
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
SBERT란?
- SBERT는 의미론적으로 의미 있는 문장 임베딩을 도출하기 위해 Siamese 및 triplet 네트워크 구조를 사용한다.
- 의미론적 유사성 검색 및 클러스터링과 같은 비지도 작업에 적합하다.
- 다양한 작업에서 다른 SOTA 상위권 문장 임베딩 방법보다 성능이 뛰어나다.
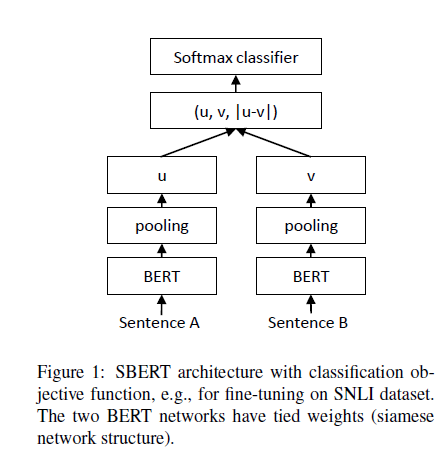
위 그림은 NLI 처리 과정이다. Sentece A, B를 구조가 유사한 두 신경망을 통해 임베딩 결과 , 를 구한 뒤
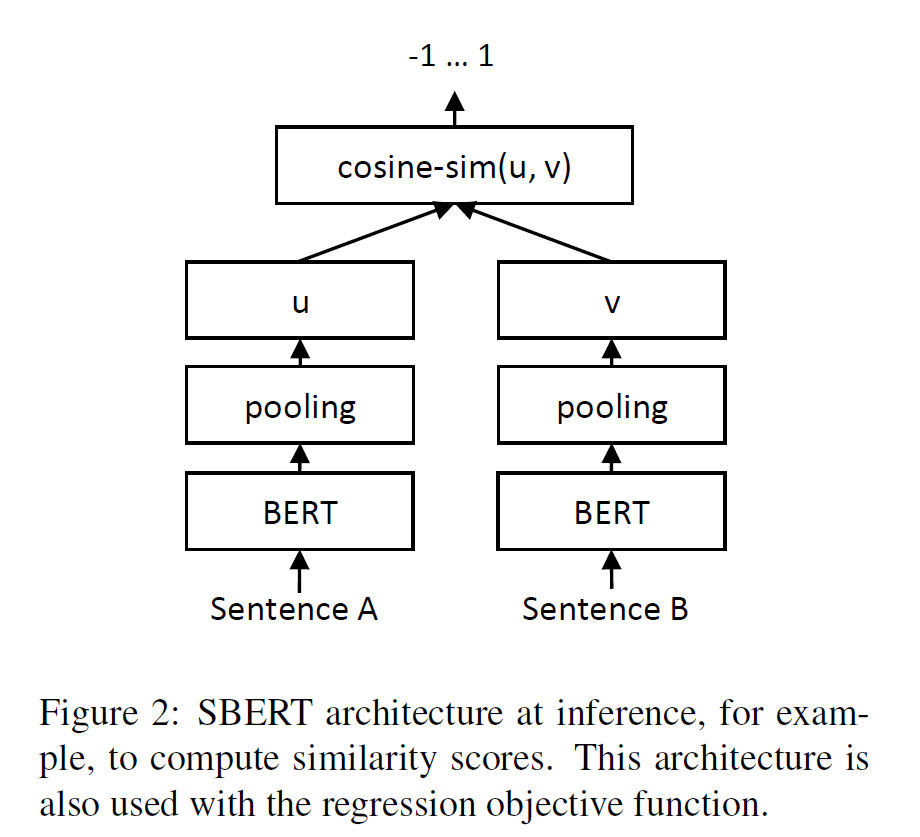
BERT v.s. SBERT
BERT는 transformer base 모델이고, SBERT는 fine-tuning된 BERT 모델을 사용하여 문장 임베딩을 생성하고, 이를 활용하여 문장 간 유사도를 측정하는 모델이다. SBERT는 문장 수준의 작업에 최적화되어 있으므로 BERT보다 특정 작업에 더 효율적이다.
BERT는
- Bidirectional Encoder Representations from Transformers의 약어로, 양방향 Transformer 인코더를 사용하여 사전 학습된 언어 모델을 만드는 데 사용된다.
- 이 모델은 양방향으로 입력 시퀀스를 처리하며, 입력 시퀀스의 모든 위치에서 문맥 정보를 고려한다.
- 이를 통해 BERT는 다양한 자연어 처리 테스크에서 우수한 성적을 보인다.
BERT의 한계
- 다양한 쌍의 문장을 처리하는 데 속도가 오래 걸린다.
- 타 SOTA 임베딩 모델보다 성능이 떨어진다.
- Cosine Similarity를 적용할 수 없다.
SBERT는
- BERT 모델을 fine-tuning하여 문장 임베딩을 생성한다.
- SBERT는 문장 임베딩을 생성하기 위해 siamese(샴, 두 개의 닮은) 또는 triplet(세 개의 닮은) network 아키텍처를 사용한다.
- 이 아키텍처를 통해 SBERT는 코사인 유사성을 사용하여 비교할 수 있는 문장 임베딩을 생성할 수 있으므로 가장 유사한 문장 쌍을 찾는 데 필요한 계산 비용이 줄어든다. (문장 검색 시간: 65시간 -> 5초)
- SBERT는 문장 수준에서의 의미를 파악하도록 설계되어 있으며, 문장 임베딩 간의 코사인 유사도를 사용하여 문장 간 유사도를 측정한다.
