![]()
쿽정렬
이전에 병합 정렬이 O(nlogn)에 실행된다는 것을 알게되었다. 퀵정렬은 병합 정렬보다는 구현과 이해가 어렵지만, 메모리적으로 이득이 있어 많은 정렬 프로그램에 사용되는 알고리즘이다. 가장 대표적인 예로 c++의 sort stl은 내부가 퀵정렬로 구현되어있다.
1. 개요
병합 정렬의 단점이 무엇인가?? 병합 정렬을 구현해보면 자연스레 알게되는데, 병합 정렬은 정렬하려는 배열의 사이즈만큼 새로운 메모리가 필요하다는 것이다. 이는 메모리 오버헤드가 크기에 비례하여 커진다는 것이다.
이에 반해, 쿽정렬은 새로운 메모리를 추가하지않고 기존 배열에서 정렬을 수행한다. 따라서, 병합 정렬과 시간은 똑같은 O(nlogn)에 수행되지만 메모리 오버헤드가 없다는 장점이 있다.
다만, 앞서 이야기했듯이 구현과 이해가 어렵다는 단점이 있어, 그냥 쌩으로 정렬 코드를 만들라고 하라면 그냥 병합 정렬 코드를 구현하는 것이 건강에 좋다. 또한, 쿽정렬은 평균적으로 O(nlogn)시간에 수행된지만, 최악의 경우에는 O(n^2)이 걸린다.
그럼 쿽정렬의 원리에 대해서 알아보자
2. 원리
만약 쿽정렬을 오늘 처음봤다면 '혹시 내가 이해할 수 있을까?' 라는 고민은 하지말자

이해가 될리가 없기 때문이다 ^^
각설하고, 쿽정렬을 가장 쉽게 이해하는 원리는 다음과 같다.
'배열 안의 각 숫자들은 정렬되었을 때, 자신들의 자리가 있을 것이다.'
뭔 개소리인가 할 수도 있지만, 마치 이런 의미이다.

우리 반에서 키 순서대로 친구들을 오름차순 정렬한다면, 내 자리는 K번째 자리일 것이다.
그렇다면, K번째 자리라는 것은 사실상 운명과도 같다. 왜냐하면 내 키나, 친구들의 키가 변하지 않는 한, 100번 1000번을 정렬해도 난 K번째 자리에 해당될 것이기 때문이다.
마찬가지로 배열 안의 숫자들을 오름차순으로 정렬해보자.
그럼, 각 원소들은 정렬되었을 때 자신만의 자리가 있을 것이다.
이 자리는 같은 원소를 100번 1000번 정렬해도 똑같은 자리이다.
[2,1,5] 를 정렬한다면, 2라는 값을 가진 원소는 정렬되었을 때 [1,2,5] 이므로 두번째 자리를 갖게 된다. 이는 자명한 사실이고, 몇 번을 반복해도 똑같은 결과가 나오게 된다.
그럼 이 사실을 더 나아가보자,
결국 각 원소는 정렬되었을 때, 자신만의 자리를 갖고 있다는 것인데, 그 자리가 어디인지 어떻게 아냐는 것이다.

아주 단순하다. 어떤 원소가 k라는 값을 가지고 있다면, 오름차순으로 정렬되었을 때 k 원소의 앞은 k값보다 작은(또는 동일한) 값을 가진다. 또한, 뒤의 값은 k보다 큰(또는 동일한) 값을 가진다.
위의 사진을 보면 k원소보다 앞은 k보다 작은 값을 가질 것이고, k원소 뒤는 k보다 큰 값을 가질 것이다.
그럼 우리는 각 원소마다 각자의 자리를 찾아주는 일을 반복하면 된다. 이것이 쿽정렬의 원리이다.
그럼 어떻게 자리를 찾아가는 지 알아보자
3. 쿽정렬 방법

다음과 같이 정렬되지않은 배열이 있다고 가정하자, 여기서 우리는 앞서 배운 쿽정렬의 원리를 되새김질 해보자
'배열 안의 각 숫자들은 정렬되었을 때, 자신들의 자리가 있을 것이다.'
따라서, 우리는 각 숫자들 마다 각자의 자리를 찾아주는 일을 반복해주면 된다.
그럼 하나의 숫자를 선택해보자, 필잔는그럼 하나의 숫자를 선택해보자, 필자는 이 값을 pivot이라고 표현하겠다.
pivot은 배열의 첫 번째 원소라고 하자
pivot = 9 가 되는 것이다.

