까지 계속 작업을 진행한다.
- 30ms에 p2,p3 중에 작업 시간이 가장 짧은 프로세스를 먼저 작업 시킨다. p2는 18ms, p3는 9ms이므로 p3를 먼저 실행시킨다.
- p3가 30ms에 시작하므로 30-6 = 24ms 대기시간을 갖게 된다.
- p3가 끝나게되면 39ms가 되고, 39ms에 p2가 실행된다. p2는 3ms에 들어왔으므로 대기시간이 39-3= 36ms가 된다.
따라서 평균 대기 시간은 (0 + 24 + 36) / 3 = 20ms이다.
FCFS 스케줄링보다 평균 대기 시간이 줄어들어 시스템 효율성이 높아졌다. SJF스케줄링은 작은 작업을 먼저 실행하기 때문에 시스템 효율성이 좋아진 것이다. 즉, 먼저 도착한 큰 작업으로 인해 작업이 지연되는 FCFS 스케줄링과는 달리 작은 작업 시간을 갖는 일을 처리하여 효율을 높인 것이다.
그러나 SJF스케줄링은 다음과 같은 이유로 사용하기 힘들다.
-
운영체제가 프로세스의 종료 시간을 정확하게 예측하기 어렵다.
현대 운영체제에서는 프로세스의 작업 길이를 추정하는 것이 어렵기 때문에 SJF 스케줄링을 사용하기 힘들다. -
공평성이 부족하다
p1이 ready queue에서 작업을 기다리고 있는데 p1보다 작업 시간이 적은 p2, p3, p4, pn... 들이 계속 들어온다면 p1은 일을 할 수 없다.
이렇게 작업이 계속 연기되는 현상을 starvation 현상 또는 무한 봉쇄(infinite blocking현상)이라고 한다. 작업 시간이 길다는 이유만으로 계속 뒤로 밀린다면 공평성이 현저히 떨어지게 된다.
물론 해결 방법이 아주 없는 것은 아니다. 첫번째는 작업시간을 미리 알려주는 방법과 두 번째는 aging이라고 하여 양보를 할 시에 나이를 먹게하여 aging이 나이가 일정 수준 이상먹으면 해당 프로세스를 무조건 실행시키게 하는 것이다.
그러나, 미리 실행 시간을 알려주는 방식도 한계가 있고, 나이를 먹게하는 aging 값을 어떤 기준으로 정할 것인가하는 문제도 있다.
따라서, SJF 스케줄링은 종료 시간을 파악하기 어렵고 starvation 현상이 일어나기 때문이 잘 사용하지 않는다.
4. HRN 스케줄링
HRN(Highest Response Ratio Next) 스케줄링은 SJF에서 발생할 수 있는 starvation 현상을 해결하기 위해 만들어진 비선점형 알고리즘으로, 최고 응답률 우선 스케줄링이라고도 한다. 기본적으로 SJF을 기반으로, 대기 시간을 고려한 변형이다.
SJF 스케줄링은 프로세스의 실행 시간이 판단 기준이기 때문에 항상 적은 시간을 사용하는 프로세스에 우선권이 주어지지만, HRN 스케줄링은 서비스를 받기 위해 기다린 시간(대기 시간)과 CPU 사용 시간을 고려하여 스케줄링을 하는 방식이다. HRN 스케줄링에서 프로세스의 우선순위를 결정하는 기준은 다음과 같다.

HRN 스케줄링은 우선순위를 정할 때, 대기 시간을 고려함으로서 starvation 현상을 완화한다. 위의 식이 최고 응답률(Highest Response Ratio)이 되겠다. 즉, 응답을 주기까지 가장 오래걸리는 시간을 비율로 환산한 것이다.
당연히 대기 시간을 고려함으로, 대기 시간이 높을 수록 우선순위가 높다. 즉, 우선순위가 높을수록 먼저 실행된다는 것이다.
