썸네일 출처 사진: Unsplash의Justin Kauffman
목차
- 동시발생행렬과 PPMI
- 차원 축소
- Support Vector Machine
- SVD로 단어 벡터 차원 축소
1. 동시발생행렬과 PPMI
이전 게시글에서 동시발생행렬을 보정한 PMI와 PPMI에 대한 설명이 있다. 간략하게 정리하면, PMI는 'a'나 'the'와 같이 어떤 말뭉치에서도 출현 빈도가 높은 단어들, 하지만 해당 말뭉치의 내용과는 별 상관이 없는 단어의 중요도가 과대평가되지 않도록 동시발생행렬을 보정하는 작업이다. 이 때 PMI는 log계산이 있는데 log의 지수 부분에 0이나 음수는 값이 무한대이거나 없기 때문에 양수로 보정해주는 것이 PPMI이다. 여기까지 단어의 의미를 반영한 분산 표현이 완성되었다. 하지만 여전히 행렬에 0이 많은 희소 표현이고, 메모리 낭비가 심하기 때문에 추가적인 처리가 필요하다. 이 때 등장한 아이디어가 차원 축소(dimensionality reduction)이다.
2. 차원 축소
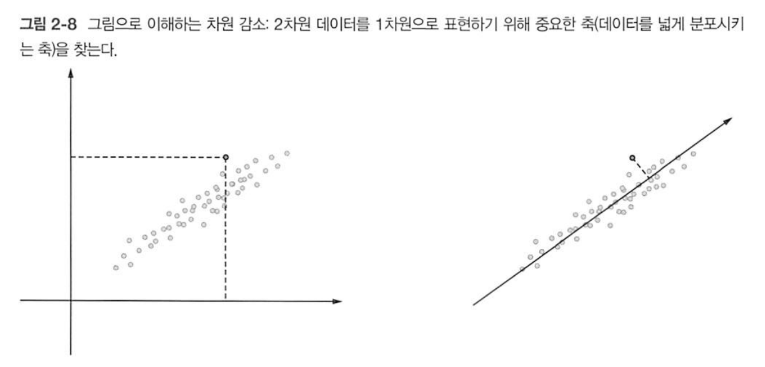
위 그림과 같이 2차원 상에 놓여있는 데이터를 1차원으로 표현하고 싶을 때, 1차원 축을 어떻게 놓아야 정보량을 최대한 보존할 수 있을까? 데이터의 분포를 최대한 넓게 퍼뜨려 놓아야 현재 데이터들의 상대적인 크기, 분산 등이 최소한으로 소실된 채 1차원으로 축소가 될 것이다.
3. Orthogonal Matrix
4. SVD
차원을 감소시키는 여러가지 방법 중 하나는 특잇값분해(Singular Value Decomposition)이다. SVD는 행렬을 세 행렬의 곱으로 분해하며 수식으로는 다음과 같다.
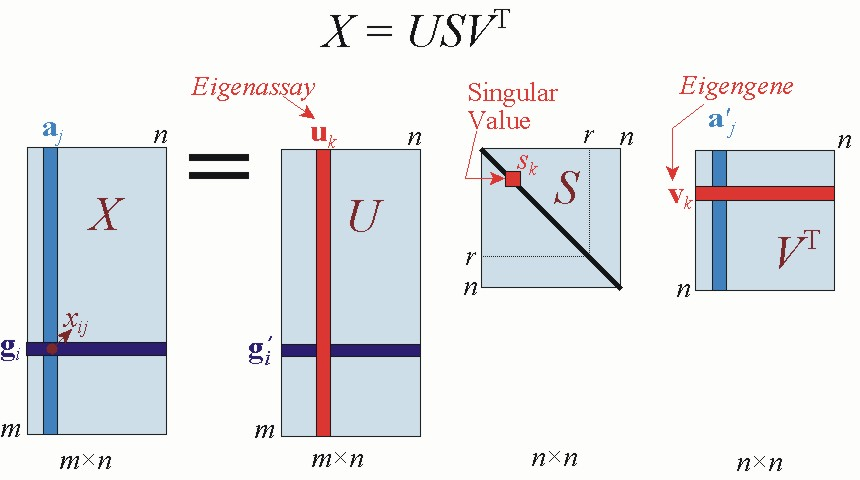
이미지 출처
는 직교행렬로, 여기서는 단어 공간의 축(기저)를 형성한다. 는 대각 행렬로 대각 성분에는 '특이값(singular value'이 큰 순서대로 나열되어 있다. 특잇값은 쉽게 말해 '해당 축'의 중요도라고 할 수 있다. 즉, 중요한 정보가 모두 앞 열에 몰려있으니 다음과 같이 잘라내도 의미가 거의 유지된 채 공간은 많이 적게 차지하게 된다.