이렇게 배열의 맨 앞 값을 pivot으로 잡아보자, 맨 뒤에 말하겠지만 맨 앞 원소를 pivot으로 잡는 것은 최악의 시나리오인 O(n^2)을 인위적으로 발생시킬 수 있는 문제를 야기하지만, 구현하기 편하므로 이렇게 하였다.
pivot이 9이므로, 9라는 원소가 오름차순 정렬 시에 있을 자리를 찾아보자,
그러기에 위해서, low와 high를 두도록 하자
pivot이 정렬된다면 pivot의 왼쪽은 pivot보다 작은 값, pivot의 오른쪽은 pivot보다 큰 값이 와야한다.
따라서, low는 piovt보다 큰 값이 pivot보다 왼쪽에 있다면 이를 찾아주는 포인터이고 high는 pivot보다 작은 값이 pivot보다 오른쪽에 있다면 이를 찾아주는 포인터이다. 따라서, high는 맨 뒤부터 시작하고, low는 pivot 앞에서부터 시작한다.

사진의 low는 left이고, high는 right이다.
그럼 이제 비교를 시작해보자, left(low)의 값이 23이고 이는 pivot보다 크다
pivot(9) < left(23) 이므로, 이는 위의 원리에 위반된다.
즉, pivot이 정렬된다면 왼쪽에 pivot보다 작은 값이 있어야 하는데, 23은 pivot보다 큰 값이므로 바꾸어주어야 한다. 따라서 left의 탐색을 여기서 멈춘다.
right의 탐색 역시도 마찬가지이다. pviot이 정렬되었다면 자신의 오른쪽에는 자신보다 큰 값이 있어야만 한다. 그런데 right(-3)은 pivot(9)보다 작으므로, right의 탐색은 여기서 멈추도록 한다.
그 다음, left와 right의 값을 서로 바꾸어주도록 한다.
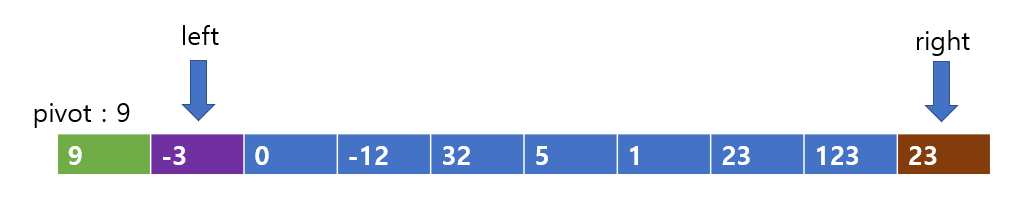
그러면 다음과 같은 모습을 갖게된다.
이 후 left먼저 탐색을 이어나가보자

left가 한 칸을 가면 0을 만난다. 9보다 작으므로 문제가 되지않는다. 그러므로 다음 칸으로 간다.

-12 역시 pivot보다 작으므로 문제가 되지 않는다. 다음 칸으로 가자

32는 pivot보다 크므로, 문제가 된다. 따라서 탐색을 멈추고 right의 탐색을 시작한다.

right의 23은 9보다 크므로 다음 칸으로 간다. 123은 9보다 크므로 다음 칸으로 간다.

