
사진: Unsplash의Phyllis Kosminsky
데이터 출처
Kaggle에서 제공하는 논문 토픽 분류 데이터셋이다. Computer인지 Statistics인지 Mathmatics인지 등등을 맞추는 문제이다. 하지만 우리에게 필요한 데이터는 논문 title과 abstract 뿐이다. 하지만 논문 토픽을 어떻게 잘 활용해 볼 수도 있을 것 같아 최대한 가져가기로 했다.
1. 캐글1
2. 캐글2
3. 캐글3
4. 캐글4
1,2,4번째 데이터셋은 깔끔했는데, 3은 세부 분류가 너무 많고, title필드(열)가 없어서 그냥 제외했다. 3번을 제외하고도 62919개나 된다. 포함하면 8만개 이상이되니 나중에 데이터가 부족하면 추가로 활용할 수 있도록 남겨뒀다.
본격적으로 데이터 수집
너무 쉽다. 다운로드만 받으면 끝이다. 하지만 title, abstract만 있는 데이터는 활용도가 낮다. 우리가 만들고자 하는 서비스에 링크가 제공되기 때문에 논문 링크를 가져다가 붙여야한다. 하지만 구글 검색 외에는 뾰족한 수가 생각이 나지 않았다. ChatGPT4 turbo가 출시된 기념으로 질문을 해봤다. coding assistant능력은 정말 기대 이상이었다. 5초만에 구글 검색 결과 최상단에 있는 링크를 크롤링하는 코드를 제공해줬다. chatgpt3에서는 만족스러운 답을 얻지 못했었는데, 정말 1차원적인 답변만 나열할 뿐이었다. 1. HTML 파싱, 2. API이용.. 이러면서 잘못 크롤링하면 저작권을 위반할 수 있다는 식으로 답답하게 나왔었다. ChatGPT4 turbo는 코드를 제공해주면서 구글 API가 제공되는데, 직접 파싱을 통해 크롤링을 하게되면 차단당할것이라고 답했다. 같은 결론이지만 훨씬 와닿게 설명해줘서 Assistant의 유용성을 체감할 수 있었다. 구글 API를 찾아보다가 다양한 크롤링 대행 웹사이트를 찾았는데 비용이 어마무시했다.
