KOALA 프로젝트
1.[Koala] 논문 데이터 수집기

사진: Unsplash의Phyllis Kosminsky 데이터 출처 Kaggle에서 제공하는 논문 토픽 분류 데이터셋이다. Computer인지 Statistics인지 Mathmatics인지 등등을 맞추는 문제이다. 하지만 우리에
2.[koala] 데이터 수집 디버깅 로그

큰일났다 네이버 링크 수집이 막혔다.. 뒤늦게 robots.txt를 확인해보니깐 arcademic 사이트에서 doc_id가 포함된 URL 크롤링을 막고 있었다. 각 웹사이트별 정책이 천차만별이라 일일이 찾아봤어야 했는데 경험이 없다보니 이렇게 실수하면서 하나 배운다.
3.Koala 프로젝트 중간 점검

주제: 논문 레퍼런스 검색을 위한 미니 검색 엔진배경: 논문 작성 시 레퍼런스 검색이 가장 귀찮고 시간이 많이 드는 일임. DB의 모든 논문의 자료를 검색하여 찾고자 하는 정보와 가장 가까운 문장을 찾아주면 좋겠다는 취지에서 개발하게 됨.참고: chatgpt4 scho
4.[Koala] 프로젝트 진행 상황 및 앞으로 할 일들

https://chat.openai.com/share/88ade769-05af-484b-af1f-f2b5334119fe 갓 GPT가 프로젝트 완수율을 30분 만에 50%p정도 높여주었다. 문득 생각난 아이디어를 구현해달라고 하니 정말 놀라운 속도로 만들어주었다. 개
5.[Koala] DB 행 데이터 분리하기

프로젝트 진행도 ■■■■■■■□□□ 70%
6.[Koala] 성능 평가용 데이터셋 크롤링

목차 시나리오 구현 시나리오 수집 방법 DB에 있는 논문(이하 우리 논문)이 인용된 논문을 찾는다. 우리 논문을 인용한 부분이 어딘지 찾는다. 그 부분을 가져온다. 사용 방법 구현
7.[Koala] Streamlit으로 UI 구현하기
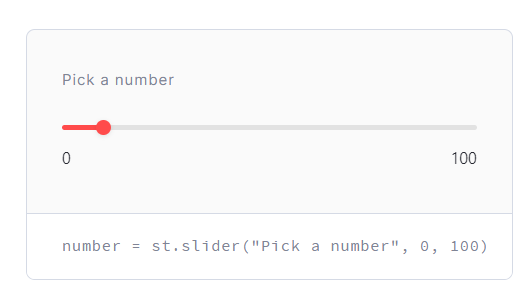
목차 환경 설정 및 기본 문법 streamlit SQL과 연동 https://hello-bryan.tistory.com/387 검색창 진행바 실제로 만들어보자!
8.[Koala]검색 알고리즘 성능 평가
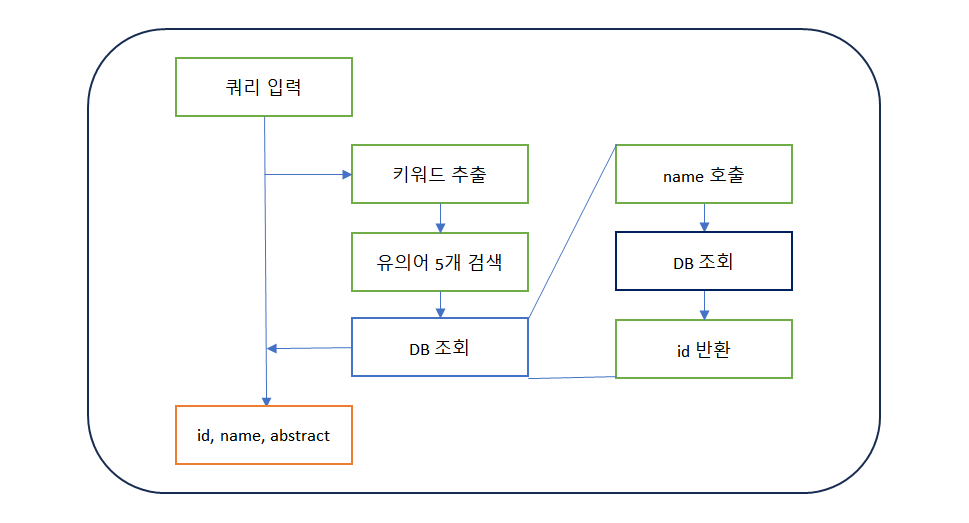
성능 평가 방법 1. Top N 출처: COVID-19 information retrieval... 2. Bpref 출처: COVID-19 information retrieval... >키워드&문장 / 절대평가 조합이 가장 검색도 빠르고 검색도 잘 될 것이다!
9.[koala] 드디어 DB 구축 완료👊
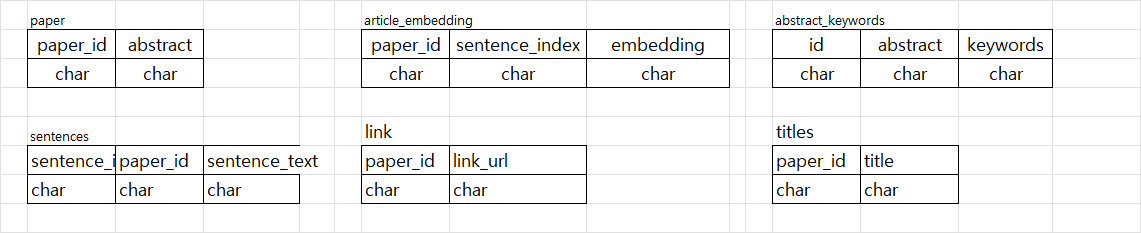
드디어 길고 길었던 embedding 및 DB 구축이 1차 완료가 되었다.너ㅓㅓㅓㅓ무 힘들었다.먼저 DB 스키마 설계는 엑셀로 테이블 구성과 Primary키 통일 등을 해주었다.행 수가 10만 개 이상이 되니까 검색 속도가 많이 느려진다. 하지만 SQL의 장점은 여전히