23은 pivot보다 크므로 다음 칸으로 간다.

right는 1 값을 갖게되고 이는 pivot보다 작다. 따라서 원리에 위반되므로 right 탐색을 멈춘다.
이제 left와 right의 값을 서로 교환해준다.
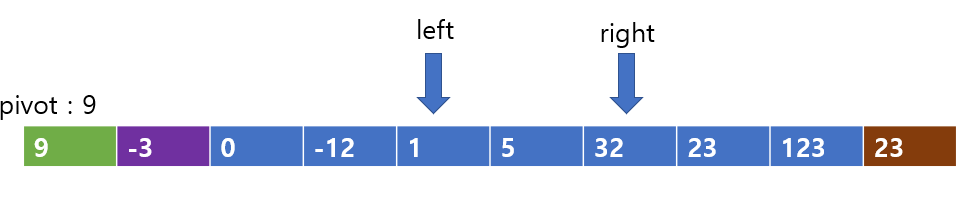
교환해준 모습이다. 이제 left의 탐색을 이어나가보자

left는 5를 만나지만 문제가 되지 않는다. 다음 칸으로 간다.
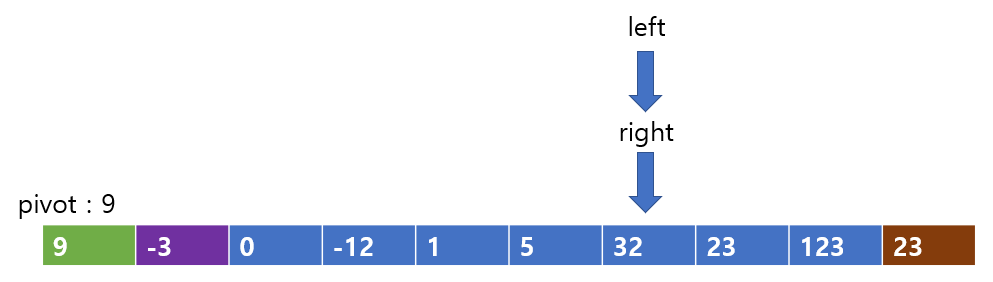
다음 칸으로 가면 left는 right와 만나게 되지만 종료하지않고 pivot과 32를 비교한다.
left가 더 크므로 원리에 어긋난다. 따라서 left는 탐색을 종료한다.

right가 탐색을 하게되면, 바로 다음 칸에 5가 있다. 5는 pivot보다 작으므로 right의 원리에 어긋난다. 또한, left와 right가 엇갈리게 된다. 즉, left <= right 가 아닌, left > right의 관계를 갖게 되는 것인데, 이는 문제가 발생한다. 왜냐하면 left의 정의를 보면 left는 pivot보다 왼쪽에 있는 값 중에 piovt보다 더 큰 값을 고르는 것이고, right의 정의는 piovt보다 오른족에 있는 값 중에 pivot보다 더 작은 값을 고르는 것이다. 그런데 left가 right보다 더 커지면 이는 pivot의 왼쪽이 아닌, 오른쪽 값을 지칭하게 되므로 정의에 어긋난다. 또한, left가 right를 앞지르게 되면 뒤로 더 갈 이유도 없다. 이유는 right가 이미 left가 앞으로 나아가야 할 부분들을 처리했기 때문이다. right도 마찬가지로 엇갈림 현상이 발생한 이후로는 더 이상 앞으로 안나가도 된다. 이 앞은 left가 이미 처리했기 때문이다.(즉, 보장된 값이라는 것이다)
여기서 left 와 right의 값을 바꾸는 것이 아니라, pivot과 right의 값을 바꾸게 된다. 이는 '엇갈림 현상' 즉, left가 right를 앞지르는 현상이 발생했다는 것은 더 이상 처리할 값이 없다는 것이고 이는 right가 가리키는 자리의 왼쪽은 pivot보다 작고, 오른쪽은 pivot보다 크다는 것이다.