50만원이 넘는다. 이 비용을 청구할 수 있을까 잠깐 고민해봤는데 '이럴거면 ChatGPT4한테 코드 짜달라해서 내가 하면 아낄 수 있는 비용이잖아' 싶어 다시 나의 Assistant에게 질문을 했다. 두 번째 질문은 구글 API를 이용해서 크롤링하는 코드 요구였다. 역시나 5초만에 유용한 코드와 함께 API는 쿼리 제한이 있어 여러 검색 결과를 얻기 위해서는 꼭 제한 횟수를 찾아봐야 한다는 조언이 돌아왔다. 찾아보니깐 구글 API는 1000번의 검색에 $5를 청구하고 있었다. 계산해보니깐 7만건을 하려면 50만원 정도가 필요했다.... 방법을 궁리하다가 구글 말고 다른 검색 엔진은 어떨지 싶어서 네이버 API를 찾아봤다. 우리의 NAVER는 무려 25000회의 검색을 매일 무료로 제공하고 있었다. WOW
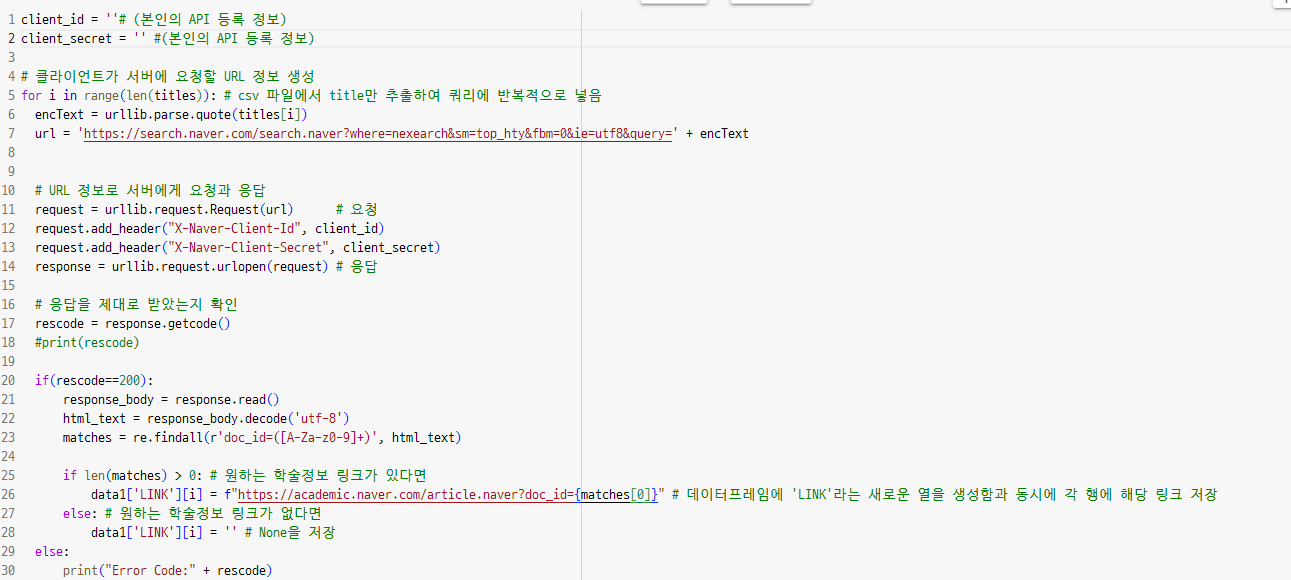
네이버 API쓰는 방법은 chatgpt4 turbo가 모를 것같아서(네이버 사랑합니다..♥) 네이버에 검색해서 나온 velog에서 가져왔다. 감사합니다. 잘 썼습니다!!
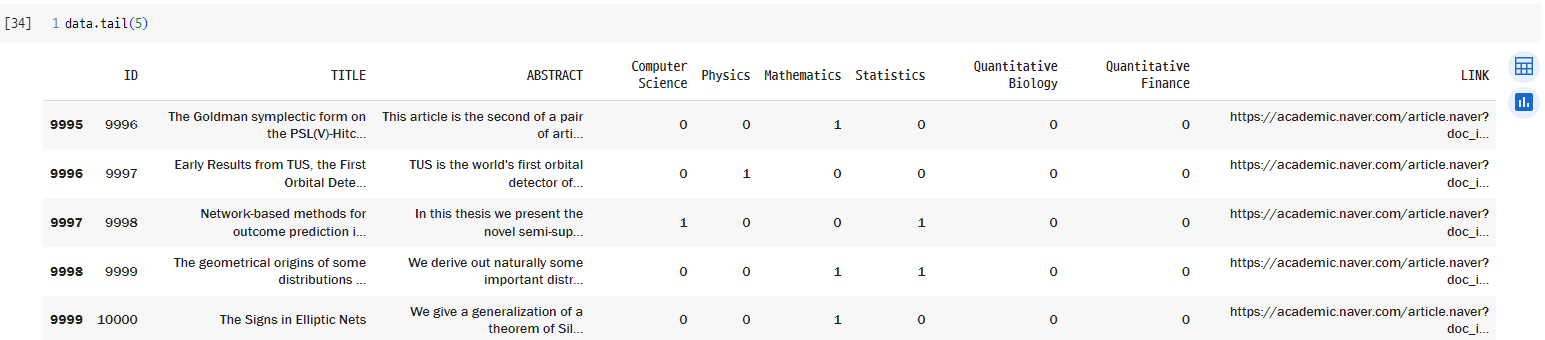
비록 구글에 비해 검색되지 않는 논문도 꽤 있었지만, 나중에 데이터가 부족하면 검색이 안된 논문만 구글에서 돈주고 검색하면 될 것 같다. 아니면 귀찮지만 arxive 등 논문 DB사이트 여러군데에서 크롤링을 하는 것도 방법이 되겠다. 하지만 굳이 그렇게까지 할 필요가 있을 지는 다른 팀원과 더 논의해봐야할 것 같다.
여기서 잠깐 문제가 발견되어서 처음으로 돌아가 몇가지 처리를 해주었다.
