

📄 배경
요즘 진행하는 새로운 프로젝트팀 기획자님께서 책의 출판사 서평을 가져올 수 있는지를 물어보셨다. 책 관련 open api 대부분은 출판사 서평까지는 제공하지는 않았다. yes24에 출판사 서평이 기재되어있는데, 간단한 웹 스크래핑으로 가져오면 되지 않을까 해서 찍먹해보기로 결정
다른 프로젝트 데모를 만들다가 만 상태의 vite 기반의 react 프로젝트 내용을 싹 비우고,
바로 구현!
🔍 발견
대부분 웹 크롤링/스크래핑 하면 파이썬으로 많이 진행하는데, 너무 거창해지는가 싶어 js로도 진행 후 바로 활용할 수 없는지 알아보았고 그러다 발견한 것이 다음의 두가지 도구였다.
cheeriopuppeteer
cheerio는 정적인 사이트 내에 정보들을 html 형태로 긁어와 원하는 정보만을 파싱할 수 있고, puppeteer는 테스트할 때에도 쓰이는 툴로, 우리가 원하는 결과에 도달하기 전까지 웹 사이트와 상호작용을 할 수 있도록 도와주는 도구이다.
(puppeteer는 playwright와 유사한 듯)
시도 1) puppeteer 활용 ❌ - 실패
내가 지금 하고자 하는 시나리오는 다음과 같았다.
- yes24 공식 페이지에 접속
- 검색창에 알고자하는 책의 제목을 입력후
- 검색 버튼 클릭
- 나온 리스트의 결과 중 첫번째 게시글 클릭
- 출판사 서평 부분을 스크랩
이 시나리오 대로 puppeteer를 활용하여 진행하다가 4번까지는 어찌저찌 해냈지만, 5번에서 어째선지 출판사의 서평부분의 selector를 제대로 가져오지 못하는 문제가 있었다. 분명히 inspector를 통해 몇번이고 확인도 해보고 각 액션간의 delay도 사이사이에 잘 넣어줬다고 생각했지만 제대로 가져올 수 없었고, 다른 방법을 찾아보기로 했다.
시도 2) cheerio 활용 ⭕️ - 성공
- 게시글 목록 -> 게시글 상세 페이지 (i want this✨)
- 게시글 상세 페이지는
게시글 id를 필요로 한다. (어디에서 얻을 수 있나? 게시글 목록에서!)- then,
1)cheerio활용 ➡️ 게시글 목록 접근하기 +게시글 id가져오기
2)cheerio활용 ➡️게시글 id를 토대로 상세 페이지 재접근 +출판사 서평가져오기
최종 목표는 내가 검색한 책의 게시글 상세 페이지(출판사 서평이 있는)에 접근하는 것이다.
yes24에서 검색어 입력시 나오는 리스트에서 각 상품 item들은 id를 가지고 있어,
클릭하게 되면 path variable로 id를 함께 넘기며 상세 페이지의 내용을 렌더링한다.
따라서 상세 페이지의 url을 확인해보면 상품의 id를 확인할 수 있다.
e.g.
https://m.yes24.com/Goods/Detail/2943352
// 뒤의 2943352가 '소원을 들어주는 카드'라는 책의id
따라서 검색목록으로 부터 이 아이디를 얻어와야한다.
cheerio는 앞서 언급했듯이 url로 접근한 정적 페이지의 html을 끌어오는 것으로, 책제목을 타이핑하는 상호작용을 할 수 없어 바로 검색결과 url을 가져와야한다.
검색의 경우 queryString으로 넘겨주는 모습이다.
e.g.
https://www.yes24.com/Product/Search?domain=ALL&query=%EC%86%8C%EC%9B%90%EC%9D%84%20%EB%93%A4%EC%96%B4%EC%A3%BC%EB%8A%94%20%EC%B9%B4%EB%93%9C
// 위의 query= 이후의 값은 책의 제목의 URL 인코딩 값
yes24의 경우 정확도보다 인기순으로 책을 추천하여 내가 입력한 책과 다른 책이 상위에 뜨기도 한다. 도서로 카테고리를 한정하고 정확도를 높이기 위해 도서명과 정확도순 필터링의 값도 함께 넘겨주기로 했다!
e.g.
https://www.yes24.com/Product/Search?domain=ALL&query=%EC%86%8C%EC%9B%90%EC%9D%84%20%EB%93%A4%EC%96%B4%EC%A3%BC%EB%8A%94%20%EC%B9%B4%EB%93%9C&page=1&order=RELATION&_searchTarget=TITLE
// &로 연결된 키(order,_searchTarget)들은 필터링 키
🎯 구현
내가 작성할 데모 프로젝트의 디렉토리 구조는 다음과 같다.