따라서 pivot과 right의 값을 바꾸어주도록 하자
엇갈림 현상이 발생한 후에는 left와 right를 계속 탐색할 이유가 없기 때문에 탐색을 종료한다.
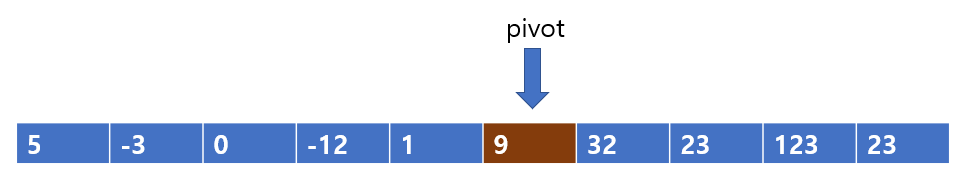
이렇게 pivot이 자신의 자리를 찾은 것이다. pviot 9의 왼쪽 값은 정렬은 안되었지만 분명 9보다 작은 값들이고, 오른쪽 값들은 분명 pivot 9보다 큰 값들이다.
이렇게 한 단계의 정렬이 끝난 것이다. pivot 9 값은 이 자리에서 움직이지 않고 그대로 일 것이다. 따라서 9는 가만히 두고 양쪽을 나누어 위의 과정을 반복해보자
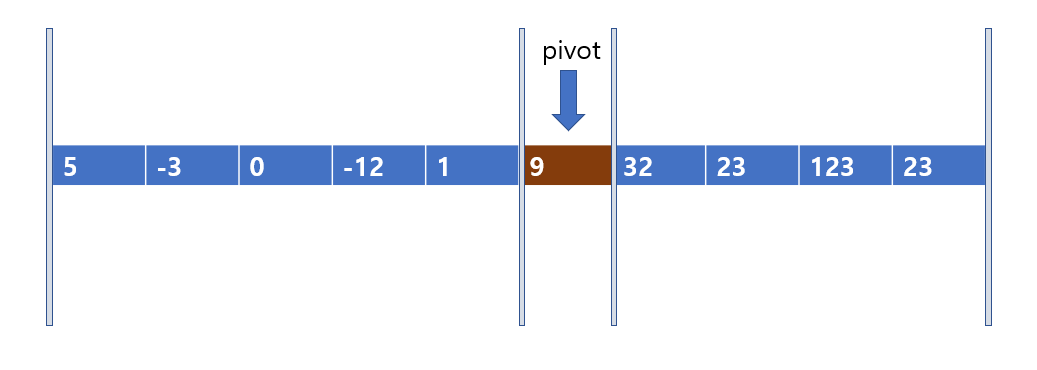
이렇게 말이다. 앞에서 언급은 안했지만, 이전 시간에 병합 정렬을 하면서 계속 분할-정복을 외쳤었다. 퀵정렬도 마찬가지로 분할-정복 알고리즘이다. O(nlogn)정렬들은 분할-정복 알고리즘이 적용되지 않으면 위의 시간복잡도 O(nlogn)을 가질 수 없다.
