
이 글은 한경훈 교수님의 수업 내용을 정리한 글입니다. 공부 목적으로 쓰는 글이며 velog에서 띄운 광고 수익은 저에게 일절 들어오지 않습니다.
목차
- CBOW를 변형한 언어 모델
- 언어 모델
- CBOW 모델을 변형한 언어 모델의 문제점
- Recurrent Nerual Network
- RNN의 활성화 함수
- 쌍곡함수
CBOW를 변형한 언어 모델
-
CBOW: 맥락으로부터 중심 단어 추측
You ? goodbye and I say hello.
You say ? and I say hello.
You say goodbye ? I say hello.
You say goodbye and ? say hello.
You say goodbye and I say ?. -
CBOW 변형 모델: 앞 맥락으로 다음 단어 추측
You say ? and I say hello.
You say goodbye ? I say hello.
You say goodbye and ? say hello.
You say goodbye and I say ?.
You say goodbye and I say hello?
언어 모델
- 단어 시퀀스에 조건부 확률을 할당하여 가장 확률이 높은 단어 시퀀스를 찾아낸다.
응용 분야
1. 기계 번역
- 기존: 규칙 기반 모델은
영어 단어와 한국어를 1:1 매칭하기 때문에
"I took a bus."를 "나는 버스를 탔다."와 "나는 버스를 태웠다." 중 어떤게 정답인지 모른다. - 보완: CBOW 변형 모델
CBOW 변형 모델은 말뭉치에서 어떤 해석이 더 자주 등장했는 지 확률을 계산해
더 높은 쪽인"나는 버스를 탔다"로 해석한다.
2. 오타 교정
- CBOW 변형 모델
"나는 부리나케 잘려갔다."로 입력하면
코퍼스에서 P(잘려갔다|부리나케)와 P(달려갔다|부리나케)를 비교해
확률이 더 높은 쪽인 "나는 부리나케 달려갔다."로 수정한다.

위 그림은... 잘못된 예시이다. beach 얘기를 하고 있는데 비속어로 인식을 했다. 발음 탓인가ㅠㅠ
3. 음성 인식
- CBOW 변형 모델
"나는 맛있는 메롱을 먹는다."라고 애매모호하게 발음되면
코퍼스에서 P(메롱|맛있는)과 P(메론|맛있는)을 비교해
확률이 더 높은 쪽인 "나는 맛있는 메론을 먹는다."로 인식한다.
4. 셰익스피어 문체
- CBOW 변형 모델
셰익스피어의 작품을 코퍼스로 학습시켜 얻은 CBOW 변형 모델은
셰익스피어가 자주 사용하는 표현과 단어를 학습하기 때문에
셰익스피어의 문체를 흉내낼 수 있다.
다음은 ChatGPT4를 이용해 블랙핑크의 붐바야 가사를 셰익스피어 문체로 바꾼 것이다.


바흐의 작품을 코퍼스로 학습시켜 얻은 CBOW 변형 모델은
바흐의 자주 사용하는 음계와 박자를 학습하기 때문에
바흐의 스타일을 흉내낼 수 있다.
CBOW 모델을 변형한 언어 모델의 문제점
-
문제: 고정된 context에서 벗어날 경우 앞의 정보가 완전히 사라진다.
Tom was watching TV in his room. Mary came into the room. Mary said hi to ?.
Tom ?로부터 18번째 앞에 나오기 때문에 맥락이 10개였다면 이 문제에 답을할 수 없다. 맥락을 아무리 늘려도 그 앞의 단어는 무시될 수 밖에 없다. (& 매개변수가 계속 늘어나므로 비효율적이다.)
- 해결: 과거의 정보를 기억하는 순환신경망을 사용한다.
-
문제: 순서가 무시된다.
You say ? and I say hello.
(you,say)와 (say, you)는 행렬곱층을 거쳐 평균하면 같기 때문에 순서가 무시된다.
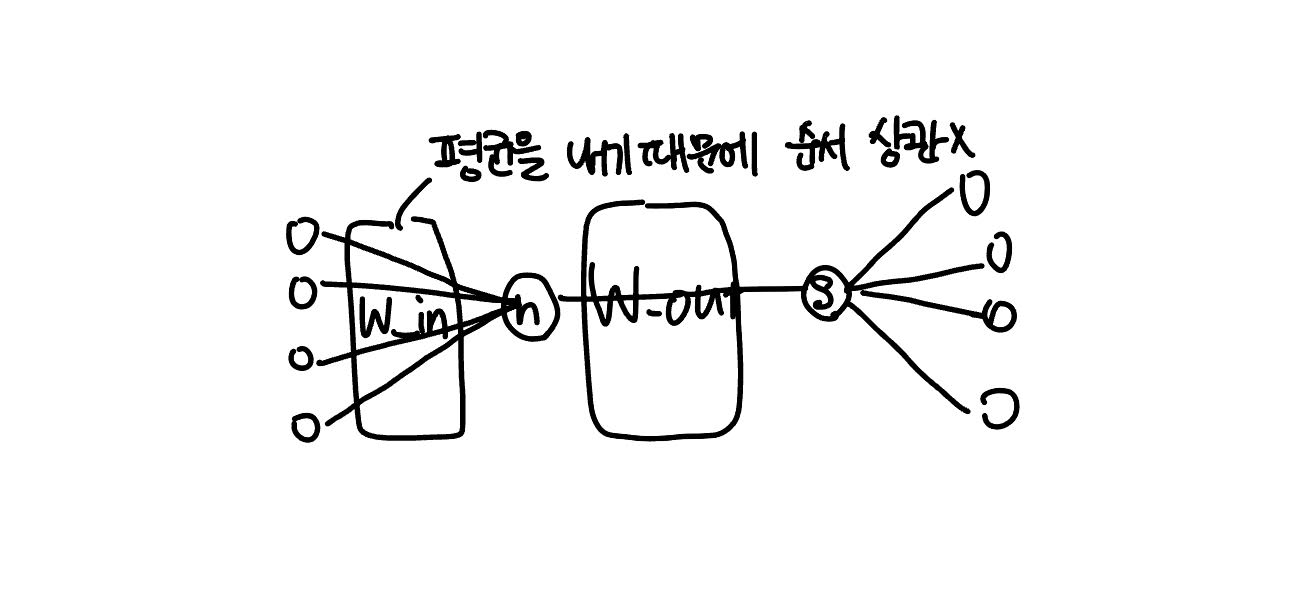
- 해결: 과거의 정보가 시간 순서로 기억되는 순환신경망을 사용한다.