빠르게 제작하기 위해src 에 모든 파일 작성했다
📦 scraping-demo ├─ src │ ├─ App.css │ ├─ App.tsx │ ├─ SearchForm.tsx // 추가 │ ├─ api.ts // 추가 │ ├─ index.css │ ├─ main.tsx │ └─ vite-env.d.ts ├─ tsconfig.json ├─ tsconfig.node.json └─ vite.config.ts // 변경
1) SearchForm.tsx제작
SearchForm 컴포넌트는 간단하게 출판사 서평을 얻어올 책의 제목을 입력 받는다.
제목 입력 후 enter를 치거나 Search 버튼을 클릭하면, 부모로부터 받은 getData 함수를 실행한다.
// SearchForm.tsx
import { useState, KeyboardEvent, ChangeEvent } from "react";
// 키워드를 입력받는 컴포넌트
const SearchForm = (props: { getData: any }) => {
const { getData } = props;
const [keyword, setKeyword] = useState("");
return (
<div className="form">
<input
type="text"
className="form-text"
onChange={(e: ChangeEvent<HTMLInputElement>) => {
setKeyword(e.target.value);
}}
onKeyDown={(e: KeyboardEvent<HTMLInputElement>) => {
if (e.key === "Enter") {
if (keyword) {
getData(keyword);
}
}
}}
/>
<button
type="button"
className="form-btn"
onClick={() => {
if (keyword) {
getData(keyword);
}
}}
>
search
</button>
</div>
);
};
export default SearchForm;

2) App.tsx 작성
App 컴포넌트에는 책의 정보가 담긴 페이지에 접근하여 화면에 렌더링하는 역할을 부여했다.
axios의 get 요청은 응답으로 data 속성에는 해당 페이지(.html)이 문자열의 형태로 전달된다.
GET response type
{
config: ...,
data: "\r\n\r\n\r\n\r\n\r\n\t<!DOCTYPE html >\r\n\t\<html lang=\"ko\">\r\n\r\n<head>\r\n\t<meta http-eq.../></html>",
...
}`
cheerio에서 제공하는 load 함수를 활용해 이 문자열을 html 구조에 맞게 파싱을 하여 원하는 정보만을 추출할 수 있다
selector로 가져온 html 요소에서 값 추출
.text(): 해당 요소에 담긴 텍스트 추출
.attr([속성명:string]): 해당 요소의 속성의 값 추출
// App.tsx
import { useState } from "react";
import { request } from "./api"; // yes24로 get 요청 함수
import { load } from "cheerio";
import SearchForm from "./SearchForm";
import "./App.css";
const App = () => {
const [book, setBook] = useState({
title: "",
author: "",
publisher: "",
content: "",
});
// 책의 정보가 담긴 페이지 api 요청 및 저장 로직
const getData = async (keyword: string) => {
// 1) 책 이름 검색 결과 페이지 요청
request(
`Product/Search?domain=ALL&query=${encodeURI(
keyword
)}&order=RELATION&_searchTarget=TITLE`
)
// 2) 원하는 책의 상세 페이지로 이동하기 위한 링크 획득
.then((html: any) => {
const $ = load(html.data);
const bookSelector = $("ul#yesSchList > li:first a.gd_name");
const data = {
bookTitle: bookSelector.text(),
bookUrl: bookSelector.attr("href"),
};
setBook((prev: any) => ({ ...prev, title: data.bookTitle }));
return data;
})
// 3) 위에서 얻은 상세 페이지 url로 재요청 후 상세 정보 획득
.then((data: any) => {
request(data.bookUrl).then((html: any) => {
const $ = load(html.data);
const data = {
author: $("span.gd_auth").text(),
publisher: $("span.gd_pub").text(),
content: $(
"div#infoset_pubReivew > div.infoSetCont_wrap > div.infoWrap_txt"
).text(),
};
setBook((prev: any) => ({
...prev,
author: data.author,
publisher: data.publisher,
content: data.content ? data.content : "출판사 서평이 없습니다",
}));
});
});
};
return (
<div className="app">
<SearchForm getData={getData} />
<div className="alert-txt">
제목을 잘못 입력했을 경우
<br /> 가장 상단에 노출되는 책의 제목과 서평을 보여줍니다.