여기서 분할이 바로 위의 partition을 나누는 작업이다. 9는 이미 정렬되었으므로 9를 움직이게 할 필요가 없다. 따라서 9를 기준으로 양 옆을 나누는 것이다. 양 옆을 나누고 무엇을 하는가? 무엇을 하긴 또 pivot을 잡고 pivot의 정렬되었을 때의 자리를 찾아주는 위의 과정을 반복해주면 된다. 이것이 정복이다.
- 분할 : 파티션을 나누어 정렬된 부분은 건드리지 않는 과정
- 정복 : 각 파티션마다 피벗을 두어 피벗이 정렬되었을 때의 자리를 찾아주는 과정
이라고 생각하면 된다.
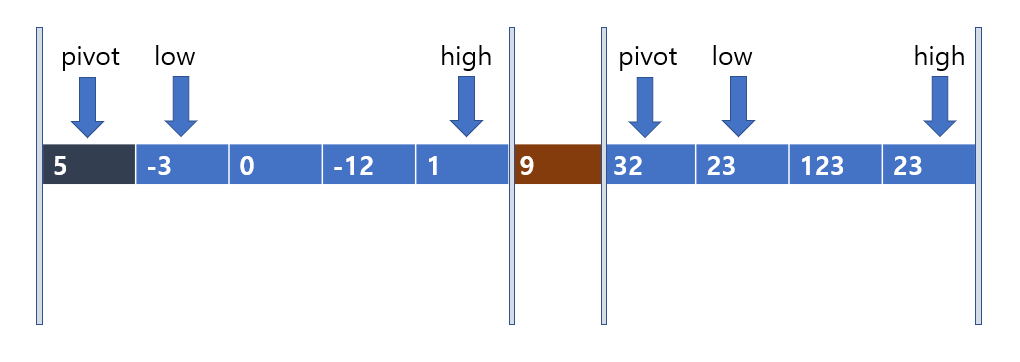
'분할'은 되었으니, 이제 다음의 그림처럼 '정복'을 해주면 된다. 9를 기준으로 왼쪽 파티션과 오른쪽 파티션을 나누었다. 왼쪽 파티션은 pviot이 5이고, 오른쪽 파티션은 pivot이 32인 것이다. 다음의 각 파티션들의 pivot이 정렬되었을 때의 자리를 찾으면 다음과 같다.
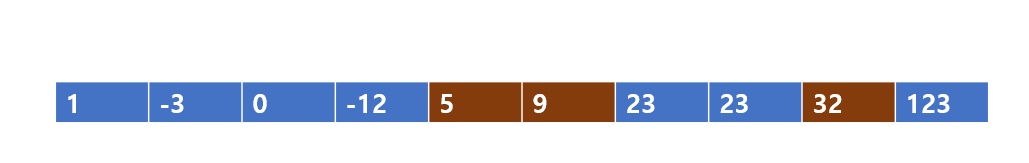
갈색으로 표시한 것이다. 그렇다면 응용을 해보자, 파티션들은 어디어디에 생길까??
바로 [1,-3,0,-12] , [23,23] ,[123] 이렇게 나뉘고 pivot을 잡고 다시 정복의 과정을 반복한다. 반복한 결과는 다음과 같다.