1. 논리 오류로 마지막 링크가 모든 행에 중복돼서 저장되었다. ㅎ..내 40분.. 교훈은 적은 숫자로 계속 돌려볼 것.. 하지만 완벽한 코드인 줄 알았으니.. 6시간이 아닌 40분임에 다행으로 여기자
2. 다시 돌리니깐 접근 거부당했다. 아마도 같은 쿼리를 매크로로 여러번(아마 5~6번째였던 것 같다)돌리니깐 비정상적인 움직임으로 감지된 것 같다. data의 앞 10000개 행을 검색에 활용했으니 뒷 10개 행 정도만 다시 검색 시도해봤다. 결과는 잘 돌아간다!! 이 맛에 코딩하지 bb
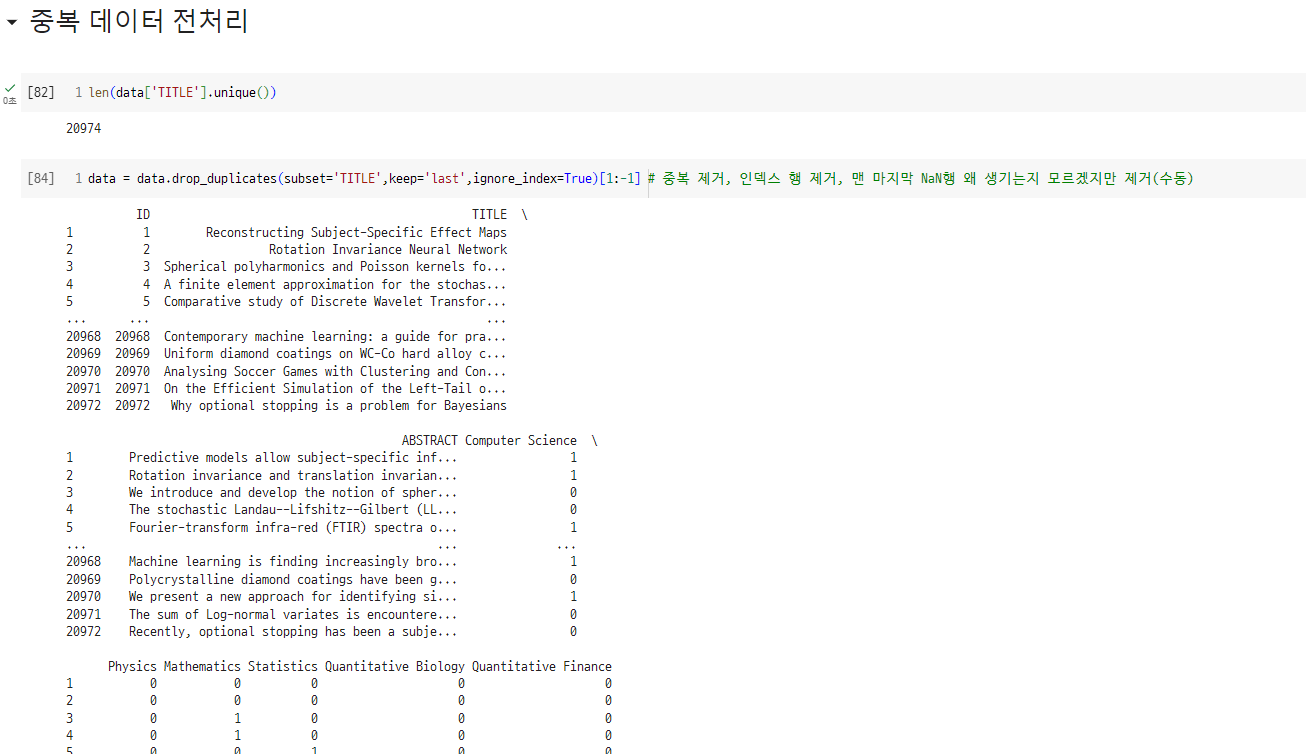
- 그러고보니.. kaggle에서 데이터 돌려막기를 할 가능성이 매우 높다는 생각이 문득 들었다. 역시나... TITLE이 중복된 행을 제거해보니 2만개만 남았따...ㅎㅎ 이거 모르고 3일동안 데이터 수집했으면 화날뻔..ㅎㅎㅎㅎ 시행착오의 연속이지만 뭔가 이렇게 하나씩 가설이 맞아떨어지는 쾌감이 크다bb
현재까지 진행상황 정리 끝! 앞으로 남은 할 일을 리스트업해봤다.
TO-DO
추가 전처리(각 링크에 들어가서 크롤링 진행 후 가능)
- 토픽과 링크가 일치하지 않는 경우 LINK 공백
- 저자, 발행정보, 피인용횟수, 자료제공처, DOI, 원본 링크, 키워드 크롤링
논문 원본 데이터 수집
- 본문 내용
- 참고 문헌
논의할 내용
- 어느 정보까지 수집할 것인지
- 필요 데이터 얼마나 될 지(추가 전처리 필요한 데이터들 어디까지 쓸 지)
- 활용 어려운 순: 캐글3(토픽이 없음, abstract로 검색해야 함) > 부정확한 링크 > 링크 공란