즉, 스케줄링 방식에 aging을 구현한 것이다. 다음의 예제를 보자
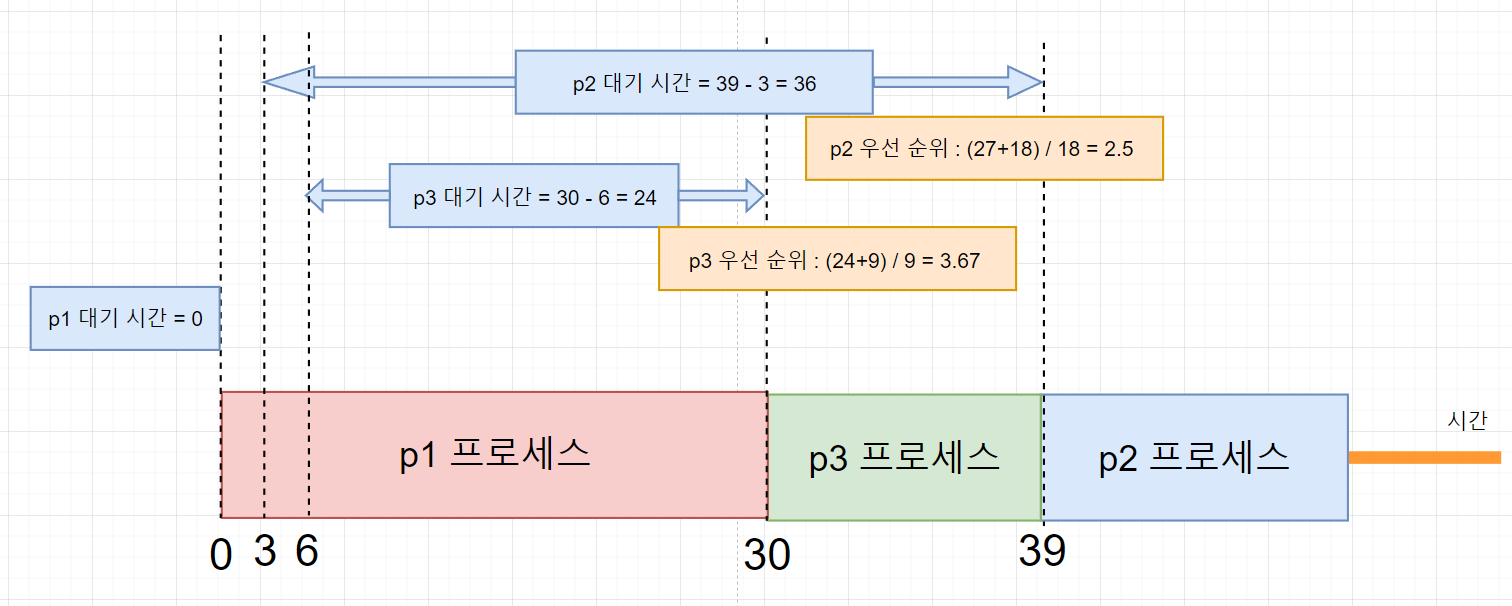
- 먼저 p1이 30ms동안 실행된다. 이때 ready queue에 있는 p2와 p3의 우선순위를 계산한다.
- p2는 3ms에 들어오고 30ms(p1이 끝나고 다음 process가 실행할 수 있는 시간)에 실행하면 대기시간 27ms이다. 따라서 (27ms+ 18ms)/ 18ms = 2.5ms이다.
- p3는 6ms에 들어오고 30ms에 실행하면 30ms-6ms = 24ms가 대기시간이다. 실행 시간이 9ms이므로 (24 + 9) / 9 = 3.67ms이다.
- HRN는 최고 응답률이 높을수록 우선순위가 높기 때문에 p3가 먼저 실행되고 p2가 실행된다.
대기 시간은 (0 + 24 + 36)/3 = 20ms가 된다.
4.1 HRN 스케줄링의 평가
HRN 스케줄링은 실행 시간이 짧은 프로세스의 우선순위를 높게 설정하면서도 대기 시간을 고려하여 starvation 현상을 완화한다.
SJF 스케줄링과 비교하면 대기 시간이 긴 프로세스의 우선순위를 높임으로서 CPU를 할당받을 확률을 높인다. 그러나 여전히 공평성이 위배되어 많이 사용되지 않는다.