SBERT 파인 튜닝에 사용된 학습 데이터
- SNLI(Bowman et al., 2015)
- 모순, 일치, 중립으로 라벨링된 570,000의 문장 쌍
- 문장 간의 주제적 유사성 메트릭을 학습하기 위해 기사를 섹션으로 분할하고 피벗 문장, 동일한 섹션의 문장, 다른 섹션의 문장으로 구성된 약하게 레이블이 지정된 문장 총 삼중항으로 구성된 대규모 데이터셋(Dor et al., 2018)
- Multi-Genre NLI
- 다양한 장르의 430,000 문장 쌍
- 위키피디아 기사의 다양한 섹션의 문장을 구별하기 위해 까다로운 논쟁의 주장 유사성 데이터셋(Misra et al., 2016)
하이퍼파라미터 튜닝
loss function: 3-way softmaxclassifier for one epochbatch-size: 16optimizer: Adamlearning rate: 2e-5pooling: mean
Loss Function
- 분류
두 문장의 임베딩 벡터 와 의 원소들의 차이에 를 곱한 뒤 소프트맥스를 취함
는 학습 가능한 가중치 행렬로, shape은 ( x )이다.
은 문장의 임베딩 벡터의 차원
는 라벨 수
cross-entropy-loss를 사용
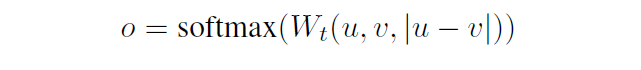
-
회귀
값의 결과가 숫자로 나오는 것을 회귀분석이라 함
유사도를 수치적으로 출력해주는 것을 의미
mean-squared-error 사용 -
삼중회귀
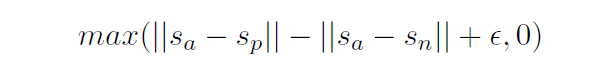
: 중심 문장
: 긍정 문장
: 부정 문장
~거리를 ~보다 가깝게 하는 것이 목표
: 는 , 과 최소 만큼 떨어져있음(기본값: = 1)
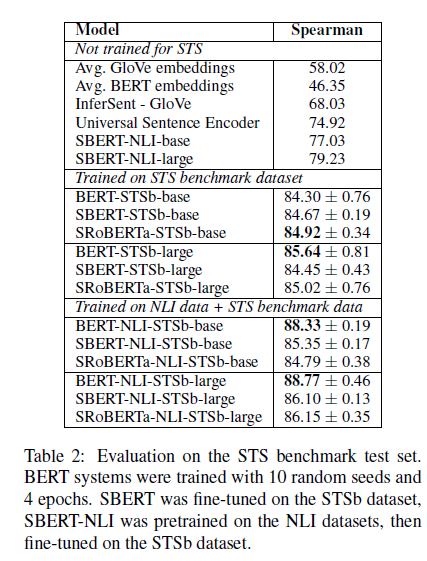
SBERT 평가에 사용된 데이터
- SICK-Relatedness dataset
- 유사도에 따라 0~5점을 부여
- STS benchmark (STSb)
- 세 가지 카테고리의 (캡션, 뉴스, 포럼) 8,628개의 문장
- 데이터셋 구성은 train(5,749), valid(1,500), test(1,379)
- 타 모델과 성능 비교
- Argument Facet Similarity(AFS)
- AFS 데이터셋에는 세 가지 논란이 되는 주제(총기 규제, 동성애 결혼, 사형) 주석이 달린 6,000개의 소셜 미디어 대화
- 0("다른 주제)에서 5("완전히 일치하는 주제")까지의 척도로 주석처리됨
- Wikipedia Sections Distinction
- 위키피디아를 사용하여 문장 임베딩 방법을 위한 주제별 세부 교육, 개발 및 테스트셋 제공
- 위키피디아 기사는 특정 측면에 초점을 맞춘 별개의 섹션으로 분리
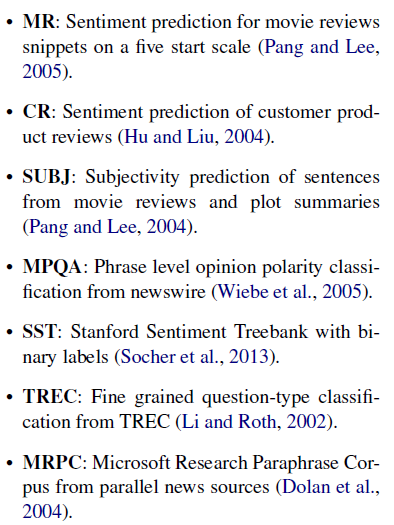
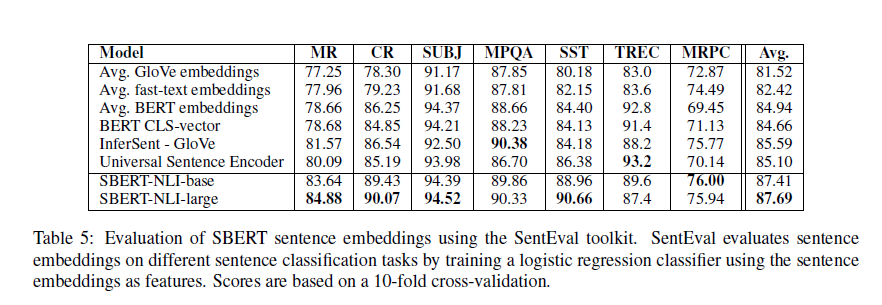
- SentEval
- 문장 임베딩을 평가하는 데이터셋 모음
- 구성 항목
- 각 항목에 대한 다른 임베딩 모델과 성능 비교

聞一知十