RNN(Recurrent Nerual Network)
-
Recurrent: 순환한다, 재발한다, 일어난다.
-
RNN: 순환하는 신경망
-
어느 한 시점에서 시작한 것이 시간을 지나 다시 원래 장소로 돌아옴
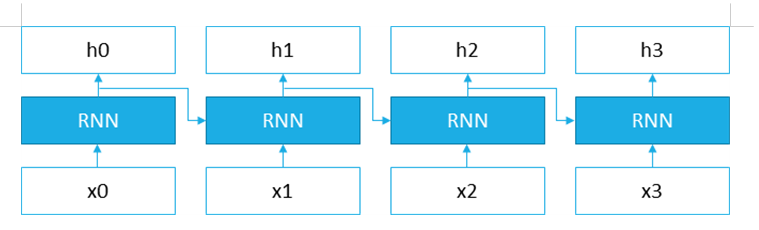
-
RNN 계층은 순환하는 경로를 포함
-
단어 벡터
X_t을 입력받는데 여기서t는 시간 -
은닉 벡터
h_t가 출력됨
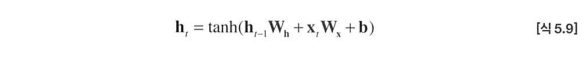 [출처:밑바닥부터 시작하는 딥러닝2 사이토 고기토 저]
[출처:밑바닥부터 시작하는 딥러닝2 사이토 고기토 저]
: 입력 를 출력 로 변환하기 위한 가중치
: 하나의 RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치
: 편향
: 이전 시각의 은닉층 행 벡터
: 현재 시각 입력 데이터의 행 벡터
[식 5.9]에서는 행렬 곱을 계산하고, 그 합을 함수를 이용해 변환하고
그 결과 시각 의 출력 가 된다.
이 는 다음 계층인 은닉층으로 보내지는 한편 다음 시각의 RNN 계층(= 현재 계층으로 되돌아옴)을 향해 오른쪽으로도 출력된다.
현재의 출력()은 한 시각이전 출력()을 이용해 계산이 된다. 즉, RNN은 라는 '상태'를 가지고 있으며[식 5.9]에서와 같이 다음 시각의 은닉벡터 로 갱신된다.
RNN의 활성화 함수
-
sigmoid와 유사하나, 대칭점이 이동한 형태의 hyperbolic tangent함수이다.
이는 계산의 편의를 위한 작업이다.
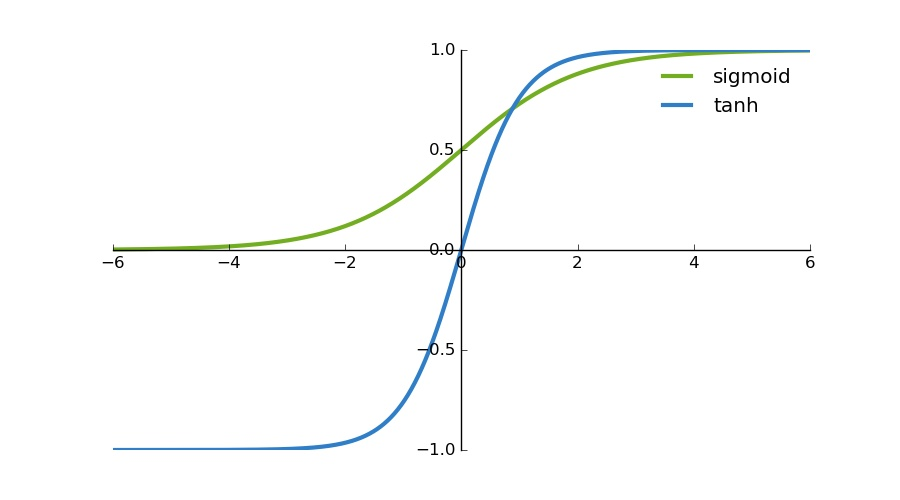
출처: RonyRestRepo -
정의
=
은 Sigmoid와 유사하게 생겼다.
- 정의
=
를 Sigmoid 형태로 표현할 수 있다.
가 딥러닝 신경망 네트워크에 활성 함수로 사용될 때 경사 하강법(Gradient Descent Algorithm) 계산 혹은 역전파 계산 과정에서 함수의 미분이 필요하다. 이 왜 를 대체할 수 있는 지 또 하나의 멋진 이유가 여기서 나온다.
- 의 미분 결과
증명 과정은 생략했지만, 결과가 덧셈, 뺄셈, 곱셈으로만 이루어지는 것을 쉽게 확인할 수 있다.
이는 GPU를 사용해서 계산할 수 있는 최적의 연산이기 때문에 딥러닝 계산에 활용될 수 있다. 나눗셈만 되어도 시간 복잡도가 크게 늘어나 GPU에서 적합하지 않게 된다.
참조