정렬이 완성된 모습이다.

미안하다!
쿽정렬은 한 번에 이해가 안되는 알고리즘 중에 하나 인 것 같다.
처음에는 어렵지만 원리를 잘 기억하고 되새기도록 하자
쿽정렬 원리 : 모든 원소는 정렬되었을 때 자신의 자리를 갖고 있다. 그 자리는 자신의 왼쪽은 자신보다 작은 값들이고, 오른족은 자신보다 큰 값들이다.
정리.
1. 쿽정렬의 원리를 되새기자
2. pivot을 잡아 쿽정렬의 원리대로 정렬되었을 때의 자리를 찾아주도록 하자
3. left는 pivot이 정렬되었을 때의 자리에서 왼쪽에 있는 값중에 pivot보다 큰 값을 걸러내고, right는 pivot이 정렬되었을 때의 자리에서 오른쪽에 있는 값 중에 pivot보다 작은 값을 걸러내도록 한다.
4. 따라서, left는 pivot보다 큰 값을 만나면 멈추고, right는 pivot보다 작은 값을 찾으면 멈춘다.
5. left와 right의 값을 바꾸어 준다.
6. 위 과정을 반복하되, left <= right일 때만 반복하자 , 만약 left > right가 되는 엇갈림 현상이 발생한다면 이는 더 이상 left, right의 정의에 어긋나므로 탐색을 종료하고, right와 pviot의 값을 교환한다.
7. pivot은 정렬되었으므로 pviot의 왼쪽과 오른쪽 파티션(분할)을 나누어서 각 파티션마다 쿽정렬(정복)을 반복하도록 한다.
4.시간 복잡도
시간복잡도는 간단하다. 각 파티션마다 쿽정렬(정복)을 반복한다 했는데, 파티션은 몇 개가 나오는가? 맨 처음에는 파티션이 1개이다. pivot의 자리를 찾아주고 나누면 파티션은 두 개가 된다. 파티션 두 개에서 각각 pivot의 자리를 찾아주면 2+2 총 4개의 파티션이 생성된다. 따라서 2^k개 만큼 파티션이 증식되는 것을 알 수 있다. 그러나 파티션의 총 개수는 n개를 넘을 수가 없다. 즉, 총 배열의 크기 n 을 넘는 파티션은 만들어질 수 없다.
왜냐하면 원소가 1이면 더 이상 파티션이 나누어질 수 없기 때문이다. n = 2^k 가 되고, k=logn 이 된다.
각 파티션마다 '정복'을 해주어야하는데, 이는 left와 right가 탐색하는 횟수이다. 총 배열 사이즈가 n이라면 대충 최대로 n/2번하는데, n으로 퉁치도록 하자
따라서 총 파티션의 개수(분할) = logn
left,right의 순회 수(정복) = n 이므로
분할 * 정복 = nlogn 이 되어 O(nlogn)이 된다.
5. 코드
#include <iostream>
using namespace std;
int n = 10;
int data[] = {9,23,0,-12,32,5,1,23,123,-3};
void swap(int a, int b){
int temp = data[a];
data[a] = data[b];
data[b] = temp;
}
int partition(int left, int right){
int pivot = left;
int low = left+1;
int high = right;
while(low <= high){
while(low <= high && data[low] <= data[pivot]) low++;
while(low <= high && data[high] >= data[pivot]) high--;
if( low <= high) swap(low, high);
}
swap(pivot, high);
return high;
}
void quickSort(int left, int right){
if(left < right){
//pivot은 인덱스이다.
int pivot = partition(left, right);
quickSort(left, pivot-1);
quickSort(pivot+1, right);
}
}
int main(){
quickSort(0, n-1);
for(int i = 0; i < n; i++){
cout << data[i] << ' ';
}
}위의 원리를 그대로 구현한 코드이다.
함수 이름들이 조금 헷갈릴 지도 모르는 데, 위에서 설명할 때 '분할'을 partition이라고 했고, '정복'을 쿽정렬이라고 했다. 여기서는 반대로 '분할'에 quickSort 이름을, '정복'에 partition 함수 이름을 두었으므로, 헷갈리면 반대로 변경하면 된다.
간단하게 설명을 하자면
void quickSort(int left, int right){
if(left < right){
//pivot은 인덱스이다.
int pivot = partition(left, right);
quickSort(left, pivot-1);
quickSort(pivot+1, right);
}
}이 부분에서 pivot을 고르도록 한다. 'partition' 함수를 두었는데, 여기서 left, right 의 교환이 이루어지고 반복된다. 최종적으로 pivot의 정렬된 자리를 반환해준다.
이 반환 값을 이용해
quickSort(left, pivot-1);
quickSort(pivot+1, right);을 반복하여 partition을 나누는 것이다.
다음은 정복 함수이다.
int partition(int left, int right){
int pivot = left;
int low = left+1;
int high = right;
while(low <= high){
while(low <= high && data[low] <= data[pivot]) low++;
while(low <= high && data[high] >= data[pivot]) high--;
if( low <= high) swap(low, high);
}
swap(pivot, high);
return high;
}pivot과 low, high를 결정한다.
원리 부분의 설명에서 left가 여기서는 low이고, right가 high이다.
이들이 탐색을 시작하는 데 low > high가 되면 더 이상 탐색을 진행하는 의미가 없으므로 종료하도록 하였고, pivot보다 큰 값을 만나면 low는 멈추게 하였고, pivot보다 작은 값을 만나면 high가 멈추도록 하고 swap시키도록 하였다.
반환값으로는 high(원리 설명 부분에서는 right)를 넘겨주어 다음 partition을 사용할 수 있도록 하였다.
6. 장단점
쿽정렬의 장점은 뭐니뭐니해도 O(nlogn) 시간복잡도를 가졌는데, 병합 정렬처럼 새로운 메모리를 추가적으로 필요로 하지않는다는 장점이다.
그러나 단점으로는 최악의 경우에는 O(n^2) 시간이 걸린다는 단점이 있다. 어떻게 O(n^2)이 걸리는가?? 쿽정렬은 병합 정렬과 마찬가지로 분할-정복 알고리즘이지만, 분할이 반으로 딱 쪼개지지 않는 알고리즘이다.
다음을 보자