</div>
<h2 className="book-title">{book.title}</h2>
<span>{book.author}</span>
<span>{book.publisher}</span>
<p className="book-review">{book.content}</p>
</div>
);
};
export default App;
3) api.tsx 작성 및 CORS 에러 방지
app에서 사용한 yes24로 요청하기 위한 GET 요청 api가 담긴 api.tsx를 작성한다.
// api.tsx
import axios from "axios";
const request = async (path: string) => {
try {
return await axios.get(`https://www.yes24.com/${path}`);
} catch (error) {
console.error(error);
}
};
export { request };하지만 단순히 위와 같이 작성했다가 CORS 에러를 만났다ㅠ
이를 해결하기 위해 프록시 설정을 해주기로 했다
// vite.config.ts
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
export default defineConfig({
plugins: [react()],
server: {
proxy: {
// 브라우저에서 /api로 요청이 들어오면,
"/api": {
target: "https://www.yes24.com/", // target url을 yes24로 변경하고,
changeOrigin: true, // target과 같은 도메인의 요청인 것처럼
rewrite: (path) => path.replace(/^\/api/, ""), // target url로 요청시 /api 문자열은 제거
},
},
},
});
이후 다시 api.tsx의 request 함수의 요청 url을 수정해주면 진짜 끝!
...
const request = async (path: string) => {
try {
return await axios.get(`/api/${path}`);
} catch (error) {
console.error(error);
}
};
...👀 결과
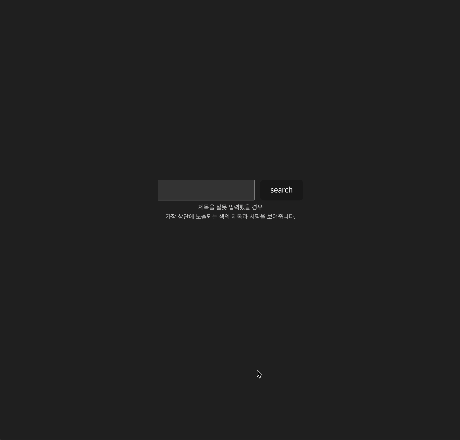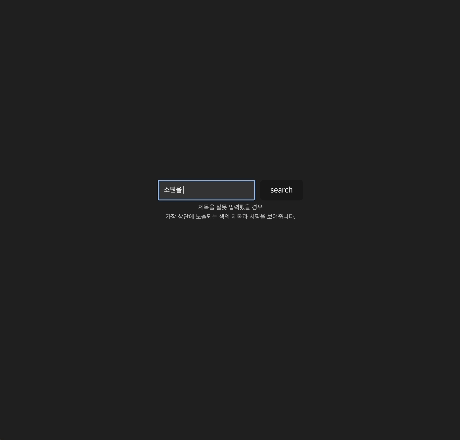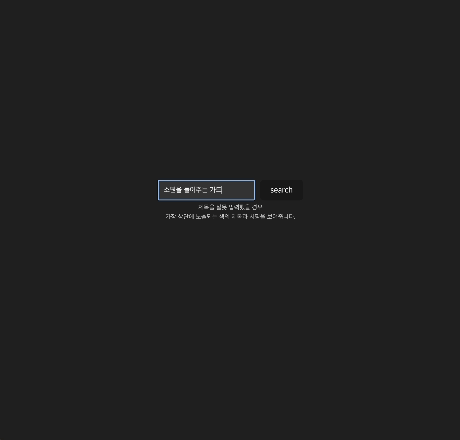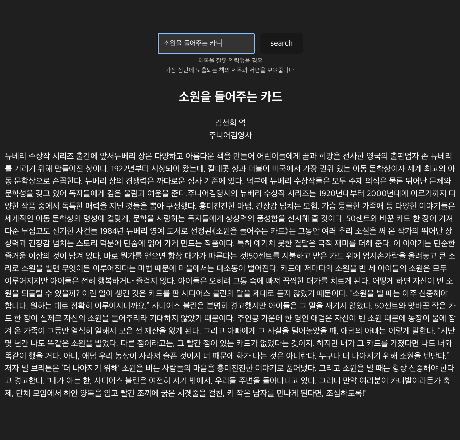
책의 제목을 작성하면 하단에 책의 저자와 출판사, yes24에 기재된 서평까지 긁어올 수 있다!
🗣️ 궁시렁
📕 참고