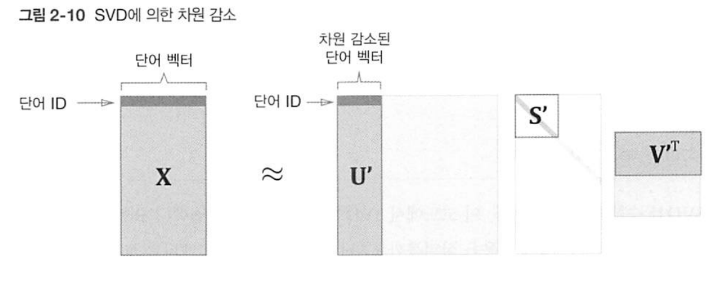
6. SVD로 단어 벡터 차원 축소
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from common.util import preprocess, create_co_matrix, ppmi
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(id_to_word)
C = create_co_matrix(corpus, vocab_size, window_size=1)
W = ppmi(C)
# SVD
U, S, V = np.linalg.svd(W)
np.set_printoptions(precision=3) # 유효 자릿수를 세 자리로 표시
print(C[0])
print(W[0])
print(U[0])
# 플롯
for word, word_id in word_to_id.items():
plt.annotate(word, (U[word_id, 0], U[word_id, 1]))
plt.scatter(U[:,0], U[:,1], alpha=0.5)
plt.show()text = 'You say goodbye and I say hello.' corpus, word_to_id, id_to_word = preprocess(text) vocab_size = len(id_to_word) C = create_co_matrix(corpus, vocab_size, window_size=1) W = ppmi(C): 짧은 문장으로 SVD의 성능을 테스트하는 코드이다.
preprocess메소드로 텍스트를corpus,word_to_id,id_to_word를 구해 각각 저장한다. 동시발생행렬을C에 저장하고 PPMI를 적용해W에 저장한다.# SVD U, S, V = np.linalg.svd(W): numpy의 선형대수 모듈에서 제공하는
svd()메소드를 활용한다. 각각U,V,D에 행렬이 저장된다.# 플롯 for word, word_id in word_to_id.items(): plt.annotate(word, (U[word_id, 0], U[word_id, 1])) plt.scatter(U[:,0], U[:,1], alpha=0.5) plt.show():
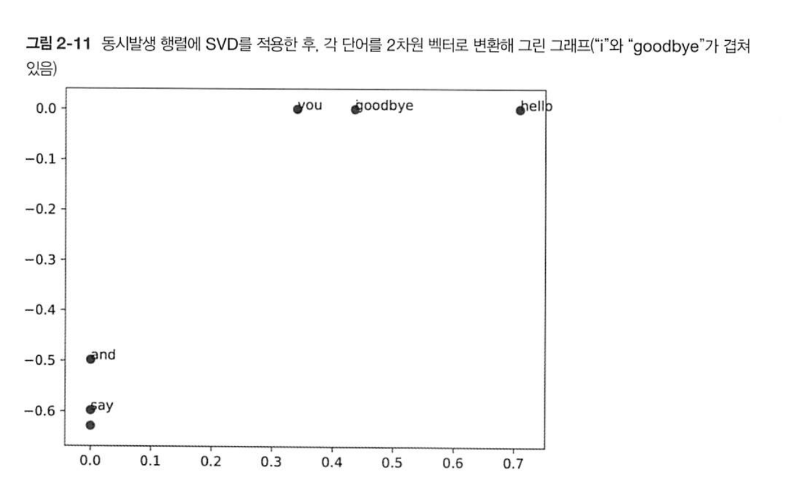
plt.annotate(word,x,y)메소드는 2차원 그래프상에서 좌표(x,y)지점에 word가 담긴 텍스트를 그린다. 이 코드를 실행하면 화면에 [그림 2-11]이 나타난다.
신기하게도 'goodbye'와 'hello', 'you'와 'i'가 제법 가까이 있음을 확인할 수 있는데, 우리의 직관에 부합한다.