다음과 같이 이미 정렬된 배열이 있다고 하자, 여기서 퀵정렬을 이용하면

다음 처럼 pivot을 1로 잡고 left와 right를 잡을 것이다.
left는 영영 탐색을 못한다. 이는 2가 1보다 크기 때문에 멈추게 된다.
반면 right는 멈추지 못하고 left를 넘게된다. 이유는 모든 수가 pivot보다 크기 때문이다.

이렇게 될 것이고, 결국 pviot과 right를 바꾸어봤자 제자리 걸음이다.
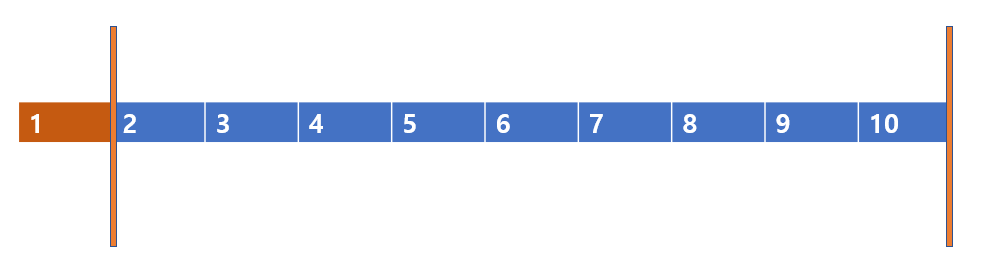
문제는 바로 이것인데, pivot이 자신이 정렬되었을 때의 자리를 기준으로 좌우 자리를 나눈다고 하였다. 그런데 문제는 분할이다.
분할이 반으로 쪼개지는 것이 아닌, 하나의 파티션만 생성하게 된다.
이 부분이 가장 큰 문제인 것이다.
결국은 각 파티션에 대한 정복과정은 하나의 원소에 대한 정렬과 마찬가지로 된다.
이는 N개의 원소에 대한 N번의 정렬과도 같다.
즉, 파티션이 N개가 나오므로 N번 정렬하면 O(n^2)이 된다는 것이다.
이것이 쿽정렬이 가지는 문제점이다.
따라서 이러한 문제점을 해결하기위해서 일부러 가운데 값을 pivot으로 잡는 방법도 존재한다.
하지만 필자는 귀찮기 때문에 이 방법은 pass하겠다~!
그냥 위의 코드에서 pivot잡는 값만 살짝 쿵 바꾸어주면 그렇게 어렵지 않게 구현이 가능하다.
+(2024/06/20)
python code도 추가하였고, 일부 부분도 수정하였다.
n = 5
data = [5,3,4,2,6]
def swap(i, j):
global data
temp = data[i]
data[i] = data[j]
data[j] = temp
def partition(left, right):
global data
p = (left + right) // 2 # shuffle 효과를 통한 최악의 경우 n^2를 벗어난다.
swap(left, p)
p = left
low = left + 1
high = right
while low <= high:
while low <= high and data[low] <= data[p]:
low += 1
while low <= high and data[high] >= data[p]:
high -= 1
if low <= high:
swap(low, high)
low += 1
high -= 1
swap(p, high)
return high
def quick_sort(left, right):
if left < right:
p = partition(left, right)
quick_sort(left, p-1)
quick_sort(p+1, right)
quick_sort(0, n-1)
print(data)